python数据类型内置的方法
数据类型的内置方法
在日常生活中不同类型的数据具有不同的功能
eg:表格数据文件具有处理表格的各项功能(透视表 图形化 公式计算)
视频数据文件具有快进 加速等各项功能
...
1.整型int
# 方式在代码中展示出来的效果就是 名字()
# 类型转换
# res = '123'
# print(type(res))
# res = int(res)
# print(type(res))
'''int在做类型转换的时候 只能转换纯数字'''
# int('123.123') # 报错 不识别小数点
# int('jason123') # 报错 不识别除数字以外的数据
'''int其实还可以做进制数转换'''
print(bin(100)) # 将十进制的100转换成二进制 0b1100100
print(oct(100)) # 将十进制的100转换成八进制 0o144
print(hex(100)) # 将十进制的100转换成十六进制 0x64
# 0b开头为二进制数 0o开头为八进制数 0x开头为十六进制数
print(int('0b1100100', 2)) # 100
print(int('0o144', 8)) # 100
print(int('0x64', 16)) # 100
2.浮点型float
# 类型转换
res = '123.23'
# print(type(res))
# res = float(res)
# print(type(res))
print(float('123')) # 123.0
3.字符串str
# 类型转换
print(str(123))
print(str(123.21))
print(str([1, 2, 3, 4]))
print(str({'name': 'jason', 'pwd': 123}))
print(str((1, 2, 3, 4)))
print(str(True))
print(str({1, 2, 3, 4}))
# 基本用法
res = 'hello world!'
# 1.索引取值
# print(res[1]) # e
# 2.切片操作 顾头不顾尾
# print(res[1:4]) # ell
# 3.步长操作
# print(res[1:10]) # ello worl
# print(res[1:10:2]) # el ol
# 4.索引支持负数
# print(res[-1]) # ! 最后一位
# print(res[-5:-1]) # orld 顾头不顾尾
# print(res[-5:-1:-1]) # 方向冲突
# 5.统计字符串内部字符的个数
# print(len(res)) # 12
# 6.