CMU-15445 LAB1:Extendible Hash Table, LRU, BUFFER POOL MANAGER
概述
最近又开了一个新坑,CMU的15445,这是一门介绍数据库的课程。我follow的是2018年的课程,因为2018年官方停止了对外开放实验源码,所以我用的2017年的实验,但是问题不大,内容基本没有变化。想要获取实验源码的同学可以上github搜,或者直接clone我的代码,找到最早的commit就ok了,仓库地址在文末。课程配套教材是《
Database System Concepts》,https://book.douban.com/subject/4740662/ 最好看原版的,中文版的貌似页数和课程中的对不上。
言归正传,本lab将实现一个Buffer Pool Manager,又分为三个子任务:
- 实现一个Extendible Hash Table
- 实现一个LRU Page Replacement Policy
- 实现Buffer Pool Manager
Extendible Hash Table
Extendible Hash Table是动态hash的一种,动态是相对静态来说的。hash的原理是通过hash函数,f(key)->B,将key映射到一个Bucket地址集合中,如果B集合选的比较小,那么当key增多后,越来越多的key会落在同一个Bucket中,这样查找效率会下降。如果B集合一开始就选的很大,那么有很多Bucket处于未满状态,浪费空间。为了解决这个问题,就引入动态hash的概念。
静态hash存在上述问题主要是hash函数确定好后就不能再变了。动态hash就没有这个问题。
数据结构
Extendible Hash Table数据结构如下:
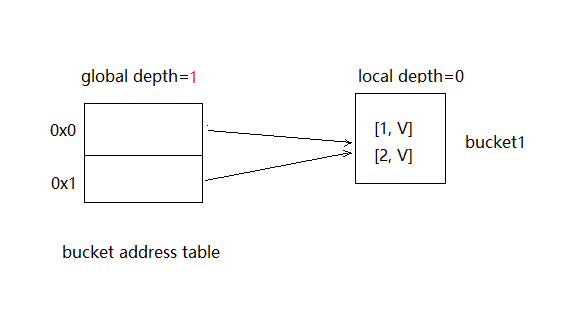
- bucket address table是一个数组,保存bucket的地址。
- global depth是一个整数值。
- 每个bucket都有一个local depth也是一个整数值,且小于等于global depth。每个bucket能装的键值对的最大值为bucketMaxSize。
查询
比如要查找key=1对应的value值,首先取h(1)对应的二进制前global depth位,作为bucket address table的下标,找到存放该key的bucket,然后在相应的bucket中查找。
插入
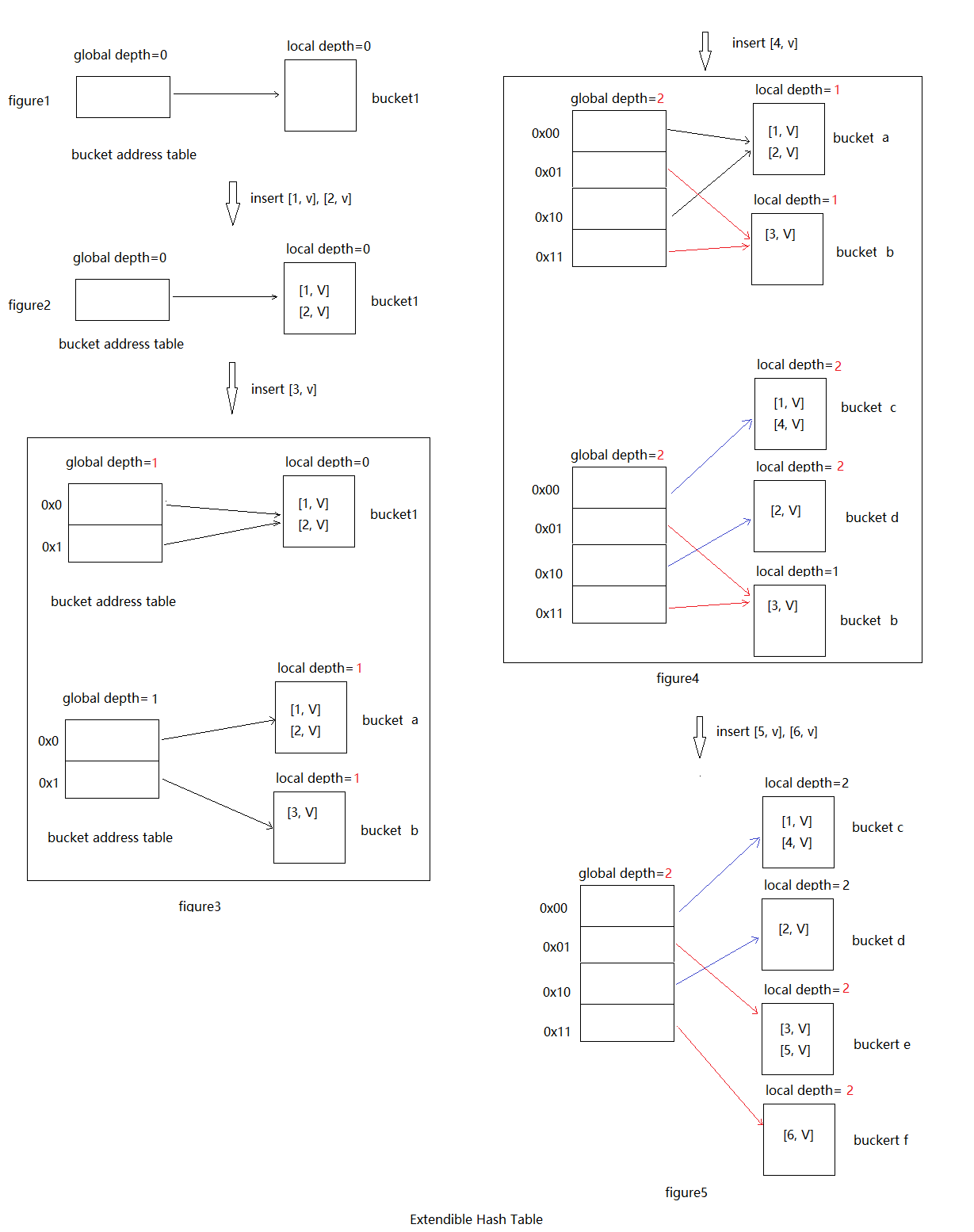
如上图,假设bucketMaxSize为2.
最开始的情况如figure1,我们插入[1, v], [2, v],因为这时global depth=0所以,全部落在bucket1中,也就是figure2。
