Scrapyd+Gerapy部署Scrapy爬虫进行可视化管理
- 服务端安装部署:


.png)

.png)
- 客户端安装部署:
.png)
.png)


.png)
.png)


.png)
.png)
.png)


.png)

.png)
.png)


.png)
.png)

.png)


.png)
.png)

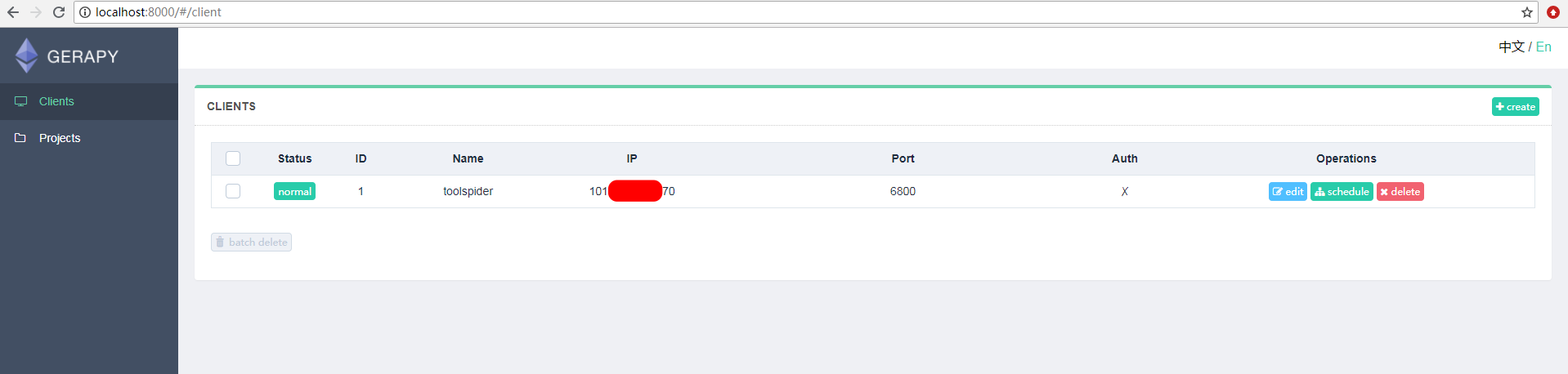
.png)
.png)

Scrapyd+Gerapy部署Scrapy爬虫进行可视化管理的更多相关文章
- 爬虫部署 --- scrapyd部署爬虫 + Gerapy 管理界面 scrapyd+gerapy部署流程
---------scrapyd部署爬虫---------------1.编写爬虫2.部署环境pip install scrapyd pip install scrapyd-client 启动scra ...
- 使用Scrapyd部署Scrapy爬虫到远程服务器上
1.准备好爬虫程序 2.修改项目配置 找到项目配置文件scrapy.cnf,将里面注释掉的url解开来 本代码需要连接数据库,因此需要修改对应的数据库配置 其实就是将里面的数据库地址进行修改,变成远程 ...
- Docker部署Portainer搭建轻量级可视化管理UI
1. 简介 Portainer是一个轻量级的可视化的管理UI,其本身也是运行在Docker上的单个容器,提供用户更加简单的管理和监控宿主机上的Docker资源. 2. 安装Docker Doc ...
- Scrapy爬虫基本使用
一.Scrapy爬虫的第一个实例 演示HTML地址 演示HTML页面地址:http://python123.io/ws/demo.html 文件名称:demo.html 产生步骤 步骤1:建议一个Sc ...
- Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合
简介:给正在学习的小伙伴们分享一下自己的感悟,如有理解不正确的地方,望指出,感谢~ 首先介绍一下这个标题吧~ 1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待 ...
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- 五十一 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:https://github.com/scrapy/scrapyd 建议安装 pip3 install s ...
- scrapy可视化管理工具spiderkeeper使用笔记
http://www.scrapyd.cn/doc/156.html 入门中文教程 spiderkeeper是一款开源的spider管理工具,可以方便的进行爬虫的启动,暂停,定时,同时可以查看分布式 ...
- Scrapy可视化管理软件SpiderKeeper
通常开发好的Scrapy爬虫部署到服务器上,要不使用nohup命令,要不使用scrapyd.如果使用nohup命令的话,爬虫挂掉了,你可能还不知道,你还得上服务器上查或者做额外的邮件通知操作.如果使用 ...
随机推荐
- MyEclipse免费使用
import java.text.DecimalFormat; import java.text.NumberFormat; import java.text.SimpleDateFormat; im ...
- 基础知识整理汇总 - Java学习(一)
java 语言规范及相关文档资源 Java源码:安装目录下 src.zip 文件 java文档:https://docs.oracle.com/en/java/ 语言规范:http://docs.or ...
- Vue那些事儿之用visual stuido code编写vue报的错误Elements in iteration expect to have 'v-bind:key' directives.
当用vsc打开我们的vue代码时,在其他编辑器里面本来没有错误,到这个编辑器里面 v-for就出毛病了.如下图所示, 那是因为我们打开了对vue进行Eslint的检查. 搜索vetur.validat ...
- [SDOI2008]洞穴勘测
嘟嘟嘟 写完lct的板儿后觉得这就是一道大水题. 连pushup都不用. 不过还是因为一个zz的错误debug了一小会儿(Link的时候连出自环--) 还有一件事就是Cut的时候判断条件还得加上,因为 ...
- day2-课堂笔记
#面向对象 函数=方法 系统内建函数:len().id() 对象函数
- shiro实战系列(十一)之Caching
Shiro 开发团队明白在许多应用程序中性能是至关重要的.Caching 是从第一天开始第一个建立在 Shiro 中的一流功 能,以确保安全操作保持尽可能的快. 然而,Caching 作为一个概念 ...
- Dubbo -- 系统学习 笔记 -- 目录
用户指南 入门 背景 需求 架构 用法 快速启动 服务提供者 服务消费者 依赖 必需依赖 缺省依赖 可选依赖 成熟度 功能成熟度 策略成熟度 配置 Xml配置 属性配置 注解配置 API配置 示例 启 ...
- scrt中使用alt键
session Options-->Terminal---->Emulation------>Emacs----->Use ALT as meta key
- java List集合中contains方法总是返回false
ArrayList的contains方法 java 今天在用ArrayList类的caontains方法是遇到了问题,我写了一个存放User类的ArrayList 但在调用list.contains( ...
- E - A Twisty Movement
A dragon symbolizes wisdom, power and wealth. On Lunar New Year's Day, people model a dragon with ba ...