移除字符串首尾指定的字符 strip()
# name = ' jason '
# print(name, len(name))
# print(len(name.strip())) # 默认移除首尾的空格
# name1 = '$$jason$$'
# print(name1.strip('$')) # jason
# print(name1.lstrip('$')) # jason$$
# print(name1.rstrip('$')) # $$jason
# username = input('username>>>:')
# username = username.strip()
# username = input('username>>>:').strip()
# if username == 'jason':
# print('老板好')
# else:
# print('去你妹的')
# 7.按照指定的字符切割字符串 split() 该方法的结果是一个列表
# res2 = 'jason|123|18'
# print(res2.split('|')) # ['jason', '123', '18']
# print(res2.split('|', maxsplit=1)) # ['jason', '123|18'] maxsplit用于控制切割的次数
# print(res2.rsplit('|', maxsplit=1)) # ['jason|123', '18']
"""如何查看数据类型都有哪些内置方法
句点符(.)
"""
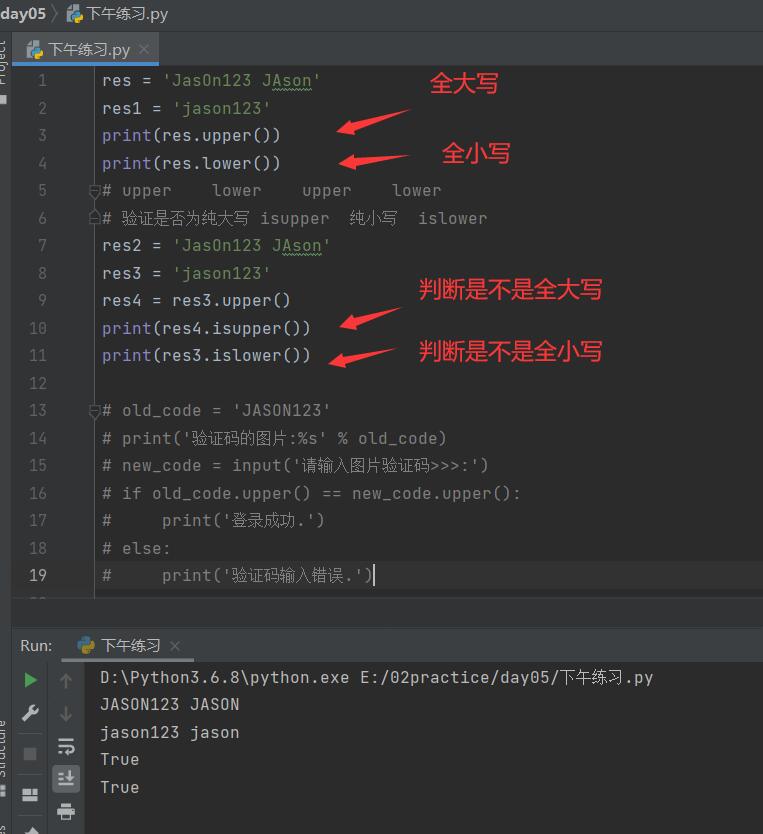
8.大小写
转全大写
print(res.upper()) # JASON123 JASON
转全小写
print(res.lower()) # jason123 jason
判断是否是纯大写
print(res.isupper())
print(res1.isupper())
判断是否是纯小写
print(res.islower())
print(res1.islower())
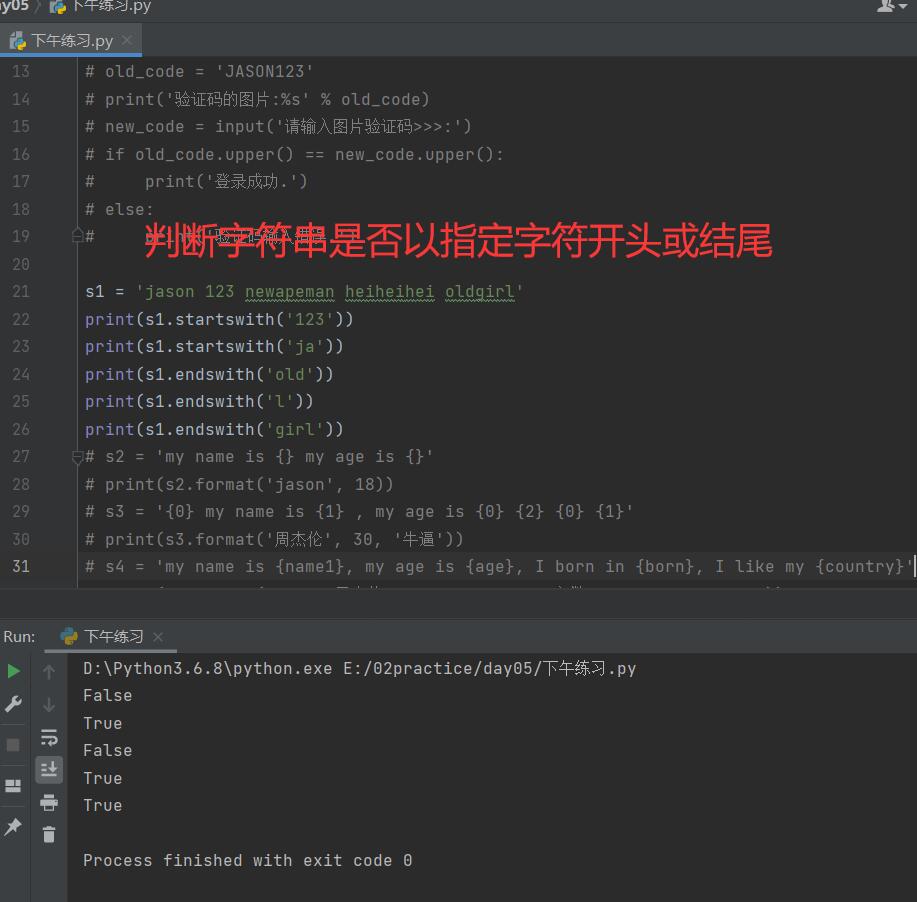
9. 判断字符串是否以指定的字符开头
9.1 判断开头
s1 = 'jason 123 newapeman heiheihei oldgirl'
print(s1.startswith('tony')) # False
print(s1.startswith('j')) # True
print(s1.startswith('jas')) # True
print(s1.startswith('jason')) # True
9.2判断结尾
print(s1.endswith('oldboy')) # False
print(s1.endswith('l')) # True
print(s1.endswith('rl')) # True
print(s1.endswith('oldgirl')) # True
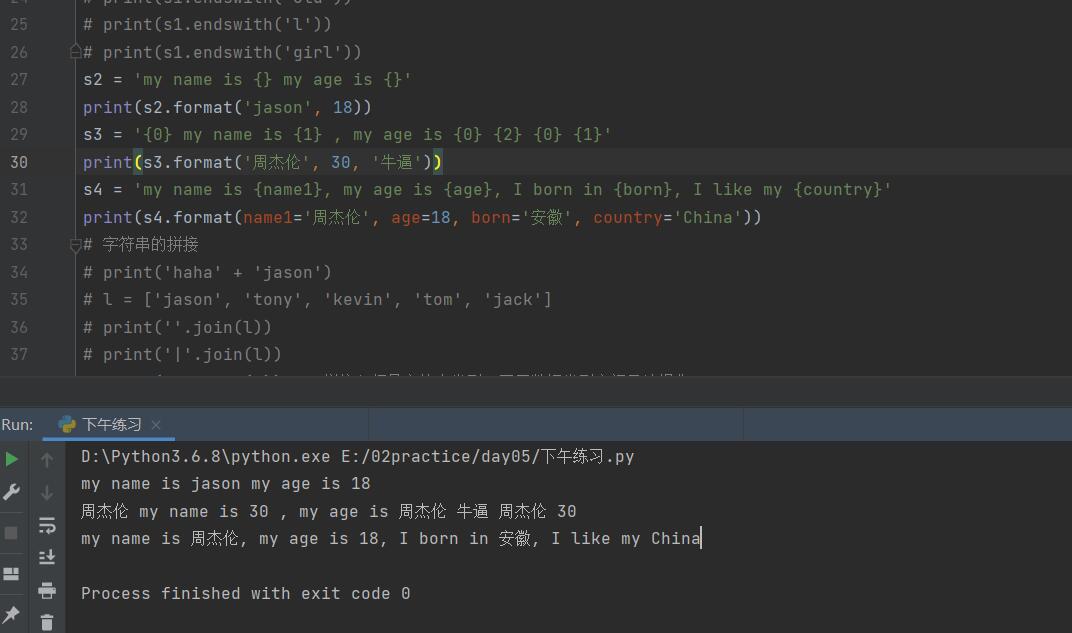
10. 字符串内置方法 format()
第一种玩法 相当于%s占位符
s2 = 'my name is {} my age is {}'
