后缀自动机(SAM)+广义后缀自动机(GSA)
经过一顿操作之后竟然疑似没退役0 0
你是XCPC选手吗?我觉得我是!
稍微补一点之前丢给队友的知识吧,除了数论以外都可以看看,为Dhaka和新队伍做点准备...
不错的零基础教程见 IO WIKI - 后缀自动机,这篇就从自己的角度总结一下吧,感觉思路总是和别人不一样...尽量用我比较能接受的语言和逻辑重新组织一遍。
注意:在本文中,字符串的下标从1开始。
目前的 SAM 模板:


const int N=100005;
const int C=26; //注意检查字符集大小! //在结构题外开任何与SAM状态相关的数组,都需要N<<1
struct SuffixAutomaton
{
int sz,lst; //状态数上限=2|S|-1 int len[N<<1],link[N<<1];
int nxt[N<<1][C];
//map<char,int> nxt[N<<1];
//extend(char),并使用nxt[clone]=nxt[q]替换memcpy SuffixAutomaton()
{
len[0]=0,link[0]=-1;
lst=sz=0;
} void extend(int c)
{
int cur=++sz;
len[cur]=len[lst]+1; int p=lst;
while(p!=-1 && !nxt[p][c])
nxt[p][c]=cur,p=link[p]; if(p==-1)
link[cur]=0;
else
{
int q=nxt[p][c];
if(len[p]+1==len[q])
link[cur]=q;
else
{
int clone=++sz;
len[clone]=len[p]+1;
link[clone]=link[q];
memcpy(nxt[clone],nxt[q],C*4); while(p!=-1 && nxt[p][c]==q)
nxt[p][c]=clone,p=link[p];
link[q]=link[cur]=clone;
}
}
lst=cur;
} int id[N<<1]; //构建完成后,id顺序为len递增(逆拓扑序)【仅可排一次】
void sort()
{
static int bucket[N<<1]; memset(bucket,0,sizeof(bucket));
for(int i=1;i<=sz;i++)
bucket[len[i]]++;
for(int i=1;i<=sz;i++)
bucket[i]+=bucket[i-1];
for(int i=1;i<=sz;i++)
id[bucket[len[i]]--]=i;
}
}sam;
目前的 GSA 模板:
typedef pair<int,int> pii; const int N=1000005;
const int C=26; //注意检查字符集大小! //在结构题外开任何与SAM状态相关的数组,都需要N<<1
struct GeneralSuffixAutomaton
{
int sz; //状态数上限=2|S|-1 int len[N<<1],link[N<<1];
int nxt[N<<1][C];
//map<char,int> nxt[N<<1];
//extend(int,char) GeneralSuffixAutomaton()
{
len[0]=0,link[0]=-1;
sz=0;
} //向trie树上插入一个字符串
void insert(char *s,int n)
{
for(int i=1,cur=0;i<=n;i++)
{
int c=s[i]-'a';
if(!nxt[cur][c])
nxt[cur][c]=++sz;
cur=nxt[cur][c];
}
} //扩展GSA,对于lst的c转移进行扩展
int extend(int lst,int c)
{
int cur=nxt[lst][c];
len[cur]=len[lst]+1; int p=link[lst];
while(p!=-1 && !nxt[p][c])
nxt[p][c]=cur,p=link[p]; if(p==-1)
link[cur]=0;
else
{
int q=nxt[p][c];
if(len[p]+1==len[q])
link[cur]=q;
else
{
int clone=++sz;
len[clone]=len[p]+1;
link[clone]=link[q];
for(int i=0;i<C;i++)
nxt[clone][i]=len[nxt[q][i]]?nxt[q][i]:0; while(p!=-1 && nxt[p][c]==q)
nxt[p][c]=clone,p=link[p];
link[q]=link[cur]=clone;
}
}
return cur;
} //基于trie树建立GSA
void build()
{
queue<pii> Q;
for(int i=0;i<C;i++)
if(nxt[0][i])
Q.push(pii(0,i)); while(!Q.empty())
{
pii tmp=Q.front();
Q.pop(); int cur=extend(tmp.first,tmp.second);
for(int i=0;i<C;i++)
if(nxt[cur][i])
Q.push(pii(cur,i));
}
} int id[N<<1]; //构建完成后,id顺序为len递增(逆拓扑序)【仅可排一次】
void sort()
{
static int bucket[N<<1]; memset(bucket,0,sizeof(bucket));
for(int i=1;i<=sz;i++)
bucket[len[i]]++;
for(int i=1;i<=sz;i++)
bucket[i]+=bucket[i-1];
for(int i=1;i<=sz;i++)
id[bucket[len[i]]--]=i;
}
}gsa;
简单的目录:
正确性证明(其实没写啥...)
~ 背景 ~ (SAM 要解决什么问题,为什么“暴力”方法不行)
很久以前就听说过 SAM,一直有一个不明觉厉的印象,导致一直没敢看。但其实 SAM 本质上来说是一个偏板子的知识点(甚至板子也不算长),其中比较困难的地方在于对于 SAM 结构的理解,以及再次基础上对于其性质的利用。网络上的各种材料,感觉大多从一个已经有一定理解的角度来进行讲述,一开始看下来感觉有点概念不清晰。
简单来说,SAM 想要解决的是一个这样的问题:首先对于字符串 $s$ 建立一个自动机,再将另外的字符串$t$扔到自动机里面逐字符进行匹配。假设目前已经匹配到了 $t[i]$,那么这个匹配到的状态表示的意思是“$t[1:i]$ 的 $i$ 个后缀中,最长的出现在 $s$ 中的连续子字符串”。
举个例子,$s=abb$、$t=abbcab$,那么匹配到 $t[6]=b$ 时,匹配到的状态应该是 $ab$。虽然 $s$ 与 $t$ 的最长公共连续子字符串为 $abb$,但是因为 $abb$ 不是 $t[1:6]$ 的后缀,所以不是需要求的结果。
对于这个问题有一种非常暴力的做法,就是用 $s$ 的 $\dfrac{|s|\cdot (|s|-1)}{2}$ 个子串来建立 AC 自动机。在这个自动机上我们能够匹配到 $s$ 的任意连续子字符串,于是能够满足我们的需求,但是状态数直接爆炸了。我们需要一个类似这个 AC 自动机的结构(包含状态、转移边和 fail 边的自动机,通过转移边进行一次匹配,失配的时候通过 fail 边往回跳),但是状态数是 $O(|s|)$ 的。
~ 概念:endpos 等价类 ~ (规定一种将多个子串归入到同一个状态的规则)
为了将状态由 $O(|s|^2)$ 压缩到 $O(|s|)$,我们需要一个状态能够表示多个 $s$ 的子串。我们规定,若两个 $s$ 的子串 endpos 等价,则其属于同一个 SAM 状态。
那么我们首先需要了解 endpos 的概念。对于子串 $s'\in s$,其 endpos 等于其出现在 $s$ 中的右端位置的集合。举个例子来说,$s=abcabbacab$、$s'=ab$,我们可以通过肉眼发现 $s'$ 在 $s$ 中出现的位置有$[1:2]$、$[4:5]$、$[9:10]$,那么有 $\mathrm{endpos}(s')=\{2,5,10\}$。需要注意的是,$s'$ 在 $s$ 中出现的位置可能重叠,比如$s=aaaa$、$s'=aa$,那么 $s'$ 的出现位置为$[1:2]$、$[2:3]$、$[3:4]$,此时 $\mathrm{endpos}(s')=\{2,3,4\}$。
对于两个 $s$ 的子串$s_1'$、$s_2'$,如果有 $\mathrm{endpos}(s_1')=\mathrm{endpos}(s_2')$,那么我们称 $s_1'$ 与 $s_2'$ endpos 等价,其属于同一个 endpos 等价类。
下面以字符串 $s=abab$ 为例,对于其所有子串进行等价类划分:
| 子串 | endpos | 子串 | endpos |
| abab | $\{4\}$ | ba | $\{3\}$ |
| aba | $\{3\}$ | a | $\{1,3\}$ |
| bab | $\{4\}$ | b | $\{2,4\}$ |
| ab | $\{2,4\}$ | $\empty$ | / |
根据上表,一共可以划分出 $5$ 个等价类:$\mathrm{endpos}(ba,aba)=\{3\}$,$\mathrm{endpos}(bab,abab)=\{4\}$,$\mathrm{endpos}(a)=\{1,3\}$,$\mathrm{endpos}(b,ab)=\{2,4\}$,以及需要单列出来的空串 $\empty$(我们可以认为 $\mathrm{endpos}(\empty)=\{0,1,2,\cdots,|s|\}$,包含 $0$ 是为了区分形如 $s=aa\cdots a$ 时的 $\mathrm{endpos}(a)$)。
~ 概念:SAM 的状态 ~ (同一 / 不同状态中的子串具有什么性质与联系,这对于理解建立 SAM 的过程十分关键)
有了 endpos 等价类的定义,我们考虑属于同一等价类的子串具有什么样的性质。
首先,假如两个子串 $s_1'$ 与 $s_2'$ 具有相同的 $\mathrm{endpos}$,考虑一个具体的出现位置 $r\in \mathrm{endpos}$ 则有 $s_1'=s[l_1:r]$、$s_2'=s[l_2:r]$,那么显然两者必须存在后缀关系。
接着,我们考虑字符串 $s$ 的两个子串 $s_{long}'$ 与 $s_{short}'$,其中 $s_{short}'$ 是 $s_{long}'$ 的一个后缀。对于这两个子串的 endpos,显然每个 $s_{long}'$ 出现的位置上均出现了$s_{short}'$,这也就是说有:
\[\mathrm{endpos}(s_{long}')\subseteq \mathrm{endpos}(s_{short}')\]
