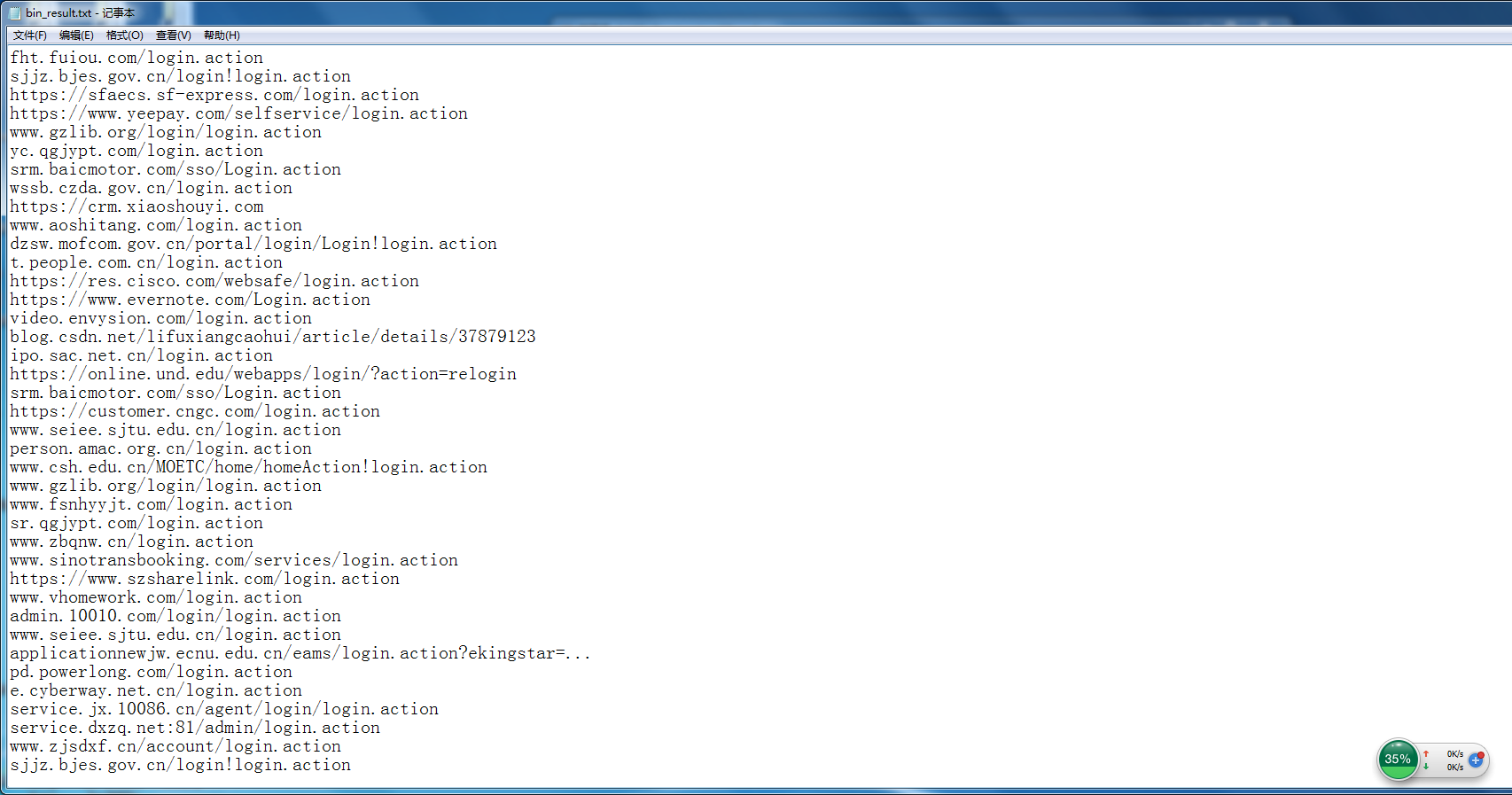
Perl6 必应抓取(1):测试版代码
一个相当丑漏的代码, 以后有时间再优化了。
默认所有查找都是15页, 如果结果没有15页这么多估计会有重复。速度还是很快的。
sub MAIN() {
my $fp = open 'bin_result.txt', :w;
my $number = ;
print 'String:';
my $string = get;
$string = do given $string {S:g/\s/+/};
use HTTP::UserAgent;
my $url = 'http://cn.bing.com/search?q=';
my $ua = HTTP::UserAgent.new;
my $check = rx/'<'cite'>'(.*?)'</cite>'/;#要查的内容
my @number = '';
@number.append(..$number);
my $page='';
my $html;
my $target = $url~$string~'&first=20&FROM=FERE'~$page;
$html = $ua.get($target).content;
loop {
say '===============> '~$target;
$html ~~ $check;
$html = $/.postmatch;
#$0 = do given ~$0 {S:g/'<strong>'//;}
if not $ {
#当是null时, 说明这一页已全部提取, 构造下一页
$page = Int($page);
my $page_next = $string~'&first='~$page~'0&FROM=FERE'~$page;
$target = $url~$page_next;
$html = $ua.get($target).content;
$page++;
#/search?q=123&first=10&FORM=PERE
#/search?q=123&first=20&FORM=PERE1
#/search?q=123&first=30&FORM=PERE2
#/search?q=123&first=30&FORM=PERE2