print(s2.format('jason',18)) # my name is jason my age is 18
第二种玩法 大括号内写索引值可以打破顺序 并且可以反复使用相同位置的数据
s3 = '{1} my name is {1} my age is {0} {0} {0} {1} {1}'
print(s3.format('jason', 18))
第三种玩法 大括号内写变量名
s4 = '{name1} my name is {name1} my age is {age} {name1} {name1}'
print(s4.format(name1='jason', age=18))
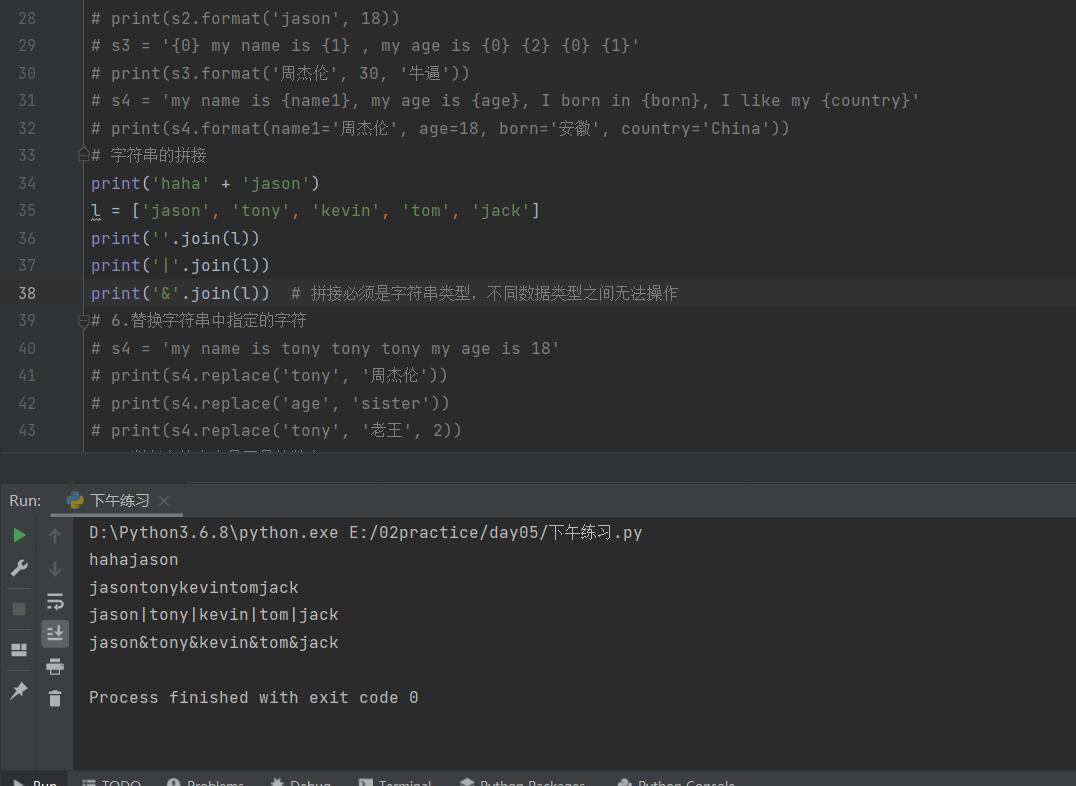
11.字符串的拼接
方式1 字符串相加
print('hello' + 'world')
方式2 join方法
12.替换字符串中指定的字符
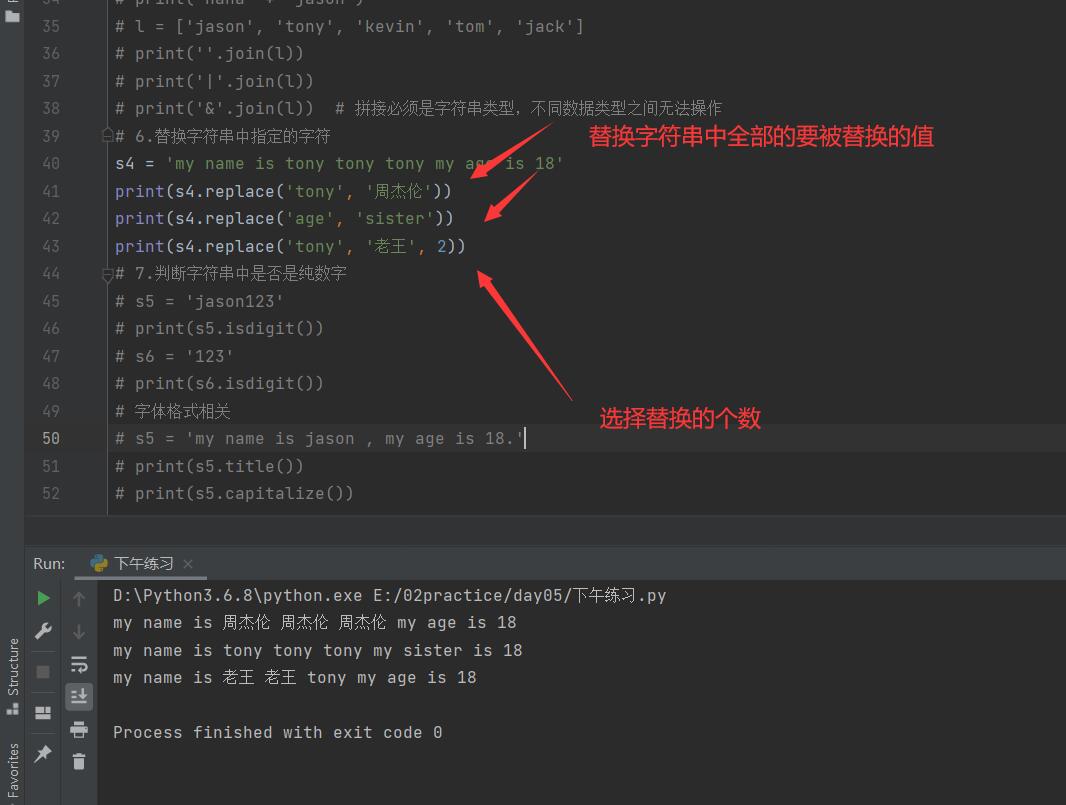
13. 判断字符串中是否是纯数字
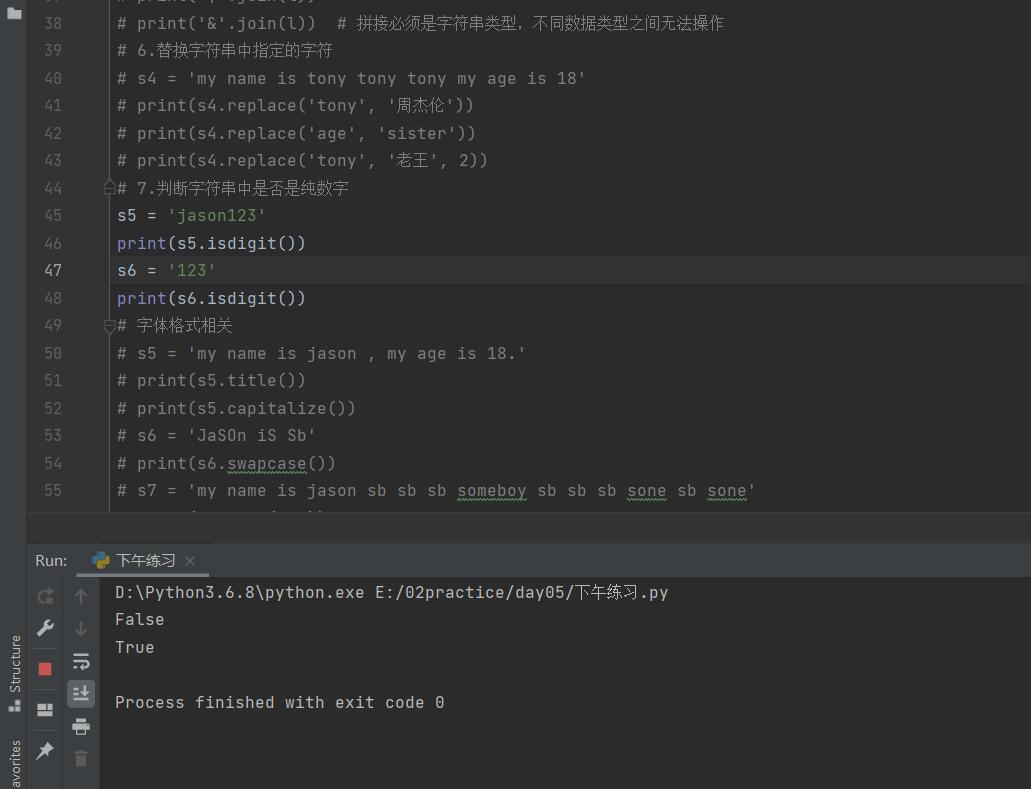
'''实际案例'''
guess_age = input('请输入猜测的年龄>>>:').strip()
if guess_age.isdigit():
guess_age = int(guess_age)
else:
print('你能不能好好输')
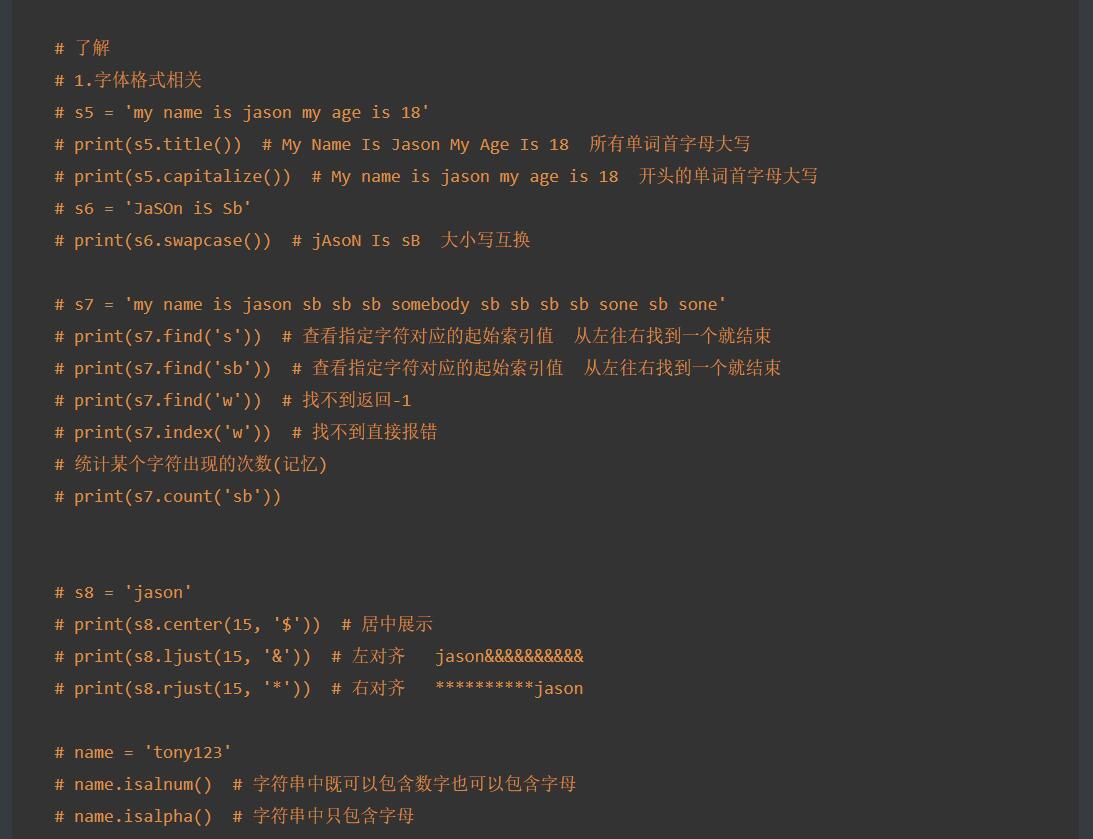
14. 需要简单了解的内置方法
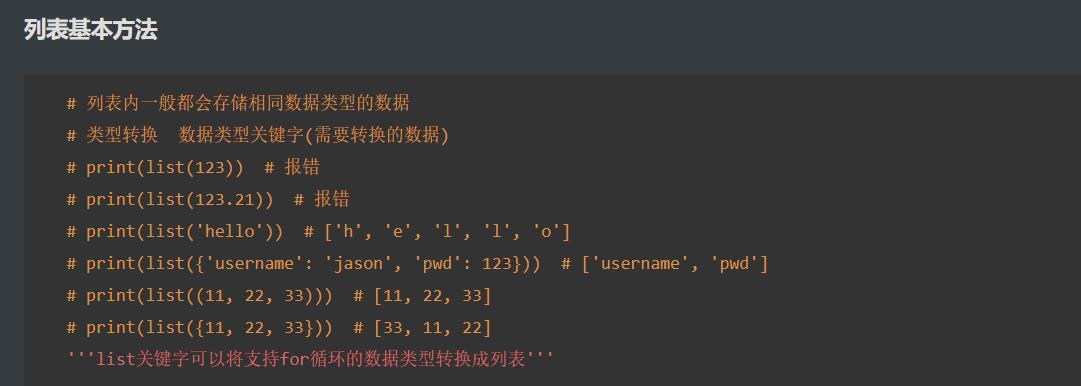
4.列表的内置方法list

- 列表内一般都会存储相同数据类型的数据
- 只有可迭代对象的数据类型才能转换成列表,不然就会报错
1. 修改值
name_list = ['jason', 'kevin', 'tony', 'jack']
name_list[0] = 666
print(name_list) # [666, 'kevin', 'tony', 'jack']
2. 添加值
方式1 尾部追加(将括号内的数据当成一个整体追加到列表末尾)
name_list.append(666)
print(name_list) # ['jason', 'kevin', 'tony', 'jack', 666]
name_list.append([666, 777, 888, 999])
print(name_list) # ['jason', 'kevin', 'tony', 'jack', [666, 777, 888, 999]]
方式2 插入元素(将括号内的数据当成一个整体插入到索引指定位置)
name_list.insert(0, 'heiheihei')
print(name_list) # ['heiheihei', 'jason', 'kevin', 'tony', 'jack']
name_list.insert(2, 'hahaha')
