Hadoop伪分布安装详解(二)
目录:
1.修改主机名和用户名
2.配置静态IP地址
3.配置SSH无密码连接
4.安装JDK1.7
5.配置Hadoop
6.安装Mysql
7.安装Hive
8.安装Hbase
9.安装Sqoop
********************
1.修改主机名和用户名
- 修改主机名:Centos中通过vi /etc/sysconfig/network 修改HOSTNAME=

- 为了使Hadoop节点之间能互相访问,需要修改hosts文件,root用户执行并且所有节点均需执行
vi /etc/hosts

- centos修改主机名执行useradd hadoop 添加以Hadoop为用户名的用户,执行passwd hadoop修改用户的密码
2. 配置静态IP地址

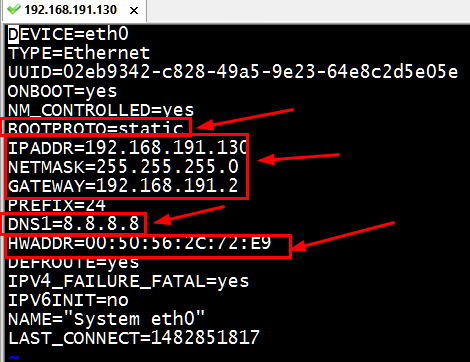
[root@neusoft-master ~]# vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
TYPE=Ethernet
UUID=02eb9342-c828-49a5-9e23-64e8c2d5e05e
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.191.130
NETMASK=255.255.255.0
GATEWAY=192.168.191.2
PREFIX=24
DNS1=8.8.8.8
HWADDR=00:50:56:2C:72:E9
DEFROUTE=yes
IPV4_FAILURE_FATAL=yes
IPV6INIT=no
NAME="System eth0"
LAST_CONNECT=1482851817
注意:如果多台虚拟机复制会有问题,我罗列了遇到的问题,如果没有图形界面网络配置更简单,如果沒有問題請跳过
方法1:利用图形界面解决
(1)图形界面找见图标,编辑
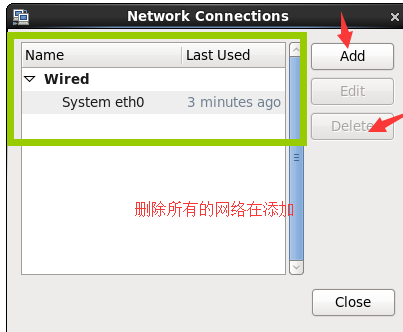
(2)删除所有网络
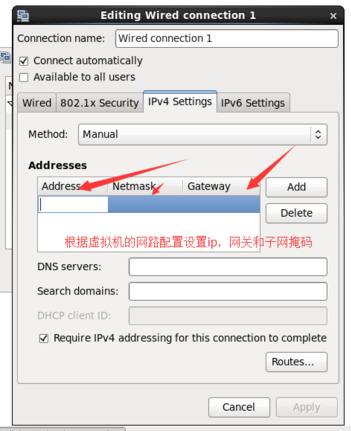
(3)根据虚拟机配置ip,网管等
解决 Error:No suitable device found: no device found for connection "System eth0"
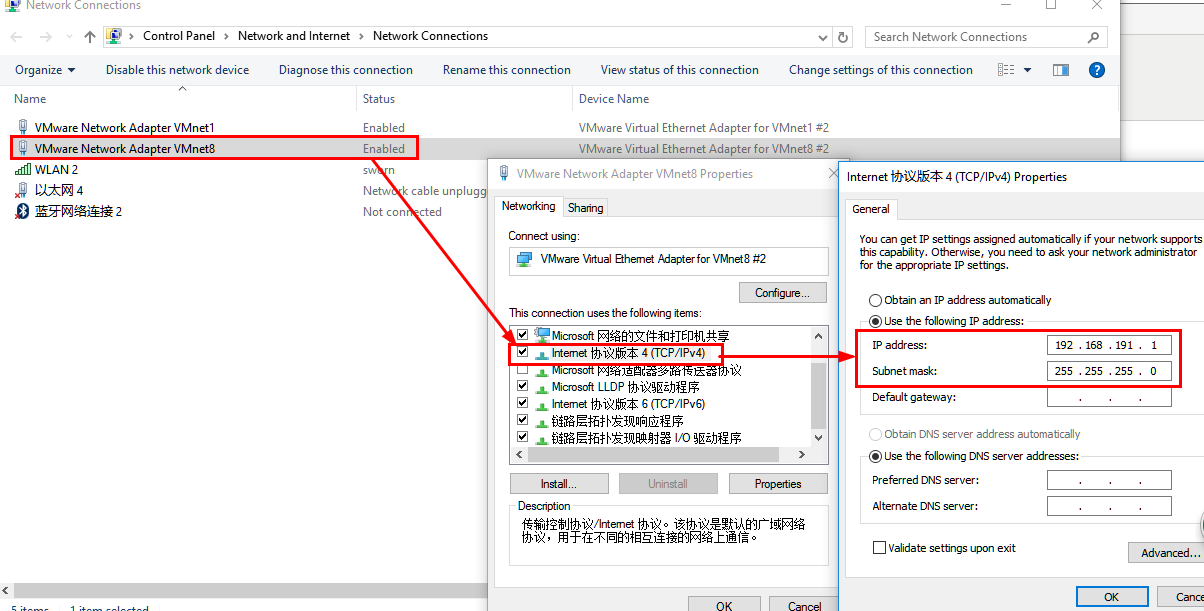
注意:VM的虚拟网卡VMnet8一定需要在windows操作系统的网络中开启,同时在虚拟机中配置正确的子网掩码及网关
存在的问题点1:
windows上的网络配置
存在的问题点2:
VM软件配置
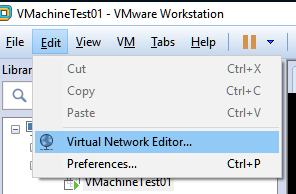

