机器学习-文本数据-文本的相关性矩阵 1.cosing_similarity(用于计算两两特征之间的相关性)
函数说明:
1. cosing_similarity(array) 输入的样本为array格式,为经过词袋模型编码以后的向量化特征,用于计算两两样本之间的相关性
当我们使用词频或者TFidf构造出词袋模型,并对每一个文章内容做词统计以后,
我们如果要判断两个文章内容的相关性,这时候我们需要对数字映射后的特征做一个余弦相似度的匹配:即a.dot(b) / sqrt(a^2 + b^2)
在sklearn中使用metrics.pairwise import cosine_similarity
代码:
第一步: 对数据使用DataFrame化,并进行数组化
第二步:对数据进行分词,并去除停用词,使用' '.join连接列表
第三步:np.vectorizer向量化函数,调用函数进行分词和停用词的去除
第四步:使用TF-idf词袋模型,对特征进行向量化数字映射
第五步:使用 from sklearn.metrics.pairwise import cosine_similarity, 对两两样本之间做相关性矩阵,使用的是余弦相似度计算公式
import pandas as pd
import numpy as np
import re
import nltk #pip install nltk corpus = ['The sky is blue and beautiful.',
'Love this blue and beautiful sky!',
'The quick brown fox jumps over the lazy dog.',
'The brown fox is quick and the blue dog is lazy!',
'The sky is very blue and the sky is very beautiful today',
'The dog is lazy but the brown fox is quick!'
] labels = ['weather', 'weather', 'animals', 'animals', 'weather', 'animals'] # 第一步:构建DataFrame格式数据
corpus = np.array(corpus)
corpus_df = pd.DataFrame({'Document': corpus, 'categoray': labels}) # 第二步:构建函数进行分词和停用词的去除
# 载入英文的停用词表
stopwords = nltk.corpus.stopwords.words('english')
# 建立词分割模型
cut_model = nltk.WordPunctTokenizer()
# 定义分词和停用词去除的函数
def Normalize_corpus(doc):
# 去除字符串中结尾的标点符号
doc = re.sub(r'[^a-zA-Z0-9\s]', '', string=doc)
# 是字符串变小写格式
doc = doc.lower()
# 去除字符串两边的空格
doc = doc.strip()
# 进行分词操作
tokens = cut_model.tokenize(doc)
# 使用停止用词表去除停用词
doc = [token for token in tokens if token not in stopwords]
# 将去除停用词后的字符串使用' '连接,为了接下来的词袋模型做准备
doc = ' '.join(doc) return doc # 第三步:向量化函数和调用函数
# 向量化函数,当输入一个列表时,列表里的数将被一个一个输入,最后返回也是一个个列表的输出
Normalize_corpus = np.vectorize(Normalize_corpus)
# 调用函数进行分词和去除停用词
corpus_norm = Normalize_corpus(corpus) # 第四步:使用TfidVectorizer进行TF-idf词袋模型的构建
from sklearn.feature_extraction.text import TfidfVectorizer Tf = TfidfVectorizer(use_idf=True)
Tf.fit(corpus_norm)
vocs = Tf.get_feature_names()
corpus_array = Tf.transform(corpus_norm).toarray()
corpus_norm_df = pd.DataFrame(corpus_array, columns=vocs)
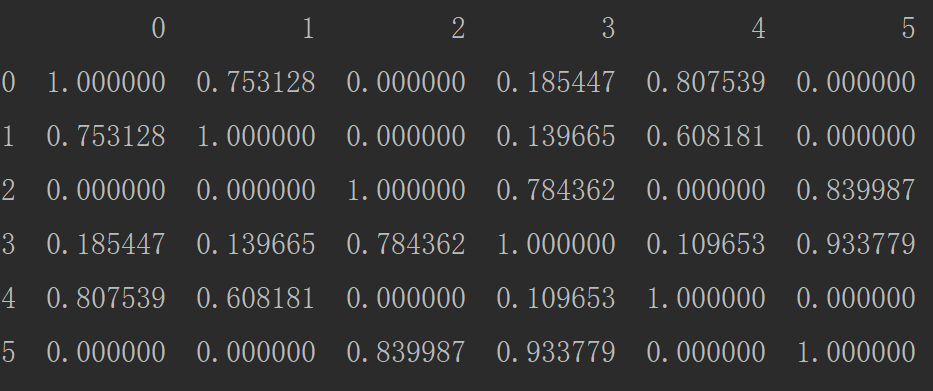
print(corpus_norm_df.head()) from sklearn.metrics.pairwise import cosine_similarity similarity_matrix = cosine_similarity(corpus_array)
similarity_matrix_df = pd.DataFrame(similarity_matrix)
print(similarity_matrix_df)
机器学习-文本数据-文本的相关性矩阵 1.cosing_similarity(用于计算两两特征之间的相关性)的更多相关文章
- Python机器学习之数据探索可视化库yellowbrick
# 背景介绍 从学sklearn时,除了算法的坎要过,还得学习matplotlib可视化,对我的实践应用而言,可视化更重要一些,然而matplotlib的易用性和美观性确实不敢恭维.陆续使用过plot ...
- R如何检验类别变量(nominal variable)与其他变量之间的相关性
1.使用Pearson积差相关系性进行检验的话可以判断两个变量之间的相关性是否显著以及相关性的强度 显著性检验 (significant test) 连续变量 vs 类别变量 (continuous ...
