[SPDK/NVMe存储技术分析]010 - 理解SGL
在NVMe over PCIe中,I/O命令支持SGL(Scatter Gather List 分散聚合表)和PRP(Physical Region Page 物理(内存)区域页), 而管理命令只支持PRP;而在NVMe over Fabrics中,无论是管理命令还是I/O命令都只支持SGL。NVMe over Fabrics既支持FC网络,又支持RDMA网络。众所周知,在RDMA编程中,SGL(Scatter/Gather List)是最基本的数据组织形式。 SGL是一个数组,该数组中的元素被称之为SGE(Scatter/Gather Element),每一个SGE就是一个Data Segment(数据段)。其中,SGE的定义如下(参见verbs.h):
struct ibv_sge {
uint64_t addr;
uint32_t length;
uint32_t lkey;
};
- addr: 数据段所在的虚拟内存的起始地址 (Virtual Address of the Data Segment (i.e. Buffer))
- length: 数据段长度(Length of the Data Segment)
- lkey: 该数据段对应的L_Key (Key of the local Memory Region)
而在数据传输中,发送/接收使用的Verbs API为:
- ibv_post_send() - post a list of work requests (WRs) to a send queue 将一个WR列表放置到发送队列中
- ibv_post_recv() - post a list of work requests (WRs) to a receive queue 将一个WR列表放置到接收队列中
下面以ibv_post_send()为例,说明SGL是如何被放置到RDMA硬件的线缆(Wire)上的。
- ibv_post_send()的函数原型
#include <infiniband/verbs.h> int ibv_post_send(struct ibv_qp *qp,
struct ibv_send_wr *wr,
struct ibv_send_wr **bad_wr);
ibv_post_send() posts the linked list of work requests (WRs) starting with wr to the send queue of the queue pair qp. It stops processing WRs from this list at the first failure (that can be detected immediately while requests are being posted), and returns this failing WR through bad_wr.
The argument wr is an ibv_send_wr struct, as defined in <infiniband/verbs.h>.
struct ibv_send_wr {
uint64_t wr_id; /* User defined WR ID */
struct ibv_send_wr *next; /* Pointer to next WR in list, NULL if last WR */
struct ibv_sge *sg_list; /* Pointer to the s/g array */
int num_sge; /* Size of the s/g array */