这个式子说明,对于某个子串 $s'$ 的所有后缀,其 $\mathrm{endpos}$ 集合的大小随着后缀长度的增加而单调不增,那么属于同一状态(即 endpos 相同)的所有子串应该是一些长度连续的、互为后缀的字符串。【这里说实话有点绕,需要努力理解一下】
引用 OI WIKI 的表述,也许能更好的帮助理解 “长度连续、互为后缀”:
对于每一个状态 $v$,一个或多个子串与之匹配。我们记 $longest(v)$ 为其中最长的一个字符串,记 $len(v)$ 为它的长度。类似地,记 $shortest(v)$ 为最短的子串,它的长度为 $minlen(v)$。那么对应这个状态的所有字符串都是字符串 $longest(v)$ 的不同的后缀,且所有字符串的长度恰好覆盖区间 $[minlen(v), len(v)]$ 中的每一个整数。
举一个例子,假如字符串为 ababcabcd,那么集合划分如下,可以验证一下上述性质:
| 字符串 | endpos | 字符串 | endpos | 字符串 | endpos |
| a | $\{1,4\}$ | c | $\{3,6\}$ | ca | $\{4\}$ |
| b | $\{2,5\}$ | bc | bca | ||
| ab | abc | abca | |||
| cab | $\{5\}$ | cabc | $\{6\}$ | ||
| bcab | bcabc | ||||
| abcab | abcabc | ||||
虽然在实际中我们并不会存下一个 SAM 状态中的全部字符串,但暂时可以将每个状态形象地理解成 endpos 等价的的字符串集合,从而帮助理解建立 SAM 的过程。
从自动机匹配的角度来看的话,如果我们在 SAM 上匹配到了某一状态,这就表示自动机接受了这个字符串集合中的其中一个字符串(其实我们有办法确定具体是哪一个,但要等到学完怎么建 SAM 后才能说清楚)。
~ 概念:后缀链接 link ~ (SAM 中的 “fail” 转移边)
除了状态以外,自动机的另一个重要的组成部分就是转移。与 AC 自动机十分相似的是,后缀自动机也有 $\mathrm{nxt}$(匹配成功时)与 $\mathrm{link}$(匹配失败时,对应着 AC 自动机中的 $\mathrm{fail}$)两类转移。其中 $\mathrm{nxt}$ 的意义与 AC 自动机中的 $\mathrm{nxt}$ 完全一致,就不做展开了;需要稍微解释一下的是后缀链接 $\mathrm{link}$。
后缀链接的定义为:对于 SAM 中的一个状态 $state$,其对应 endpos 等价类中的字符串均为 $\mathrm{longest}(state)$ 的后缀(这是之前的结论);我们取一个最长的 $\mathrm{longest}(state)$ 的后缀,使得其与 $\mathrm{longest}(state)$ 不 endpos 等价(其实这个后缀就是 $\mathrm{shortest}(state)$ 再去掉最左边的一个字符,长度为 $\mathrm{minlen}(state)-1$),我们就将这个最长后缀所在的状态赋给 $\mathrm{link}(state)$。于是我们得到一个挺常用的性质:
\[\mathrm{minlen}(state)=\mathrm{len}\left(\mathrm{link}(state)\right)+1\]
根据上述定义,我们可以对上面的例子得到后缀链接(红色箭头):

我们尝试理解一下为什么失配时要跳后缀链接。对于当前已匹配到的状态 $state$,有$\mathrm{endpos}(state)=\{p_1, p_2,\cdots, p_n\}$,那么在状态 $state$ 尝试匹配字符 $c$ 失配,就表示 $s[p_1+1], s[p_2+1], \cdots, s[p_n+1]$ 均不等于 $c$(否则就存在 $\mathrm{nxt}(c)$ 的转移边),那么我们就需要舍弃一部分已匹配串的前缀(即取已匹配串的一个后缀)后再次尝试匹配。当我们通过后缀链接跳到 $\mathrm{link}(state)$ 时,这个状态的 endpos 集合更大了一些,我们说不定能找到某个新增的 $p_i$ 使得 $s[p_i+1]=c$,从而完成匹配。从这个角度来看,转移到 $\mathrm{link}(state)$ 时我们只需要舍弃最小的已匹配长度,就会带来 endpos 集合的变大,而 endpos 集合的变大则有可能新增一些 $\mathrm{nxt}$ 转移使得待匹配的字符 $c$ 被接受,这个逻辑和 AC 自动机的 $\mathrm{fail}$ 边是完全一致的。
~ SAM 的建立 ~
SAM 的建立是一个在线的过程。假如我们需要对于字符串 $s$ 构建 SAM,我们依次往 SAM 中添加每一个字符 $s[i]$ 来将 SAM 进行一次扩展,接下来细说一次扩展中需要做的事情。
首先,在未添加任何字符时,有一个初始状态对应着空集 $\empty$ 的等价类,我们将其记作 $state_0$。
在进行扩展的过程中,我们维护了一个变量:$last$。其表示在扩展字符 $s[i]$ 之前,字符串 $s[1:i-1]$ 在部分建成的 SAM 中所属的状态。初始时 $last=state_0$。
接下来,我们尝试在当前串 $s[1:i-1]$ 的后面再插入一个字符 $s[i]=c$。我们首先创建一个新的节点 $cur$,并赋值 $\mathrm{len}(cur)=\mathrm{len}(last)+1$,此时 $last$ 的转移边及 $\mathrm{link}(cur)$ 仍未确定,需要进行如下的讨论:
1. 我们从 $last$ 开始,沿着后缀链接 $\mathrm{link}$ 一直走,边走边将途径节点(包含 $last$)的 $\mathrm{nxt}(c)$ 均赋值为 $cur$,直到某个节点 $p$ 存在 $\mathrm{nxt}(c)$ 的转移边才停下。假如这样的节点 $p$ 不存在,那么我们会一直走到 $state_0$,此时我们直接令 $\mathrm{link}(cur)=state_0$ 即可完成操作。

2. 假如我们在一个节点 $p$ 停下,那么我们记 $p$ 通过字符 $c$ 转移到的节点为 $q$,即有 $\mathrm{nxt}_p(c)=q$。现在考虑 $\mathrm{len}(p)$ 与 $\mathrm{len}(q)$ 之间的关系。假如 $\mathrm{len}(p)+1=\mathrm{len}(q)$ 成立,那么我们仅需令 $\mathrm{link}(cur)=q$ 即可完成操作。
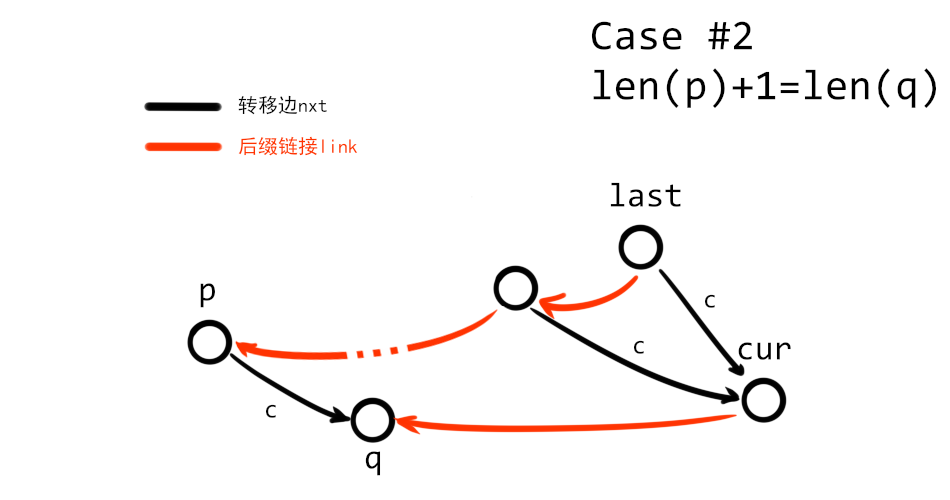
3. 假如有 $\mathrm{len}(p)+1\neq \mathrm{len}(q)$,那么需要通过依次通过四步来扩展 SAM:
(1) 新建一个节点 $clone$,设定 $\mathrm{len}(clone)=\mathrm{len}(p)+1$,并复制 $q$ 的所有 $\mathrm{nxt}$ 转移。例如,假如有 $\mathrm{nxt}_q(c)=tmp$,就同样令 $\mathrm{nxt}_{clone}(c)=tmp$;
(2) 同样是对于 $clone$,复制 $q$ 的后缀链接(即令 $\mathrm{link}(clone)=\mathrm{link}(q)$),同时抹去 $\mathrm{link}(q)$;
(3) 从 $p$ 开始(包含 $p$)沿着后缀链接 $\mathrm{link}$ 一直走到 $state_0$。假设在这个过程中经过某个节点 $x$,且存在 $\mathrm{nxt}_x(c)=q$ 的转移,就将该转移重定向至 $clone$(即令 $\mathrm{nxt}_x(c)=clone$);
(4) 将 $q$ 和 $cur$ 的后缀链接指向 $clone$,即令 $\mathrm{link}(q)=\mathrm{link}(cur)=clone$。
做完以上四步以后,最麻烦的 $\mathrm{len}(p)+1\neq \mathrm{len}(q)$ 的 case 也已经解决了。
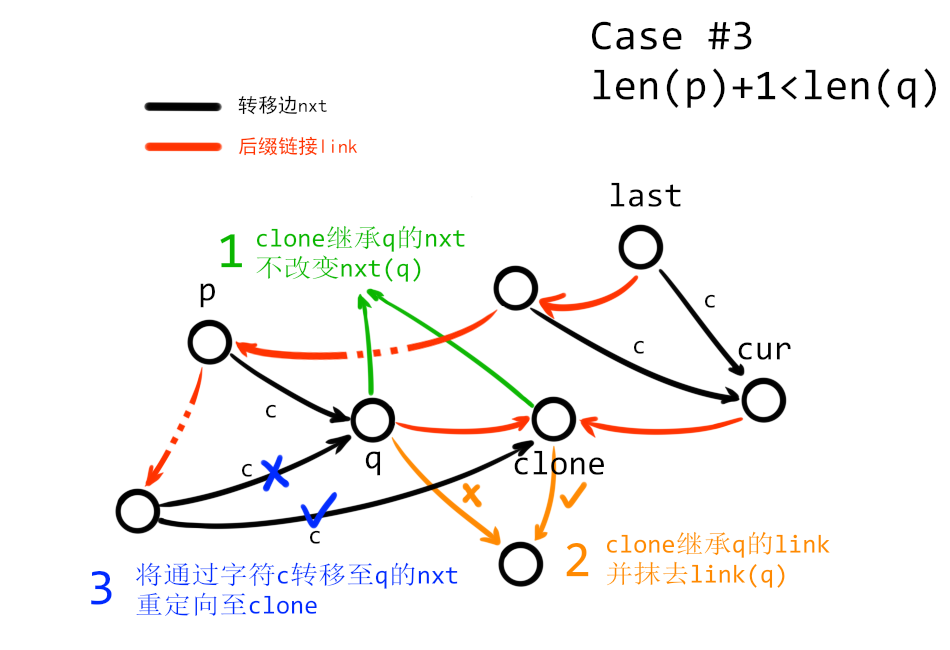
(上图中实际上节点 $p$ 也是需要重定向的,但为了表示的方便,没有画出重定向 $\mathrm{nxt}_p(c)$ 的箭头)
最后的最后,我们令 $last=cur$,为扩展下一个字符做准备。
虽然说了那么多,其实代码实现相当简单,与上面的讨论一一对应,甚至没有什么注释的必要:
int sz,lst; //状态数上限=2|S|-1
int len[N<<1],link[N<<1];
int nxt[N<<1][C];
//初始情况下,sz=lst=0,len[0]=0,link[0]=-1
//令link[0]=-1是为了标记后缀链接路径的终点 void extend(int c)
{
int cur=++sz;
len[cur]=len[lst]+1; int p=lst;
while(p!=-1 && !nxt[p][c])
nxt[p][c]=cur,p=link[p]; if(p==-1)
//case #1
link[cur]=0;
else
{
int q=nxt[p][c];
if(len[p]+1==len[q])
//case #2
link[cur]=q;
else
{
//case #3
int clone=++sz;
len[clone]=len[p]+1;
link[clone]=link[q];
memcpy(nxt[clone],nxt[q],C*4); while(p!=-1 && nxt[p][c]==q)
nxt[p][c]=clone,p=link[p];
link[q]=link[cur]=clone;
}
}
lst=cur;
}
~ 正确性证明 ~
细节有点多(懒),具体可以参考 OI WIKI - SAM - 正确性证明 以及 OI WIKI - SAM - 对操作数为线性的证明。不过对于抄板子不是那么关键。
为了便于感性的理解,我们不妨举一个扩展 SAM 的过程中最复杂的 Case #3 的例子。
字符串 $s=abb$,当仅扩展了 $ab$ 与扩展完了 $abb$ 时,SAM 的结构分别如下:

可以看出,做一次 Case #3 的扩展相当于对于一个 endpos 等价类(如图中的 $\{b,ab\}$)做拆分。更深入的分析就不展开了。
~ SAM 的性质 ~
对于一个长度为 $n$ 的字符串,SAM 的状态数是 $2n$ 级别的,转移数是 $3n$ 级别的。这个性质没什么特殊的应用,记得数组别开小就行了。
比较关键的性质在于 SAM 的后缀链接 $\mathrm{link}$ 上。
1. SAM 的后缀链接构成一个树形结构
我们不妨回顾一下后缀链接的定义:对于 SAM 中的一个状态 $state$,我们取一个最长的 $\mathrm{longest}(state)$ 的后缀,使得其与 $\mathrm{longest}(state)$ 不 endpos 等价,$\mathrm{link}(state)$ 就指向该后缀所属于的状态。
