Python之函数进阶
本节内容
上一篇中介绍了Python中函数的定义、函数的调用、函数的参数以及变量的作用域等内容,现在来说下函数的一些高级特性:
- 递归函数
- 嵌套函数与闭包
- 匿名函数
- 高阶函数
- 内置函数
- 总结
一、递归函数
函数是可以被调用的,且一个函数内部可以调用其他函数。如果一个函数在内部调用本身,这个函数就是一个递归函数。函数递归调用的过程与循环相似,而且理论上,所有的递归函数都可以写成循环的方式,但是递归函数的优点是定义简单,逻辑清晰。递归和循环都是一个重复的操作过程,这些重复性的操作必然是需要有一定的规律性的。另外,很明显递归函数也需要一个结束条件,否则就会像死循环一样递归下去,直到由于栈溢出而被终止(这个下面介绍)。
可见,要实现一个递归函数需要确定两个要素:
- 递归规律
- 结束条件
1. 实例:计算正整数n的阶乘 n! = 1 * 2 * 3 * ... * n
循环实现
思路有两个:
- 从1乘到n,需要额外定义一个计数器存放n当前的值
- 从n乘到1,无需额外定义计数器,直接对n进行减1操作,直到n=0返回1结束
def fact(n):if n == 0:return 1result = 1while n >= 1:result *= nn -= 1return result
递归实现
先来确定递归函数的两个要素:
- 递归规律:n!=1 * 2 * 3 * ... * n = (n-1)! * n,也就是说fact(n) = fact(n-1) * n,且n逐一减小
- 结束条件:当n==0时返回1结束
def fact(n):if n == 0:return 1return fact(n-1) * n
怎么样?递归函数的实现方式是不是既简单、又清晰。
我们计算fact(5)的计算过程是这样的:
===> fact(5)===> 5 * fact(4)===> 5 * (4 * fact(3))===> 5 * (4 * (3 * fact(2)))===> 5 * (4 * (3 * (2 * fact(1))))===> 5 * (4 * (3 * (2 * 1)))===> 5 * (4 * (3 * 2))===> 5 * (4 * 6)===> 5 * 24===> 120
同理,要实现求1 + 2 + 3 + ... + n,可以这样写:
def fact(n):if n == 1:return 1return fact(n-1) + n
2. 递归函数优缺点
递归函数的优点:
定义简单、逻辑清晰。
递归函数的缺点:
效率并不高且需要注意防止栈溢出。
其他特点:
大家会发现上面实现的递归函数在运算的过程中n是逐渐减小的,也就是说问题规模应该是逐层减小的。
3. 递归特性总结
下面我们来总结写递归的特性:
- 必须有一个明确的结束条件
- 每次进入更深一层的递归时,问题规模相比上次递归都应有所减小
- 递归效率不高,递归层次过多会导致栈溢出。
因为在计算中,函数调用是通过栈(stack,特点是后进先出--LIFO)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈针,每当函数返回,栈就会减少一层栈针。由于栈的大小不是无限的,所有递归调用的次数过多,会导致栈溢出。关于堆栈的介绍可以看下这里:<<内存堆和栈的区别>>。
每种编程语言都对递归函数可递归的深度有限制(可以看看这里),有些是跟相应内存空间的分配有关(因为栈是在内存空间中的),如Java。Python中对递归的深度限制默认为1000,可以通过sys.getrecursionlimit()函数来获取该值,超过这个深度会报错:RecursionError: maximum recursion depth exceeded in comparison。当然也可以通过sys.setrecursionlimit(n)来设置新的限制值。
二、嵌套函数与闭包
1. 嵌套函数
嵌套函数是指在函数内部定义一个函数,这些函数都遵循各自的作用域和生命周期规则。
