RNN与应用案例:注意力模型与机器翻译
1. 注意力模型
1.2 注意力模型概述
注意力模型(attention model)是一种用于做图像描述的模型。在笔记6中讲过RNN去做图像描述,但是精准度可能差强人意。所以在工业界,人们更喜欢用attention model。
结合下图,先简单地讲一下,注意力模型的运作原理。
第一步:进来一张图片
第二步:图片进入卷积神经网络,进行前向运算,将某个卷积层的结果输出。注意,上一个笔记中讲的RNN做图像描述,用的是全链接层的输出。至于说哪个层的输出好,没法下结论,这个需要去不同的场景中做实验比较。比如这个实验中选择了输出卷积层的第5层结果进行输出。
第三步:卷积层中的输出作为输入,进入了RNN,这个RNN的运作与之前讲的有所不同,因为加进了“注意力”的因素,会去注意图片中的某一块趋于,具体的逻辑下文详述。
第四步:输出,生成描述性的文字。
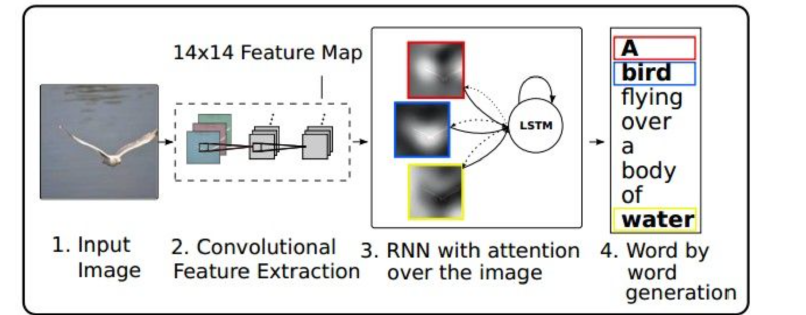
1.1.2 注意力模型的结构
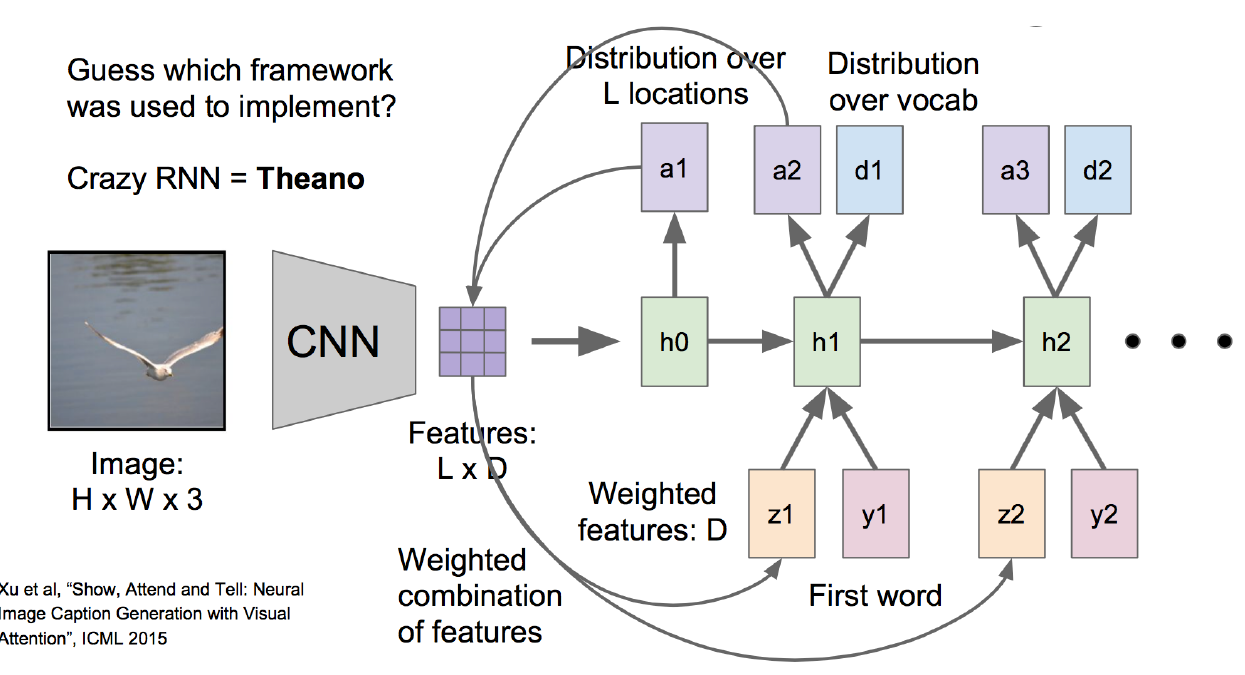
现在,我们来针对上图中的结构,仔细地讲述注意力模型的运作原理。
第一步:
还是一样,输入一张图片。当然不是一张原始的图片,而是图片转换成的H * W * 3维的矩阵,H和W是像素的高度和宽度,3是3个颜色指标。
第二步:
这个矩阵进入了卷积神经网络CNNN,做前向运算,在第五层卷基层的时候输出结果。这个结果是一个L * D的矩阵。D是这一层卷基层中神经元的个数,比如有512个。L是每个神经元中的feature map,比如是14 * 14维的。那么L * D 就是 196 * 512维的向量了。
第三步:
自己先人为创建一个D * 1维的权重向量W(这个权重的最优值在后向求导的时候会算出来的,一开始可以先随便初始化一个)。
拿从CNN出来的feature向量L * D 去乘以 这个权重向量W,得到的是L * 1的向量。也就是图中的h0,h0经过一个sotmax,会得到L * 1的概率,也就是说,对一个L 维的feature map(14 * 14)求出196个相对应的概率向量,就是图中的a1。
第四步:
a1是196维的概率向量,把它再与 L * D的feature向量相乘,求加权。也就是说,对521层神经元上的feature map都乘以一组概率,得到的是图中的z1。
这是至关重要的一步,也是注意力模型的核心,因为概率的大小重新调整了feature向量中每个值的大小。概率大的就会放更多的注意力上去,概率小的,注意力就减小了。
这个z1直接作用于第二次循环中的h1.
第五步:
