python爬虫_入门
本来觉得没什么可写的,因为网上这玩意一搜一大把,不过爬虫毕竟是python的一个大亮点,不说说感觉对不起这玩意
基础点来说,python2写爬虫重点需要两个模块,urllib和urllib2,其实还有re
先介绍下模块的一些常用功能
urllib.urlopen('http://xxx.xxx.xxx') #打开一个网址,只是打开,和open差不多
urllib2.Request(url) #解析网址,这个可以省略,具体不是很懂,一些功能,比如加head头什么的也需要使用这个
urllib.urlretrieve(url,filename) #下载用,把url提供的东西down下来,并用filename保存
举个蜂鸟爬图片的例子,下面上伪代码:
1、url解析
2、打开url
3、读取url,就是read()
4、使用re.findall找到所有和图片有关系的地址,这里只jpg
5、循环下载
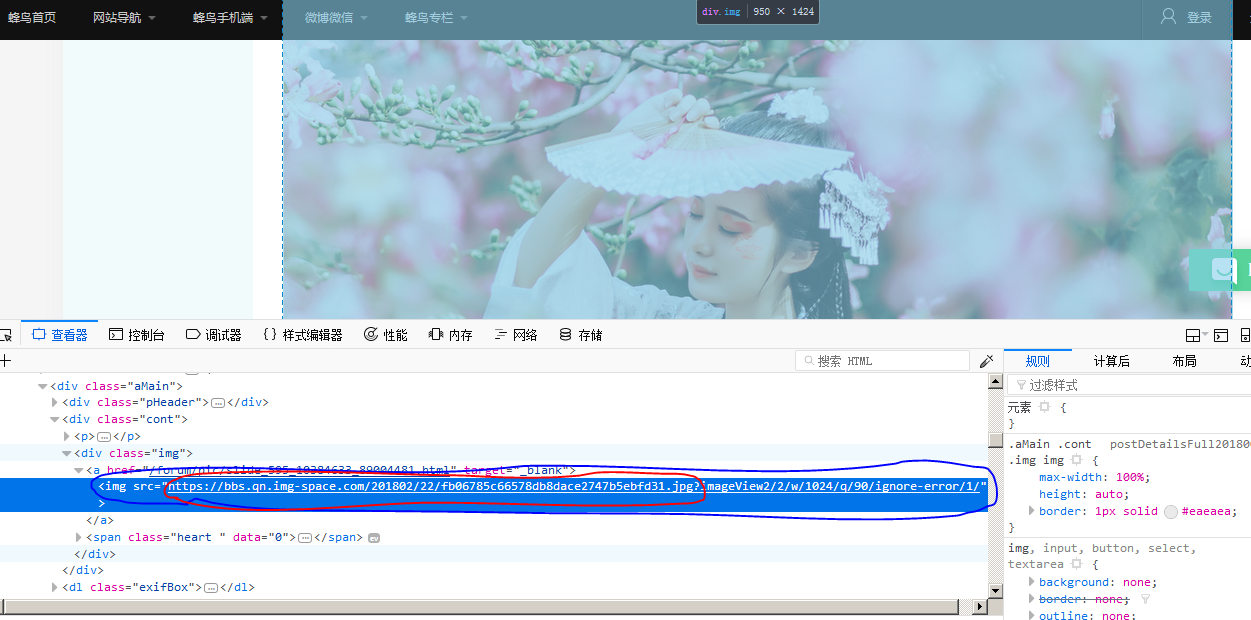
看图上,图片链接格式是src="http://index_url/page_num/image_name.jpg?XXXXXXX",那么如果需要下载的话一定是需要红圈部分,也就是http://index_url/page_num/image_name.jpg
分析之后后面的事就好办了,下面上代码
import urllib
import urllib2
import re #处理地址,并获取页面全部的图片地址
def get_image_url(url):
#url_format = urllib2.Request(url) #1
url_open = urllib.urlopen(url) #
url_read = url_open.read() #
re_value = re.compile('(?<=src\=\").*?\.jpg')
image_url_list = re.findall(re_value,url_read) #
return image_url_list #这个函数专门用来下载,前面两行是将图片连接中/前面的内容全部删除,留下后面的文件名用来保存文件的,try不说了,不清楚请翻回去看容错
def down_image(image_url):
rev = '^.*/'
file_name = re.sub(rev,'',image_url)
try:
urllib.urlretrieve(image_url,file_name)
except:
print 'download %s fail' %image_url
else:
print 'download %s successed' %image_url if __name__ == '__main__':
url = 'http://bbs.fengniao.com/forum/10384633.html'
image_url_list = get_image_url(url)
for image_url in image_url_list:
down_image(image_url) #
困死,睡觉去。。。。。有时间再说说翻页什么的,就能爬网站了
python爬虫_入门的更多相关文章
- python爬虫_入门_翻页
写出来的爬虫,肯定不能只在一个页面爬,只要要爬几个页面,甚至一个网站,这时候就需要用到翻页了 其实翻页很简单,还是这个页面http://bbs.fengniao.com/forum/10384633. ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- python爬虫如何入门
学爬虫是循序渐进的过程,作为零基础小白,大体上可分为三个阶段,第一阶段是入门,掌握必备的基础知识,第二阶段是模仿,跟着别人的爬虫代码学,弄懂每一行代码,第三阶段是自己动手,这个阶段你开始有自己的解题思 ...
