斯坦福CS229机器学习课程笔记 Part1:线性回归 Linear Regression
机器学习三要素
机器学习的三要素为:模型、策略、算法。
模型:就是所要学习的条件概率分布或决策函数。
线性回归模型
策略:按照什么样的准则学习或选择最优的模型。
最小化均方误差,即所谓的 least-squares(在spss里线性回归对应的模块就叫OLS即Ordinary Least Squares):
算法:基于训练数据集,根据学习策略,选择最优模型的计算方法。
确定模型中每个θi取值的计算方法,往往归结为最优化问题。对于线性回归,我们知道它是有解析解的,即正规方程 The normal equations:
监督学习(Supervised Learning)
SupervisedLearning,Wiki
通过训练资料(包含输入和预期输出的数据集)去学习或者建立一个函数模型,并依此模型推测新的实例。函数的输出可以是一个连续的值(回归问题,Regression),或是预测一个分类标签(分类问题,Classification)。
机器学习中与之对应还有:
无监督学习(Unsupervised Learning)
强化学习(Reinforcement Learning)

在课程中定义了一些符号:
x(i):输入特征(input features)
y(i) :目标变量(target variable)
(x(i),y(i)) :训练样本(training example)
{(x(i),y(i));i=1,...,m} :训练集合(training set)
m :训练样本数量
h :假设函数(hypothesis)
线性回归(Linear Regression)
例子:房屋价格与居住面积和卧室数量的关系
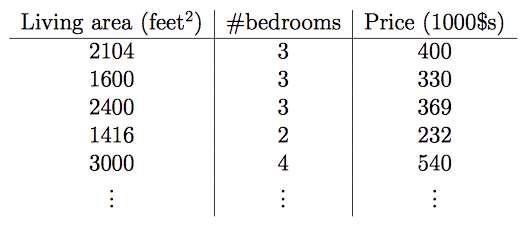
在这里输入特征变成了两个x1,x2,目标变量就是价格
x1: Living area
x2: bedrooms
可以把它们称之为x的二维向量。
在实际情况中,我们需要根据你所选择的特征来进行一个项目的设计。
我们之前已经了解了监督学习,所以需要我们决定我们应该使用什么样的假设函数来进行训练参数。线性函数是最初级,最简单的选择。
所以针对例子假设函数:
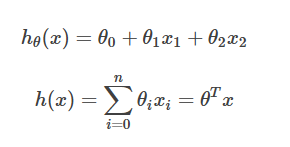
其中的θ就是要训练的参数(也被成为权重),我们想要得到尽可能符合变化规律的参数,使得这个函数可以用来估计价格。
因为要训练θ,所以引入cost function(损失函数/成本函数)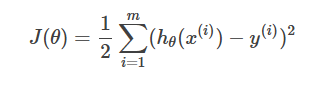
对于线性规划问题,通常J函数(误差平方和)是碗状的,所以往往只会有一个全局最优解,不用过多担心算法收敛到局部最优解。
最小二乘法(LMS algorithm)
课程中的比喻很形象,将用最快的速度最小化损失函数 比作如何最快地下山。也就是每一步都应该往坡度最陡的方向往下走,而坡度最陡的方向就是损失函数相应的偏导数,因此算法迭代的规则是:

其中α是算法的参数learning rate,α越大每一步下降的幅度越大速度也会越快,但过大有可能导致算法无法收敛。
假设只有一个训练样本:(x,
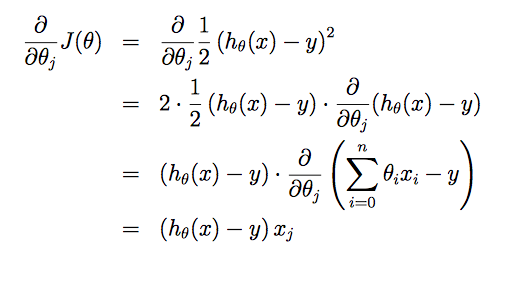
更新函数为:θj:=θj+α(y(i)−hθ(x(i)))x(i)j
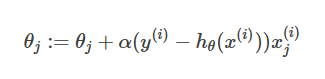
这就是最小二乘法(LMS, least mean squares)更新规则。
梯度下降(gradient descent)
在面对多个样本进行处理时,就需要在此基础上演变更新规则。有两种策略:
批量梯度下降 batch gradient descent 
随机梯度下降 stochastic gradient descent (incremental gradient descent) 
当训练样本量很大时,batch
gradient descent的每一步都要遍历整个训练集,开销极大;而stochastic gradient
descent则只选取其中的一个样本。因此训练集很大时,后者的速度要快于前者。
虽然 stochastic gradient
descent 可能最终不会收敛到最优解(代价函数等于0),大多数情况下都能得到真实最小值的一个足够好的近似。
正规方程组(normal equations)
梯度的矩阵表示

针对矩阵中的每个元素对 f 求导,将导数写在各个元素对应的位置。
矩阵的迹
一个 n×n 矩阵A的主对角线(从左上方至右下方的对角线)上各个元素的总和被称为矩阵A的迹(或迹数),一般记作tr(A)。
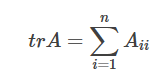