现在来到了h1这一层,这一层的输入除了刚刚说的z1,还有原来就有的y1,和h0,y1是上一次循环的输出,h0是上一时刻的记忆。h1也会进入一个softmax的运算,输出一组概率,这组概率会再回到feature向量那里做权重加和,于是feature向量又进行了一轮的调整,再作用到了h2上,也就是我们看到的z2。h1出来生成一个概率向量外,还会输出一组每个词的概率,然后选取概率最大的那个词作为本轮循环的最终输出。(所有词以one-hot的形式维护在词典中)。
循环往复以上两步,实现了在每一轮的循环中都输入了新的feature向量,注意力也会改变。比如第一轮注意力是在bird,第二轮注意力在sea.
2. 翻译系统
2.1 背景
传统的机器翻译是基于统计的
2.2 初版的神经网络翻译系统
初版的翻译系统由两部分组成:encode与decode
encode:将输入的语言以一种方式表征,比如说one-hot形式,将源语言信息压缩到“记忆”中。
decode:从“记忆”中解码输出另一种语言。
如下图,encode和decode分别是一个RNN。第一个encode的RNN,在迭代到h3的时候完成,这个h3中包含了所有的记忆。接着,h3作为第二个decode的RNN的输入进行解码,每一次迭代的输出是翻译成的另一种语言的word。 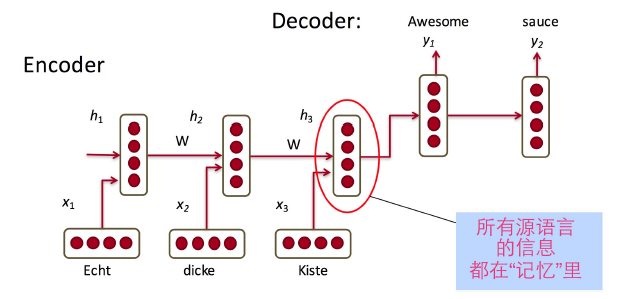
下面是具体的公式:
编码的过程: 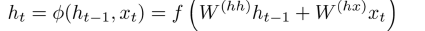
解码的过程: 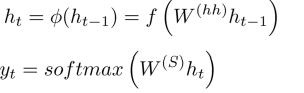
最小化交叉熵损失: 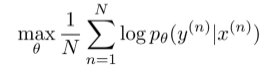
2.3 小小改进后的神经网络翻译系统
后来对初版的翻译系统做了小小的改进。
第一个改进是将输入的稀疏向量变成了稠密向量,即用one-hot向量乘以一个权重矩阵后变成了embedding dense vector.这个嵌入向量并不是通过其他语料库学习到直接使用的,而是在这个翻译的神经网络里现场学到的。
第二个改进是在decode的RNN中,每次迭代,输入到隐藏层的不仅仅是当前时刻的输入Xt,上一时刻的记忆,还有encode RNN输出的那个记忆。也就是说这个记忆不仅仅是只传给了第二个RNN中的第一层h1,而是施加给了每词迭代中的h。
两个改进可在下图的结构中看出: 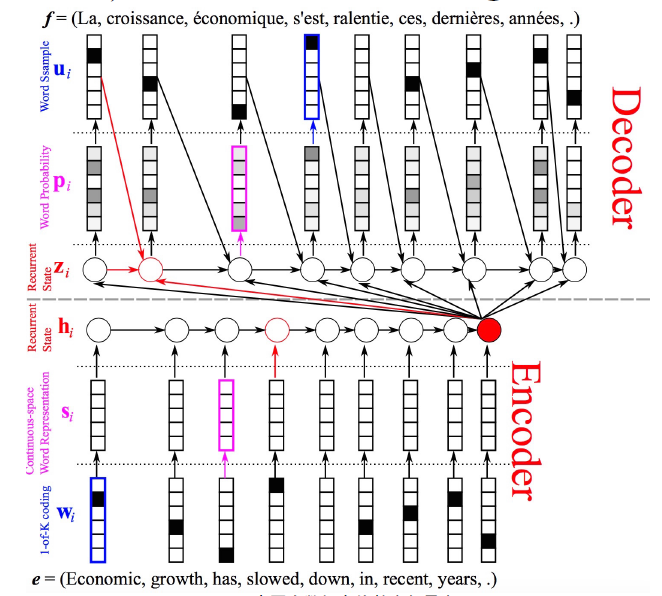
那么你可能要问了,这样的RNN做出来翻译的效果如何呢?
有点小小的惭愧,这种方式的NMT模型,比传统的SMT模型要差。当句子越长的时候,效果就越差,如果词表越大,UNK越少(UNK只词频比较少的词),翻译效果就越好。
2.4 双向RNN的神经网络翻译系统
首先来回顾一下双向RNN:
有些情况下,当前的输出不止依赖于之前的序列元素,还可能依赖之后的序列元素。比如做英文完形填空的时候,需要依据上下文才能判断所填的是什么。
双向RNN的结构与公式如下: 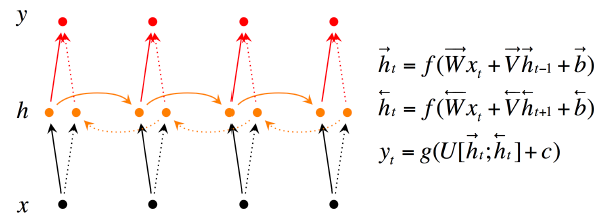