这也就是说,对于任意状态 $state$ 的后缀链接所指向的状态 $\mathrm{link}(state)$,$state$ 所包含的子串长度均长于 $\mathrm{link}(state)$ 中的子串长度(即 $\mathrm{minlen}(state)>\mathrm{len}(\mathrm{link}(state))$)。利用这个性质,我们发现后缀链接不会构成环,因为沿着后缀链接走时,所经过状态中的子串长度严格单调减。
同时,由于所有后缀链接的路径一定止于 $state_0$,所以所有后缀链接一定构成树形结构。有说法称其为 parent 树。
2. 在 parent 树上,祖先对应的字符串是子孙的后缀
上文已经回答过了,“沿着后缀链接走时,所经过状态中的子串长度严格单调减”。
稍微推广一下,我们可以求出多个字符串的最长公共后缀:对于字符串 $s_1,\cdots,s_n$,我们找到其在 SAM 上的位置 $x_1,\cdots,x_n$,那么最长公共后缀就是 $\mathrm{LCA}(x_1,\cdots,x_n)$。
3. 若某个状态存在 $\mathrm{nxt}(c)$ 转移,那么其在 parent 树上的祖先均存在 $\mathrm{nxt}(c)$ 转移
子孙存在 $\mathrm{nxt}(c)$ 转移,说明子孙出现的某个位置 $r_i\in \mathrm{endpos}(\text{子孙})$ 后面有一个字符 $c$。因为祖先是子孙的后缀,所以子孙出现的所有地方祖先均出现,那么显然有 $r_i\in \mathrm{endpos}(\text{祖先})$,则祖先也存在 $\mathrm{next}(c)$ 转移。
4. 每个状态的 $\mathrm{endpos}$ 集合为其在 parent 树中子树 $\mathrm{endpos}$ 集合的并集
我们在构建 SAM 的过程中,将 $last$ 所经过的状态提取出来,则这些状态分别包含子串 $s[1:i]$,$1\leq i\leq n$。那么我们为 $s[1:i]$ 所在的状态打上 $i$ 的标签,表示 $i$ 为该状态的一个出现位置。然后我们考虑该状态在 parent 树上的祖先们,由于祖先是子孙的后缀,那么 $i$ 也是祖先们的一个出现位置,那么我们可以将 $i$ 的标签打在 $s[1:i]$ 所在状态一直到 $state_0$ 的路径上。对于所有 $s[1:i]$ 均这样打标签,最终每个状态的 $\mathrm{endpos}$ 就是被打上的标签集合。
不过这个结论暂时还不够严谨,我们需要证明 $s[1:i]$ 所在状态的子孙均不出现在位置 $i$。这也并不困难,因为一个子串出现在位置 $i$ 当且仅当其为 $s[1:i]$ 的一个后缀,而 $s[1:i]$ 的后缀仅会存在于 $s[1:i]$ 所在状态到 $state_0$ 的路径上,一定不在 $s[1:i]$ 所在状态的子树中。
淦,虽然感觉这里有很多性质可以挖,但写的时候只能列出比较显然的几条...另外的一些 DP 相关的性质需要在实际应用中体现吧。
补充5. 在 SAM 上,对于每个节点暴力跳后缀链接到 $state_0$,总的时间复杂度是 $\mathrm{O}(n^{1.5})$
虽然在少量博客上看到这个性质,但是并没有找到证明,不是十分确定。不过有题目用到了这个性质(如 2019 ICPC 徐州的 L 题),所以大概是对的。从直观上确实比较难卡出很坏的情况。
~ 经典应用(SAM) ~
1. 所有本质不同的子串及其出现次数(SAM 性质 / parent 树上 DP)
由于 SAM 中所有状态所表示的字符串都是互不相同的,所以本质不同的子串数量就是$\sum_{state}\mathrm{len}(state)-\mathrm{minlen}(state)+1$,即把每个状态中包含的字符串数量全部加起来。
#include <map>
#include <cstdio>
#include <vector>
#include <cstring>
#include <algorithm>
using namespace std; typedef long long ll; const int N=100005;
const int C=26; //注意检查字符集大小! ll ans=0; struct SuffixAutomaton
{
int sz,lst; //状态数上限=2|S|-1 int len[N<<1],link[N<<1];
//int nxt[N<<1][C];
map<int,int> nxt[N<<1];
//extend(char),并使用nxt[clone]=nxt[q]替换memcpy SuffixAutomaton()
{
len[0]=0,link[0]=-1;
lst=sz=0;
} void extend(int c)
{
int cur=++sz;
len[cur]=len[lst]+1; int p=lst;
while(p!=-1 && !nxt[p][c])
nxt[p][c]=cur,p=link[p]; if(p==-1)
link[cur]=0;
else
{
int q=nxt[p][c];
if(len[p]+1==len[q])
link[cur]=q;
else
{
int clone=++sz;
len[clone]=len[p]+1;
link[clone]=link[q];
//memcpy(nxt[clone],nxt[q],C*4);
nxt[clone]=nxt[q]; while(p!=-1 && nxt[p][c]==q)
nxt[p][c]=clone,p=link[p];
link[q]=link[cur]=clone;
}
}
lst=cur;
ans+=len[cur]-len[link[cur]];
}
}sam; int n;
int a[N]; int main()
{
scanf("%d",&n);
for(int i=1;i<=n;i++)
scanf("%d",&a[i]); for(int i=1;i<=n;i++)
sam.extend(a[i]),printf("%lld\n",ans);
return 0;
}
另一方面,某一子串的出现次数就等于其 $\mathrm{endpos}$ 集合的大小。根据性质“每个状态的 $\mathrm{endpos}$ 集合为其在 parent 树中子树 $\mathrm{endpos}$ 集合的并集”,我们对于 $s[1:i]$ 所在状态赋为 $1$,其余状态为 $0$,然后通过在 parent 树上 dfs 求子树中 $1$ 的个数即可。
#include <cstdio>
#include <vector>
#include <cstring>
#include <algorithm>
using namespace std; typedef long long ll; const int N=1000005;
const int C=26; //注意检查字符集大小! struct SuffixAutomaton
{
int sz,lst; //状态数上限=2|S|-1 int len[N<<1],link[N<<1];
int nxt[N<<1][C];
//map<char,int> nxt[N<<1];
//extend(char),并使用nxt[clone]=nxt[q]替换memcpy SuffixAutomaton()
{
len[0]=0,link[0]=-1;
lst=sz=0;
} void extend(int c)
{
int cur=++sz;
len[cur]=len[lst]+1; int p=lst;
while(p!=-1 && !nxt[p][c])
nxt[p][c]=cur,p=link[p]; if(p==-1)
link[cur]=0;
else
{
int q=nxt[p][c];
if(len[p]+1==len[q])
link[cur]=q;
else
{
int clone=++sz;
len[clone]=len[p]+1;
link[clone]=link[q];
memcpy(nxt[clone],nxt[q],C*4); while(p!=-1 && nxt[p][c]==q)
nxt[p][c]=clone,p=link[p];
link[q]=link[cur]=clone;
}
}
lst=cur;
} int id[N<<1]; //构建完成后,id顺序为len递增(逆拓扑序)【仅可排一次】
void sort()
{
static int bucket[N<<1]; memset(bucket,0,sizeof(bucket));
for(int i=1;i<=sz;i++)
bucket[len[i]]++;
for(int i=1;i<=sz;i++)
bucket[i]+=bucket[i-1];
for(int i=1;i<=sz;i++)
id[bucket[len[i]]--]=i;
}
}sam; int n;
char s[N]; int cnt[N<<1]; int main()
{
scanf("%s",s+1);
n=strlen(s+1); for(int i=1;i<=n;i++)
sam.extend(s[i]-'a'),cnt[sam.lst]=1; sam.sort(); ll ans=0;
for(int i=sam.sz;i>=1;i--)
{
int id=sam.id[i];
if(cnt[id]>1)
ans=max(ans,1LL*cnt[id]*sam.len[id]); cnt[sam.link[id]]+=cnt[id];
}
printf("%lld\n",ans);
return 0;
}
在以上的实现中,并没有显式地对于 parent 树进行 dfs,而是将所有状态拓扑排序后按序处理。进行拓扑排序的策略并不复杂,我们只需要按照 $\mathrm{len}(state)$ 进行一趟桶排,这样即可保证祖先($\mathrm{len}$ 较小)一定排在子孙($\mathrm{len}$ 较大)的前面,此时倒序即为一个合法的拓扑排序。
int id[N<<1]; //构建完成后,id顺序为len递增(逆拓扑序)【仅可排一次】
void sort()
{
static int bucket[N<<1]; memset(bucket,0,sizeof(bucket));
for(int i=1;i<=sz;i++)
bucket[len[i]]++;
for(int i=1;i<=sz;i++)
bucket[i]+=bucket[i-1];
for(int i=1;i<=sz;i++)
id[bucket[len[i]]--]=i;
}
2. 字典序第 K 大子串(SAM 上 DP)
我们先考虑本质相同的子串仅计算一次的情况。刚刚在计算本质不同子串数量的时候,我们利用状态的性质解决了,但实际上还有一个在 SAM 上 DP 的做法。