对Normal Equation求解

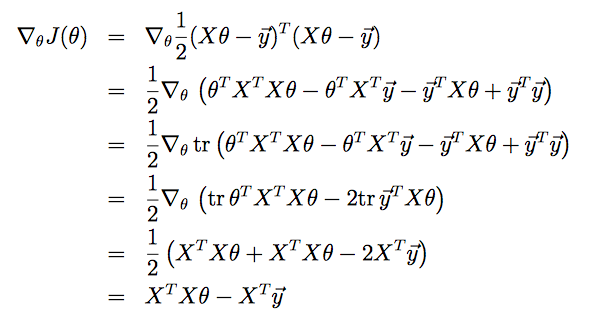
推倒过程利用了矩阵的迹的性质。因为J(θ)是个实数,所以它的迹等于它本身。

线性模型的概率解释(Probabilistic interpretation)
为什么要在回归问题中使用最小二乘法?
首先引入误差(error term)概念,假设:
ε(i) 表示误差项,包含随机因素或未考虑因素。 假设误差满足概率分布,而且满足对应误差项彼此独立(IID, independently and identically distributed)。所以我们直接设 ε(i ) 满足Gaussian分布(正态分布)。ε(i ) ∼ N(0, σ2)
于是可以获得目标变量的条件概率分布:
再引入似然性函数(likelihood function)概念: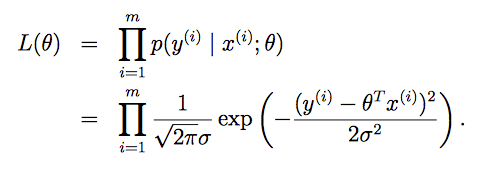
我们需要选择参数θ使得数据出现的可能性尽可能大,即最大化L(θ),这就是极大似然估计(maximum likelihood)。
为了数学计算上的便利,对L(θ)取对数。

