spark基础知识介绍2
dataframe以RDD为基础的分布式数据集,与RDD的区别是,带有Schema元数据,即DF所表示的二维表数据集的每一列带有名称和类型,好处:精简代码;提升执行效率;减少数据读取;
如果不配置spark.deploy.recoveryMode选项为ZOOKEEPER,那么集群的所有运行数据在Master重启是都会丢失
spark工作机制
用户在client端提交作业后,会由Driver运行main方法并创建spark context上下文。
执行add算子,形成dag图输入dagscheduler,按照add之间的依赖关系划分stage输入task scheduler。
task scheduler会将stage划分为task set分发到各个节点的executor中执行。
Parquet仅仅是一种存储格式,它是语言、平台无关的,并且不需要和任何一种数据处理框架绑定,Parquet是面向分析型业务的列式存储格式
Spark使用parquet文件存储格式,速度快,压缩技术出色,极大的减少磁盘I/o,通常情况下能够减少75%的存储空间,由此可以极大的减少spark sql处理数据的时候的数据输入内容,操作parquet时候cpu也进行了极大的优化,有效的降低了cpu,采用parquet可以极大的优化spark的调度和执行
parquet文件的读写
写:
scala> import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.SQLContext
scala> import java.util.Properties
import java.util.Properties
scala> val prop = new Properties();
prop: java.util.Properties = {}
scala> val con=new SQLContext(sc)
warning: there was one deprecation warning; re-run with -deprecation for details
con: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@57f045a7
scala> val url = "jdbc:mysql://localhost:3306/test?user=root&password=root";
url: String = jdbc:mysql://localhost:3306/test?user=root&password=root
scala> val aa=con.read.jdbc(url,"user_pay_3004",prop)
aa: org.apache.spark.sql.DataFrame = [id: bigint, zoneid: bigint ... 13 more fields]
scala> val filterDF=aa.select("id","userid","daynum","money")
filterDF: org.apache.spark.sql.DataFrame = [id: bigint, userid: decimal(20,0) ... 2 more fields]
scala> filterDF.write.parquet("hdfs://localhost:9000/tmp/userpay")
查看hdfs:
[root@host ~]# hdfs dfs -ls /tmp/userpay
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/root/hadoop/hadoop-2.7.4/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/root/hive/apache-hive-2.1.1/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Found 2 items
-rw-r--r-- 1 root supergroup 0 2018-08-22 17:59 /tmp/userpay/_SUCCESS
-rw-r--r-- 1 root supergroup 211210 2018-08-22 17:59 /tmp/userpay/part-00000-ad2fc643-024c-4c20-ab27-fb05022a0cba-c000.snappy.parquet
将数据保存为其他格式:
scala> filterDF.write.json("/tmp/userpayjson")
scala> filterDF.write.csv("/tmp/userpaycsv")
查看hdfs
[root@host ~]# hdfs dfs -ls /tmp/userpayjson
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/root/hadoop/hadoop-2.7.4/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/root/hive/apache-hive-2.1.1/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Found 2 items
-rw-r--r-- 1 root supergroup 0 2018-08-22 18:14 /tmp/userpayjson/_SUCCESS
-rw-r--r-- 1 root supergroup 1686038 2018-08-22 18:14 /tmp/userpayjson/part-00000-52975166-d91a-45bb-a747-1684e49ecf17-c000.json
[root@host ~]# hdfs dfs -ls /tmp/userpaycsv
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/root/hadoop/hadoop-2.7.4/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/root/hive/apache-hive-2.1.1/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Found 2 items
