java使用elasticsearch分组进行聚合查询(group by)-项目中实际应用
java连接elasticsearch 进行聚合查询进行相应操作
一:对单个字段进行分组求和
1、表结构图片:
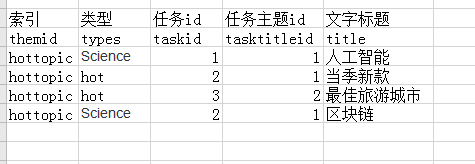
根据任务id分组,分别统计出每个任务id下有多少个文字标题
1.SQL:select id, count(*) as sum from task group by taskid;
java ES连接工具类
public class ESClientConnectionUtil {
public static TransportClient client=null;
public final static String HOST = "192.168.200.211"; //服务器部署
public final static Integer PORT = 9301; //端口
public static TransportClient getESClient(){
System.setProperty("es.set.netty.runtime.available.processors", "false");
if (client == null) {
synchronized (ESClientConnectionUtil.class) {
try {
//设置集群名称
Settings settings = Settings.builder().put("cluster.name", "es5").put("client.transport.sniff", true).build();
//创建client
client = new PreBuiltTransportClient(settings).addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(HOST), PORT));
} catch (Exception ex) {
ex.printStackTrace();
System.out.println(ex.getMessage());
}
}
}
return client;
}
public static TransportClient getESClientConnection(){
if (client == null) {
System.setProperty("es.set.netty.runtime.available.processors", "false");
try {
//设置集群名称
Settings settings = Settings.builder().put("cluster.name", "es5").put("client.transport.sniff", true).build();
//创建client
client = new PreBuiltTransportClient(settings).addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(HOST), PORT));
} catch (Exception ex) {
ex.printStackTrace();
System.out.println(ex.getMessage());
}
}
return client;
}
//判断索引是否存在
public static boolean judgeIndex(String index){
client= getESClientConnection();
IndicesAdminClient adminClient;
//查询索引是否存在
adminClient= client.admin().indices();
IndicesExistsRequest request = new IndicesExistsRequest(index);
IndicesExistsResponse responses = adminClient.exists(request).actionGet();
if (responses.isExists()) {
return true;
}
return false;
}
}
java ES语句(根据单列进行分组求和)
//根据 任务id分组进行求和
SearchRequestBuilder sbuilder = client.prepareSearch("hottopic").setTypes("hot");
//根据taskid进行分组统计,统计出的列别名叫sum
TermsAggregationBuilder termsBuilder = AggregationBuilders.terms("sum").field("taskid");
sbuilder.addAggregation(termsBuilder);
SearchResponse responses= sbuilder.execute().actionGet();
//得到这个分组的数据集合
Terms terms = responses.getAggregations().get("sum");
List<BsKnowledgeInfoDTO> lists = new ArrayList<>();
for(int i=0;i<terms.getBuckets().size();i++){
//statistics
String id =terms.getBuckets().get(i).getKey().toString();//id
Long sum =terms.getBuckets().get(i).getDocCount();//数量
System.out.println("=="+terms.getBuckets().get(i).getDocCount()+"------"+terms.getBuckets().get(i).getKey());
}
//分别打印出统计的数量和id值
根据多列进行分组求和
//根据 任务id分组进行求和
SearchRequestBuilder sbuilder = client.prepareSearch("hottopic").setTypes("hot");
//根据taskid进行分组统计,统计出的列别名叫sum
TermsAggregationBuilder termsBuilder = AggregationBuilders.terms("sum").field("taskid");
//根据第二个字段进行分组
TermsAggregationBuilder aAggregationBuilder2 = AggregationBuilders.terms("region_count").field("birthplace");
//如果存在第三个,以此类推;
sbuilder.addAggregation(termsBuilder.subAggregation(aAggregationBuilder2));
SearchResponse responses= sbuilder.execute().actionGet();
//得到这个分组的数据集合
Terms terms = responses.getAggregations().get("sum");
List<BsKnowledgeInfoDTO> lists = new ArrayList<>();
for(int i=0;i<terms.getBuckets().size();i++){
//statistics
String id =terms.getBuckets().get(i).getKey().toString();//id
Long sum =terms.getBuckets().get(i).getDocCount();//数量
System.out.println("=="+terms.getBuckets().get(i).getDocCount()+"------"+terms.getBuckets().get(i).getKey());
}
//分别打印出统计的数量和id值
对多个field求max/min/sum/avg
SearchRequestBuilder requestBuilder = client.prepareSearch("hottopic").setTypes("hot");
//根据taskid进行分组统计,统计别名为sum
TermsAggregationBuilder aggregationBuilder1 = AggregationBuilders.terms("sum").field("taskid")
//根据tasktatileid进行升序排列
.order(Order.aggregation("tasktatileid", true));
// 求tasktitleid 进行求平均数 别名为avg_title
AggregationBuilder aggregationBuilder2 = AggregationBuilders.avg("avg_title").field("tasktitleid");
//
AggregationBuilder aggregationBuilder3 = AggregationBuilders.sum("sum_taskid").field("taskid");
requestBuilder.addAggregation(aggregationBuilder1.subAggregation(aggregationBuilder2).subAggregation(aggregationBuilder3));
SearchResponse response = requestBuilder.execute().actionGet();
Terms aggregation = response.getAggregations().get("sum");
Avg terms2 = null;
Sum term3 = null;
for (Terms.Bucket bucket : aggregation.getBuckets()) {
terms2 = bucket.getAggregations().get("avg_title"); // org.elasticsearch.search.aggregations.metrics.avg.InternalAvg
term3 = bucket.getAggregations().get("sum_taskid"); // org.elasticsearch.search.aggregations.metrics.sum.InternalSum
System.out.println("编号=" + bucket.getKey() + ";平均=" + terms2.getValue() + ";总=" + term3.getValue());
}
如上内容若有不恰当支持,请各位多多包涵并进行点评。技术在于沟通!