有这样的一个结论:一个字符串本质不同的子串数量,相当于在 SAM 上通过 $\mathrm{nxt}$ 转移产生的路径数量。我们尝试理解这个结论。首先,这样的计数一定不会少算(有子串没被算到),因为每个本质不同的子串都会在 SAM 上存在唯一对应的路径;同时,这个计数也不会多算(算到多余的子串),因为 SAM 仅接受模式串的子串。
利用这个结论,我们直接利用 DP 计算从每个状态出发的路径数量即可(由于 $\mathrm{nxt}$ 转移构成的图是一个 DAG,我们仍然可以通过令 $\mathrm{len}$ 从小到大来获得一个正拓扑序)。DP 的转移方程为 $path[x]=1+\sum_{y=\mathrm{nxt}_x(c_i)}path[y]$,需要按照逆拓扑序依次计算。
对于本质相同的子串计算出现次数的情况,将上面转移方程中的 $1$ 替换成 $cnt[x]$ 即可。
那么求字典序第 $K$ 大子串,只需要从 $state_0$ 开始贪心,每次选取最小的前缀路径数量大于等于 $K$ 的转移即可(原理同线段树上二分,只不过 SAM 上每个状态有字符集大小的分叉)。
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std; typedef long long ll; const int N=500005;
const int C=26; //注意检查字符集大小! struct SuffixAutomaton
{
int sz,lst; //状态数上限=2|S|-1 int len[N<<1],link[N<<1];
int nxt[N<<1][C];
//map<char,int> nxt[N<<1];
//extend(char),并使用nxt[clone]=nxt[q]替换memcpy SuffixAutomaton()
{
len[0]=0,link[0]=-1;
lst=sz=0;
} void extend(int c)
{
int cur=++sz;
len[cur]=len[lst]+1; int p=lst;
while(p!=-1 && !nxt[p][c])
nxt[p][c]=cur,p=link[p]; if(p==-1)
link[cur]=0;
else
{
int q=nxt[p][c];
if(len[p]+1==len[q])
link[cur]=q;
else
{
int clone=++sz;
len[clone]=len[p]+1;
link[clone]=link[q];
memcpy(nxt[clone],nxt[q],C*4); while(p!=-1 && nxt[p][c]==q)
nxt[p][c]=clone,p=link[p];
link[q]=link[cur]=clone;
}
}
lst=cur;
} int id[N<<1]; //构建完成后,id顺序为len递增(逆拓扑序)【仅可排一次】
void sort()
{
static int bucket[N<<1]; memset(bucket,0,sizeof(bucket));
for(int i=1;i<=sz;i++)
bucket[len[i]]++;
for(int i=1;i<=sz;i++)
bucket[i]+=bucket[i-1];
for(int i=1;i<=sz;i++)
id[bucket[len[i]]--]=i;
}
}sam; int n;
char s[N];
int type,K; int cnt[N<<1];
ll path[N<<1][2]; int main()
{
scanf("%s",s+1);
scanf("%d%d",&type,&K);
n=strlen(s+1); for(int i=1;i<=n;i++)
sam.extend(s[i]-'a'),cnt[sam.lst]=1; sam.sort(); for(int i=sam.sz;i>=0;i--)
{
int id=sam.id[i]; path[id][0]=1,path[id][1]=cnt[id];
for(int j=0;j<C;j++)
{
int nxt=sam.nxt[id][j];
if(nxt)
for(int k=0;k<2;k++)
path[id][k]+=path[nxt][k];
}
if(id!=-1)
cnt[sam.link[id]]+=cnt[id];
} if(path[0][type]-cnt[0]<K)
printf("-1\n");
else
{
int cur=0;
while(K)
{
for(int i=0;i<C;i++)
{
int nxt=sam.nxt[cur][i];
if(!nxt)
continue; if(path[nxt][type]>=K)
{
cur=nxt,putchar('a'+i);
K-=(type?cnt[cur]:1);
break;
}
K-=path[nxt][type];
}
}
}
return 0;
}
3. 两个字符串的最长公共子串(SAM 上匹配)
对于 $s,t$ 两个字符串,对于 $s$ 串建立 SAM,$t$ 在这个 SAM 上进行匹配,失配时跳 $\mathrm{link}$。实现上和 AC 自动机差不多。
例题:SPOJ-LCS Longest Common Substring
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std; typedef long long ll; const int N=250005;
const int C=26; //注意检查字符集大小! struct SuffixAutomaton
{
int sz,lst; //状态数上限=2|S|-1 int len[N<<1],link[N<<1];
int nxt[N<<1][C];
//map<char,int> nxt[N<<1];
//extend(char),并使用nxt[clone]=nxt[q]替换memcpy SuffixAutomaton()
{
len[0]=0,link[0]=-1;
lst=sz=0;
} void extend(int c)
{
int cur=++sz;
len[cur]=len[lst]+1; int p=lst;
while(p!=-1 && !nxt[p][c])
nxt[p][c]=cur,p=link[p]; if(p==-1)
link[cur]=0;
else
{
int q=nxt[p][c];
if(len[p]+1==len[q])
link[cur]=q;
else
{
int clone=++sz;
len[clone]=len[p]+1;
link[clone]=link[q];
memcpy(nxt[clone],nxt[q],C*4); while(p!=-1 && nxt[p][c]==q)
nxt[p][c]=clone,p=link[p];
link[q]=link[cur]=clone;
}
}
lst=cur;
} int id[N<<1]; //构建完成后,id顺序为len递增(逆拓扑序)【仅可排一次】
void sort()
{
static int bucket[N<<1]; memset(bucket,0,sizeof(bucket));
for(int i=1;i<=sz;i++)
bucket[len[i]]++;
for(int i=1;i<=sz;i++)
bucket[i]+=bucket[i-1];
for(int i=1;i<=sz;i++)
id[bucket[len[i]]--]=i;
}
}sam; int n,m;
char s[N],t[N]; int main()
{
scanf("%s%s",s+1,t+1);
n=strlen(s+1),m=strlen(t+1); for(int i=1;i<=n;i++)
sam.extend(s[i]-'a'); int ans=0,cur=0,len=0;
for(int i=1;i<=m;i++)
{
int p=cur;
while(p!=-1 && !sam.nxt[p][t[i]-'a'])
p=sam.link[p],len=sam.len[p]; if(p!=-1)
cur=sam.nxt[p][t[i]-'a'],len++;
else
cur=len=0; ans=max(ans,len);
}
printf("%d\n",ans);
return 0;
}
4. 多个字符串的最长公共子串(SAM 上匹配 + parent 树上 DP)
想同时处理所有字符串是比较困难的,我们考虑先对于一个串建立 SAM,然后对于其余的串依次求出“当匹配到状态 $state$ 时,最长的匹配长度”。
考虑对于具体某一个待匹配串 $t$,我们还是像两个字符串一样求 $t[1:i]$ 在 SAM 上匹配得到的状态以及匹配上的长度 $len$。但不同的是,我们还需要额外维护一个数组 $curlen$,表示字符串 $t$ 对于每个状态的 $\mathrm{longest}(state)$ 能匹配的最长后缀长度。更新的规则为 $curlen[x]=\mathrm{max}(curlen[x],len)$,因为 $t[1:i]$ 所对应的状态可能由多个状态转移而来,我们需要取其中最大的匹配长度。
需要注意到,我们在维护 $curlen$ 的过程中,只考虑到了 $t[1:i]$ 这不超过 $|t|$ 个状态,但实际上对于 SAM 上的任意状态均应计算 $curlen$。所以我们按照 $\mathrm{len}$ 从大到小的顺序计算没经过的状态的 $curlen$,并使用 $curlen[x]$ 来更新 $curlen[\mathrm{link}(x)]$,规则为 $curlen[\mathrm{link}(x)]=\mathrm{max}(curlen[\mathrm{link}(x)],curlen[x])$。
对于一个待匹配串 $t$ 我们能按照如上的方法求得每个状态的 $curlen$,那么所有字符串的在每个状态的最长匹配长度,就是 $ans[state]=\mathrm{min}_t(curlen_t[state])$。而最终答案为 $\mathrm{min}_{state}(ans[state])$。
例题:SPOJ-LCS2 Longest Common Substring II
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std; typedef long long ll; const int N=100005;
const int C=26; //注意检查字符集大小! struct SuffixAutomaton
{
int sz,lst; //状态数上限=2|S|-1 int len[N<<1],link[N<<1];
int nxt[N<<1][C];
//map<char,int> nxt[N<<1];
//使用nxt[clone]=nxt[q]替换memcpy SuffixAutomaton()
{
len[0]=0,link[0]=-1;
lst=0;
} void extend(int c)
{