-rw-r--r-- 1 root supergroup 0 2018-08-22 18:14 /tmp/userpaycsv/_SUCCESS
-rw-r--r-- 1 root supergroup 759695 2018-08-22 18:14 /tmp/userpaycsv/part-00000-b738993e-ca0c-41bc-8e8f-e249990c7cc1-c000.csv
比较发现,parquet格式存储占用空间最少
读取:
scala> val parquetDF=con.read.parquet("/tmp/userpay/part-00000-ad2fc643-024c-4c20-ab27-fb05022a0cba-c000.snappy.parquet")
parquetDF: org.apache.spark.sql.DataFrame = [id: bigint, userid: decimal(20,0) ... 2 more fields]
scala> parquetDF.show
+---+-------+--------+-----+
| id| userid| daynum|money|
+---+-------+--------+-----+
|105|1005754|20171226| 600|
|106|1005751|20171226| 600|
|107|1005761|20171226| 600|
|108|1005843|20171226| 3000|
|109|1005788|20171226| 600|
|110|1005798|20171226| 600|
|111|1005819|20171226| 600|
|112|1005795|20171226| 600|
|113|1005834|20171226| 600|
|114|1005769|20171226| 3000|
|115|1005809|20171226| 600|
|116|1005829|20171226| 600|
|117|1005856|20171226| 600|
|118|1005793|20171226| 600|
|119|1005826|20171226| 600|
|120|1005806|20171226| 600|
|121|1005917|20171226| 600|
|122|1005857|20171226| 600|
|123|1005937|20171226| 3000|
|124|1005891|20171226| 600|
+---+-------+--------+-----+
only showing top 20 rows
Executor之间如何共享数据
通过HDFS
Spark累加器的特点:
累加器在全局唯一的,只增不减,记录全局集群的唯一状态;在Executor中修改它,在driver读取;executor级别共享的,而广播变量是task级别的共享;两个application不可以共享累加器,但是同一个app不同的job可以共享
*只要是改变每一行列的数据,一般都是用Map操作
*RangePartitioner主要是依赖的RDD的数据划分成不同的范围,关键的地方是不同的范围是有序的
*Google的面试题:如何在一个不确定数据规模的范围内进行排序?(rangePartitioner的水塘抽样算法)
*HashPartitioner最大的弊端是:数据倾斜!!!极端情况下某(几)个分区拥有RDD的所有数据。
*RangePartitioner除了是结果有序的基石外,最为重要的是尽量保证每个Partition中的数据量是均匀的。
RangePartitioner分区则尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,也就是说一个分区中的元素肯定都是比另一个分区内的元素小或者大;但是分区内的元素是不能保证顺序的。简单的说就是将一定范围内的数映射到某一个分区内。其原理是水塘抽样
Spark应用程序的执行过程
1)构建Spark Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源;
2).资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上;
3).SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
4).Task在Executor上运行,运行完毕释放所有资源。
描述Yarn执行一个任务的过程
1)客户端client向ResouceManager提交Application,ResouceManager接受Application
并根据集群资源状况选取一个node来启动Application的任务调度器driver(ApplicationMaster)
2)ResouceManager找到那个node,命令其该node上的nodeManager来启动一个新的
JVM进程运行程序的driver(ApplicationMaster)部分,driver(ApplicationMaster)启动时会首先向ResourceManager注册,说明由自己来负责当前程序的运行
3)driver(ApplicationMaster)开始下载相关jar包等各种资源,基于下载的jar等信息决定向ResourceManager申请具体的资源内容。
4)ResouceManager接受到driver(ApplicationMaster)提出的申请后,会最大化的满足
资源分配请求,并发送资源的元数据信息给driver(ApplicationMaster);
5)driver(ApplicationMaster)收到发过来的资源元数据信息后会根据元数据信息发指令给具体
机器上的NodeManager,让其启动具体的container。
6)NodeManager收到driver发来的指令,启动container,container启动后必须向driver(ApplicationMaster)注册。
7)driver(ApplicationMaster)收到container的注册,开始进行任务的调度和计算,直到
任务完成。
Yarn中的container是由谁负责销毁的
ApplicationMaster负责销毁,在Hadoop Mapreduce不可以复用,在spark on yarn程序container可以复用
.提交任务时,如何指定Spark Application的运行模式?