当前的记忆不仅来自于上一个时刻的记忆,还受影响于下一个时刻的记忆。
在翻译系统中,双向RNN用于捕获周边(两侧的信息),不仅如此,改进后的模型中还加入了“注意力”模型,用于关注当前正在翻译的词。
下面我们来看一下改进后模型的结构与原理。
(1) encode部分
隐藏层hj是受两个方向的记忆一起作用的。
前后两个记忆的计算方式都是一样的。第一个是由这个时刻的输入xj乘以权重W,和上一时刻的记忆hj-1乘以权重U组成;第二个是这个时刻的输入xj乘以权重W,和下一时刻的记忆hj+1乘以权重U组成的。注意两边的w,U权重是不同的。
为什么要用分段函数表示呢,因为在起始点的词是没有前一时刻的记忆的,所以计为0
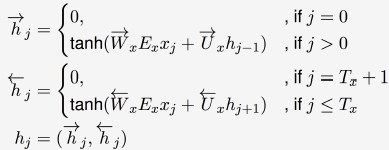
encode的结构: 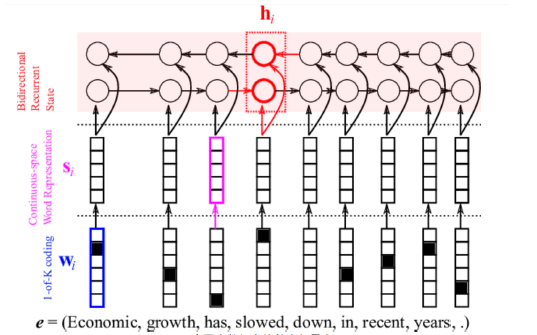
(2) decode部分
解码的过程也是一个RNN,但不是双向的。
si是它的隐藏层,也就是记忆体,它有三个输入,一个是前一时刻的输出词作为这一时刻的输入,第二个是前一时刻的记忆,第三个是注意力矩阵ci。
ti是经过选择的输出
yi是输出层,它是经过一个softmax实现的,所以输出的是概率向量。sh
(3) Attention 部分
句子是变化长度的,要集中经理在某个部分上。
和图像处理中的注意力模型一样,有一个注意力矩阵V,(这个矩阵中的参数也是在模型训练中需要学习的),将这个矩阵乘以tanh函数再放进一个soaftmax中,变成了一个概率向量,重要的需要关注的位置的概率会比较大,无需关注的地方的概率比较小。然后将它乘以隐藏层的记忆,就体现出来关注的信息。 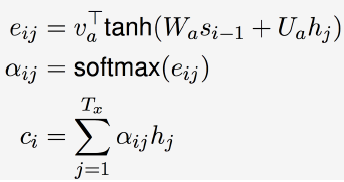
tensorflow框架下有一个序列到序列进行翻译的学习案例。
文档可以参见https://www.tensorflow.org/versions/r0.11/tutorials/seq2seq/index.html
代码可以参见https://github.com/tensorflow/tensorflow/tree/master/tensorflow/models/rnn/translate
这个案例我在另一份笔记中会详细讲述。0]
3.RNN生成模型的其他应用
RNN生成模型的应用有许多有趣的案例,下面罗列了一些,并且附上了相关代码与案例原文的链接。
3.1 生成字符级别的语言模型
上一个笔记中将的语言生成模型是针对word来做的,这里的原理是完全一样的,只是针对chart来做。将所有chart,包括标点符号全部作为输入。大致的结构如下:
![QQ截图20161027132426.png-71.6kB][131]