java使用elasticsearch分组进行聚合查询(group by)-项目中实际应用的更多相关文章
- java使用elasticsearch进行模糊查询-已在项目中实际应用
java使用elasticsearch进行模糊查询 使用环境上篇文章本人已书写过,需要maven坐标,ES连接工具类的请看上一篇文章,以下是内容是笔者在真实项目中运用总结而产生,并写的是主要方法和思路 ...
- Mysql教程:(二)分组与函数查询group by
分组与函数查询 温馨提示:分组之后查询其他函数结果是不正确的: 分组函数:group by 按班级分组,查询出每班数学最高分:select class,max(maths) from score gr ...
- mqtt协议实现 java服务端推送功能(三)项目中给多个用户推送功能
接着上一篇说,上一篇的TOPIC是写死的,然而在实际项目中要给不同用户 也就是不同的topic进行推送 所以要写活 package com.fh.controller.information.push ...
- java 项目中几种O实体类的概念
经常会接触到vo,do,dto的概念,本文从领域建模中的实体划分和项目中的实际应用情况两个角度,对这几个概念进行简析. 得出的主要结论是:在项目应用中,vo对应于页面上需要显示的数据(表单),do对应 ...
- MongoDB分组查询,聚合查询,以及复杂查询
准备数据 from pymongo import MongoClient import datetime client=MongoClient('mongodb://localhost:27017') ...
- Django-model聚合查询与分组查询
Django-model聚合查询与分组查询 聚合函数包含:SUM AVG MIN MAX COUNT 聚合函数可以单独使用,不一定要和分组配合使用:不过聚合函数一般和group by 搭配使用 agg ...
- 使用Java操作Elasticsearch(Elasticsearch的java api使用)
1.Elasticsearch是基于Lucene开发的一个分布式全文检索框架,向Elasticsearch中存储和从Elasticsearch中查询,格式是json. 索引index,相当于数据库中的 ...
- MongoDB聚合查询及Python连接MongoDB操作
今日内容概要 聚合查询 Python操作MongoDB 第三方可视化视图工具 今日内容详细 聚合查询 Python操作MongoDB 数据准备 from pymongo import MongoCli ...
- JAVA项目中的常用的异常处理情况总结
可能遇见的异常或错误: 检查性异常:最具代表的检查性异常是用户错误或问题引起的异常,这是程序员无法预见的.例如要打开一个不存在文件时,一个异常就发生了,这些异常在编译时不能被简单地忽略. 运行时异常: ...
随机推荐
- UIView动画下
#import "ViewController.h" @interface ViewController () { UIButton *btn; } @end @implement ...
- sql union 语句 case语句
1:Union语句: 把两个结果合为一体(但是完全重复的数据会去掉) Eg1: select name, age, ‘学生无工资’ from student union ...
- C# 文本转语音,在语音播放过程中停止语音
1,运用SpVoice播放语音 在VS2013创建Windows窗体应用程序项目,添加引用COM组件Microsoft Speech Object Library: using SpeechLib; ...
- Git使用(一)——Cygwin
1.下载2.安装镜像:1)上海交大的FTP:ftp://ftp.sjtu.edu.cn/sites/cygwin.com/pub/cygwin/2)163的镜像:http://mirrors.163. ...
- SSH:Hibernate框架(七种关联关系映射及配置详解)
概念 基本映射是对一个实体进行映射,关联映射就是处理多个实体之间的关系,将关联关系映射到数据库中,所谓的关联关系在对象模型中有一个或多个引用. 分类 关联关系分为上述七种,但是由于相互之间有各种关系, ...
- Java - equals方法
java提高篇(十三)-----equals()方法总结 equal和==区别 ==比较对象基于内存引用,两个引用完全相同返回true Java 语言里的 equals方法其实是交给开发者去覆写的,让 ...
- 简单测试--C#实现中文汉字转拼音首字母
第一种: 这个是自己写的比较简单的实现方法,要做汉字转拼音首字母,首先应该有一个存储首字母的数组,然后将要转拼音码的汉字与每个首字母开头的第一个汉字即“最小”的汉字作比较,这里的最小指的是按拼音规则比 ...
- HDU5840(SummerTrainingDay08-B 树链剖分+分块)
This world need more Zhu Time Limit: 12000/6000 MS (Java/Others) Memory Limit: 65536/65536 K (Jav ...
- C# 8.0 范围类型 Range Type
目录 C# 8 范围类型 Range Type: 范围缩写: 从一个索引开始到数组的最后一个对象 从数组的第一个对象到指定索引 整个数组: 从数组的某个索引开始一直到距数组尾部某个索引: 范围类型 替 ...
- JS 创建自定义对象的方式方法
一.概述 还记得刚开始做项目的时候,看到别人封装的js工具类百思不得其解,看来看去看不懂,深挖一下,其实就是自己没有耐下心去看,但是遇到问题不解决,总会遇到的,今天还是遇到了,就去找了找帖子,重新思考 ...