#last;
$html ~~ $check;
$html = $/.postmatch;
if ($page > $number) {last;}
}
my $ok_check = $.Str;
my $result = $ok_check;
$result = do given $result {S:g/'<strong>'//;}
$result = do given $result {S:g/'</strong>'//;}
say $result;
$fp.say($result);
}
#$fp.print($html);
}


下次代码优化:
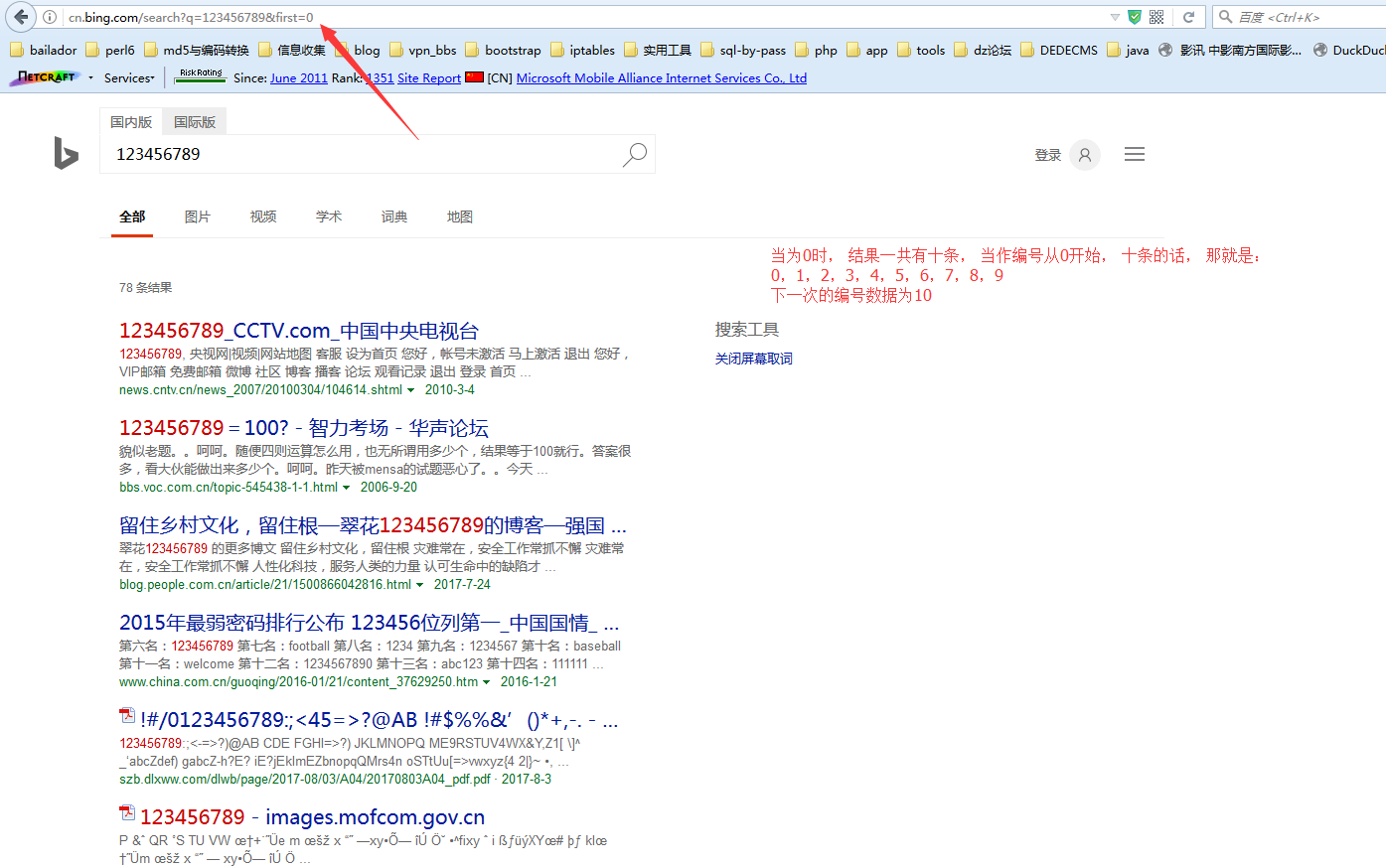
总结一下必应的规律, 如下:
http://cn.bing.com/search?q=&first=&FORM=PERE
http://cn.bing.com/search?q=&first=&FORM=PERE
http://cn.bing.com/search?q=&first=&FORM=PERE1
http://cn.bing.com/search?q=&first=&FORM=PERE2
http://cn.bing.com/search?q=&first=&FORM=PERE3
http://cn.bing.com/search?q=&first=&FORM=PERE4
http://cn.bing.com/search?q=&first=&FORM=PERE4
http://cn.bing.com/search?q=&first=&FORM=PERE4
http://cn.bing.com/search?q=&first=&FORM=PERE4
http://cn.bing.com/search?q=&first=&FORM=PERE4
在页面上测试, 参数只虽两个即可:
q=查询字符串&first=起始帐号


Perl6 必应抓取(1):测试版代码的更多相关文章
- Perl6 必应抓取(2):最终版
use HTTP::UserAgent; use URI::Encode; Firefox/52.0>); my $bing_url = 'http://cn.bing.com/search?q ...