int cur=++sz;
len[cur]=len[lst]+1; int p=lst;
while(p!=-1 && !nxt[p][c])
nxt[p][c]=cur,p=link[p]; if(p==-1)
link[cur]=0;
else
{
int q=nxt[p][c];
if(len[p]+1==len[q])
link[cur]=q;
else
{
int clone=++sz;
len[clone]=len[p]+1;
link[clone]=link[q];
memcpy(nxt[clone],nxt[q],C*4); while(p!=-1 && nxt[p][c]==q)
nxt[p][c]=clone,p=link[p];
link[q]=link[cur]=clone;
}
}
lst=cur;
} int id[N<<1]; //构建完成后,id顺序为len递增(逆拓扑序)【仅可排一次】
void sort()
{
static int bucket[N<<1]; memset(bucket,0,sizeof(bucket));
for(int i=1;i<=sz;i++)
bucket[len[i]]++;
for(int i=1;i<=sz;i++)
bucket[i]+=bucket[i-1];
for(int i=1;i<=sz;i++)
id[bucket[len[i]]--]=i;
}
}sam; int n,m;
char s[N],t[N]; int ans[N<<1],curlen[N<<1]; int main()
{
scanf("%s",s+1);
n=strlen(s+1); for(int i=1;i<=n;i++)
sam.extend(s[i]-'a');
sam.sort(); for(int i=1;i<=sam.sz;i++)
ans[i]=sam.len[i]; while(~scanf("%s",t+1))
{
m=strlen(t+1); int cur=0,len=0;
for(int i=1;i<=m;i++)
{
int p=cur,c=t[i]-'a';
while(p!=-1 && !sam.nxt[p][c])
p=sam.link[p],len=sam.len[p]; if(p!=-1)
cur=sam.nxt[p][c],len++;
else
cur=len=0; //对于同一cur,可能从多个p转移过来,故不能用len直接赋值cur
curlen[pos]=max(curlen[pos],len);
} for(int i=sam.sz;i>=1;i--)
{
int id=sam.id[i];
curlen[sam.link[id]]=max(curlen[sam.link[id]],curlen[id]);
}
for(int i=1;i<=sam.sz;i++)
ans[i]=min(ans[i],curlen[i]),curlen[i]=0;
} int fans=0;
for(int i=1;i<=sam.sz;i++)
fans=max(fans,ans[i]);
printf("%d\n",fans);
return 0;
}
~ 从 SAM 到广义 SAM ~
在上文中处理多个字符串的问题时,我们先对于其中一个字符串建立 SAM,对于剩余的字符串依次在这个 SAM 上面跑。有没有办法对于多个字符串直接建立一个自动机,使得任意字符串的任意子串都能被自动机接受?答案是肯定的。
我们考虑这样的实现:对于字符串 $s_1,\cdots,s_n$,我们首先对于 $s_1$ 使用 $extend()$ 函数依次插入建立 SAM,接着我们将 $last$ 移回 $state_0$ 并重新依次插入 $s_2$。这个实现的逻辑比较简单,对于能够“接受任意字符串的任意子串”的正确性也是比较显然的,不过在细节上存在一些问题:对于多次经过同一个状态时反复插入会产生孤立联通块,这些孤立连通块内的点在进行从 $state_0$ 开始的匹配时永远不会被走到(详见 ix35 - 悲惨故事 长文警告 关于广义 SAM 的讨论)。这种现象的存在会导致进行拓扑排序等操作时出错(一个例子为 yy1695651 - ICPC2019 G题广义SAM的基排为什么不行?)。
另一方面,上述方法的复杂度与 $\sum_i |s_i|$ 线性相关,因为相当于依次插入 $n$ 个字符串。但假如题目中的字符串不是直接给出的,而是采用 trie 树的形式,那么 $n$ 个节点的 trie 树可以产生总长为 $n^2$ 级别的字符串,其形状大概如下:
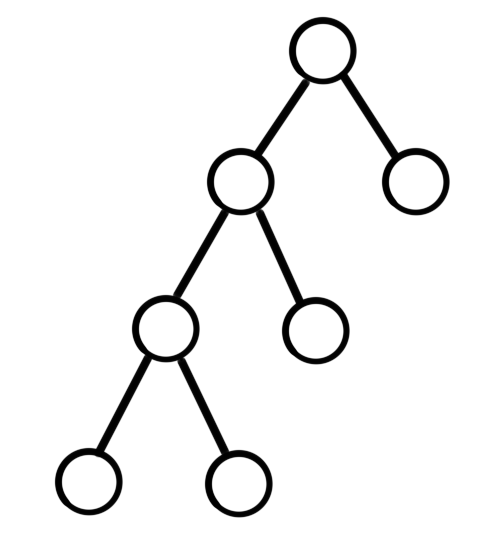
出于适用范围更广的原则,本文介绍基于 trie 树和离线 bfs 的广义 SAM 实现方法。其能够建立正确的广义 SAM,同时时空复杂度仅与 trie 树的节点数相关。
~ 广义 SAM(GSA)的建立 ~
我们从 trie 树的角度来考虑 SAM 的实现。由于模式串仅为单一字符串,所以对于 SAM 而言是基于退化为一条链的 trie 树建立的。
那么对于一个非退化的 trie 树,我们也可以在修改很少几处的情况下建立 GSA。
1. 插入顺序
在建立 SAM 的过程中,我们是按照字符串中从前到后的顺序依次扩展 SAM 的,从 trie 树的角度看就是从浅到深。那么在建立 GSA 时,我们为了保证先扩展较浅的节点、再扩展较深的节点,可以采用 bfs 进行实现。
如果不采用从浅到深的顺序,就可能出现由状态 $x$ 转移到状态 $y$、而状态 $y$ 已经先求完 $\mathrm{nxt}$ 与 $\mathrm{link}$ 的情况,此时会产生类似每次重置 $last$ 一样的孤立连通块问题,需要额外的不少讨论才能保证正确性。使用从浅到深的 bfs 则不会出现这种情况。
2. 节点标号
在建立 GSA 前,我们首先需要用 $\mathrm{nxt}$ 数组来建立 trie 树。因此每步插入的 $cur$ 都是已经建好的节点,无须开新点;只有 $clone$ 需要动态开点。同时,由于我们按照深度扩展,每次的 $last$ 都是通过 bfs 得知的,无须再额外维护 $last$ 这个变量。
3. 信息隔离
在建立 SAM 的过程中,我们在插入 $s[i]$ 时不会知道任何 $s[j]$($j>i$)的信息。但是在建立 GSA 时,我们有可能获得更深节点的信息,具体来说就是 $\mathrm{nxt}_{last}$ 可能指向比 $last$ 更深的节点。因此我们需要仔细检查之前 SAM 的板子中所有用到 $\mathrm{nxt}$ 的地方:
void extend(int c)
{
int cur=++sz;
len[cur]=len[lst]+1; int p=lst;
//nxt[lst][c]一定存在,且等于cur【会产生问题 #1】
while(p!=-1 && !nxt[p][c])
nxt[p][c]=cur,p=link[p]; if(p==-1)
link[cur]=0;
else
{
int q=nxt[p][c];
//这里我们认为dep[p]<dep[lst],
//那么假如nxt[p][c]是某次clone赋值的,说明那次clone在当前扩展操作之前,那么直接使用是ok的;
//假如nxt[p][c]是构建trie树时赋值的,则dep[q]=dep[p]+1<=dep[lst]<dep[cur],说明一定已经被扩展到了。
//综上,【不会产生问题】
if(len[p]+1==len[q])
link[cur]=q;
else
{
int clone=++sz;
len[clone]=len[p]+1;
link[clone]=link[q];
memcpy(nxt[clone],nxt[q],C*4);
//假如nxt[q][i]是构建trie树时赋值的,dep[nxt[q][i]]最大可以等于dep[cur],
//即使nxt[q][i]与cur同深度,在广义SAM的扩展过程中也有先后之分,
//所以如果扩展cur时未扩展过nxt[q][i],那么nxt[q][i]在此时应该视为0【会产生问题 #2】 while(p!=-1 && nxt[p][c]==q)
nxt[p][c]=clone,p=link[p];
//同q=nxt[p][c]处的分析,对于nxt[p][c]的使用都是安全的【不会产生问题】
link[q]=link[cur]=clone;
}
}
lst=cur;
}
我们需要对于会产生问题的两处稍加修改,具体而言:
(1) 在 #1 处,初始令 $p=\mathrm{link}[lst]$ 即可(因为 $\mathrm{nxt}[lst][c]=cur$ 在构建 trie 树时就被赋值了;而其余所有 $\mathrm{nxt}[p][c]$ 假如为非 clone 点,在 trie 树上的深度一定小于 $dep[cur]$,则可以直接使用 );
(2) 在 #2 处,我们对于 $q$ 的每一个 $\mathrm{nxt}$ 转移,均检查是否被扩展过(等价于检查 $\mathrm{len}$ 是否为 $0$),若未被扩展过,即使 $\mathrm{nxt}[q][i]\neq 0$ 也必须视为 $0$。
综合以上三点,我们可以写出如下的 GSA 的实现:
typedef pair<int,int> pii; const int N=1000005;
const int C=26; //注意检查字符集大小! //在结构题外开任何与SAM状态相关的数组,都需要N<<1
struct GeneralSuffixAutomaton
{
int sz; //状态数上限=2|S|-1 int len[N<<1],link[N<<1];
int nxt[N<<1][C];
//map<char,int> nxt[N<<1];
//extend(int,char) GeneralSuffixAutomaton()
{
len[0]=0,link[0]=-1;
sz=0;
} //向trie树上插入一个字符串
void insert(char *s,int n)
{
for(int i=1,cur=0;i<=n;i++)
{
int c=s[i]-'a';
if(!nxt[cur][c])
nxt[cur][c]=++sz;
cur=nxt[cur][c];
}
} //扩展GSA,对于lst的c转移进行扩展
int extend(int lst,int c)
{
int cur=nxt[lst][c];
len[cur]=len[lst]+1; int p=link[lst];
while(p!=-1 && !nxt[p][c])
nxt[p][c]=cur,p=link[p]; if(p==-1)
link[cur]=0;
else
{
int q=nxt[p][c];
if(len[p]+1==len[q])
link[cur]=q;
else
{
int clone=++sz;
len[clone]=len[p]+1;
link[clone]=link[q];
for(int i=0;i<C;i++)