- 机器学习入门-文本数据-构造词频词袋模型 1.re.sub(进行字符串的替换) 2.nltk.corpus.stopwords.words(获得停用词表) 3.nltk.WordPunctTokenizer(对字符串进行分词操作) 4.np.vectorize(对函数进行向量化) 5. CountVectorizer(构建词频的词袋模型)
函数说明: 1. re.sub(r'[^a-zA-Z0-9\s]', repl='', sting=string) 用于进行字符串的替换,这里我们用来去除标点符号 参数说明:r'[^a-zA-Z0- ...
- NLP相关问题中文本数据特征表达初探
1. NLP问题简介 0x1:NLP问题都包括哪些内涵 人们对真实世界的感知被成为感知世界,而人们用语言表达出自己的感知视为文本数据.那么反过来,NLP,或者更精确地表达为文本挖掘,则是从文本数据出发 ...
- 文本数据预处理:sklearn 中 CountVectorizer、TfidfTransformer 和 TfidfVectorizer
文本数据预处理的第一步通常是进行分词,分词后会进行向量化的操作.在介绍向量化之前,我们先来了解下词袋模型. 1.词袋模型(Bag of words,简称 BoW ) 词袋模型假设我们不考虑文本中词与词 ...
- scikit-learning教程(三)使用文本数据
使用文本数据 本指南的目标是探讨scikit-learn 一个实际任务中的一些主要工具:分析二十个不同主题的文本文档(新闻组帖子)集合. 在本节中,我们将看到如何: 加载文件内容和类别 提取适用于机器 ...
- 如何使用 scikit-learn 为机器学习准备文本数据
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 文本数据需要特殊处理,然后才能开始将其用于预测建模. 我们需要解析文本,以删除被称为标记化的单词.然后,这些词还需要被编码为整型或浮点型,以用作 ...
- Bulk Insert:将文本数据(csv和txt)导入到数据库中
将文本数据导入到数据库中的方法有很多,将文本格式(csv和txt)导入到SQL Server中,bulk insert是最简单的实现方法 1,bulk insert命令,经过简化如下 BULK INS ...
- C#大数据文本高效去重
C#大数据文本高效去重 转载请注明出处 http://www.cnblogs.com/Huerye/ TextReader reader = File.OpenText(@"C:\Users ...
随机推荐
- bzoj5050: 建造摩天楼
Description 属于小Q管辖的n座摩天楼从左往右排成一排,编号依次为1到n,第i座摩天楼的高度为h_i.小Q会进行m次以下两种 操作之一: 2 l r,询问h_l+h_{l+1}+...+h_ ...
- bzoj 4866: [Ynoi2017]由乃的商场之旅
设第i个字母的权值为1<<i,则一个可重集合可以重排为回文串,当且仅当这个集合的异或和x满足x==x&-x,用莫队维护区间内有多少对异或前缀和,异或后满足x==x&-x,这 ...
- requests 请求几个接口 出现’您的账户在其它设备使用过,为保障安全,需重新登入才能在本设备使用‘
因为接口和接口直接有个字段是关联的 在登陆请求后,后台响应了个token,下面的请求 ,请求头要带上这个token 才认为是登陆后 的操作
- IDC:IDC(互联网数据中心)
ylbtech-IDC:IDC(互联网数据中心) IDC为互联网内容提供商(ICP).企业.媒体和各类网站提供大规模.高质量.安全可靠的专业化服务器托管.空间租用.网络批发带宽以及ASP.EC等业务. ...
- 在linux下sh批处理文件调用java的方法
解密 java -classpath collection-impl-0.0.1.jar com.ai.toptea.collection.message.DESEncrypt 1EFE4663895 ...
- jQuery插件制作之全局函数用法实例
原文地址:http://www.jb51.net/article/67056.htm 本文实例讲述了jQuery插件制作之全局函数用法.分享给大家供大家参考.具体分析如下: 1.添加新的全局函数 所谓 ...
- MySQL binlog 企业案例升级版
需求:1.创建一个数据库 oldboy2.在oldboy下创建一张表t13.插入5行任意数据4.全备5.插入两行数据,任意修改3行数据,删除1行数据6.删除所有数据7.再t1中又插入5行新数据,修改3 ...
- Linux下的文件操作——基于文件描述符的文件操作(2)
文件描述符的复制 MMAP文件映射 ftruncate修改文件大小 文件描述符的复制 系统调用函数dup和dup2可以实现文件描述符的复制,经常用来重定向进程的stdin(0), stdout(1 ...
- C#一年中有多少周方法和js一年中第几周
最近在做一个时间插件,用的是jquery-daterangepicker ,现在分享一下查询时间是一年中的第几周的js方法 和 一年中有多少周的C#后台方法,默认是按照周一为一周的开始,如果一年的第 ...
- 批处理taskkill运行结束不掉程序以及停留问题
我原来就一句代码 TASKKILL /F /IM QQ.exe 保存为taskkill.bat,结果运行起来一直显示,但是没有结束掉进程,百度搜索才知道taskkill为系统关键字,不能命名为task ...