1)cluster模式:./spark-submit --class xx.xx.xx --master yarn --deploy-mode cluster xx.jar
2) client模式:./spark-submit --class xx.xx.xx --master yarn --deploy-mode client xx.jar
不启动Spark集群Master和work服务,可不可以运行Spark程序
可以,只要资源管理器第三方管理就可以,如由yarn管理,spark集群不启动也可以使用spark;spark集群启动的是work和master,这个其实就是资源管理框架,yarn中的resourceManager相当于master,NodeManager相当于worker,做计算是Executor,和spark集群的work和manager可以没关系,归根接底还是JVM的运行,只要所在的JVM上安装了spark就可以。
spark on yarn Cluster 模式下,ApplicationMaster和driver是在同一个进程,driver 位于ApplicationMaster进程中。该进程负责申请资源,还负责监控程序、资源的动态情况。
查看yarn进程日志
yarn logs -applicationId <app ID>
谈谈你对container的理解?
1)Container作为资源分配和调度的基本单位,其中封装了的资源如内存,CPU,磁盘,网络带宽等。 目前yarn仅仅封装内存和CPU
2)Container由ApplicationMaster向ResourceManager申请的,由ResouceManager中的资源调度器异步分配给ApplicationMaster
3) Container的运行是由ApplicationMaster向资源所在的NodeManager发起的,Container运行时需提供内部执行的任务命令.
Spark on Yarn架构 要能画出来
ResourceManager(RM)
ResourceManager负责集群资源的统一管理和调度,承担了 JobTracker 的角色,整个集群只有“一个”,总的来说,RM有以下作用:
1.处理客户端请求
2.启动或监控ApplicationMaster
3.监控NodeManager
4.资源的分配与调度
NodeManager(NM)
NodeManager管理YARN集群中的每个节点。NodeManager 提供针对集群中每个节点的服务,从监督对一个容器的终生管理到监视资源和跟踪节点健康。
1.管理单个节点上的资源
2.处理来自ResourceManager的命令
3.处理来自ApplicationMaster的命令
ApplicationMaster(AM)
每个应用有一个,负责应用程序的管理 。ApplicationMaster 负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器的执行和资源使用(CPU、内存等的资源分配)。请注意,尽管目前的资源更加传统(CPU 核心、内存),但未来会支持新资源类型(比如图形处理单元或专用处理设备)。AM有以下作用:
1.负责数据的切分
2.为应用程序申请资源并分配给内部的任务
3.任务的监控与容错
Container
Container 是 YARN 中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
Container有以下作用:
对任务运行环境进行抽象,封装CPU、内存等多维度的资源以及环境变量、启动命令等任务运行相关的信息
Executor启动时,资源通过哪几个参数指定?
1)num-executors是executor的数量
2)executor-memory 是每个executor使用的内存
3)executor-cores 是每个executor分配的CPU
画Spark的工作模式
画图讲解spark工作流程
讲讲shuffle的过程
BlockManager怎么管理硬盘和内存的
Spark性能优化主要有哪些手段
简要描述Spark分布式集群搭建的步骤
对于Spark你觉得他对于现有大数据的现状的优势和劣势在哪里
函数式编程特点
spark用户提交的任务成为application,一个application对应一个sparkcontext,app中存在多个job,每触发一次action操作就会产生一个job
这些job可以并行或串行执行,每个job中有多个stage,stage是shuffle过程中DAGSchaduler通过RDD之间的依赖关系划分job而来的,每个stage里面有多个task,组成taskset有TaskSchaduler分发到各个executor中执行,executor的生命周期是和app一样的,即使没有job运行也是存在的,所以task可以快速启动读取内存进行计算,spark的迭代计算都是在内存中进行的,API中提供了大量的RDD操作如join,groupby等,而且通过DAG图可以实现良好的容错
spark:spark的shuffle是在DAGSchedular划分Stage的时候产生的,TaskSchedule要分发Stage到各个worker的executor,减少shuffle可以提高性能
hive: 表(数据+元数据)。 存的是和hdfs的映射关系,hive是逻辑上的数据仓库,实际操作的都是hdfs上的文件,HQL就是用sql语法来写的mr程序。
Sqoop工作原理是什么?
hadoop生态圈上的数据传输工具。
可以将关系型数据库的数据导入非结构化的hdfs、hive或者bbase中,也可以将hdfs中的数据导出到关系型数据库或者文本文件中。
使用的是mr程序来执行任务,使用jdbc和关系型数据库进行交互。
import原理:通过指定的分隔符进行数据切分,将分片传入各个map中,在map任务中在每行数据进行写入处理没有reduce。
export原理:根据要操作的表名生成一个java类,并读取其元数据信息和分隔符对非结构化的数据进行匹配,多个map作业同时执行写入关系型数据库
22、RDD机制?
rdd分布式弹性数据集,简单的理解成一种数据结构,是spark框架上的通用货币。
所有算子都是基于rdd来执行的,不同的场景会有不同的rdd实现类,但是都可以进行互相转换。
rdd执行过程中会形成dag图,然后形成lineage保证容错性等。
从物理的角度来看rdd存储的是block和node之间的映射。
18、spark有哪些组件?