print(name_list) # ['jason', 'kevin', 'hahaha', 'tony', 'jack']
name_list.insert(0, [11, 22, 33])
print(name_list)
方式3 扩展元素(相当于for循环+append操作)
name_list.extend([111, 222, 333, 444, 555])
print(name_list) # ['jason', 'kevin', 'tony', 'jack', 111, 222, 333, 444, 555]
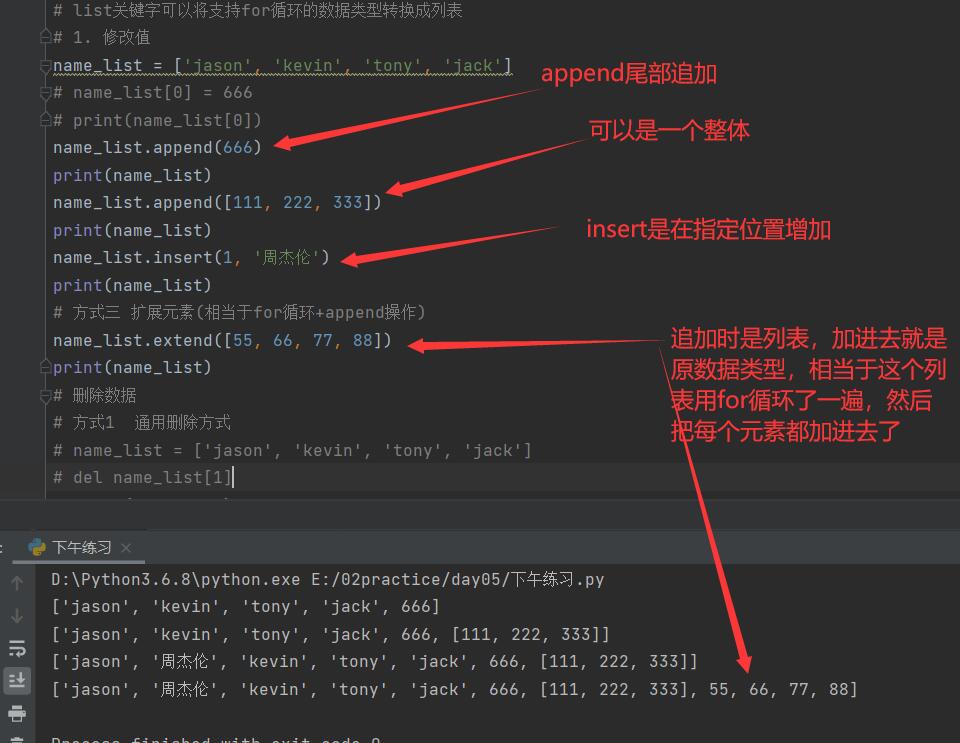
3. 列表删除数据
删除数据
方式1 通用删除方式
del name_list[1] # 根据索引直接删除 del是关键字delete缩写
print(name_list) # ['jason', 'tony', 'jack']
方式2 remove() 括号内指定需要移除的元素值
name_list.remove('jason')
print(name_list)
print(name_list.remove('jason')) # None
方式3 pop() 括号内指定需要弹出的元素索引值 括号内如果不写参数则默认弹出列表尾部元素
name_list.pop(1)
print(name_list)
name_list.pop()
print(name_list)
print(name_list.pop()) # jack
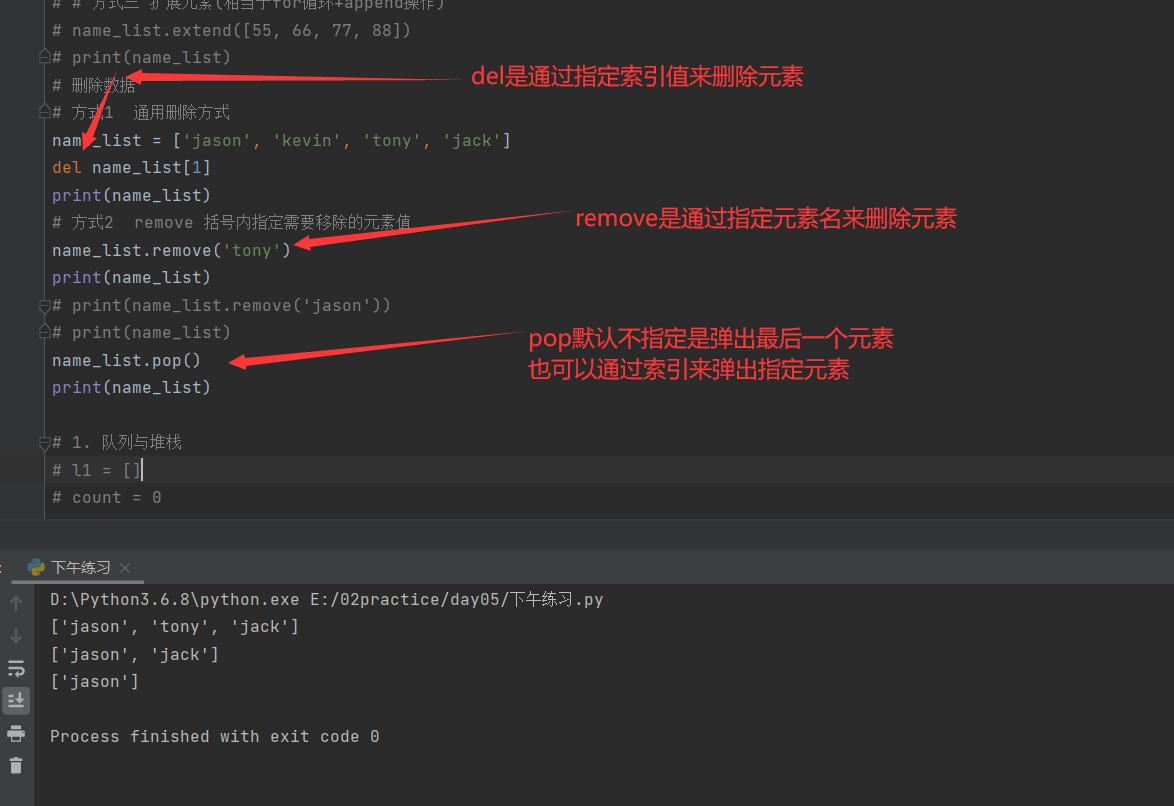
3. 列表删除数据
删除数据
方式1 通用删除方式
del name_list[1] # 根据索引直接删除 del是关键字delete缩写
print(name_list) # ['jason', 'tony', 'jack']
方式2 remove() 括号内指定需要移除的元素值
name_list.remove('jason')
print(name_list)
print(name_list.remove('jason')) # None
方式3 pop() 括号内指定需要弹出的元素索引值 括号内如果不写参数则默认弹出列表尾部元素
name_list.pop(1)
print(name_list)
name_list.pop()
print(name_list)
print(name_list.pop()) # jack
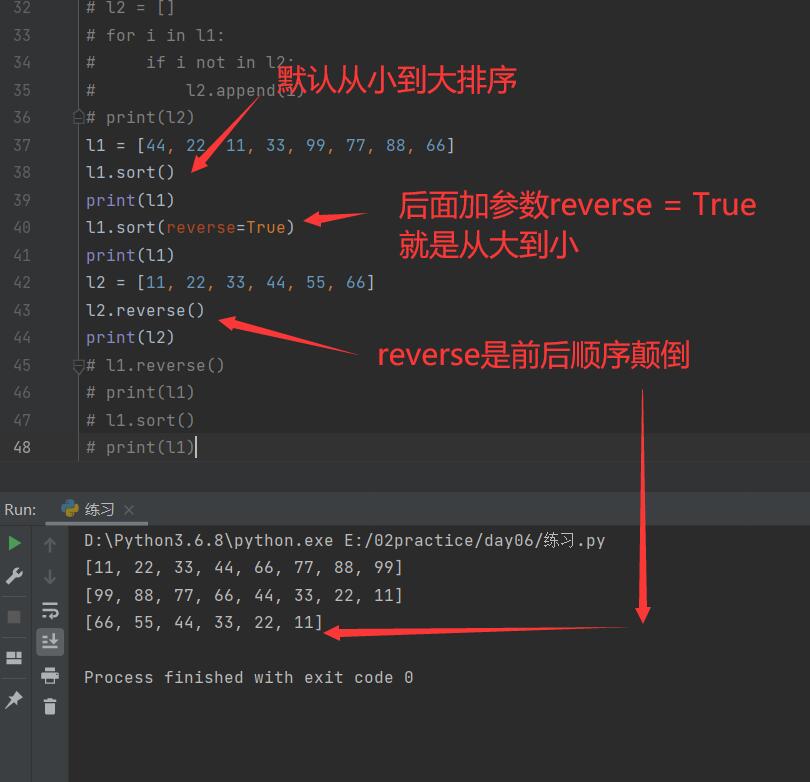
4.升序降序
l1 = [44, 22, 11, 33, 99, 77, 88, 66]
# l1.sort() # 默认是升序
# l1.sort(reverse=True) # 参数指定 降序
# print(l1)
# l1.reverse() # 顺序颠倒
# print(l1)
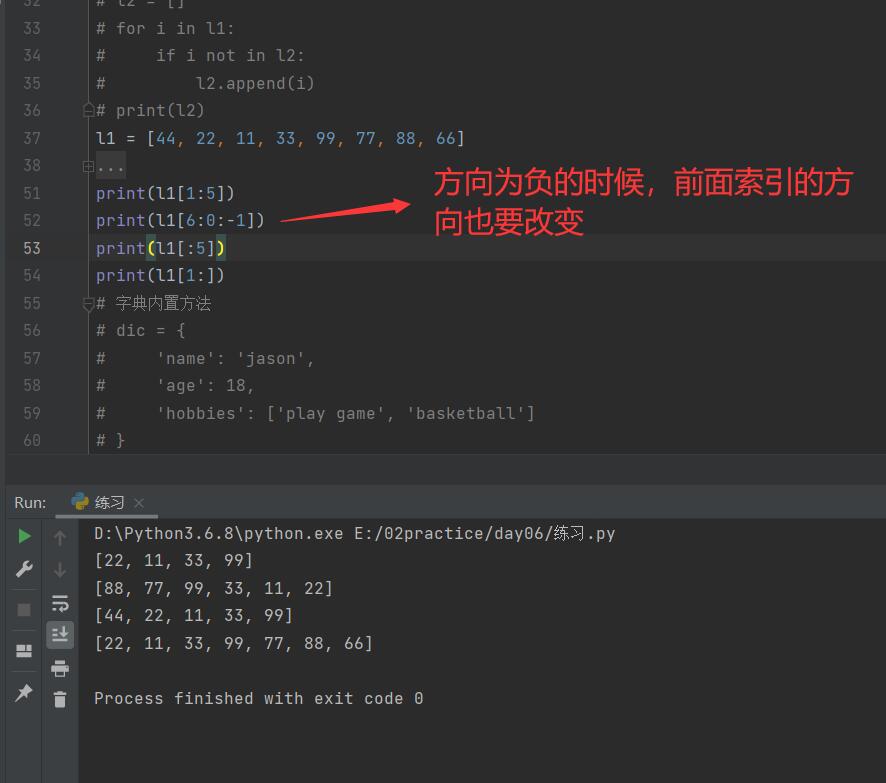
5. 列表的切片
l1 = [44, 22, 11, 33, 99, 77, 88, 66]