nxt[clone][i]=len[nxt[q][i]]?nxt[q][i]:0; while(p!=-1 && nxt[p][c]==q)
nxt[p][c]=clone,p=link[p];
link[q]=link[cur]=clone;
}
}
return cur;
} //基于trie树建立GSA
void build()
{
queue<pii> Q;
for(int i=0;i<C;i++)
if(nxt[0][i])
Q.push(pii(0,i)); while(!Q.empty())
{
pii tmp=Q.front();
Q.pop(); int cur=extend(tmp.first,tmp.second);
for(int i=0;i<C;i++)
if(nxt[cur][i])
Q.push(pii(cur,i));
}
} int id[N<<1]; //构建完成后,id顺序为len递增(逆拓扑序)【仅可排一次】
void sort()
{
static int bucket[N<<1]; memset(bucket,0,sizeof(bucket));
for(int i=1;i<=sz;i++)
bucket[len[i]]++;
for(int i=1;i<=sz;i++)
bucket[i]+=bucket[i-1];
for(int i=1;i<=sz;i++)
id[bucket[len[i]]--]=i;
}
}gsa;
~ 经典应用(GSA) ~
1. 本质不同的子串数量及出现次数
本质不同的子串数量还是利用 GSA 的性质即可,等于 $\sum_{state}\mathrm{len}(state)-\mathrm{len}\left(\mathrm{link}(state)\right)$。
例题:洛谷P6139 【模板】广义后缀自动机(广义 SAM)
#include <queue>
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std; typedef long long ll;
typedef pair<int,int> pii; const int N=1000005;
const int C=26; //注意检查字符集大小! //在结构题外开任何与SAM状态相关的数组,都需要N<<1
struct GeneralSuffixAutomaton
{
int sz; //状态数上限=2|S|-1 int len[N<<1],link[N<<1];
int nxt[N<<1][C];
//map<char,int> nxt[N<<1];
//extend(int,char) GeneralSuffixAutomaton()
{
len[0]=0,link[0]=-1;
sz=0;
} //向trie树上插入一个字符串
void insert(char *s,int n)
{
for(int i=1,cur=0;i<=n;i++)
{
int c=s[i]-'a';
if(!nxt[cur][c])
nxt[cur][c]=++sz;
cur=nxt[cur][c];
}
} //扩展GSA,对于lst的c转移进行扩展
int extend(int lst,int c)
{
int cur=nxt[lst][c];
len[cur]=len[lst]+1; int p=link[lst];
while(p!=-1 && !nxt[p][c])
nxt[p][c]=cur,p=link[p]; if(p==-1)
link[cur]=0;
else
{
int q=nxt[p][c];
if(len[p]+1==len[q])
link[cur]=q;
else
{
int clone=++sz;
len[clone]=len[p]+1;
link[clone]=link[q];
for(int i=0;i<C;i++)
nxt[clone][i]=len[nxt[q][i]]?nxt[q][i]:0; while(p!=-1 && nxt[p][c]==q)
nxt[p][c]=clone,p=link[p];
link[q]=link[cur]=clone;
}
}
return cur;
} //基于trie树建立GSA
void build()
{
queue<pii> Q;
for(int i=0;i<C;i++)
if(nxt[0][i])
Q.push(pii(0,i)); while(!Q.empty())
{
pii tmp=Q.front();
Q.pop(); int cur=extend(tmp.first,tmp.second);
for(int i=0;i<C;i++)
if(nxt[cur][i])
Q.push(pii(cur,i));
}
} int id[N<<1]; //构建完成后,id顺序为len递增(逆拓扑序)【仅可排一次】
void sort()
{
static int bucket[N<<1]; memset(bucket,0,sizeof(bucket));
for(int i=1;i<=sz;i++)
bucket[len[i]]++;
for(int i=1;i<=sz;i++)
bucket[i]+=bucket[i-1];
for(int i=1;i<=sz;i++)
id[bucket[len[i]]--]=i;
}
}gsa; int n,m;
char s[N]; int main()
{
scanf("%d",&n);
for(int i=1;i<=n;i++)
{
scanf("%s",s+1);
m=strlen(s+1);
gsa.insert(s,m);
} gsa.build(); ll ans=0;
for(int i=1;i<=gsa.sz;i++)
ans+=gsa.len[i]-gsa.len[gsa.link[i]];
printf("%lld\n",ans);
return 0;
}
出现次数也是在 parent 树上 DP。
这道题中,具体一个状态产生的贡献是 $\left(\mathrm{len}(state)-\mathrm{minlen}(state)+1\right)\cdot cnt_1[state]\cdot cnt_2[state]$。
#include <queue>
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std; typedef long long ll;
typedef pair<int,int> pii; const int N=400005;
const int C=26; //注意检查字符集大小! //在结构题外开任何与SAM状态相关的数组,都需要N<<1
struct GeneralSuffixAutomaton
{
int sz; //状态数上限=2|S|-1 int len[N<<1],link[N<<1];
int nxt[N<<1][C];
//map<char,int> nxt[N<<1];
//extend(int,char) GeneralSuffixAutomaton()
{
len[0]=0,link[0]=-1;
sz=0;
} //向trie树上插入一个字符串
void insert(char *s,int n)
{
for(int i=1,cur=0;i<=n;i++)
{
int c=s[i]-'a';
if(!nxt[cur][c])
nxt[cur][c]=++sz;
cur=nxt[cur][c];
}
} //扩展GSA,对于lst的c转移进行扩展
int extend(int lst,int c)
{
int cur=nxt[lst][c];
len[cur]=len[lst]+1; int p=link[lst];
while(p!=-1 && !nxt[p][c])
nxt[p][c]=cur,p=link[p]; if(p==-1)
link[cur]=0;
else
{
int q=nxt[p][c];
if(len[p]+1==len[q])
link[cur]=q;
else
{
int clone=++sz;
len[clone]=len[p]+1;
link[clone]=link[q];
for(int i=0;i<C;i++)
nxt[clone][i]=len[nxt[q][i]]?nxt[q][i]:0; while(p!=-1 && nxt[p][c]==q)
nxt[p][c]=clone,p=link[p];
link[q]=link[cur]=clone;
}
}
return cur;
} //基于trie树建立GSA
void build()
{
queue<pii> Q;
for(int i=0;i<C;i++)
if(nxt[0][i])
Q.push(pii(0,i)); while(!Q.empty())
{
pii tmp=Q.front();
Q.pop(); int cur=extend(tmp.first,tmp.second);
for(int i=0;i<C;i++)
if(nxt[cur][i])
Q.push(pii(cur,i));
}
} int id[N<<1]; //构建完成后,id顺序为len递增(逆拓扑序)【仅可排一次】
void sort()
{
static int bucket[N<<1]; memset(bucket,0,sizeof(bucket));
for(int i=1;i<=sz;i++)
bucket[len[i]]++;
for(int i=1;i<=sz;i++)
bucket[i]+=bucket[i-1];
for(int i=1;i<=sz;i++)
id[bucket[len[i]]--]=i;
}
}gsa; int n,m;
char s[N],t[N];
int cnt1[N<<1],cnt2[N<<1]; int main()
{
scanf("%s",s+1);
n=strlen(s+1);
scanf("%s",t+1);
m=strlen(t+1); gsa.insert(s,n);
gsa.insert(t,m); gsa.build();
gsa.sort(); for(int i=1,cur=0;i<=n;i++)
{
cur=gsa.nxt[cur][s[i]-'a'];
cnt1[cur]++;
}
for(int i=1,cur=0;i<=m;i++)
{
cur=gsa.nxt[cur][t[i]-'a'];
cnt2[cur]++;
} ll ans=0;
for(int i=gsa.sz;i>=1;i--)
{
int id=gsa.id[i];
int lst=gsa.link[id];
ans+=1LL*(gsa.len[id]-gsa.len[lst])*cnt1[id]*cnt2[id];
cnt1[lst]+=cnt1[id];
cnt2[lst]+=cnt2[id];
}
printf("%lld\n",ans);
return 0;
}
多个字符串的最长公共子串也许不能用 GSA 做