来看个例子:
def outer():level = 1print('outer', level)def inner():print('inner', level)inner()
调用outer函数outer(),输出结果如下:
outer 1inner 1
再来看个例子:
def outer():level = 1print('outer', level)def inner():level = 2print('inner', level)inner()
调用outer函数outer(),输出结果如下:
outer 1inner 2
嵌套函数查找变量的顺序是:先查找自己函数体内部是否包含该变量,如果包含则直接应用,如果不包含则查找外层函数体内是否包含该函数,依次向外。
2. 闭包
首先要说明一个问题:函数名其实也是一个变量,我们通过def定义一个函数时,实际上就是在定义一个变量,函数名就是变量名称,函数体就是该变量的值。我们知道,变量是可以赋值给其他变量的,因此函数也是可以被当做返回值返回的,并且可以赋值给其他变量。
def outer(x):def inner(y):print(x+y)return inner
f1 = outer(10)f2 = outer(20)f1(100)f2(100)
上面操作的执行结果是:
110120
我们知道局部变量的作用域是在定义它的函数体内部,局部变量在函数执行时进行声明,函数执行完毕则会被释放。上面也提到过了,函数也是一个变量,那么嵌套函数内部定义的函数也是一个局部变量,也就是说嵌套函数每调用一次,其内部的函数都会被定义一次。因此,在上面的示例中
f1 = outer(10)f2 = outer(20)
对于f1和f2而言,两次调用嵌套函数outer并返回的内部函数inner是不同的,且它们取到的x值也是不同的。从表面上来看f1和f2相当于把x分别替换成了10和20:
def f1(y):print(10+y)def f2(y):print(20+y)
但实际上不是这样的,f1和f2还是这样的:
def f1(y):print(x+y)def f2(y):print(x+y)
f1和f2被调用时,y的值是通过参数传递进来的(100),而x还是个变量。inner函数会在自己的函数体内部查找该局部变量x,发现没找到,然后去查找它外层的函数局部变量x,找到了。这里好像出现问题了,因为之前说过了局部变量会在函数执行结束后被释放,那么f1和f2被调用时outer函数已经执行完了,理论上x的值应该被释放了才对啊,为什么还能引用x的值?其实,这就是闭包的作用。
闭包的定义
如果在一个内部函数中,引用了外部非全局作用域中的变量,那么这个内部函数就被认为是闭包(closure)。
在一些语言中,在函数中可以(嵌套)定义另一个函数时,如果内部的函数应用了外部函数的变量,则可能产生闭包。闭包可以用来在一个函数与一组“私有”变量之间创建关联关系。在该内部函数被多次调用的过程中,这些私有变量能够保持其持久性。在支持将函数作为对象使用的编程语言中,一般都支持闭包,比如:Python、PHP、Javascript等。
闭包就是根据不同的配置信息得到不同的结果。专业解释是:闭包(closure)是词法闭包(Lexical Closure)的简称,是引用了自由变量的函数。这个被引用的自由变量将和这个函数一同存在,即使已经离开了创造它的环境也不例外。所以,有另一种说法认为闭包是由函数和与其相关的应用环境组合而成的实体。
闭包的工作原理
Ptyhon支持一种特性叫做函数闭包(function closres),它的工作原理是:在非全局(global)作用域(函数)中定义inner函数时,这个inner函数会记录下外层函数的namespaces(外层函数作用域的locals,其中包括外层函数局部作用域中的所有变量),可以称作:定义时状态,inner函数可以通过__closure__(早期版本中为func_closure)这个属性来获得inner函数外层嵌套函数的namespaces。其实我们可以通过打印一个函数的__closesure__属性值是否为None来判断闭包是否发生。