# print(l1[1:5])
# print(l1[::-1]) # 冒号左右两边不写数字默认全都要
# print(l1[:5]) # [44, 22, 11, 33, 99] 左边不写默认从头开始
# print(l1[1:]) # [22, 11, 33, 99, 77, 88, 66] 右边不写默认到尾部
6. 列表比较大小
ll1 = [999, 111]
ll2 = [111, 222, 333, 444, 555, 666, 777, 888]
print(ll1 > ll2) # True 列表比较运算采用相同索引元素比较 只要有一个比出了结果就直接得出结论
s1 = 'hello world'
s2 = 'abc'
print(s1 > s2) # 字符串比较大小也是按照索引位置内部转成ASCII对应的数字比较
5. 字典的内置方法dict

1. 取值
dic = {
'name': 'jason',
'age': 18,
'hobbies': ['play game', 'basketball']
}
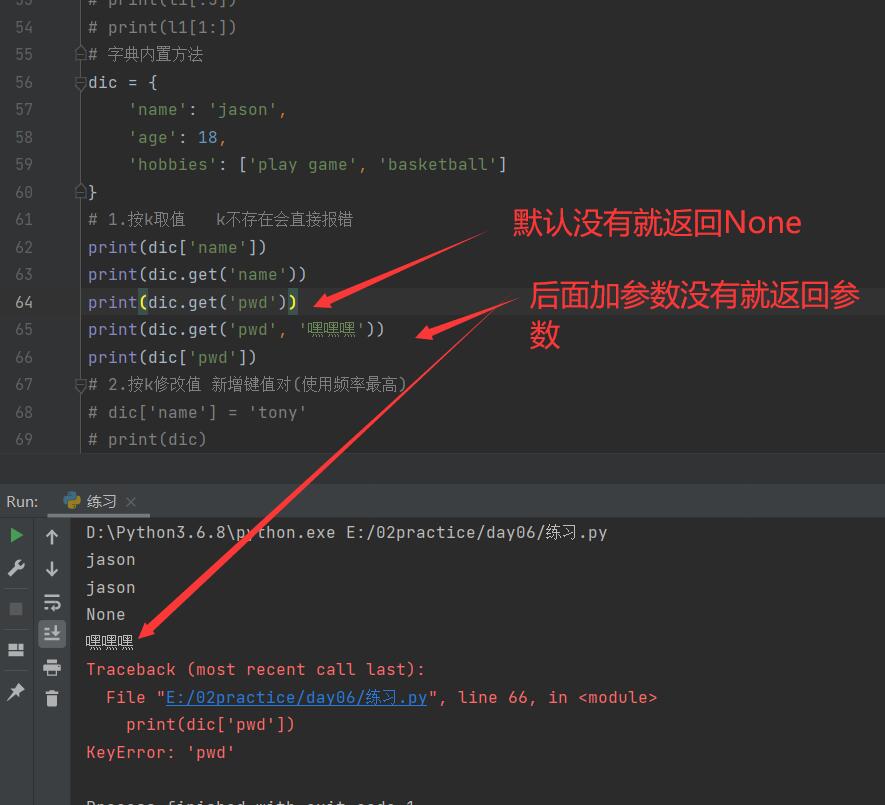
print(dic['name'])
print(dic['pwd']) # 报错 这个方法不推荐使用
print(dic.get('name')) # jason 强烈推荐
# 即使k不存在 不会报错,会返回值:None
print(dic.get('pwd', '哈哈哈')) # 'pwd'不存在返回值:'哈哈哈' 强烈推荐
2. 修改值
dic = {
'name': 'jason',
'age': 18,
'hobbies': ['play game', 'basketball']
}
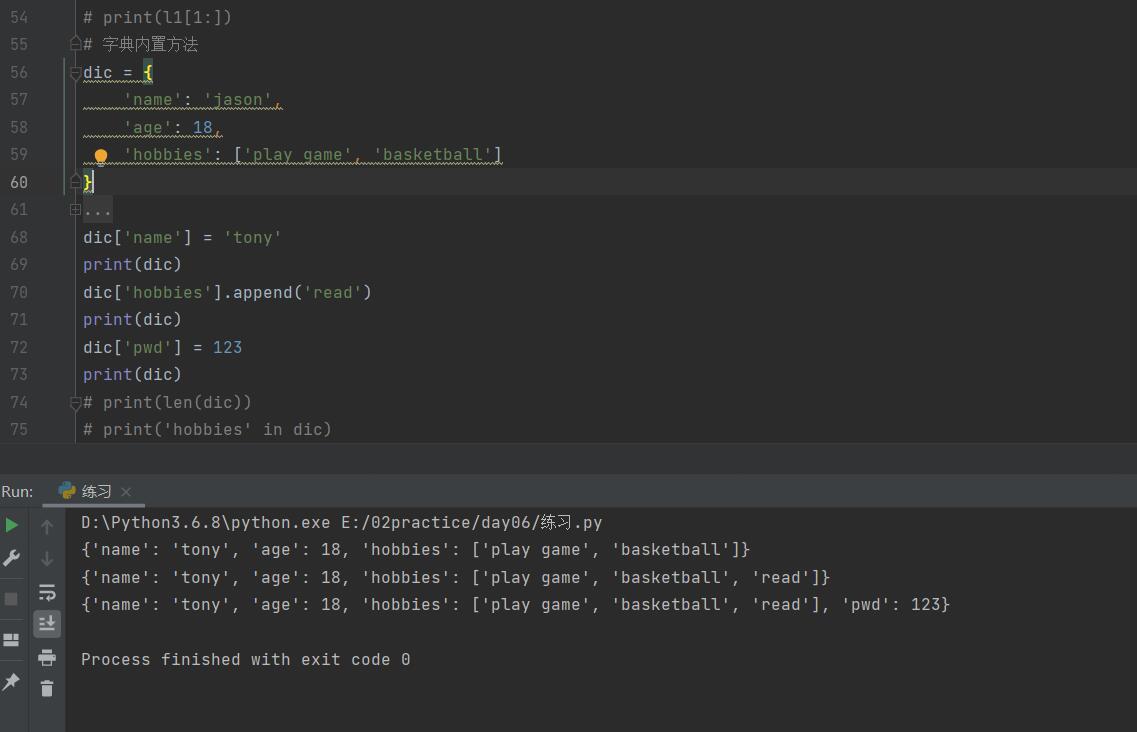
# 按k修改值 新增键值对(使用频率最高)
dic['name'] = 'jasonNB' # 键存在为修改值
print(dic)
dic['hobbies'].append('read')
print(dic)
dic['pwd'] = 123 # 键不存在为新增键值对
print(dic)
3. 统计键值对个数
dic = {
'name': 'jason',
'age': 18,
'hobbies': ['play game', 'basketball']
}
print(len(dic)) # 3
4. 成员运算
print('jason' in dic) # False
print('name' in dic) # True
# 因为字典只暴露K值,V不暴露给外界
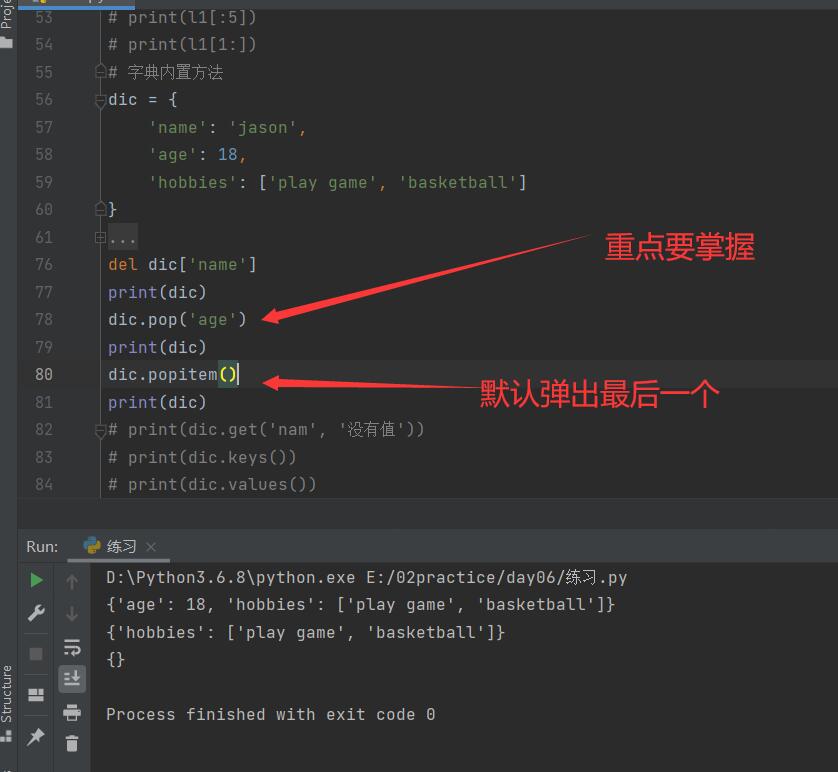
5. 删除元素
# 方式1
del dic['name']
print(dic)
# 方式2 指定k弹出键值对 给出v
print(dic.pop('age'))
print(dic)