在figure2基础上,再插入[3, v],这时还是应该插到bucket1中,但是bucket1已经满了,同时bucket1的local depth = global depth = 1。这时先将bucket address table扩大一倍,同时global depth加1。然后重新创建两个新的bucket a, bucket b,local depth在原来local depth基础上加1(由0变为1),再将bucket 1中的[1, v], [2, v]分配到新的两个bucket中,分配规则如下:
如果h(key)的第local depth(1)位是0,那么放到bucket a中,如果为1那么放到bucket b中。分配完毕后,重新调整bucket address table中指向原来bucket 1的指针指向,这里index 0和1的指针原来都指向bucket 1,所以都需要调整,调整规则如下:
index的第local depth(1)位为0的指向bucket a, 为1的指向bucket b。
最后在插入[3, v], 假设h(3)的前global depth为1,那么插入到bucket b中。最终的效果如figure3。
在figure3基础上再插入[4, v],算法和前面一样,假设[4, v]本应插入到bucket a中,但是bucket a满了,且global depth = bucket 1的local depth。所以先将bucket address table扩大一倍。然后重新创建两个新的bucket, bucket c和bucket d,再将bucket a中的[1, v], [2, v]重新分配到bucket c和bucket d中。在调整buckert address table指针指向,最后再插入[4, v]。最终效果如figure 4。
在figure4基础上,再插入[5, v], [6, v],假设都落在bucket b中,那么插入[5, v]后bucket b将满,再插入[6, v]的时候bucket b已经满了。这时和前面不一样,此时global depth(2) > bucket b的local depth(1)。所以不需要扩大bucket address table。只需要创建两个新的bucket, bucket e和bucket f。将原来bucket b中的[3, v], [5, v]分配到bucket e和bucket f中。然后调整原来指向bucket b的指针指向bucket e和bucket f。最后在插入[6, v]。最终效果如figure 5。
LRU PAGE REPLACEMENT POLICY
实现最近最少使用算法,说白了就是给你一些序列,比如1, 2, 3, 1,这时哪个是最近最少使用到的。可以画下图,越下面的越久没有使用到。先用了1,再用了2,那么2比1新,所以2在1上面,然后用了3,那么3应该在2的上面,最后用了1,那么把1从最下面调到最上面,同时2变到了最下面,至此2应该是最近最久没有使用的。
1 2 3 1
1 2 3
1 2
那么用什么数据结构来存储呢?