(1)master:管理集群和节点,不参与计算。
(2)worker:计算节点,进程本身不参与计算,和master汇报。
(3)Driver:运行程序的main方法,创建spark context对象。
(4)spark context:控制整个application的生命周期,包括dagsheduler和task scheduler等组件。
(5)client:用户提交程序的入口。
Spark Streaming和Storm有何区别?
一个实时毫秒一个准实时亚秒,不过storm的吞吐率比较低。
shuffle举例:
rdd1 = someRdd.reduceByKey(...)
rdd2 = someOtherRdd.reduceByKey(...)
rdd3 = rdd1.join(rdd2)
由于使用redcuebykey的时候没有指定分区器,所以都是使用的默认分区器,会导致rdd1和rdd2都采用的是hash分区器。两个reducebykey操作会产生两个shuffle过程。如果,数据集有相同的分区数,执行join操作的时候就不需要进行额外的shuffle。由于数据集的分区相同,因此rdd1的任何单个分区中的key集合只能出现在rdd2的单个分区中。 因此,rdd3的任何单个输出分区的内容仅取决于rdd1中单个分区的内容和rdd2中的单个分区,并且不需要第三个shuffle。
在join的过程中为了避免shuffle,可以使用广播变量。当executor内存可以存储数据集,在driver端可以将其加载到一个hash表中,然后广播到executor。然后,map转换可以引用哈希表来执行查找。
有时候需要打破最小化shuffle次数的规则。当增加并行度的时候,额外的shuffle是有利的。例如,数据中有一些文件是不可分割的,那么该大文件对应的分区就会有大量的记录,而不是说将数据分散到尽可能多的分区内部来使用所有已经申请cpu。在这种情况下,使用reparition重新产生更多的分区数,以满足后面转换算子所需的并行度,这会提升很大性能。
在对大量分区执行聚合的时候,在driver的单线程中聚合会成为瓶颈。要减driver的负载,可以首先使用reducebykey或者aggregatebykey执行一轮分布式聚合,同时将结果数据集分区数减少。实际思路是首先在每个分区内部进行初步聚合,同时减少分区数,然后再将聚合的结果发到driver端实现最终聚合。典型的操作是treeReduce 和 treeAggregate。
当聚合已经按照key进行分组时,此方法特别适用。例如,假如一个程序计算语料库中每个单词出现的次数,并将结果使用map返回到driver。一种方法是可以使用聚合操作完成在每个分区计算局部map,然后在driver中合并map。可以用aggregateByKey以完全分布的方式进行统计,然后简单的用collectAsMap将结果返回到driver。
RDD分布式数据集的五大特性
1),A list of partitions(一系列的分区)
2),A function for computing each split(计算每个分片的方法)
3),A list of dependencies on other RDDs(一系列的依赖RDD)
4),Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
(可选,对于key-value类型的RDD都会有一个分区器)
5),Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)(可选,最佳位置)
RDD的计算
RDD的计算实际上我们可以分为两个大部分:
1),Driver端的计算
主要是stage划分,task的封装,task调度执行
2),Executor端的计算
真正的计算开始,默认情况下每个cpu运行一个task。一个task实际上就是一个分区,我们的方法无论是转换算子里封装的,还是action算子里封装的都是此时在一个task里面计算一个分区的数据。
针对foreach方法,是我们的方法被传入了迭代器的foreach(每个元素遍历执行一次函数),
而对于foreachpartiton方法是迭代器被传入了我们的方法(每个分区执行一次函数,我们获取迭代器后需要自行进行迭代处理,也即上述第二个demo的partition.foreach)。
master URLs
master可以是以下几种:
|
Master URL |
含义 |
|
local |
Spark单线程本地跑 |
|
local[K] |
Spark K个工作线程本地跑 |
|
local[K,F] |
K个工作线程,F次失败尝试 |
|
local[*] |
Cup核数个工作线程,本地 |
|
local[*,F] |
Cup核数个工作线程,F次失败尝试 |
|
spark://HOST:PORT |
Standalone cluster master |
|
spark://HOST1:PORT1,HOST2:PORT2 |
基于zk做了HA |
|
mesos://HOST:PORT |
Mesos cluster. |
|
yarn |
基于yarn的client或者cluster模式 |