闭包与装饰器
其实装饰器就是一种闭包,或者说装饰器是闭包的一种经典应用。区别在于,装饰器的参数(配置信息)是一个函数或类,专门对类或函数进行加工、处理和功能增强。关于装饰器,我们会在后面详细介绍。
三、匿名函数
在Python中有两种定义函数的方式:
- 通过def关键字定义的函数:这是最常用的方式,前面已经介绍过
- 通过lambda关键字定义的匿名函数:这是本次要说的主角
lambda作为一个关键字,作为引入表达式的语法。与def定义的函数相比较而言,lambda是单一的表达式,而不是语句块。也就是说,我们仅仅能够在lambda中封装有限的业务逻辑(通常只是一个表达式),这样设计的目的在于:让lambda纯粹为了编写简单的函数(通常称为小函数)而设计,def则专注于处理更大的业务。
1. 匿名函数的定义
语法:
lambda argument1, argument2, ... argumentN :expression using argments
冒号左边是函数的参数,冒号右边是一个整合参数并计算返回值的表达式。
实例:定义一个求两个数之和的函数
def函数
def add(x, y):return x + y
lambda函数
lambda x, y: x+y
2. 匿名函数的调用方式:
调用方式1:匿名函数也是一个函数对象,可以将匿名函数赋值给一个变量,然后通过在这个变量后加上一对小括号来调用:
add = lambda x, y: x+ysum = add(1, 2)
调用方式2:直接在lambda函数后加上一对小括号调用:
sum = (lambda x, y: x+y)(1, 3)
3. 匿名函数的特性:
- 函数体只能包含一个表达式
- 不能有return语句(表达式的值就是它的返回值)
- 参数个数不限,可以有0个、1个或多个
4. 什么时候用匿名函数
从上面提到的“匿名函数的调用方式”来看,匿名函数貌似没有什么卵用,反而可读性更差了。那么匿名函数在Python中存在的意义是什么呢?匿名函数一般应用于函数式编程中,在Python中通常是指与高阶函数的配合使用--把匿名函数当做高阶函数的参数来使用,下面的高阶函数实例中会用到。
四、高阶函数
我们上面已经提到过:函数名也是变量,函数名就是指向函数的变量。并且我们已经知道:变量是可以作为参数传递给函数的。由此,我们得出一个结论:函数是一个接受另外一个函数作为参数的,而这种函数就称为高阶函数(Higher-order function)。
1. 自定义高阶函数
我们来自定义一个高阶函数,这个函数用于求两个数的和,同时接收一个函数用于在求和之前对两个数值参数做一些额外的处理(如:取绝对值、求平方或其他任意操作)
def nb_add(x, y, f):return f(x) + f(y)
其中x,y是用于求和的两个数值参数,f是对x,y进行处理的函数。我们试着先给f传递一个内置的abs(取绝对值)函数,也就是说先对x和y分别取绝对值,然后再相加:
result = nb_add(10, -20, abs)print(result)
运行结果是:30
我们来自定义一个求平方的方法,然后传递给f试试:
def pow2(x):return pow(x, 2)result = nb_add(10, -20, pow2)print(result)
输出结果是:500
我们发现上面定义的pow2(x)函数的函数体只有一个表达式,因此我们完全可以不单独定义该函数而使用匿名函数来实现,这样可以使diamante变得更简洁:
def nb_add(x, y, f):return f(x) + f(y)result = nb_add(10, 20, lambda x: pow(x, 2))print(result)
2. 常见内置高阶函数
Python内置了一些非常有用的高阶函数,下面我们来看看常见的几个:
map函数
map(function, iterable, ...)