先看下有哪些操作:
void Insert(const T &value);
bool Victim(T &value);
bool Erase(const T &value);
Insert():将value加到最顶部,或者如果value已经在队列中,将其提取到最顶部。
Victim():提取最近最久没有使用的元素,将最底部的元素弹出。
Erase():删除某个元素。
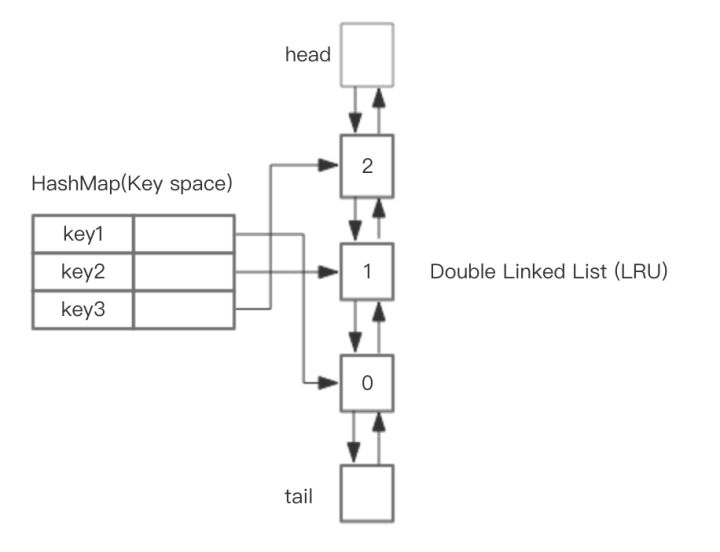
首先想到的是单向链表。但是如果用单向链表的话,Victim()需要访问尾元素,单向链表每次都要从头到尾遍历一遍才能访问尾元素,性能可想而知。
用双向链表就可以解决这个问题,双向链表可以以O(1)的时间访问头尾元素。还有个问题,如果调用Insert(v),按照之前的算法,我先得知道v在不在这个双向链表中,如果不在直接插到头部,如果在的话,将其提取到头部。如果仅仅是双向链表,那么还是需要遍历一遍队列,查询v是不是已经在队列中了。
可以用一个map记录已经在队列中的元素到链表节点的键值对,这样就可以以O(1)的时间查询某个value是否已经在队列中。
最终确定数据结构如下:
BUFFER POOL MANAGER
为什么需要BUFFER POOL MANAGER
假设两种极端的情况:
- 没有缓冲池,那么数据都位于磁盘上,第一次访问一页数据,需要将其从磁盘读取到内存,第二次在访问相同的页时,还需要从磁盘读,非常耗时。
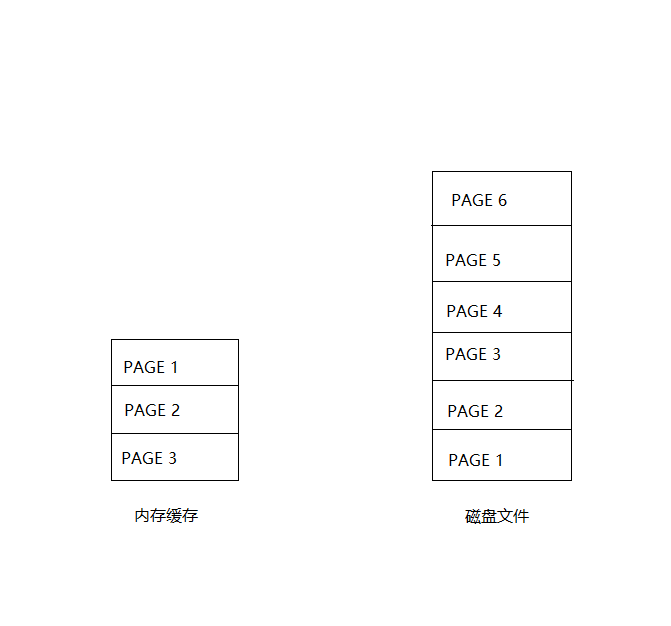
- 假设内存无限大,那么访问一页数据后,将该页数据直接保存到内存,下次再访问该页时,直接访问内存缓存就行。但是现实中内存比磁盘容量小得多,只能缓存有限个数据页,如下图内存只能缓存三个页,依次访问PAGE 1, 2, 3, 现在已经缓存了PAGE 1, 2, 3,假设想读取PAGE 4,那么得先清空一个内存缓存页,用来缓存PAGE 4的数据,那么清除谁呢?。这时候任务2的替换策略就派上用场了,根据LRU替换策略,PAGE 1是最近最久没有被使用过的,那么就将PAGE 1重新写回到磁盘,然后将PAGE 4读取到内存。
所以BUFFER POOL MANAGER的作用是加速数据的访问,同时对使用者来说是透明的。
具体代码就不贴了,可以参考我的实现:https://github.com/gatsbyd/cmu_15445_2018
CMU-15445 LAB1:Extendible Hash Table, LRU, BUFFER POOL MANAGER的更多相关文章
- CMU15445 (Fall 2019) 之 Project#2 - Hash Table 详解
前言 该实验要求实现一个基于线性探测法的哈希表,但是与直接放在内存中的哈希表不同的是,该实验假设哈希表非常大,无法整个放入内存中,因此需要将哈希表进行分割,将多个键值对放在一个 Page 中,然后搭配 ...