所谓谓词(predicate),英文定义是这样的:A predicate is a function that returns bool (or something that can be implicitly converted to bool),也就是返回值是true或者false的函数,使用过scala或者spark的同学都知道有个filter方法,这个高阶函数传入的参数就是一个返回true或者false的函数。如果是在sql语言中,没有方法,只有表达式,where后边的表达式起的作用正是过滤的作用,而这部分语句被sql层解析处理后,在数据库内部正是以谓词的形式呈现的。
spark架构

以spark为核心的生态圈,最底层是分布式存储系统如hdfs,Amazon s3,Hypertable以及其他格式的存储系统如hbase等,资源管理采用yarn,mesos等集群管理模式,或者自带的standalone独立运行模式以及local模式,在大数据架构中,spark为上层多种应用提供服务,spark sql,spark steaming,mlib,graphx
spark的特点:基于内存计算,速度快;易用,支持java,python,scala等多种语言;通用,可以与sql,streaming以及复杂的分析结合,有一系列的高级工具;有效集成hadoop,或者其他分布式系统
spark的应用场景:快速查询系统;实施日志采集系统;机器学习;图计算
spark 集 结构化数据(spark sql),处理实时数据的spark streaming,机器学习(mllib),图计算graphx,用于统计分析的sparkR与一身,高度整合。
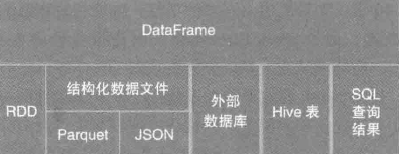
spark sql是处理结构化数据的一个模块,提供了一个dataframe的编程抽象。可以看做是一个分布式查询引擎,主要由catalyst优化, spark sql内核,hive支持三部分组成。dataframe是以指定列组织的分布式集合,相当于关系数据库的一张表。
dataframe支持多种数据源构建:
集群相关概念
def pipe(command: Seq[String],env: scala.collection.Map[String,String],printPipeContext: (String => Unit) => Unit,printRDDElement: (Int, String => Unit) => Unit,separateWorkingDir: Boolean,bufferSize: Int,encoding: String): org.apache.spark.rdd.RDD[String]
def pipe(command: String,env: scala.collection.Map[String,String]): org.apache.spark.rdd.RDD[String]
def pipe(command: String): org.apache.spark.rdd.RDD[String]
pipe通过一个shell命令
scala> val jj=sc.makeRDD(1 to 100)scala> jj.pipe("ls /root ").collect
res16: Array[String] = Array(10, aaa, aaa;, anaconda-ks.cfg, apache-ant-1.10.3, app, custtmp, dbbak, DBD-mysql-4.029, DBD-mysql-4.029.tar.gz, db.sql, derby.log, hadoop, hbase-1.4.4, hbase-2.0.0, hbasedatadir, hdfs, hdfs:, hive, install.log, install.log.syslog, ip.txt, localhost, metastore_db, myshell, mysql, mysql-connector-java-5.1.39.jar, pig, pig_1529372711098.log, pig_1529394265679.log, profile, project, QueryResult.java, role1.java, role.java, sbt-0.13.15.tgz, sbt-launch.jar, scala, scala-2.12.3.tgz, shellcode, shellfile, software, spark, spark-2.2.0-bin-hadoop2.7.tgz, sparkapp, spark_ceshi, sparktest, sqoop, sqoop1, ${system:java.io.tmpdir}, target, tmpdata, zookeeper1, zookeeper-3.4.12, zookeeper.out, 10, aaa, aaa;, anaconda-ks.cfg, apache-ant-1.10.3, app, custtmp, dbbak, DBD-mys...