enum ibv_wr_opcode opcode; /* Operation type */
int send_flags; /* Flags of the WR properties */
uint32_t imm_data; /* Immediate data (in network byte order) */
union {
struct {
uint64_t remote_addr; /* Start address of remote memory buffer */
uint32_t rkey; /* Key of the remote Memory Region */
} rdma;
struct {
uint64_t remote_addr; /* Start address of remote memory buffer */
uint64_t compare_add; /* Compare operand */
uint64_t swap; /* Swap operand */
uint32_t rkey; /* Key of the remote Memory Region */
} atomic;
struct {
struct ibv_ah *ah; /* Address handle (AH) for the remote node address */
uint32_t remote_qpn; /* QP number of the destination QP */
uint32_t remote_qkey; /* Q_Key number of the destination QP */
} ud;
} wr;
};
struct ibv_sge {
uint64_t addr; /* Start address of the local memory buffer */
uint32_t length; /* Length of the buffer */
uint32_t lkey; /* Key of the local Memory Region */
};
在调用ibv_post_send()之前,必须填充好数据结构wr。 wr是一个链表,每一个结点包含了一个sg_list(i.e. SGL: 由一个或多个SGE构成的数组), sg_list的长度为num_sge。

下面图解一下SGL和WR链表的对应关系,并说明一个SGL (struct ibv_sge *sg_list)里包含的多个数据段是如何被RDMA硬件聚合成一个连续的数据段的。
- 01 - 创建SGL
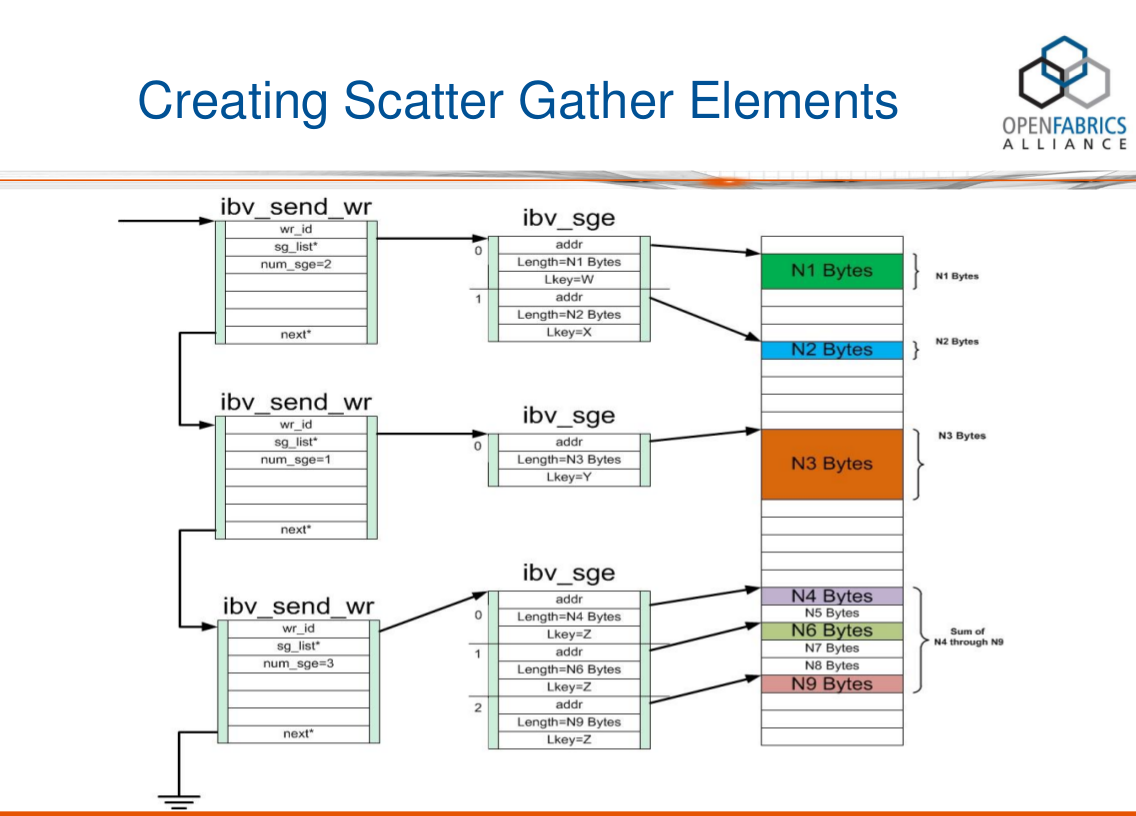
从上图中,我们可以看到wr链表中的每一个结点都包含了一个SGL,SGL是一个数组,包含一个或多个SGE。
- 02 - 使用PD做内存保护

一个SGL至少被一个MR保护, 多个MR存在同一个PD中。
- 03 - 调用ibv_post_send()将SGL发送到wire上去
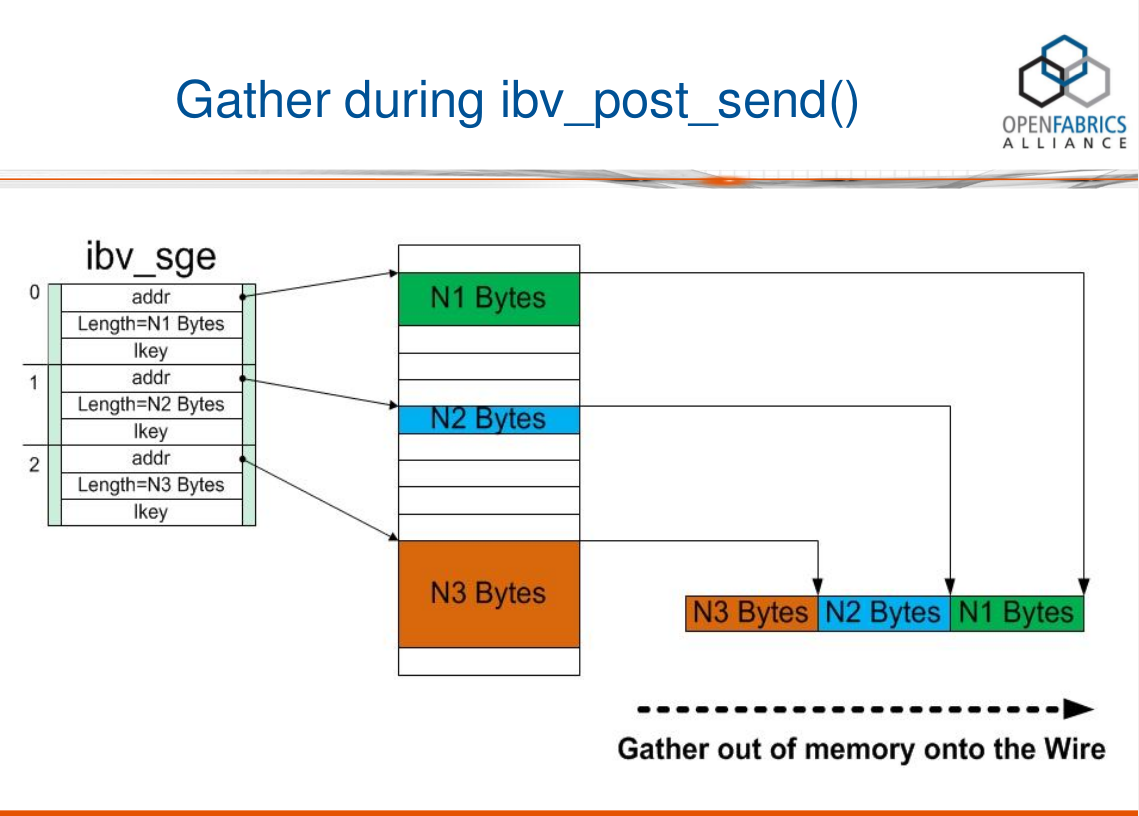
在上图中,一个SGL数组包含了3个SGE, 长度分别为N1, N2, N3字节。我们可以看到,这3个buffer并不连续,它们Scatter(分散)在内存中的各个地方。RDMA硬件读取到SGL后,进行Gather(聚合)操作,于是在RDMA硬件的Wire上看到的就是N3+N2+N1个连续的字节。换句话说,通过使用SGL, 我们可以把分散(Scatter)在内存中的多个数据段(不连续)交给RDMA硬件去聚合(Gather)成连续的数据段。