方法2:问题复述:
复制好的虚拟机,启动登陆进去(用户名和密码跟之前那台是一样的),修改好IPADDR,然后网卡重启出现问题?
#service network restart
出现问题:Error:No suitable device found: no device found for connection "System eth0" 如图所示:

#ifup eth0
出现: eth0: unknown interface: No such device 这样的问题,网卡都启动不了,出现问题.
解决:
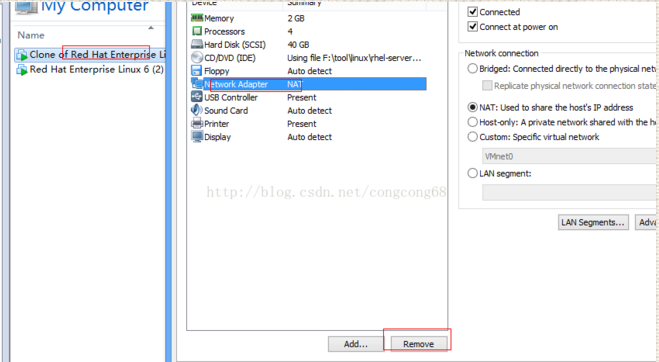
(1)我们在界面点击Network Adapter Remove删除网卡,如图所示:
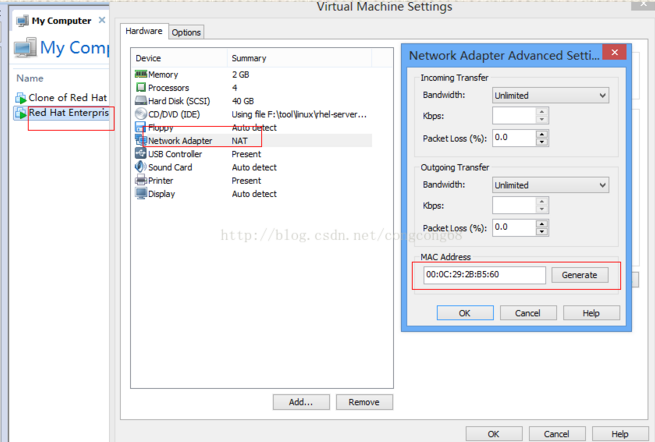
(2)添加一个新的网卡,就是点击add,这时跟前面一台的MAC Address 就不一样,如图所示:
(3)复制地址
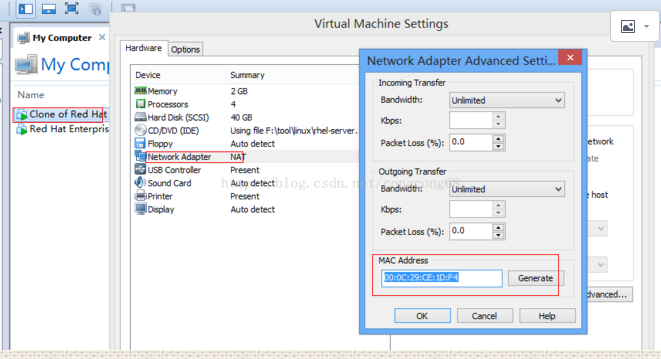
(4)重新启动虚拟机,然后进入到/etc/udev/rules.d/目录
#cat 70-persistent-net.rules
里面的信息跟我们Network Adapter的MAC Address地址一样,如图所示:

(5) 进入/etc/sysconfig/network-scripts/目录
#vi ifcfg-eth0
把HWADDR修改成Network Adapter的MAC Address地址一样,如图所示:
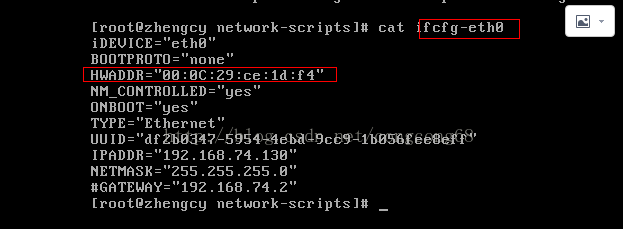
(6)重启网卡,这时就能正常启动,如图所示:

3.配置SSH无密码连接
(0)在Centos中首先关闭防火墙
service iptables stop(临时关闭防火墙)
永久关闭防火墙:
chkconfig iptables off
<补充的防火墙内容:>
- CentOS 6:
- 重启后不会复原,永久性生效。
开启: chkconfig iptables on
关闭: chkconfig iptables off
2.即时生效,重启后复原
开启: service iptables start
关闭: service iptables stop
- CentOS 7:
systemctl start firewalld.service#启动firewall
systemctl stop firewalld.service#停止firewall
systemctl disable firewalld.service#禁止firewall开机启动
- 查询TCP连接情况:
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
- 查询端口占用情况:
netstat -anp | grep portno(例如:netstat –apn | grep 80)
(1) 检查ssh是否安装
yum install ssh
yum install rsync #远程同步数据的工具
(2)启动SSH服务命令
service sshd restart
检查SSH是否已经安装成功
rpm -qa | grep openssh rpm -qa | grep rsync
显示相应信息即可。
(3)生成SSH公钥
对于伪分布式环境只需要本机链接本机即可:
主节点执行:ssh-keygen -t rsa 一路回车即可,最后显示的图形是公钥的指纹加密。
生成公钥后需要将公钥发到本机的authorized_keys的列表,执行:
ssh-copy-id -i ~/.ssh/id_rsa.pub root@neusoft-master 或ssh-copy-id -i ~/.ssh/id_rsa.pub neusoft-master(主机名)
也可以使用cat命令复制公钥到authorized_keys中,cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
如果是多机器需要需要通过scp命令赋值到主节点中,在分发至子节点。
(4)检查是否可以无密码ping通:使用”ssh 主机名”的方式验证
这里使用的是 ssh neusoft-master 无密码输入的提示,则安装成功。
如果执行上述步骤仍然不成功,有可能是~/.ssh 文件夹权限问题。执行如下程序
chmod 700 ~/.ssh #ssh文件夹一定是700权限
chmod 600 ~/.ssh/authorized_keys #authorized_keys文件夹一定是600权限
4.安装JDK
(1)通过java主页下载jdk1.7.x版本,使用SecureCRT上传到Centos中

(2)卸载原来的openjdk
rpm -qa |grep jdk 如果出现openjdk就需要卸载
使用yum -y remove xxx,其中xxx为刚才rpm -qa |grep jdk的结果
(3)方法1利用tar包安装JDK
- 解压tar文件
tar -zxvf jdk-7u80-linux-x64.tar.gz
- 配置环境变量 vi /etc/profile
export JAVA_HOME=/opt/jdk1..0_80 或/usr/java/default #根據书记情况改写 export PATH=$PATH:$JAVA_HOME/bin
- 立马生效
source /etc/profile
- 验证安装 ,如下java -version

(4)方法2利用rpm包安装JDK
- 如果是rpm文件只需要执行以下命令:
rpm -ivh oracle-j2sdk1.7-1.7.0+update67-1.x86_64.rpm (使用该文件方便)
cd /usr/java/
ls
ln -s jdk1.7.0-cloudera lastest
ln -s /usr/java/lastest default
ls -l #环境变量配置参考如下
配置环境变量 vi /etc/profile 修改如下:
export JAVA_HOME=/opt/jdk1..0_80 或/usr/java/default #根據书记情况改写 export PATH=$PATH:$JAVA_HOME/bin
如下图所示:

- 立马生效
source /etc/profile
- 验证安装 ,如下java -version
END~ 如果遇到安裝的問題請直接提問~
Hadoop伪分布安装详解(二)的更多相关文章
- Hadoop伪分布安装详解(五)
目录: 1.修改主机名和用户名 2.配置静态IP地址 3.配置SSH无密码连接 4.安装JDK1.7 5.配置Hadoop 6.安装Mysql 7.安装Hive 8.安装Hbase 9.安装Sqoop ...
- Hadoop伪分布安装详解(三)
目录: 1.修改主机名和用户名 2.配置静态IP地址 3.配置SSH无密码连接 4.安装JDK1.7 5.配置Hadoop 6.安装Mysql 7.安装Hive 8.安装Hbase 9.安装Sqoop ...
- Hadoop伪分布安装详解(四)
目录: 1.修改主机名和用户名 2.配置静态IP地址 3.配置SSH无密码连接 4.安装JDK1.7 5.配置Hadoop 6.安装Mysql 7.安装Hive 8.安装Hbase 9.安装Sqoop ...
- Hadoop伪分布安装详解(一)
注:以下截图针对Ubuntu操作系统,对Centos步骤类似.请读者选择不同镜像即可. 第一部分:VMware WorkStation10 安装 1.安装好VMware10虚拟机软件并下载好Ubunt ...
- hadoop 0.20.2伪分布式安装详解
adoop 0.20.2伪分布式安装详解 hadoop有三种运行模式: 伪分布式不需要安装虚拟机,在同一台机器上同时启动5个进程,模拟分布式. 完全分布式至少有3个节点,其中一个做master,运行名 ...
- hadoop伪分布安装
解压 将安装包hadoop-2.2.0.tar.gz存放到/home/haozhulin/install/目录下,并解压 #将hadoop解压到/home/haozhulin/install路径下,定 ...
- 转载 hadoop 伪分布安装
一. 概要 经过几天的调试,终于在Linux Cent OS 5.5下成功搭建Hadoop测试环境.本次测试在一台服务器上进行伪分布式搭建.Hadoop 伪分布式模式是在单机上模拟 Ha ...
- Hadoop伪分布安装配置
安装环境: 系统:Ubuntu 14.10 64bit hadoop:2.5.1 jdk:1.8.0_11 安装步骤: 一.安装JDK 安装 jdk,并且配置环境以及设置成默认 sudo gedi ...
- linux配置Hadoop伪分布安装模式
1)关闭禁用防火墙: /etc/init.d/iptables status 会得到一系列信息,说明防火墙开着. /etc/rc.d/init.d/iptables stop 关闭防火墙 2)禁用SE ...
随机推荐
- int、char、long各占多少字节数
Java基本类型占用的字节数:1字节: byte , boolean2字节: short , char4字节: int , float8字节: long , double 编码与中文:Unicode/ ...
- location 符号
元字符 描述 \ 将下一个字符标记符.或一个向后引用.或一个八进制转义符.例如,“\\n”匹配\n.“\n”匹配换行符.序列“\\”匹配“\”而“\(”则匹配“(”.即相当于多种编程语言中都有的“转义 ...
- CXAnimation类
#include "XAnimation.h" CXAnimation::CXAnimation(void) { m_strName = ""; m_nFram ...
- Windows Phone 性能优化(一)
在实际的项目开发过程中,应用的性能优化是一个永恒的话题,也是开发者群里最常讨论的话题之一,我在之 前的公司做 wp项目时,也遇到过性能的瓶颈.当页面中加载的内容越来越多时,内存涨幅非常明显(特别是 一 ...
- jquery的defer
deferred.promise() 和 .promise() 这两个API语法几乎一样,但是有着很大的差别.deferred.promise()是Deferred实例的一个方法,他返回一个Defer ...
- python3+spark2.1+kafka0.8+sparkStreaming
python代码: import time from pyspark import SparkContext from pyspark.streaming import StreamingContex ...
- ashx上传姿势
很多情况下网上流传的cer,asa,cdx……等等来上传,其实很多时候是不行的.但是ashx会好一些. PS:其实这个姿势也蛮老了,但是还是相当一大部分站点存在.也是一个姿势所以写博文记住它.免得忘了 ...
- [开机启动]Linux开机自启和运行级别
嵌入式系统中程序自启动方法 在很多嵌入式系统中,由于可用资源较少,常常在系统启动后就直接让应用程序自动启动,以减少用户操作和节省资源.如何让自己的应用程序自动启动呢? 在Linux系统中,配置应 ...
- H2 Database 支持数据类型
整数(INT) -2147483648 到 2147483647 java.lang.Integer 布尔型(BOOLEAN) TRUE 和 FALSE java.lang.Boolean 微整数(T ...
- 如何解决redis高并发客户端频繁time out?
解决方案:https://www.zhihu.com/question/24781521