jj: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[19] at makeRDD at <console>:24
缓存:集群中没有足够的内存的时候,spark会根据缓存情况确定一个LRU(least recently used,最近使用最少算法)将缓存分区数据进行删除。手动删除则采用unpersist
spark基本组件
负责集群运行的master,worker;负责作业运行的client和driver;负责资源管理的管理器(如yarn)以及执行单元(executor)等
从架构层面上说,每个spark application都有控制集群的主控节点master,负责集群资源管理的cluster manager,执行具体任务的worker节点和执行单元executor,负责作业提交的client端和负责作业控制的driver进程组成。
sparkclient负责任务的提交,driver进程通过运行用户的main函数,在集群上执行各种并发操作和计算。其中sparkcontext是应用程序与集群交互的唯一通道,主要包括:获取数据,交互操作,分析和构建dag图,通过scheduler调度任务,block跟踪,shuffle跟踪等
用户client提交一个程序给driver后,driver会将所有rdd依赖关联到一起绘制成一张DAG图;运行任务时,调度scheduler会配合组件block tracker和shuffle tracker进行工作;通过clustermanager进行资源统一调配;具体任务在worder进点运行,由task线程池负责具体任务执行,线程池通过多个task运行任务。由blockmanager进行存储管理,数据在内存中可以保存多份,一方面进行备份,另一份支持retrytask和stragglingtask快速恢复。
提交作业的两种方式:dirver运行在集群中,dirver运行在客户端
无论基于哪种运行模式,基础概念是一致的
stage,一个spark作业一般包含一个到多个stage
task,一个stage包含一到多个task,通过多个task实行并行运行的功能。
dagscheduler,实现净spark作业分解成一到多个stage,每个stage根据RDD的partition个数决定task的个数,然后生成相应的taskset放到taskscheduler中。
基于standalone模式的spark架构
这两种运行方式通过--deploy-mode进行配置,默认为client模式.
在整个框架下各个进程角色如下:
master主控节点,负责接收client提交的作业,管理worker,并命令worker启动driver和executor.
worker:slave节点上的守护进程,负责管理本节点上的资源,并定时想master汇报心跳,接收master的命令,启动driver和executor.
client,客户端进程,负责提交作业到master.
dirver,一个spark作业运行时包括一个driver进程,也是作业的主进程。负责dag图的构建,stage的划分,task任务的管理以及调度生成schedulerbackend用于akka通信,主要组件包括dagscheduler,taskscheduler,schedulerbackend.
executer:执行作业的地方,每个application一般会对应多个worker,但一个application在每个worker上只产生一个executor进程,每个executor进程接受driver的命令launchtask,一个executor可以执行一到多个task.
spark sql表分区是一种常用的优化手段
scala> val df1=sc.makeRDD(1 to 5).map(x=>(x,x*2)).toDF("single","double")
df1: org.apache.spark.sql.DataFrame = [single: int, double: int]
scala> val df2=sc.makeRDD(6 to 10).map(x=>(x,x*3)).toDF("single","triple")
df2: org.apache.spark.sql.DataFrame = [single: int, triple: int]
//存储df1到一个分区目录
scala> df1.write.parquet("/sparksql/test_table/key=1")
//存储df2到一个分区目录
scala> df2.write.parquet("/sparksql/test_table/key=2")
scala> import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.SQLContext
scala> val sqlcon=new SQLContext(sc)
warning: there was one deprecation warning; re-run with -deprecation for details
sqlcon: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@2f1a19b1
//读取分区表。
scala> val df=sqlcon.read.option("mergeSchema","true").parquet("/sparksql/test_table")
df: org.apache.spark.sql.DataFrame = [single: int, double: int ... 2 more fields]
scala> df.show
+------+------+------+---+
|single|double|triple|key|
+------+------+------+---+
| 6| null| 18| 2|
| 7| null| 21| 2|
| 8| null| 24| 2|
| 9| null| 27| 2|
| 10| null| 30| 2|
| 1| 2| null| 1|
| 2| 4| null| 1|
| 3| 6| null| 1|
| 4| 8| null| 1|
| 5| 10| null| 1|
+------+------+------+---+
scala> df.printSchema
root
|-- single: integer (nullable = true)