最后,作为一个代码控(不喜欢纸上谈兵),贴一小段代码展示一下如何为调用ibv_post_send()准备SGL和WR以加深理解。
1 #define BUFFER_SIZE 1024
2
3 struct connection {
4 struct rdma_cm_id *id;
5 struct ibv_qp *qp;
6
7 struct ibv_mr *recv_mr;
8 struct ibv_mr *send_mr;
9
10 char recv_region[BUFFER_SIZE];
11 char send_region[BUFFER_SIZE];
12
13 int num_completions;
14 };
15
16 void foo_send(void *context)
17 {
18 struct connection *conn = (struct connection *)context;
19
20 /* 1. Fill the array SGL having only one element */
21 struct ibv_sge sge;
22
23 memset(&sge, 0, sizeof(sge));
24 sge.addr = (uintptr_t)conn->send_region;
25 sge.length = BUFFER_SIZE;
26 sge.lkey = conn->send_mr->lkey;
27
28 /* 2. Fill the singly-linked list WR having only one node */
29 struct ibv_send_wr wr;
30 struct ibv_send_wr *bad_wr = NULL;
31
32 memset(&wr, 0, sizeof(wr));
33 wr.wr_id = (uintptr_t)conn;
34 wr.opcode = IBV_WR_SEND;
35 wr.sg_list = &sge;
36 wr.num_sge = 1;
37 wr.send_flags = IBV_SEND_SIGNALED;
38
39 /* 3. Now send ... */
40 ibv_post_send(conn->qp, &wr, &bad_wr);
41
42 ...<snip>...
43 }
附录一: OFED Verbs

A great ship asks deep waters. | 是大船就得走深水,是蛟龙就得去大海里畅游。
[SPDK/NVMe存储技术分析]010 - 理解SGL的更多相关文章
- [SPDK/NVMe存储技术分析]015 - 理解内存注册(Memory Registration)
使用RDMA, 必然关系到内存区域(Memory Region)的注册问题.在本文中,我们将以mlx5 HCA卡为例回答如下几个问题: 为什么需要注册内存区域? 注册内存区域有嘛好处? 注册内存区域的 ...
- [SPDK/NVMe存储技术分析]003 - NVMeDirect论文
说明: 之所以要翻译这篇论文,是因为参考此论文可以很好地理解SPDK/NVMe的设计思想. NVMeDirect: A User-space I/O Framework for Application ...
- [SPDK/NVMe存储技术分析]002 - SPDK官方介绍
Introduction to the Storage Performance Development Kit (SPDK) | SPDK概述 By Jonathan S. (Intel), Upda ...