- HttpClient 4.x 执行网站登录并抓取网页的代码
HttpClient 4.x 的 API 变化还是很大,这段代码可用来执行登录过程,并抓取网页. HttpClient API 文档(4.0.x), HttpCore API 文档(4.1) pack ...
- php中抓取网页内容的代码
方法一: 使用file_get_contents方法实现 $url = "http://news.sina.com.cn/c/nd/2016-10-23/doc-ifxwztru695114 ...
- xheditor编辑器上传截图图片抓取远程图片代码
xheditor是一款很不错的开源编辑器,用起来很方便也很强大. 分享一个xheditor直接上传截图的问题解决方法. 第一步.设置参数 localUrlTest:/^https?:\/\/[^\/] ...
- python网页抓取练手代码
from urllib import request import html.parser class zhuaqu(html.parser.HTMLParser): blogHtml = " ...
- Python网络编程_抓取百度首页代码(注释详细)
1 #coding=utf-8 2 #网络编程 3 4 #客户端建立socket套接字 5 #引入socket模块 6 import socket 7 #实例化一个套接字,2个参数分别是: IPV4. ...
- 抓取网站数据不再是难事了,Fizzler(So Easy)全能搞定
首先从标题说起,为啥说抓取网站数据不再难(其实抓取网站数据有一定难度),SO EASY!!!使用Fizzler全搞定,我相信大多数人或公司应该都有抓取别人网站数据的经历,比如说我们博客园每次发表完文章 ...
- PHP的cURL库:抓取网页,POST数据及其他,HTTP认证 抓取数据
From : http://developer.51cto.com/art/200904/121739.htm 下面是一个小例程: ﹤?php// 初始化一个 cURL 对象$curl = curl_ ...
- php中封装的curl函数(抓取数据)
介绍一个封闭好的函数,封闭了curl函数的常用步骤,方便抓取数据. 代码如下: <?php /** * 封闭好的 curl函数 * 用途:抓取数据 * edit by www.jbxue.com ...
随机推荐
- Hibernate学习--hibernate延迟加载原理-动态代理(阿里电面)
在正式说hibernate延迟加载时,先说说一个比较奇怪的现象吧:hibernate中,在many-to-one时,如果我们设置了延迟加载,会发现我们在eclipse的调试框中查看one对应对象时,它 ...
- rxjs5.X系列 —— ErrorHandling/Condition/Mathematical系列 api 笔记
欢迎指导与讨论 : ) 前言 本文是笔者翻译 RxJS 5.X 官网各类operation操作系列的的第四篇 —— ErrorHanding异常处理.Condition Operator情况操作.Ma ...
- 按着shift键对dbgrid进行多条记录选择的问题(50分)
可以用sendmessage,想dbgrid 发键盘信息,按下shift键,同时按下button1procedure TForm1.Button1Click(Sender: TObject);vari ...
- 【操作系统、UNIX环境编程】进程间通信
多个进程可以共享系统中的各种资源,但其中许多资源一次只能为一个进程使用,我们把一次仅允许一个进程使用的资源称为临界资源,许多物理设备都属于临界资源,如打印机等. Linux下进程间通信有如下几种方式: ...
- KMP算法模板(pascal)
洛谷P3375: program rrr(input,output); var i,j,lena,lenb:longint; a,b:ansistring; next:..]of longint; b ...
- 【bzoj4542】[Hnoi2016]大数 莫队算法
题目描述 给出一个数字串,多次询问一段区间有多少个子区间对应的数为P的倍数.其中P为质数. 输入 第一行一个整数:P.第二行一个串:S.第三行一个整数:M.接下来M行,每行两个整数 fr,to,表示对 ...
- 《Unix网络编程卷1:套接字联网API》读书笔记
第一部分:简介和TCP/IP 第1章:简介 第2章:传输层:TCP.UDP和SCTP TCP:传输控制协议,复杂.可靠.面向连接协议 UDP:用户数据报协议,简单.不可靠.无连接协议 SCTP:流控制 ...
- 拓展kmp总结
借鉴自:https://blog.csdn.net/dyx404514/article/details/41831947 定义母串S,和子串T,设S的长度为n,T的长度为m,求T与S的每一个后缀的最长 ...
- innodb--表空间
MySQL把数据库中表结构的定义信息保存到数据库目录的.frm文件中. 在InnoDB中数据库中存储的数据及索引实际是存放在表空间里的(tablespace). 可以将每个基于InnoDB存储引擎的表 ...
- Error: Chromium revision is not downloaded. Failed to download Chromium
在使用prerender-spa-plugin做前端预渲染的时候,安装puppeteer的时候因为下载Chromium 失败报错,有如下解决方法: 1.使用Chromium 国内源 npm confi ...