|-- double: integer (nullable = true)
|-- triple: integer (nullable = true)
|-- key: integer (nullable = true)
------------------------------------------------------------
scala> val df2=sc.makeRDD(6 to 10,2).map(x=>(x,x*3)).toDF("single","double")
df2: org.apache.spark.sql.DataFrame = [single: int, double: int]
scala> val df1=sc.makeRDD(1 to 5,2).map(x=>(x,x*2)).toDF("single","double")
df1: org.apache.spark.sql.DataFrame = [single: int, double: int]
scala> df1.write.parquet("/sparksql/test_table/key=1")
scala> df2.write.parquet("/sparksql/test_table/key=2")
scala> import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.SQLContext
scala> val sqlcon=new SQLContext(sc)
warning: there was one deprecation warning; re-run with -deprecation for details
sqlcon: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@15b2f467
scala> val df=sqlcon.read.option("mergeSchema","true").parquet("/sparksql/test_table")
df: org.apache.spark.sql.DataFrame = [single: int, double: int ... 1 more field]
scala> df.show
+------+------+---+
|single|double|key|
+------+------+---+
| 8| 24| 2|
| 9| 27| 2|
| 10| 30| 2|
| 3| 6| 1|
| 4| 8| 1|
| 5| 10| 1|
| 6| 18| 2|
| 7| 21| 2|
| 1| 2| 1|
| 2| 4| 1|
+------+------+---+
parquet数据源自动从文件路径中找到了key这个分区列,并且正确合并了两个不相同但相容的schema,如果查询条件跳过了key=1的分区,spark查询优化器会根据查询条件将该分区目录剪掉,完全不扫描该目录的数据。
查看hdfs:
[root@host ~]# hdfs dfs -ls -R /sparksql
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/root/hadoop/hadoop-2.7.4/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/root/hive/apache-hive-2.1.1/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
drwxr-xr-x - root supergroup 0 2018-08-28 16:42 /sparksql/test_table
drwxr-xr-x - root supergroup 0 2018-08-28 16:42 /sparksql/test_table/key=1
-rw-r--r-- 1 root supergroup 0 2018-08-28 16:42 /sparksql/test_table/key=1/_SUCCESS
-rw-r--r-- 1 root supergroup 552 2018-08-28 16:42 /sparksql/test_table/key=1/part-00000-e300fef1-400d-400a-8f6b-2f7ce133d033-c000.snappy.parquet
-rw-r--r-- 1 root supergroup 560 2018-08-28 16:42 /sparksql/test_table/key=1/part-00001-e300fef1-400d-400a-8f6b-2f7ce133d033-c000.snappy.parquet
drwxr-xr-x - root supergroup 0 2018-08-28 16:42 /sparksql/test_table/key=2
-rw-r--r-- 1 root supergroup 0 2018-08-28 16:42 /sparksql/test_table/key=2/_SUCCESS
-rw-r--r-- 1 root supergroup 552 2018-08-28 16:42 /sparksql/test_table/key=2/part-00000-eb15514c-72da-4ec0-a0c1-896f25b201fd-c000.snappy.parquet
-rw-r--r-- 1 root supergroup 560 2018-08-28 16:42 /sparksql/test_table/key=2/part-00001-eb15514c-72da-4ec0-a0c1-896f25b201fd-c000.snappy.parquet
spark基础知识介绍2的更多相关文章
- spark基础知识介绍(包含foreachPartition写入mysql)
数据本地性 数据计算尽可能在数据所在的节点上运行,这样可以减少数据在网络上的传输,毕竟移动计算比移动数据代价小很多.进一步看,数据如果在运行节点的内存中,就能够进一步减少磁盘的I/O的传输.在spar ...
- 最全的spark基础知识解答
原文:http://www.36dsj.com/archives/61155 一. Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduc ...