- Python爬虫教程——入门五之URLError异常处理
大家好,本节在这里主要说的是URLError还有HTTPError,以及对它们的一些处理. 1.URLError 首先解释下URLError可能产生的原因: 网络无连接,即本机无法上网 连接不到特定的 ...
- 【Python爬虫】入门知识
爬虫基本知识 这阵子需要用爬虫做点事情,于是系统的学习了一下python爬虫,觉得还挺有意思的,比我想象中的能干更多的事情,这里记录下学习的经历. 网上有关爬虫的资料特别多,写的都挺复杂的,我这里不打 ...
- python爬虫从入门到放弃前奏之学习方法
首谈方法 最近在整理爬虫系列的博客,但是当整理几篇之后,发现一个问题,不管学习任何内容,其实方法是最重要的,按照我之前写的博客内容,其实学起来还是很点枯燥不能解决传统学习过程中的几个问题: 这个是普通 ...
随机推荐
- KVM:日常管理常用命令
1.查看.编辑及备份KVM 虚拟机配置文件 以及查看KVM 状态: 1.1.KVM 虚拟机默认的配置文件在 /etc/libvirt/qemu 目录下,默认是以虚拟机名称命名的.xml 文件,如下,: ...
- C语言指针的高级操作
C语言指针的高级操作 指针 指针 在上篇博客中我介绍了C语言指针的最基本操作,那么我在这篇博客中会介绍一下C语言指针的一些骚操作. 指向指针的指针 这名字乍一听有点拗口,再次一听就更加拗口了.先看定 ...
- UIView动画上
主要参考:http://blog.csdn.net/huifeidexin_1/article/details/7597868 http://www.2cto.com/kf/201409/33566 ...
- Java maven项目的小随笔
1.web.xml里面有filter拦截设置,注意. 2.编译之后,网页中读取资源的路径是apache-tomcat/wtpwebapps/..,若该路径下没有相应资源,则报404错误.
- [转]Magento刷新索引的几种方法
本文转自:https://blog.csdn.net/IT_Wallace/article/details/78513951 在数据表中经常会使用索引,下面简单介绍一下索引的利弊: 创建索引可以大大提 ...
- EWS 邮件提醒
摘要 之前做的邮件提醒的项目,最近需要优化,由于使用了队列,但即时性不是特别好,有队列,就会出现先后的问题,最近调研了exchange 流通知的模式,所以想使用流通知模式和原先的拉取邮件的方法结合,在 ...
- QYH练字
汉字书写笔划,提取自百度汉语等网站... 以下凑字数: [发文说明]博客园是面向开发者的知识分享社区,不允许发布任何推广.广告.政治方面的内容.博客园首页(即网站首页)只能发布原创的.高质量的.能让读 ...
- 【Tomcat】tomcat配置文件详解
Tomcat Server的结构图 结构框架,如下 属性表格 元素名 属性 解释 server(它代表整个容器,是Tomcat实例的顶层元素.由org.apache.catalina.Server接口 ...
- Median(vector+二分)
Median Time Limit: 5 Seconds Memory Limit: 65536 KB The median of m numbers is after sorting them in ...
- java锁的简化
java使用单独的锁对象的代码展示 private Lock bankLock = new ReentrantLock(); //因为sufficientFunds是锁创建的条件所以称其为条件对象也叫 ...