SPOJ 的那题是比较弱的,因为 $n\leq 10$,所以可以存个长度为 $10$ 的数组搞一搞。以下讨论的是 $n, \sum_i |s_i|\leq 1\times 10^6$ 级别的该问题。
在 SAM 上,疑似对于每个状态暴力跳 fail 是 $\mathrm{O}(n^{1.5})$ 的。那么在 GSA 上,是否能够保证所有串各自占有的状态之和是 $|s_i|^{1.5}$ 呢?这个结论是存疑的...就算成立,时间复杂度也明显比 SAM 要差。
~ 一些练习题 ~
SAM / GSA 的裸题一般都是一眼会,稍微难一点的题目会在此基础上套线段树合并、LCT access 维护树链等内容,但此时难点就不再 SAM 上了。做到啥补充啥吧。
Kattis-firstofhername First of Her Name(2019 ICPC WF)【GSA 裸题】
题目中给定了一棵 trie 树,所以建立 GSA 是比较自然的想法。考虑回答查询,某个字符串的前缀如果是 $s$,就相当于反转的 $s$ 是从 trie 树的对应位置到 $state_0$ 的路径的前缀。所以我们只需要用类似求出现次数的方法,对于每个字符串在结尾处令 $cnt=1$(在这题中就是将 $cnt[1:n]$ 均置 $1$),然后按照拓扑序 DP 即可。
#include <queue>
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std; typedef long long ll;
typedef pair<int,int> pii; const int N=1000005;
const int C=26; //注意检查字符集大小! ll cnt[N<<1]; //在结构题外开任何与SAM状态相关的数组,都需要N<<1
struct GeneralSuffixAutomaton
{
int sz; //状态数上限=2|S|-1 int len[N<<1],link[N<<1];
int nxt[N<<1][C];
//map<char,int> nxt[N<<1];
//extend(int,char) GeneralSuffixAutomaton()
{
len[0]=0,link[0]=-1;
sz=0;
} //扩展GSA,对于lst的c转移进行扩展
int extend(int lst,int c)
{
int cur=nxt[lst][c];
len[cur]=len[lst]+1; int p=link[lst];
while(p!=-1 && !nxt[p][c])
nxt[p][c]=cur,p=link[p]; if(p==-1)
link[cur]=0;
else
{
int q=nxt[p][c];
if(len[p]+1==len[q])
link[cur]=q;
else
{
int clone=++sz;
len[clone]=len[p]+1;
link[clone]=link[q];
for(int i=0;i<C;i++)
nxt[clone][i]=len[nxt[q][i]]?nxt[q][i]:0; while(p!=-1 && nxt[p][c]==q)
nxt[p][c]=clone,p=link[p];
link[q]=link[cur]=clone;
}
}
return cur;
} //基于trie树建立GSA
void build()
{
queue<pii> Q;
for(int i=0;i<C;i++)
if(nxt[0][i])
Q.push(pii(0,i)); while(!Q.empty())
{
pii tmp=Q.front();
Q.pop(); int cur=extend(tmp.first,tmp.second);
for(int i=0;i<C;i++)
if(nxt[cur][i])
Q.push(pii(cur,i));
}
} int id[N<<1]; //构建完成后,id顺序为len递增(逆拓扑序)【仅可排一次】
void sort()
{
static int bucket[N<<1]; memset(bucket,0,sizeof(bucket));
for(int i=1;i<=sz;i++)
bucket[len[i]]++;
for(int i=1;i<=sz;i++)
bucket[i]+=bucket[i-1];
for(int i=1;i<=sz;i++)
id[bucket[len[i]]--]=i;
}
}gsa; int n,q;
char s[N]; int main()
{
scanf("%d%d",&n,&q);
for(int i=1;i<=n;i++)
{
char ch=getchar();
while(ch<'A' || ch>'Z')
ch=getchar(); int lst;
scanf("%d",&lst);
gsa.nxt[lst][ch-'A']=i,cnt[i]=1;
} gsa.sz=n;
gsa.build();
gsa.sort(); for(int i=gsa.sz;i>=1;i--)
{
int id=gsa.id[i];
cnt[gsa.link[id]]+=cnt[id];
} while(q--)
{
scanf("%s",s+1);
int n=strlen(s+1); int cur=0;
for(int i=n;i>=1;i--)
{
int c=s[i]-'A';
if(!gsa.nxt[cur][c])
{
cur=0;
break;
}
cur=gsa.nxt[cur][c];
}
printf("%d\n",gsa.len[cur]>=n?cnt[cur]:0);
}
return 0;
}
计蒜客42551 Loli, Yen-Jen, and a cool problem(2019 ICPC 徐州)【GSA 基础性质,去重处理】
这题本身挺裸的。对于每次询问 $s[x-L+1:x]$ 的出现次数,我们只需要找到其所在的状态就行了,从 $x$ 沿着 $\mathrm{link}$ 暴力跳、直到当前状态的 $\mathrm{len}$ 区间包含 $L$ 即可。理论上需要将 $x$ 相同的询问同时处理,不过数据貌似没卡。
这题稍微有点恶心的是 trie 树上会有重合的节点。对于重合的节点,我们选择最早出现的一个作为代表,其余节点全部映射到代表。这会导致非代表点变成孤立连通块,在进行拓扑排序的时候需要注意忽略这些 $\mathrm{len}=0$ 的孤立点。
#include <queue>
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std; typedef long long ll;
typedef pair<int,int> pii; const int N=300005;
const int C=26; //注意检查字符集大小! //在结构题外开任何与SAM状态相关的数组,都需要N<<1
struct GeneralSuffixAutomaton
{
int sz; //状态数上限=2|S|-1 int len[N<<1],link[N<<1];
int nxt[N<<1][C];
//map<char,int> nxt[N<<1];
//extend(int,char) GeneralSuffixAutomaton()
{
len[0]=0,link[0]=-1;
sz=0;
} //扩展GSA,对于lst的c转移进行扩展
int extend(int lst,int c)
{
int cur=nxt[lst][c];
len[cur]=len[lst]+1; int p=link[lst];
while(p!=-1 && !nxt[p][c])
nxt[p][c]=cur,p=link[p]; if(p==-1)
link[cur]=0;
else
{
int q=nxt[p][c];
if(len[p]+1==len[q])
link[cur]=q;
else
{
int clone=++sz;
len[clone]=len[p]+1;
link[clone]=link[q];
for(int i=0;i<C;i++)
nxt[clone][i]=len[nxt[q][i]]?nxt[q][i]:0; while(p!=-1 && nxt[p][c]==q)
nxt[p][c]=clone,p=link[p];
link[q]=link[cur]=clone;
}
}
return cur;
} //基于trie树建立GSA
void build()
{
queue<pii> Q;
for(int i=0;i<C;i++)
if(nxt[0][i])
Q.push(pii(0,i)); while(!Q.empty())
{
pii tmp=Q.front();
Q.pop(); int cur=extend(tmp.first,tmp.second);
for(int i=0;i<C;i++)
if(nxt[cur][i])
Q.push(pii(cur,i));
}
} int id[N<<1]; //构建完成后,id顺序为len递增(逆拓扑序)【仅可排一次】
void sort()
{
static int bucket[N<<1]; memset(bucket,0,sizeof(bucket));
for(int i=1;i<=sz;i++)
if(len[i])
bucket[len[i]]++;
for(int i=1;i<=sz;i++)
bucket[i]+=bucket[i-1];
for(int i=1;i<=sz;i++)
if(len[i])
id[bucket[len[i]]--]=i;
}
}gsa; int n,q;
char s[N]; int to[N];
ll cnt[N<<1]; int main()
{
scanf("%d%d",&n,&q);
scanf("%s",s+1); gsa.nxt[0][s[1]-'A']=1,to[1]=1,cnt[1]++;
for(int i=2;i<=n;i++)
{
int x,c=s[i]-'A';
scanf("%d",&x); x=to[x];
if(!gsa.nxt[x][c])
gsa.nxt[x][c]=i;
to[i]=gsa.nxt[x][c];
cnt[to[i]]++;
} gsa.sz=n;
gsa.build();
gsa.sort(); for(int i=gsa.sz;i>=1;i--)
{
int id=gsa.id[i];
if(id)
cnt[gsa.link[id]]+=cnt[id];
} while(q--)
{
int x,y;
scanf("%d%d",&x,&y); x=to[x];
while(gsa.len[gsa.link[x]]>=y)
x=gsa.link[x];
printf("%lld\n",cnt[x]);
}
return 0;
}
牛客4010D 卡拉巴什的字符串(2020 Wannafly Camp Day2)【题意转化,SAM 基础性质】