- Nginx基础知识介绍
Nginx基础知识介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Nginx概述 Nginx是免费的.开源的.高性能的HTTP和正向/反向代理服务器.邮件代理服务器.以及T ...
- TCP_Wrappers基础知识介绍
1. TCP_Wrappers基础知识介绍 TCP_Wrappers是在 Solaris, HP_UX以及 Linux中广泛流行的免费软件.它被设计为一个介于外来服务请求和系统服务回应的中间处理软件. ...
- Swift Playgrounds for mac基础知识介绍
Swift Playgrounds是一款适用于iPad和Mac的革命性应用程序,它使Swift学习变得互动而有趣.它不需要编码知识,因此非常适合刚开始的学生.使用Swift解决难题,以掌握基本知识.S ...
- WPF Step By Step -基础知识介绍
回顾 上一篇我们介绍了WPF基本的知识.并且介绍了WPF与winform传统的cs桌面应用编程模式上的变化,这篇,我们将会对WPF的一些基础的知识做一个简单的介绍,关于这些基础知识更深入的应用则在后续 ...
- python基础----基础知识介绍
一 编程语言的划分 编译型:将代码一次性全部编译成二进制,然后运行. 缺点:开发效率低,不能跨平台(windows与linux) 优点:执行效率高 代表语言:c语言 解释型:当程序开始运 ...
- android开发学习---linux下开发环境的搭建&& android基础知识介绍
一.配置所需开发环境 1.基本环境配置 JDK 5或以上版本(仅有JRE不够) (http://www.oracle.com/technetwork/java/javase/downloads/ind ...
- Linux基础知识介绍
1.Linux知识说明1)文件位置 1)/etc/inittab2)模式介绍 0:挂起模式-不推荐 1:单用户模式-只有管理员可以进入该模式,可以修改root密码,处理有登录权限而没有修改文件的权限问 ...
随机推荐
- 【转】C# 开发Chrome内核浏览器(WebKit.net)
WebKit.net是对WebKit的.Net封装,使用它.net程序可以非常方便的集成和使用webkit作为加载网页的容器.这里介绍一下怎么用它来显示一个网页这样的一个最简单的功能. 第一步: 下载 ...
- PHP 函数获取文件名
<?php // php 获取 文件名 function getExt($url){ $arr = parse_url($url); // URL 字符串予以解析,并将结果返回数组中 //pr ...
- Python单元测试框架之pytest 1 ---如何执行测试用例
From: https://www.cnblogs.com/fnng/p/4765112.html 介绍 pytest是一个成熟的全功能的Python测试工具,可以帮助你写出更好的程序. 适合从简 ...
- Lucene 4.8 - Facet Demo
package com.fox.facet; /* * Licensed to the Apache Software Foundation (ASF) under one or more * con ...
- bzoj4814: [Cqoi2017]小Q的草稿
Description 小Q是个程序员.众所周知,程序员在写程序的时候经常需要草稿纸.小Q现在需要一张草稿纸用来画图,但是桌上 只有一张草稿纸,而且是一张被用过很多次的草稿纸.草稿纸可以看作一个二维平 ...
- Git revert及其他一些回退操作
放弃本地的代码和本地提交,希望会退到远程分支的某次提交时,使用git reset --hard fa042ce. 本地已提交,但是发现有问题,想要撤销本地的提交,使用git checkout /trs ...
- CVE-2017-8570漏洞利用
CVE-2017-8570漏洞是一个逻辑漏洞,利用方法简单,影响范围广.由于该漏洞和三年前的SandWorm(沙虫)漏洞非常类似,因此我们称之为“沙虫”二代漏洞. 编号 CVE-2017-8570 影 ...
- module 'pip' has no attribute 'pep425tags'
AMD64 import pip._internal print(pip._internal.pep425tags.get_supported()) 1 2 WIN32 import pip prin ...
- Shiro 权限注解
Shiro 权限注解: Shiro 提供了相应的注解用于权限控制,如果使用这些注解就需要使用AOP 的功能来进行 判断,如Spring AOP:Shiro 提供了Spring AOP 集成用于 ...
- for练习.html
<script> 偶数 var str=""; for (var i = 1 ; i <= 100; i++){ if (i%2 == 0) { //str = ...