map函数的参数说明:
- map函数接收两类参数:函数和可迭代对象(Iterable)
- 第一个参数是函数,后面的参数都是可迭代对象。
- 处理函数的参数个数需要与传入的可迭代对象参数的个数对应,否则会报错。
- 如果传入的可迭代对象参数有多个,且每个iterable元素数量不相等时,结果中的元素个数与最短的那个iterable的元素个数一致。
map函数的作用是:
将传入的函数依次作用到可迭代对象的每个元素,并把结果作为新的迭代器对象(Iterator)返回(Python2.x中会直接返回一个列表)。
实例1:计算给定列表中的每个元素的平方值并放回一个新的列表
def pow2(x):return x * xL = [1, 2, 3, 4, 5, 6]list1 = list(map(pow2, L))print(list1)
输出结果为:[1, 4, 9, 16, 25, 36]
上面已经演示过,pow2()可以直接使用匿名函数:
L = [1, 2, 3, 4, 5, 6]list1 = list(map(lambda x: pow(x, 2), L))print(list1)
可见map函数作为高阶函数,事实上是把运算规则抽象了,因此,我们不仅可以计算简单的f(x)=x*x,还可以计算任意复杂的函数。
实例2:计算两个序列中对应元素的和并保存至一个新的列表中
L = [1, 2, 3, 4, 5, 6]T = (7, 8, 9, 10)list1 = list(map(lambda x, y: x+y, L, T))print(list1)
输出结果为:[8, 10, 12, 14]
reduce函数
这里需要说明一下:reduce函数在Python 2.x中跟map函数一样都是Python内置函数,Python 3.x中已经被转移到functools模块了。
reduce(function, sequence, initializer=None)
reduce函数的参数说明:
- 接收一个函数参数、一个序列参数和一个可选的initalizer参数
- 如果可选参数initializer被提供,则相当于把它作为sequence的一个元素插入sequence的首部
reduce函数的作用是:
把一个函数作用在指定的序列上,这个函数必须接收两个参数,然后把计算结果继续和序列的下一个元素做累计计算,最终返回一个结果。简单来讲,就是对一个序列中的元素做聚合运算。
实例1:计算指定数列中所有元素的和
from functools import reduceL = [1, 2, 3, 4, 5]sum1 = reduce(lambda x, y: x + y, L)print(sum1)sum2 = reduce(lambda x, y: x + y, L, 6)print(sum2)
输出结果为:
1521
这个过程相当于:(((1 + 2) + 3) + 4) + 5
实例2:将数字字符串转成int
from functools import reducedef fn(x, y):return int(x)*10 + int(y)num = reduce(lambda x, y: int(x)*10 + int(y), '12345')print(num)
也可以封装成一个函数:
from functools import reducedef str2int(s):return reduce(lambda x, y: int(x)*10 + int(y), s)num = str2int('12345')print(num)
也可以先通过map函数将字符串中的字符转成int,然后再通过reduce进行运算:
from functools import reducedef str2int(s):def char2num(c):return {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}[c]return reduce(lambda x, y: x*10 + y, map(char2num, s))num = str2int('12345')print(num)
其实char2sum也可以用匿名函数来实现,但是可读性不太好。另外我举这个例子的本义不是为了单纯的演示map/reduce/匿名函数的使用,而是想说明嵌套函数与高阶函数综合使用的场景,这在某些场景下可以使代码逻辑变得更清晰。
filter函数
filter(function, iterable)
filter函数的参数说明:
- filter函数接收一个函数参数和一个可迭代对象参数,函数参数可以为None
- 函数的返回值(True或False)用于判断可迭代对象的当前元素是否要保留
filter函数的作用是:
用于过滤可迭代对象,具体过程是:把传入的函数依次作用于可迭代对象的每个元素,如果函数返回值为Ture则保留该元素,如果返回值为False则丢弃该元素,并最终把保留的元素作为一个iterator(迭代器)返回。如果function是None,则根据可迭代对象各元素的真值测试结果决定是否保留该元素。
与Python内置的filter函数作用刚好相反的函数是
itertools.filterfalse(function, sequence),它用于过滤出序列中通过function函数计算结果为False的元素。
实例1:分别打印出指定列表中的奇数和偶数
from itertools import filterfalseL = [1, 2, 3, 4, 5, 6, 7, 8, 9]odd_num = list(filter(lambda x: x % 2 == 1, L))even_num = list(filterfalse(lambda x: x%2 == 1, L))print('奇数:', odd_num)print('偶数:', even_num)
输出结果:
奇数: [1, 3, 5, 7, 9]偶数: [2, 4, 6, 8]
实例2:删除序列中的空字符串
L = ['ABC', '', 'DEF', ' ', '1233', None]list1 = list(filter(None, L))print(list1)
输出结果为:['ABC', 'DEF', ' ', '1233']
由于第4个由3个空白字符组成的字符串的真值测试结果为True,因此它还是会被保留。被看来还是需要传递个函数参数才行:
L = ['ABC', '', 'DEF', ' ', '1233', None]list1 = list(filter(lambda s: s and s.strip(), L))print(list1)
输出结果:['ABC', 'DEF', '1233']
sorted函数
sorted(iterable[, key][, reverse])
sorted函数的参数说明:
- sorted函数可以接收一个可迭代对象iterable作为必选参数,还可以接收两个可选参数key和reverse,但是这两个可选参数如果要提供的话,需要作为关键字参数进行传递;
- 参数key接收的是一个函数名,该函数用来实现自定义排序;如,要按照绝对值大小进行排序:key=abs
- 参数reverse接收的是一个布尔值:如果reverse=Ture,表示倒叙排序,如果reverse=False,表示正序排序;reverse默认值为False
关于参数key的进一步说明: 排序的核心是比较两个元素的大小。如果要比较的是两个数字,我们可以直接比较;如果是字符串,也可以按照ASCII码的大小进行比较。但是,如果要比较的元素是两个序列或dict等复杂数据呢?这时,我们可能需要指定一个计算“用于比较的值”的运算规则,比如我们指定取两个dict中的某个共同的key对应的值来进行比较,又比如我们指定用将两个字符串都转换为小写或者大写后的结果值进行比较。其实说简单点,参数key这个函数作用是:计算/获取用来进行比较的值。如果我们需要自定义这个函数时,需要注意该函数应该有一个参数,这个参数接收的就是可迭代对象中每个元素的值。
sorted函数的作用是:
对可迭代对象iterable中的元素进行排序,并将排序结果作为一个新的list返回。
实例1:数字列表排序
list1 = sorted([10, 9, -21, 13, -30])list2 = sorted([10, 9, -21, 13, -30], key=abs)list3 = sorted([10, 9, -21, 13, -30], key=abs, reverse=True)print(list1)print(list2)print(list3)
输出结果:
[-30, -21, 9, 10, 13][9, 10, 13, -21, -30][-30, -21, 13, 10, 9]
实例2:字符串列表排序
list1 = sorted(['how', 'What', 'check', 'Zero'])list2 = sorted(['how', 'What', 'check', 'Zero'], key=lower)list3 = sorted(['how', 'What', 'check', 'Zero'], key=lower, reverse=True)print(list1)print(list2)print(list3)
输出结果:
['What', 'Zero', 'check', 'how']['check', 'how', 'What', 'Zero']['Zero', 'What', 'how', 'check']