这个案例的代码可以见:https://gist.github.com/karpathy/d4dee566867f8291f086
来看一下模型在学习过程中的进展是如何的:
学习第100轮的时候,还很混乱 
学习第300轮之后,已经能正确得插入词与词之间的空格 
第500轮之后,知道了要加句号在某个位置,并且句号之后加一个空格 
700-900轮时,已经非常像英文的句子,已经学会了使用引号,省略号等,学出来的词也已经是标准的英文单词 
1200轮的时候,能识别人名要大写,并且单词和句子也几乎是正确的。 
所以,RNN与学习的时候是一个逐步学习的过程。
3.2 生成维基百科
同样的原理,如果喂给RNN的是维基百科的内容,那么它也能在学习之后模仿写出维基百科。
已经有小伙伴整理了一部分维基百科的数据做成text的格式,有兴趣的小伙伴可以去下载数据测试一下。
数据地址:http://cs.stanford.edu/people/karpathy/char-rnn/wiki.txt
3.3 生成模型写食谱
同样,RNN也可以去模仿写食谱。这个案例的具体信息见以下链接。
案例:https://gist.github.com/nylki/1efbaa36635956d35bcc
代码:https://gist.github.com/karpathy/d4dee566867f8291f086
数据:http://www.ffts.com/recipes/lg/lg32965.zip
3.4 生成模型写奥巴马演讲稿
还有一些小伙伴尝试了用RNN去写奥巴马的演讲稿。
数据下载地址:
https://medium.com/@samim/obama-rnn-machine-generated-political-speeches-c8abd18a2ea0#.9sb793kbm
3.5 合成音乐
音乐也是一个时序的一个任务。将乐谱用一种方式表示出来输入RNN,预测完之后,再把它转换成音符。
具体的过程请见blog:https://highnoongmt.wordpress.com/2015/05/22/lisls-stis-recurrent-neural-networks-for-folk-music-generation/
还有一个更高级的合成音乐案例,这里面还涉及到了乐理的一些知识,
具体请看blog:http://www.hexahedria.com/2015/08/03/composing-music-with-recurrent-neural-networks/
RNN与应用案例:注意力模型与机器翻译的更多相关文章
- TensorFlow系列专题(十一):RNN的应用及注意力模型
磐创智能-专注机器学习深度学习的教程网站 http://panchuang.net/ 磐创AI-智能客服,聊天机器人,推荐系统 http://panchuangai.com/ 目录: 循环神经网络的应 ...