# 方式2是最经常用的,其他基本不用
# 方式3 弹出键值对 组织成元组的形式 第一个元素是k第二个元素是v(了解)
print(dic.popitem())
print(dic)
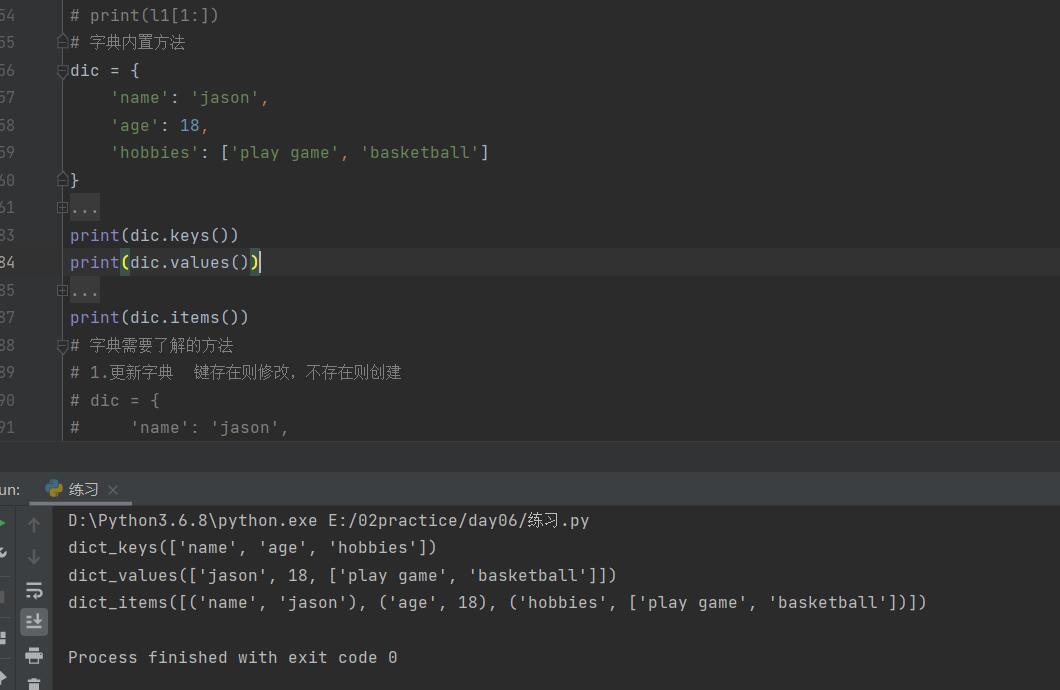
6. keys( )、values( )、item( )
print(dic.keys()) # dict_keys(['name', 'age', 'hobbies']) 获取字典所有的键 看成列表即可
print(dic.values()) # dict_values(['jason', 18, ['play game', 'basketball']]) 获取字典所有的值 看成列表即可
print(dic.items()) # dict_items([('name', 'jason'), ('age', 18), ('hobbies', ['play game', 'basketball'])])
# 获取字典里面所有的键值对 组织成列表套元组的形式 元组内有两个元素 第一个是k第二个是v
7. 字典需要了解的方法
dic = {
'name': 'jason',
'age': 18,
'hobbies': ['play game', 'basketball']
}
# 1.更新字典 键存在则修改 不存在则创建
dic.update({'name': 'jasonNB', 'pwd': 123})
print(dic)
# 2.当键存在的情况下 不修改而是获取该键对应的值
print(dic.setdefault('name', 'jasonNB'))
print(dic)
# 当键不存在的情况下 新增一组键值对 并且该方法的结果是新增的值
print(dic.setdefault('pwd', '123'))
print(dic)
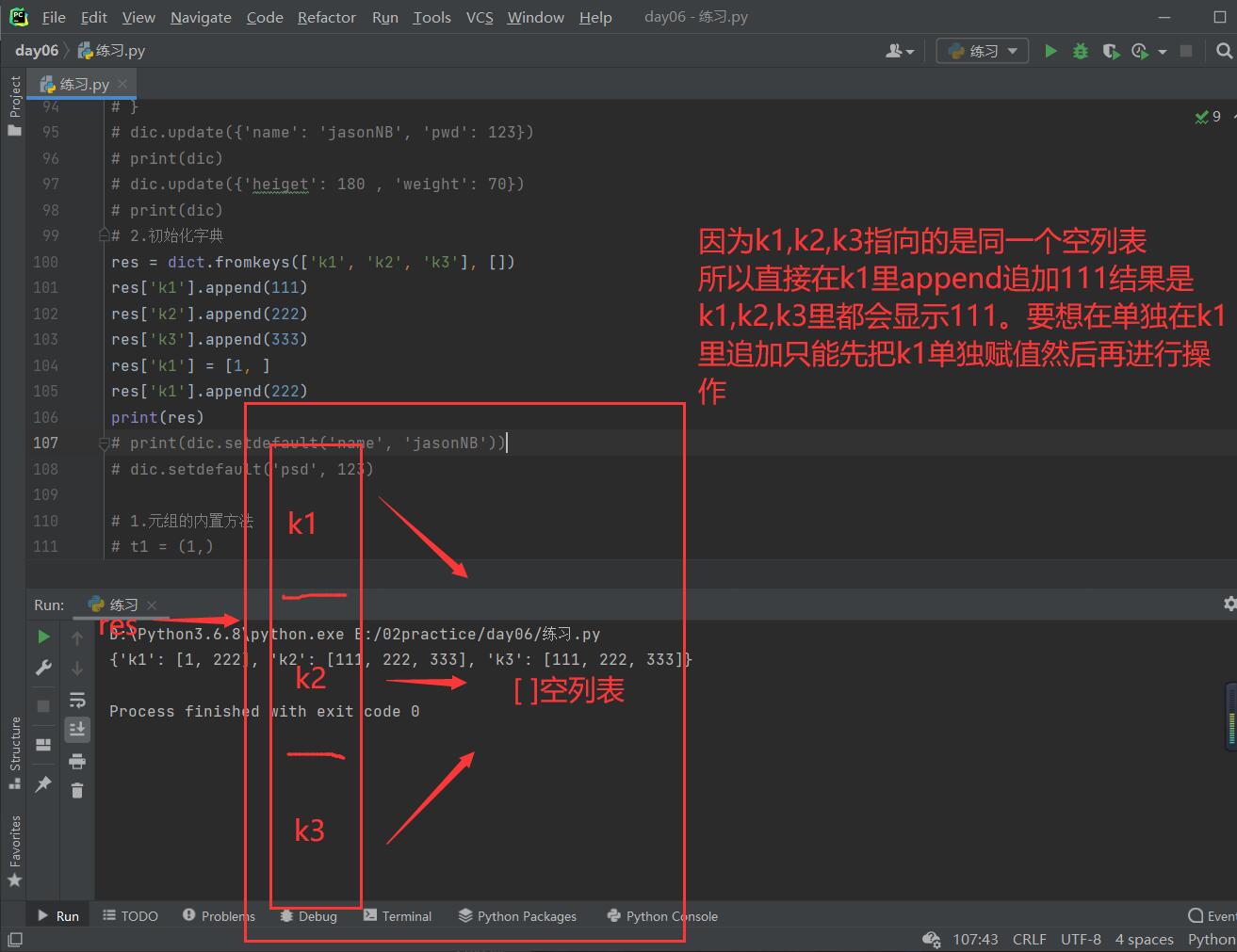
# 3.初始化字典
print(dict.fromkeys(['k1', 'k2', 'k3'], []))
'''笔试题'''
res = dict.fromkeys(['k1', 'k2', 'k3'], [])
res['k1'].append(111)
res['k2'].append(222)
res['k3'].append(333)
res['k1'] = [111,222,333]
res['k1'].append(444)
print(res)
6. 元组的内置方法tuple
1. 元组的最重要的规则

小括号括起来 内部存放多个元素 元素与元素逗号隔开
元素可以是任意数据 但是元组内元素不支持‘修改’(索引指向的元素的内存地址不能改变)
也可以简单的认为它是一个不可变的列表
# 元组第一道笔试题
t1 = (111) # 整型
t2 = (11.11) # 浮点型
t3 = ('hello') # 字符串
'''元组哪怕内部只有一个元素 也需要加上逗号'''
t1 = (111,) # 元组
t2 = (11.11,) # 元组
t3 = ('hello',) # 元组