实例3:tuple列表排序
假设我们用一组tuple表示姓名和年龄,然后用sorted()函数分别按姓名升序和年龄降序进行排序:
def sort_by_name(t):return t[0]def sort_by_age(t):return t[1]L = [('Tom', 18), ('Jerry', 15), ('Peter', 16), ('John', 20)]list1 = sorted(L, key=sort_by_name)list2 = sorted(L, key=sort_by_age, reverse=True)print('sort by name asc: ', list1)print('sort by age desc: ', list2)
输出结果:
sort by name asc: [('Jerry', 15), ('John', 20), ('Peter', 16), ('Tom', 18)]sort by age desc: [('John', 20), ('Tom', 18), ('Peter', 16), ('Jerry', 15)]
实例4:字典内容排序
对字典排序的方法有很多中,但核心思想都是一样的:把dict中的key或value或item分离出来放到一个list中,然后在对这个list进行排序,从而间接实现对dict的排序。
D = {'Tom': 18, 'Jerry': 15, 'Peter': 16, 'John': 20}list1 = sorted(D.items(), key=lambda d: d[0])list2 = sorted(D.items(), key=lambda d: d[1], reverse=True)print('sort by key asc:', list1)print('sort by value desc:', list2)
输出结果:
sort by key asc: [('Jerry', 15), ('John', 20), ('Peter', 16), ('Tom', 18)]sort by value desc: [('John', 20), ('Tom', 18), ('Peter', 16), ('Jerry', 15)]
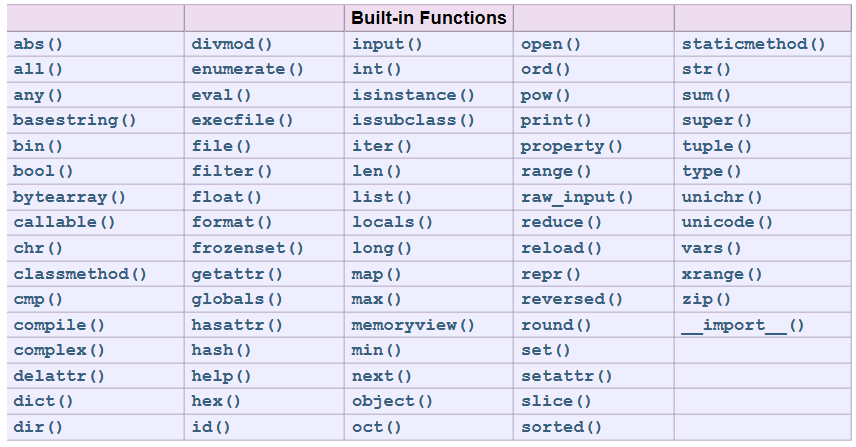
五、内置函数
Python解释器有许多内置的函数和类型,有一些之前已经用到过,比如:
- 数学函数:abs()、max()、min()、pow()、sum()
- 类型转换函数:int()、float()、str()、bool()、list()、tuple()、dict()、set()
- 进制转换函数:bin()、oct()、hex()
- 高阶函数:map()、filter()、sorted()
- 打开文件用的函数:的open()
- 输入与输出函数:input()、raw_input()、print()
- 获取对象内存地址的函数:id()
这些函数我们在之前的文章中基本都演示了,不在此赘述。关于他们的详细说明以及其它内置函数的使用可以参考下面给出的列表及官方文档连接地址。
Python 3相对于Python 2的内置函数有些变动:
- 新增了一些内置方法,如:ascii()、bytes()、exec()
- 删除了一些内置方法, 如:cmp()、execfile()
- 移动了一些内置方法,如:reduce()被移动到了functools模块下
- 修改了一些内置方法,如:sorted()函数在Python 3.5的文档中么有再提到cmp参数了(貌似用不到这个参数)
Python 3中的高阶函数还有一个比较大的改变,如map()和filter()在Python 2中是直接返回一个列表(list),而在Python 3中是返回一个迭代器(Iterator)。
Python 3.5内置函数列表(官方文档地址)

Python 2.7内置函数列表(官方文档地址)
六、总结
这里讲了分别讲了Python中函数的一些高级应用,如果能把这些内容整合起来灵活运用会发挥很大的威力。比如后面要说到的装饰就是高阶函数、嵌套函数以及闭包的一个典型应用。
Python之函数进阶的更多相关文章
- 【转】Python之函数进阶
[转]Python之函数进阶 本节内容 上一篇中介绍了Python中函数的定义.函数的调用.函数的参数以及变量的作用域等内容,现在来说下函数的一些高级特性: 递归函数 嵌套函数与闭包 匿名函数 高阶函 ...
- 《Python》 函数进阶和名称空间作用域
函数进阶: 一.动态参数:*args **kwargs *args是元祖形式,接收除去键值对以外的所有参数 # args可以换成任意变量名,约定俗成用args **kwargs接收的只是键值对的参数 ...