- Spell checker using hash table
Problem description Given a text file, show the spell errors from it. (https://www.andrew.cmu.edu/c ...
- 算法与数据结构基础 - 哈希表(Hash Table)
Hash Table基础 哈希表(Hash Table)是常用的数据结构,其运用哈希函数(hash function)实现映射,内部使用开放定址.拉链法等方式解决哈希冲突,使得读写时间复杂度平均为O( ...
- 散列表(hash table)——算法导论(13)
1. 引言 许多应用都需要动态集合结构,它至少需要支持Insert,search和delete字典操作.散列表(hash table)是实现字典操作的一种有效的数据结构. 2. 直接寻址表 在介绍散列 ...
- 哈希表(Hash Table)
参考: Hash table - Wiki Hash table_百度百科 从头到尾彻底解析Hash表算法 谈谈 Hash Table 我们身边的哈希,最常见的就是perl和python里面的字典了, ...
- Berkeley DB的数据存储结构——哈希表(Hash Table)、B树(BTree)、队列(Queue)、记录号(Recno)
Berkeley DB的数据存储结构 BDB支持四种数据存储结构及相应算法,官方称为访问方法(Access Method),分别是哈希表(Hash Table).B树(BTree).队列(Queue) ...
- 几种常见 容器 比较和分析 hashmap, map, vector, list ...hash table
list支持快速的插入和删除,但是查找费时; vector支持快速的查找,但是插入费时. map查找的时间复杂度是对数的,这几乎是最快的,hash也是对数的. 如果我自己写,我也会用二叉检索树,它在 ...
- PHP内核探索之变量(3)- hash table
在PHP中,除了zval, 另一个比较重要的数据结构非hash table莫属,例如我们最常见的数组,在底层便是hash table.除了数组,在线程安全(TSRM).GC.资源管理.Global变量 ...
- php Hash Table(四) Hash Table添加和更新元素
HashTable添加和更新的函数: 有4个主要的函数用于插入和更新HashTable的数据: int zend_hash_add(HashTable *ht, char *arKey, uint n ...
随机推荐
- AtCoder Regular Contest 069 F - Flags
题意: 有n个点需要摆在一个数轴上,每个点需要摆在ai这个位置或者bi上,问怎么摆能使数轴上相邻两个点之间的距离的最小值最大. 二分答案后显然是个2-sat判定问题,因为边很多而连边的又是一个区间,所 ...
- 【洛谷P1214】等差数列
题目大意:列出从一个给定上界的双平方数集合中选出若干个数,组成长度为 N 的等差数列的首项和公差. 题解:首先,因为是在双平方数集合上的等差数列,而且根据题目范围可知,上界不超过 2e5,可以先打表, ...
- java基础基础总结----- StringBuffer(重要)
前言StringBuffer:(常用的方法) StringBuffer与StringBuilder的区别 关于安全与不安全的解释:
- Hadoop生态圈-使用Kafka命令在Zookeeper中对应关系
Hadoop生态圈-使用Kafka命令在Zookeeper中对应关系 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.zookeeper保存kafka的目录 二.使用Ka ...
- 函数和常用模块【day04】: 总结(十二)
- Lua程序设计(四)面向对象类继承
1.类继承 ①代码 Sharp = { _val = } --① 父类 function Sharp:new() local new_sharp = { } self.__index = self - ...
- stickey-footer实现footer固定页面底部
先看看实现效果:http://getbootstrap.com/2.3.2/examples/sticky-footer.html 当一个网页比较简单,内容比较少使得网页不足浏览器高的时候,为了显示更 ...
- java整理的一些面试资料
平时逛博客的时候收集了一些认为不错的java面试题 以后跳槽的时候可以来这里刷一刷 1:后端技术精选 https://www.cnblogs.com/javazhiyin/tag/Java面试题/
- screen命令记录
1.screen -x 进入 2.ctrl+a+n 下一个 3.ctrl+a+p 上一个任务 4.ctrl+a+d 退出 5.ctrl+c 结束任务 其他 screen -ls 所有任务 screen ...
- 微信小程序调用接口返回数据或提交数据
由于小程序发起网络请求需要通过 wx.request 文档地址 https://mp.weixin.qq.com/debug/wxadoc/dev/api/network-request.html 习 ...