'''容器类型:内部可以存放多个值的数据类型都可以称之为容器类型
建议:所有的容器类型在存储数据的时候 如果内部只有一个元素
那么也推荐你加上逗号
2. 索引取值、切片操作、步长、统计个数、for循环
t = (111, 222, 333, 444, 555)
# 1.索引取值
print(t[2])
print(t[-1])
# 2.切片操作
print(t[1:5])
print(t[1:])
print(t[:])
# 3.步长
print(t[1:5:2])
4.统计元组内元素的个数
print(len(t)) # 5
# 5.for循环
for i in t:
print(i)
3. 类型转换
# 类型转换 能够支持for循环的数据都可以转换成元组
print(tuple(111))
print(tuple(11.11))
print(tuple('hello')) # ('h', 'e', 'l', 'l', 'o')
print(tuple([11,22,33])) # (11, 22, 33)
print(tuple({'name':'jason','pwd':123})) # ('name', 'pwd')
7. 集合set
集合是大括号括起来,里面有多个元素,元素与元素之间用逗号隔开,元素类型是不可变类型,不能有重复的元素。
1. 去重
# 1.定义空集合需要使用关键字set
s1 = set()
# 2.类型转换 能够支持for循环的数据类型都可以转成集合(元素要是不可变类型)
'''集合内元素是无序的'''
# 去重
s1 = {1, 2, 2, 2, 3, 4, 3, 4, 3, 1, 2, 3, 2, 1, 2, 3, 2, 1, 2, 3}
print(s1) # {1, 2, 3, 4}
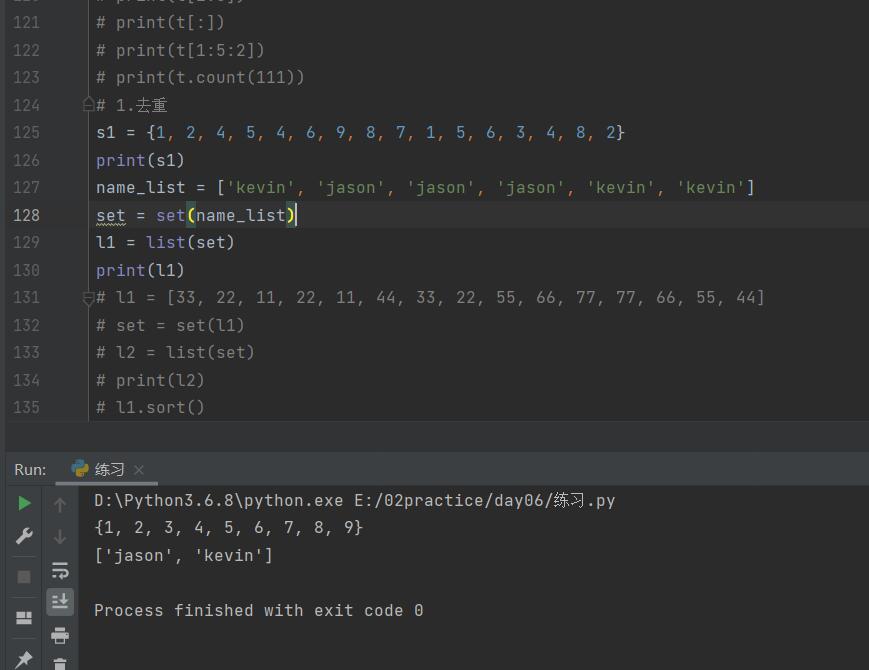
name_list = ['kevin', 'jason', 'jason', 'jason', 'kevin', 'kevin']
# 1.先将列表转换成集合
s1 = set(name_list)
# 2.再将去重之后的集合转换成列表
l1 = list(s1)
print(l1)
"""课堂练习题"""
ll = [33, 22, 11, 22, 11, 44, 33, 22, 55, 66, 77, 77, 66, 55, 44]
# 基本要求:去重即可
s1 = set(ll)
ll1 = list(s1)
print(ll1)
# 拔高要求:去重并保留原来的顺序
1.先定义一个新列表
new_list = []
# 2.for循环ll列表
for i in ll:
# 3.判断当前元素是否在新列表中
if i not in new_list:
# 3.1 如果不在 则添加到新列表
new_list.append(i)
# 3.2 如果在 则不管
print(new_list)
2. 集合关系运算
# 关系运算
"""两个群体之间做差异比较 共同好友 共同关注..."""