因此,最大化对数似然函数,也就相当于最小化
也可以注意到 :δ2 的值不会影响我们的最终结果(因为所求的是θ,只要代价函数最小就可以确定θ的值,δ2是什么值并没有影响)。
局部加权线性回归 (Locally weighted linear regression,LWR)
在线性回归中,使用某个训练样本 x 通过评价h(x)来更新 θ 时,其余样本对更新的贡献是相同的;
在LWR中,使用某个训练样本 x 通过评价h(x)来更新 θ 时,离 x 近的点的重要性更高。
加权函数w的一个选择是指数衰减函数,是一个钟形 bell-shaped曲线,虽然长得像高斯分布,但它不是高斯分布:
|x(i) − x| 越小,距离越近,其权重w(i)越接近1; |x(i) − x|越大,则权重w(i)越小。
τ 被称为bandwidth带宽参数,控制 x(i) 的权重值随着离 x 距离大小而下降的速率。τ越大,下降速度越慢
在调整 θ 的过程中。如果x(i) 权重大,要努力进行拟合 使误差平方项最小。如果权重很小,误差平方项将被忽略。
对新的 x 进行预测时,LWR和线性回归也有区别:
- LWR是一个非参数算法 non-parametric algorithm:对每个新的 x 进行预测时,都需要利用训练集重新做拟合,代价很高(因此有课上的学生质疑这是否称得上是一个模型)。
- 线性回归是一个参数算法:参数个数是有限的,拟合完参数后就可以不考虑训练集,直接进行预测。
欠拟合与过拟合
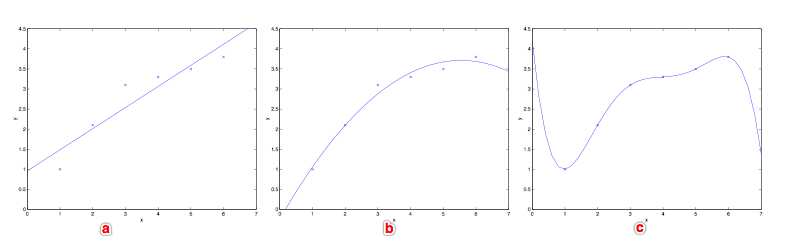
(a)代表了欠拟合(underfitting),(c)代表了过拟合(overfitting),这也说明了在监督学习中特征的选择会对学习算法的性能产生很大的影响。
参数化与非参数化
参数学习算法 Parametric Learning algorithm
始终由固定的参数拟合数据。
如:线性回归(Linear regression)
h(x)
非参数学习算法 Non-parametric Learning algorithm
参数的数量不是恒定的,有时为了更好地实现假设,会随着训练集合数量的变化而线性变化。
如:局部加权回归(Locally weight regression)
h(x)
)
Fit θ to minimize ∑iw(i)(y(i)−θTx(i))2
Output θTx
likelihood 和 probability的区别
probability 强调 y 发生的概率
likelihood 强调给定一组x,y。找到 θ 使 x 条件下 y 发生的几率最大。
参考:
https://blog.csdn.net/TRillionZxY1/article/details/76290919
斯坦福CS229机器学习课程笔记 Part1:线性回归 Linear Regression的更多相关文章
- 斯坦福CS229机器学习课程笔记 part3:广义线性模型 Greneralized Linear Models (GLMs)
指数分布族 The exponential family 因为广义线性模型是围绕指数分布族的.大多数常用分布都属于指数分布族,服从指数分布族的条件是概率分布可以写成如下形式:η 被称作自然参数(nat ...
- 斯坦福CS229机器学习课程笔记 part2:分类和逻辑回归 Classificatiion and logistic regression
Logistic Regression 逻辑回归 1.模型 逻辑回归解决的是分类问题,并且是二元分类问题(binary classification),y只有0,1两个取值.对于分类问题使用线性回归不 ...
- 机器学习 (一) 单变量线性回归 Linear Regression with One Variable
文章内容均来自斯坦福大学的Andrew Ng教授讲解的Machine Learning课程,本文是针对该课程的个人学习笔记,如有疏漏,请以原课程所讲述内容为准.感谢博主Rachel Zhang的个人笔 ...
- Stanford机器学习---第二讲. 多变量线性回归 Linear Regression with multiple variable
原文:http://blog.csdn.net/abcjennifer/article/details/7700772 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- 斯坦福第二课:单变量线性回归(Linear Regression with One Variable)
二.单变量线性回归(Linear Regression with One Variable) 2.1 模型表示 2.2 代价函数 2.3 代价函数的直观理解 I 2.4 代价函数的直观理解 I ...
- TensorFlow 学习笔记(1)----线性回归(linear regression)的TensorFlow实现
此系列将会每日持续更新,欢迎关注 线性回归(linear regression)的TensorFlow实现 #这里是基于python 3.7版本的TensorFlow TensorFlow是一个机器学 ...
- [笔记]机器学习(Machine Learning) - 01.线性回归(Linear Regression)
线性回归属于回归问题.对于回归问题,解决流程为: 给定数据集中每个样本及其正确答案,选择一个模型函数h(hypothesis,假设),并为h找到适应数据的(未必是全局)最优解,即找出最优解下的h的参数 ...
- 斯坦福第四课:多变量线性回归(Linear Regression with Multiple Variables)
4.1 多维特征 4.2 多变量梯度下降 4.3 梯度下降法实践 1-特征缩放 4.4 梯度下降法实践 2-学习率 4.5 特征和多项式回归 4.6 正规方程 4.7 正规方程及不可逆性 ...
- 吴恩达机器学习(二) 单变量线性回归(Linear Regression with one variable)
一.模型表示 1.一些术语 如下图,房价预测.训练集给出了房屋面积和价格,下面介绍一些术语: x:输入变量或输入特征(input variable/features). y:输出变量或目标变量(out ...
随机推荐
- [JS学习笔记]浅谈Javascript事件模型
DOM0级事件模型 element.on[type] = function(){} 兼容性:全部支持 lay1 lay2 lay3 e.target:直接触发事件的元素[IE8及以下不支持tage ...
- JSP的指令
JSP 指令 JSP指令用来设置整个JSP页面相关的属性,如网页的编码方式和脚本语言. 语法格式如下: <%@ directive attribute="value" %&g ...
- Java与数据库数据类型对应表
Java中的数据类型和SQL中的数据类型有很多不一样,需要仔细区分,不然易在开发中造成莫名的错误. Java数据类型 hibernate数据类型 标准SQL数据类型(PS:对于不同的DB可能有所差异) ...
- 6.etc目录下重要文件和目录详解
1./etc/下的重要的配置文件 /etc(二进制软件包的 yum /rpm 安装的软件和所有系统管理所需要的配置文件和子目录.还有安装的服务的启动命令也放置在此处) /etc/sysconfig/n ...
- make命令和makefile文件
make命令和makefile文件的结合提供了一个在项目管理领域十分强大的工具,它不仅常被用于控制源代码的编译,而且还用于手册页的编写以及将应用程序安装到目标目录. makefile文件由一组依赖关系 ...
- verilog数组定义及其初始化
这里的内存模型指的是内存的行为模型.Verilog中提供了两维数组来帮助我们建立内存的行为模型.具体来说,就是可以将内存宣称为一个reg类型的数组,这个数组中的任何一个单元都可以通过一个下标去访问.这 ...
- 学大伟业DAY2模拟赛
T1忍者钩爪 题目描述 小Q是一名酷爱钩爪的忍者,最喜欢飞檐走壁的感觉,有一天小Q发现一个练习使用钩爪的好地方,决定在这里大显身手. 场景的天花板可以被描述为一个无穷长的数轴,初始小Q挂在原点上.数轴 ...
- webpack新版本4.12应用九(配置文件之输出(output))
output 位于对象最顶级键(key),包括了一组选项,指示 webpack 如何去输出.以及在哪里输出你的「bundle.asset 和其他你所打包或使用 webpack 载入的任何内容」. ou ...
- devops 几个方便的工具
1. fake API [canned](https://github.com/sideshowcoder/canned ) fake API. [wiremock](ht ...
- fn project 打包Function
Option 1 (recommended): Use the fn cli tool We recommend using the fn cli tool which will handle a ...