- [SPDK/NVMe存储技术分析]004 - SSD设备的发现
源代码及NVMe协议版本 SPDK : spdk-17.07.1 DPDK : dpdk-17.08 NVMe Spec: 1.2.1 基本分析方法 01 - 到官网http://www.spdk.i ...
- [SPDK/NVMe存储技术分析]001 - SPDK/NVMe概述
1. NVMe概述 NVMe是一个针对基于PCIe的固态硬盘的高性能的.可扩展的主机控制器接口. NVMe的显著特征是提供多个队列来处理I/O命令.单个NVMe设备支持多达64K个I/O 队列,每个I ...
- [SPDK/NVMe存储技术分析]008 - RDMA概述
毫无疑问地,用来取代iSCSI/iSER(iSCSI Extensions for RDMA)技术的NVMe over Fabrics着实让RDMA又火了一把.在介绍NVMe over Fabrics ...
- [SPDK/NVMe存储技术分析]005 - DPDK概述
注: 之所以要中英文对照翻译下面的文章,是因为SPDK严重依赖于DPDK的实现. Introduction to DPDK: Architecture and PrinciplesDPDK概论:体系结 ...
- [SPDK/NVMe存储技术分析]012 - 用户态ibv_post_send()源码分析
OFA定义了一组标准的Verbs,并提供了一个标准库libibvers.在用户态实现NVMe over RDMA的Host(i.e. Initiator)和Target, 少不了要跟OFA定义的Ver ...
- [SPDK/NVMe存储技术分析]011 - 内核态ib_post_send()源码剖析
OFA定义了一组标准的Verbs,并在用户态提供了一个标准库libibverbs.例如将一个工作请求(WR)放置到发送队列的Verb API是ibv_post_send(), 但是在Linux内核,对 ...
随机推荐
- 矩阵LU分解
有如下方程组 ,当矩阵 A 各列向量互不相关时, 方程组有位移解,可以使用消元法求解,具体如下: 使用消元矩阵将 A 变成上三角矩阵 , , 使用消元矩阵作用于向量 b,得到向量 c,, , Ax=b ...
- 通过Dapr实现一个简单的基于.net的微服务电商系统(十八)——服务保护之多级缓存
很久没有更新dapr系列了.今天带来的是一个小的组件集成,通过多级缓存框架来实现对服务的缓存保护,依旧是一个简易的演示以及对其设计原理思路的讲解,欢迎大家转发留言和star 目录:一.通过Dapr实现 ...
- GAN实战笔记——第三章第一个GAN模型:生成手写数字
第一个GAN模型-生成手写数字 一.GAN的基础:对抗训练 形式上,生成器和判别器由可微函数表示如神经网络,他们都有自己的代价函数.这两个网络是利用判别器的损失记性反向传播训练.判别器努力使真实样本输 ...
- Spring是什么? 核心总结
Spring是一个开源框架,它由Rod Johnson创建.它是为了解决企业应用开发的复杂性而创建的. Spring使用基本的JavaBean来完成以前只可能由EJB完成的事情. 然而,Spring ...
- msf常见命令
msf命令全集 一.msfconsole ? 帮助菜单 back 从当前环境返回 banner 显示一个MSF banner cd 切换目录 color 颜色转换 connect ...
- Mac欺骗实验
实验目的 1.掌握MAC欺骗的原理 2.学会利用MacMakeUp软件工具进行伪造源MAC地址的MAC欺骗. 实验内容 使用MacMakeUp伪造主机mac地址,进行mac欺骗实验. 实验环境描述 1 ...
- 自助式bi工具为什么这么受欢迎?
目前比较流行的一种BI形式,当属于自助式BI分析,也就是自助分析平台,即在这个倡导凡事自助的社会中,BI也要以这种形式来呈现.自助式的BI分析相比较于传统的形式,是有很多优点的,我为大家整理了一版. ...
- 【windows 访问控制】十二、C#实操 主体 System.Security.Principal 案例
案例1.主体(包含用户和组)和标识(用户名)的使用. PrincipalPolicy枚举:主体类型 分为window主体.未认证的主体和未分配主体GenericPrincipal.GenericIde ...
- Map<String,String>转Json转Base64
Map<String,String> configMap = new HashMap<String,String>();System.out.println("JSO ...
- yalmip安装
1,将yalmip解压,在matlab中添加路径. 2,yalmiptest测试是否安装成功.