friends1 = {"zero", "kevin", "jason", "eg"} # 用户1的好友们
friends2 = {"Jy", "ricky", "jason", "eg"} # 用户2的好友们
# 1.求两个用户的共同好友
print(friends1 & friends2) # {'jason', 'eg'}
# 2.求两个用户所有的好友
print(friends1 | friends2) # {'kevin', 'ricky', 'jason', 'zero', 'Jy', 'eg'}
# 3.求用户1独有的好友
print(friends1 - friends2) # {'zero', 'kevin'}
# 4.求用户2独有的好友
print(friends2 - friends1) # {'ricky', 'Jy'}
# 5.求用户1和用户2各自的好友
print(friends1 ^ friends2) # {'Jy', 'zero', 'kevin', 'ricky'}
# 6.父集与子集
s1 = {11, 22, 33, 44}
s2 = {11, 33}
print(s1 > s2) # 判断s1是否是s2的父集 True
print(s2 < s1) # 判断s2是否是s1的子集 True
'''死记硬背'''
python数据类型内置的方法的更多相关文章
- Python 的内置字符串方法(收藏专用)
Python 的内置字符串方法(收藏专用) method 字符串 string python3.x python 4.7k 次阅读 · 读完需要 44 分钟 5 字符串处理是非常常用的技能,但 ...
- python数据类型内置方法
内容概要 列表内置方法 字典内置方法 字符串转换成字典的方法 eval() 元组内置方法 元组相关笔试题 集合内置方法 列表内置方法 l1 = [2, 4, 5, 7, 3, 9, 0, 6] # 升 ...
- python数据类型内置方法 字符串和列表
1.字符串 内置方法操作# a = 'qqssf'#1. print(a[-1:]) #按索引取,正向从0开始,反向从-1开始# print(len(a)) #取长度# a = 'qqssf'# 2. ...
- Python:内置split()方法
描述 Python split()通过指定分隔符对字符串进行切片,如果参数num 有指定值,则仅分隔 num 个子字符串 语法 split()方法语法: str.split(str="&qu ...
- python常用数据类型内置方法介绍
熟练掌握python常用数据类型内置方法是每个初学者必须具备的内功. 下面介绍了python常用的集中数据类型及其方法,点开源代码,其中对主要方法都进行了中文注释. 一.整型 a = 100 a.xx ...
- python循环与基本数据类型内置方法
今天又是充满希望的一天呢 一.python循环 1.wuile与else连用 当while没有被关键'break'主动结束的情况下 正常结束循环体代码之后会执行else的子代码 "" ...
- 【python基础】第09回 数据类型内置方法 01
本章内容概要 1.数据类型的内置方法简介 2.整型相关方法 3.浮点型相关方法 4.字符串相关方法 5.列表相关方法 本章内容详情 1.数据类型的内置方法简介 数据类型是用来记录事物状态的,而事物的状 ...
- python中其他数据类型内置方法
补充字符串数据类型内置方法 1.移除字符串首尾的指定字符可以选择方向1: s1 = '$$$jason$$$' print(s1.strip('$')) # jason print(s1.lstrip ...
- Python成长之路第二篇(1)_数据类型内置函数用法
数据类型内置函数用法int 关于内置方法是非常的多这里呢做了一下总结 (1)__abs__(...)返回x的绝对值 #返回x的绝对值!!!都是双下划线 x.__abs__() <==> a ...
随机推荐
- ArcMap进行天空开阔度(SVF)分析
这里的SVF并不是生物学或医学的(Stromal Vascular Fraction),而是指GIS中的(Sky View Factor,SVF),即为(城市)天空开阔度. 城市天空开阔度(Sky V ...
- 记一次解决关机蓝屏 | MULTIPLE_IRP_COMPLETE_REQUESTS | klflt.sys
已经解决蓝屏问题,原因是卡巴斯基安全软件驱动导致,需要卸载卡巴斯基安全软件,详细过程如下. 一.关机时蓝屏 Win10系统,在关机动画快结束时突然蓝屏,提示:你的设备遇到问题,需要重启,终止代码:MU ...
- JavaWeb 10_Filter过滤器
一.什么是Filter? 1.Filter 过滤器它是JavaWeb的三大组件之一-.三大组件分别是: Servlet 程序.Listener 监听器.Filter 过滤器2.Filter 过滤器它是 ...
- Ubuntu20安装nodejs和npm并切换阿里源
参考 阿里巴巴开源镜像站 Ubuntu20安装npm并切换阿里源 安装直接在终端执行 sudo apt-get install nodejs npm没有安装上就执行 sudo apt-get inst ...
- kubernetes内yaml格式
yaml格式的pod定义文件完整内容: apiVersion: v1 #必选,版本号,例如v1 可通过 kubectl api-versions 获取 kind: Pod #必选,Pod metada ...
- JDK8的 CHM 为何放弃分段锁
概述 我们知道, 在 Java 5 之后,JDK 引入了 java.util.concurrent 并发包 ,其中最常用的就是 ConcurrentHashMap 了, 它的原理是引用了内部的 Seg ...
- 【网鼎杯2020白虎组】Web WriteUp [picdown]
picdown 抓包发现存在文件包含漏洞: 在main.py下面暴露的flask的源代码 from flask import Flask, Response, render_template, req ...
- loj6077. 「2017 山东一轮集训 Day7」逆序对
题目描述: loj 题解: 容斥+生成函数. 考虑加入的第$i$个元素对结果的贡献是$[0,i-1]$,我们可以列出生成函数. 长这样:$(1)*(1+x)*(1+x+x^2)*--*(1+x+x^2 ...
- C++ bind 和 ref
#include <functional>#include <iostream> void f(int& n1, int& n2, const int& ...
- XStream类对象把List<javaBean>()转成json数据
[省市联动] Servlet端: XStream把list转成json数据 //JSONArray-->变成数组/集合[] //JSONObject-->变成简单的数据{name:ayee ...