- 深度学习之Attention Model(注意力模型)
1.Attention Model 概述 深度学习里的Attention model其实模拟的是人脑的注意力模型,举个例子来说,当我们观赏一幅画时,虽然我们可以看到整幅画的全貌,但是在我们深入仔细地观 ...
- 【NLP】Attention Model(注意力模型)学习总结
最近一直在研究深度语义匹配算法,搭建了个模型,跑起来效果并不是很理想,在分析原因的过程中,发现注意力模型在解决这个问题上还是很有帮助的,所以花了两天研究了一下. 此文大部分参考深度学习中的注意力机制( ...
- 普适注意力:用于机器翻译的2D卷积神经网络,显著优于编码器-解码器架构
现有的当前最佳机器翻译系统都是基于编码器-解码器架构的,二者都有注意力机制,但现有的注意力机制建模能力有限.本文提出了一种替代方法,这种方法依赖于跨越两个序列的单个 2D 卷积神经网络.该网络的每一层 ...
- [DeeplearningAI笔记]序列模型3.7-3.8注意力模型
5.3序列模型与注意力机制 觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.7注意力模型直观理解Attention model intuition 长序列问题 The problem of ...
- 深度学习方法(九):自然语言处理中的Attention Model注意力模型
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.NET/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 上一篇博文深度学习方法(八):Enc ...
- zz深度学习中的注意力模型
中间表示: C -> C1.C2.C3 i:target -> IT j: source -> JS sim(Query, Key) -> Value Key:h_j,类似某种 ...
- [深度概念]·Attention Model(注意力模型)学习笔记
此文源自一个博客,笔者用黑体做了注释与解读,方便自己和大家深入理解Attention model,写的不对地方欢迎批评指正.. 1.Attention Model 概述 深度学习里的Attention ...
- Attention Model(注意力模型)思想初探
1. Attention model简介 0x1:AM是什么 深度学习里的Attention model其实模拟的是人脑的注意力模型,举个例子来说,当我们观赏一幅画时,虽然我们可以看到整幅画的全貌,但 ...
随机推荐
- ABAP开发需要养成的习惯—处理规范,日期,sort,改结构
sELECT select之后不要急着处理,最多用下sort还有delete adjacent,不用sy-subrc判断之后loop操作,要注意处理逻辑. sort一个好处是为了后面read tabl ...
- ADT和DS
Abstract Data Type vs. Data Structrue 抽象数据类型=数据模型+定义在该模型上的一组操作. interface 数据结构=基于某种特定语言,实现ADT的一整套算法 ...
- MapperScannerConfigurer 自动扫描 将Mapper接口生成代理注入到Spring
Mybatis在与Spring集成的时候可以配置 MapperFactoryBean来生成Mapper接口的代理. 例如 <bean id="userMapper" clas ...
- netcore sqlserver linq contains生成的sql语句不是使用like而是charIndex
在ef中使用linq调用了contains,结果怎么都查不到值,打开sqlserver profiler 发现生成的sql语句不是使用like...而是CharIndex 参考文档:https://s ...
- c# 2016QQ自动登录程序
程序是抓QQ主程序窗体句柄,通过移位定位到QQ 输入框,虚拟键盘输入后,ALT切换到密码框的方式实现的 附程序: using System;using System.Collections.Gener ...
- Linux_(2)基本命令(下)
六.文件搜索命令11 :which功能描述:显示系统命令所在目录命令所在路径:/usr/bin/which执行权限:所有用户语法:which [命令名称]范例:$ which ls 12 :find功 ...
- 利用Swoole编写一个TCP服务器,顺带测试下Swoole的4层生命周期
1首先我们写一个入口脚本,这里简单点的功能就是开启服务和关闭服务 <?php //CLI命令 if(isset($argv[1]) && in_array($argv[1], [ ...
- Maven的conf目录下settings.xml的简单配置
省略一些其他配置 <?xml version="1.0" encoding="UTF-8"?> <settings xmlns="h ...
- Android.DebugTools.Traceview & dmtracedump
1. Android 调试工具之Traceview http://www.cnblogs.com/devinzhang/archive/2011/12/18/2291592.html TraceVie ...
- C单链表操作
#include <stdio.h> #include <stdlib.h> #define ElemType int #define Status int #define O ...