- 10.Python初窥门径(函数进阶)
Python(函数进阶) 一.函数的传参(接上期) 形参角度(一共四种,后两种) 动态参数(万能参数)* # 定义一个函数时,*所有的位置参数聚合到一个元组中 def func(*args): # * ...
- python开发函数进阶:生成器表达式&各种推导式
一,生成器表达式 #生成器表达式比列表解析更省内存,因为惰性运算 #!/usr/bin/env python #_*_coding:utf-8_*_ new_2 = (i*i for i in ran ...
- day09 python之函数进阶
楔子 假如有一个函数,实现返回两个数中的较大值: def my_max(x,y): m = x if x>y else y return mbigger = my_max(10,20)print ...
- Python入门-函数进阶
昨天我们简单的了解了函数的定义,调用,以及传参,其实还有一个更重要的传参:动态传参,让我们继续昨天没有说完的,以及今天我要分享的东西. 一.动态传参 之前我们说过了传参,如果我们需要给一个函数传参,而 ...
- python学习——函数进阶
首先来看下面这个函数. def func(x,y): bigger = x if x > y else y return bigger ret = func(10,20) print(ret) ...
- python开发函数进阶:装饰器
一,装饰器本质 闭包函数 功能:就是在不改变原函数调用方式的情况下,在这个函数前后加上扩展功能 作用:解耦,尽量的让代码分离,小功能之前的分离. 解耦目的,提高代码的重用性 二,设计模式 开放封闭原则 ...
- python开发函数进阶:匿名函数
一,匿名函数 #简单的需要用函数去解决的问题 匿名函数的函数体 只有一行#也叫lambda表达式# cal2(函数名) = lambda n(参数) : n*n(参数怎么处理,并且返回值)#参数可以有 ...
随机推荐
- 【自动化测试】PO思路
http://blog.csdn.net/liubofengpython/article/details/7720078
- mysql利用存储过程批量插入数据
最近需要测试一下mysql单表数据达到1000W条以上时增删改查的性能.由于没有现成的数据,因此自己构造,本文只是实例,以及简单的介绍. 首先当然是建表: [sql]view plaincopy CR ...
- Python 字典(Dictionary) get()方法
描述 Python 字典(Dictionary) get() 函数返回指定键的值,如果值不在字典中返回默认值. 语法 get()方法语法: dict.get(key, default=None) 参数 ...
- linux设置默认路由细节问题
在这里,我想给大家讲解下,linux系统默认路由的设置的一些细节问题.这样在设置多块网卡的时候如何设置路由可以为初学者少走一些弯路. 默认情况下配置多块网卡,每个网卡都要配置ip,每个ip又是在不 ...
- PHPMailer邮件类使用错误分析
PHPMailer配置清单如下: require_once ‘class.phpmailer.php‘; $receiver = ”; $mail = new PHPMailer ( ); $mai ...
- 【转】ACE编程小结
转自:http://blog.csdn.net/mjp_mjp/article/details/4406059 1.多线程中的ACE_Reactor::EventLoop,当在多线程(池)中调用Eve ...
- zzzzz
Extension Method: Return another string if string is null or emptyJust a tiny little extension metho ...
- bzoj1036 树的统计Count
第一次写链剖,于是挑了个简单的裸题写. 以下几点要注意: 1.链剖中的height是从根到该店经过的轻边个数 2.分清num与sum..... #include<cstdio> #incl ...
- 说说Python 中的文件操作 和 目录操作
我们知道,文件名.目录名和链接名都是用一个字符串作为其标识符的,但是给我们一个标识符,我们该如何确定它所指的到底是常规文件文件名.目录名还是链接名呢?这时,我们可以使用os.path模块提供的isfi ...
- PermGen space Eclipse 终极解决方案
1.选中项目右键 run or debug configurations... 2.在 VM arguments 加入 -Xms128m -Xmx512m -XX:PermSize=64M -XX: ...