我们考虑依次加入字符,那么在加到 $s[i]$ 时,我们需要考虑 $s[1:i-1]$ 的答案与 $s[1:i]$ 的区别。假如加入 $s[i]$ 会使得答案发生改变,那么最长的 LCP 一定是一个 $s[1:i]$ 的后缀,否则该 LCP 也一定在 $s[1:i-1]$ 中出现过了。
通过这样的转化后,我们只需要关心最长的、出现过多次的 $s[1:i]$ 的后缀是什么。在插入完 $s[i]$ 后,SAM 的 $last$ 指针指向 $\mathrm{endpos}=\{i\}$ 的状态,那么根据后缀链接的性质,$\mathrm{link}(last)$ 恰为我们所要的东西(因为其 endpos 集合大于 $1$,即出现多次),所以答案即为 $\mathrm{len}(\mathrm{link}(last))$ 的 MEX。有一个细节是,当字符串为形如 "aaaa" 时答案应该全是 $0$,因为 LCP 的值为 $-,1,2,3$,并没有出现过 $0$。
#include <cstdio>
#include <vector>
#include <cstring>
#include <algorithm>
using namespace std; const int N=1000005;
const int C=26; //注意检查字符集大小! //在结构题外开任何与SAM状态相关的数组,都需要N<<1
struct SuffixAutomaton
{
int sz,lst; //状态数上限=2|S|-1 int len[N<<1],link[N<<1];
int nxt[N<<1][C];
//map<char,int> nxt[N<<1];
//extend(char),并使用nxt[clone]=nxt[q]替换memcpy SuffixAutomaton()
{
len[0]=0,link[0]=-1;
lst=sz=0;
} void init()
{
for(int i=0;i<=sz;i++)
{
len[i]=link[i]=0;
for(int j=0;j<C;j++)
nxt[i][j]=0;
}
link[0]=-1;
lst=sz=0;
} void extend(int c)
{
int cur=++sz;
len[cur]=len[lst]+1; int p=lst;
while(p!=-1 && !nxt[p][c])
nxt[p][c]=cur,p=link[p]; if(p==-1)
link[cur]=0;
else
{
int q=nxt[p][c];
if(len[p]+1==len[q])
link[cur]=q;
else
{
int clone=++sz;
len[clone]=len[p]+1;
link[clone]=link[q];
memcpy(nxt[clone],nxt[q],C*4); while(p!=-1 && nxt[p][c]==q)
nxt[p][c]=clone,p=link[p];
link[q]=link[cur]=clone;
}
}
lst=cur;
} int id[N<<1]; //构建完成后,id顺序为len递增(逆拓扑序)【仅可排一次】
void sort()
{
static int bucket[N<<1]; memset(bucket,0,sizeof(bucket));
for(int i=1;i<=sz;i++)
bucket[len[i]]++;
for(int i=1;i<=sz;i++)
bucket[i]+=bucket[i-1];
for(int i=1;i<=sz;i++)
id[bucket[len[i]]--]=i;
}
}sam; int n;
char s[N]; int main()
{
int T;
scanf("%d",&T);
while(T--)
{
scanf("%s",s+1);
n=strlen(s+1); sam.init(); printf("0");
sam.extend(s[1]-'a'); int mx=0,zero=0;
for(int i=2;i<=n;i++)
{
sam.extend(s[i]-'a'); int val=sam.len[sam.link[sam.lst]];
mx=max(mx,val);
zero|=(val==0);
printf(" %d",zero?mx+1:0);
}
printf(" \n");
}
return 0;
}
牛客38727C Cmostp(2022 牛客暑期多校 加赛)【LCT access 维护 parent 树的链并,离线转化】
这题其实只有模型抽象用到了 SAM,所以题解写在 LCT 那里了。右端点在区间 $[l,r]$ 的状态等价于字符串 $s[1:l]$ 到 $s[1:r]$ 这 $r-l+1$ 个状态在 parent 树上的链并。
(待续)
SAM 在处理字典序相关问题时比较乏力,在这种情况下从后缀树、后缀数组的角度往往具有更好的性质。
当问题中的询问数是 $|s|$ 级别的时,可以往 SAM 想一想。
后缀自动机(SAM)+广义后缀自动机(GSA)的更多相关文章
- D. Match & Catch 后缀自动机 || 广义后缀自动机
http://codeforces.com/contest/427/problem/D 题目是找出两个串的最短公共子串,并且在两个串中出现的次数只能是1次. 正解好像是dp啥的,但是用sam可以方便很 ...
- [bzoj3277==bzoj3473]出现k次子串计数——广义后缀自动机+STL
Brief Description 给定n个字符串,对于每个字符串,您需要求出在所有字符串中出现次数大于等于k次的子串个数. Algorithm Design 先建立一个广义后缀自动机,什么是广义后缀 ...
- 后缀自动机 (SAM)
后缀自动机 定义 定义 SAM 为一个有限状态自动机,接受且仅接受 \(S\) 的一个后缀. 同时,SAM 是这样的自动机中最小的那个,其中状态数至多为 \(2n - 1\),转移数至多为 \(3n ...
- 【bzoj3277/bzoj3473】串/字符串 广义后缀自动机
题目描述 字符串是oi界常考的问题.现在给定你n个字符串,询问每个字符串有多少子串(不包括空串)是所有n个字符串中至少k个字符串的子串(注意包括本身). 输入 第一行两个整数n,k.接下来n行每行一个 ...
- bzoj3926: [Zjoi2015]诸神眷顾的幻想乡 对[广义后缀自动机]的一些理解
先说一下对后缀自动机的理解,主要是对构造过程的理解. 构造中,我们已经得到了前L个字符的后缀自动机,现在我们要得到L+1个字符的后缀自动机,什么需要改变呢? 首先,子串$[0,L+1)$对应的状态不存 ...
- BZOJ 3926 && ZJOI 2015 诸神眷顾的幻想乡 (广义后缀自动机)
3926: [Zjoi2015]诸神眷顾的幻想乡 Time Limit: 10 Sec Memory Limit: 512 MB Description 幽香是全幻想乡里最受人欢迎的萌妹子,这天,是幽 ...
- BZOJ 3277 串 (广义后缀自动机)
3277: 串 Time Limit: 10 Sec Memory Limit: 128 MB Submit: 309 Solved: 118 [Submit][Status][Discuss] De ...
- BZOJ 3473: 字符串 [广义后缀自动机]
3473: 字符串 Time Limit: 20 Sec Memory Limit: 256 MBSubmit: 354 Solved: 160[Submit][Status][Discuss] ...
- BZOJ.2780.[SPOJ8093]Sevenk Love Oimaster(广义后缀自动机)
题目链接 \(Description\) 给定n个模式串,多次询问一个串在多少个模式串中出现过.(字符集为26个小写字母) \(Solution\) 对每个询问串进行匹配最终会达到一个节点,我们需要得 ...
随机推荐
- Java开发问题:Column 'AAA' in where clause is ambiguous解决办法
当在java开发中遇到了Column 'AAA' in where clause is ambiguous问题时, 你需要去看看:多表查询的时候不同的表是否出现了相同名称相同的列, 如果存在,你需要在 ...
- [ARC096C] Everything on It 补题记录
题目链接 题目大意: 对于集合 \(\{1,2,\dots,n\}\) ,求它的子集族中,有多少个满足: 任意两个子集互不相同: \(1,2,\dots,n\) 都在其中至少出现了 \(2\) 次. ...
- Idea Maven调试properties 找不到报错
问题:maven执行package命令打包时,src/main/java路径下的properties文件偶尔丢失 解决方式:pom.xml中加入resources配置 <build> &l ...
- CF1702A Round Down the Price 题解
题意:给定一个数 \(n\),找出一个数为 \(10^k \leq n\),求二者的差. 建立一个数组,储存 \(10^k\),每次直接查询求差输出. 注意数据范围. #include<cstd ...
- windows版本rabbitmq安装及日志level设置
1.DirectX Repair 安装缺失的C++组件,不安装缺失的组件会造成第二部安装erl文件夹缺少bin文件夹2.安装otp_win64_23.1 1.配置 ERLANG_HOME:地址为Erl ...
- Spark: Cluster Computing with Working Sets
本文是对spark作者早期论文<Spark: Cluster Computing with Working Sets>做的翻译(谷歌翻译),文章比较理论,阅读起来稍微有些吃力,但读完之后总 ...
- 举重若轻流水行云,前端纯CSS3实现质感非凡的图片Logo鼠标悬停(hover)光泽一闪而过的光影特效
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_197 喜欢看电影的朋友肯定会注意到一个有趣的细节,就是电影出品方一定会在片头的Logo环节做一个小特效:暗影流动之间光泽一闪而过, ...
- Odoo14 收发邮件服务器设置
# 维护邮箱的七个地方 # 1.settings中Discuss栏将External Email Servers勾选(启用外部邮件服务),然后维护Alias Domain(域名) # 2.Techni ...
- 5.26 NOI 模拟
\(T1\)石子与HH与HHの取 博弈是不可能会的 \(c_i\)相等,比较显然的\(Nim,\)直接前缀异或求一下 \(a_i=1,\)区间长度对\(2\)取模 结论\(:\)黑色石子严格大于白色个 ...
- springmvc静态资源配置
<servlet> <servlet-name>dispatcher</servlet-name> <servlet-class>org.springf ...