Python制作手游《和平精英》游戏资料查询助手
写在前面的一些P话:
《和平精英》这个游戏想必大家都玩过了,今天来教大家制作一个《和平精英》游戏的资料查询助手
受害者地址:
https://gp.qq.com/main.shtml
1、我们要去获取这些数据《和平精英》武器配件 (爬虫部分)
首先:对于 武器一个详情页url地址发送请求, 获取 每个武器的url地址
其次:对于 每个武器的url地址发送请求 然后获取每个武器的一些基本信息
2、爬虫代码实现思路 (https://jq.qq.com/?_wv=1027&k=NofUEYzs)
1. 发送请求 (https://jq.qq.com/?_wv=1027&k=NofUEYzs)
url 唯一资源定位
请求头 headers 字典形式
请求体
注意点: headers参数问题
请求方式:get请求 / post请求
2. 获取数据 (https://jq.qq.com/?_wv=1027&k=NofUEYzs)
遇到到反爬怎么办,遇到加密怎么办:
字体加密、JS加密、动态数据网页参数变化怎么找,在哪找
response.text:获取网页的文本数据、字符串
json() :json字典数据怎么取值? 根据键值对取值
content
状态码
3. 解析数据 (https://jq.qq.com/?_wv=1027&k=NofUEYzs)
方式很多种:
正则表达式 re
bs4
xpath
parsel (css选择器/xpath)
4. 保存数据 (只要打印输入就可以了) (https://jq.qq.com/?_wv=1027&k=NofUEYzs)
保存文本
保存json
保存数据库:
非关系型数据库
关系型数据库
开始敲代码 (https://jq.qq.com/?_wv=1027&k=NofUEYzs)
需要爬取的数据:武器、配件、物资、载具


在发送请求之前是不是需要加一个请求头
请求头: 把python代码伪装成浏览器对服务器发送一个请求 然后服务器就会给我们返回一个response数据
user-agent :浏览器信息
python答疑 咨询 学习交流群2:660193417###
import requests # 第三方模块
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
response = requests.get(url=html_url, headers=headers)先爬取解析武器的数据,优缺点、武器的伤害都全部爬取下来
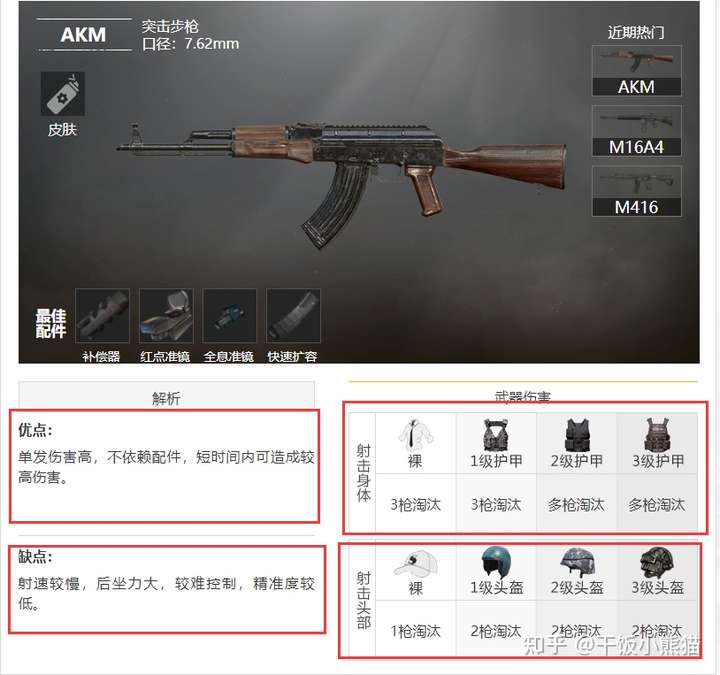
python答疑 咨询 学习交流群2:660193417###
def get_arms_info():
url = '和平精英-官方网站-腾讯游戏'
response = get_response(html_url=url)
selector = parsel.Selector(response.text)
# css选择器 就根据标签属性提取相关内容
href = selector.css('#section-container .clear li a::attr(href)').getall()
titles = selector.css('#section-container .clear li a::attr(title)').getall()
# 通常我们要获取一个列表里面 每个元素 是不是要通过遍历 for循环
zip_data = zip(href, titles)
lis = []
for index in zip_data:
dit = {
'物品名称': index[1],
'详情页': index[0]
}
lis.append(dit)
pd_data = pd.DataFrame(lis)
pd.set_option('display.max_columns', None)
print(pd_data)
arms_num = input('请输入你要查询的武器序号: ')
if int(arms_num) <= len(lis):
arms_url = lis[int(arms_num)]['详情页']
response_1 = get_response(arms_url)
selector_1 = parsel.Selector(response_1.text)
kind = selector_1.css('.wea_class::text').get() # 武器种类
bullet = selector_1.css('.wea_bullet::text').get() # 子弹口径
skin_list = selector_1.css('.parts_list li .skin_name::text').getall() # 子弹口径
# 把列表转成我们字符串类型
skin_name = '/'.join(skin_list)
advantage = selector_1.css('.merit_text p:nth-child(2)::text').get()
defect = selector_1.css('.merit_text p:nth-child(4)::text').get()
st_hurt = selector_1.css('.merit_rt_st li::text').getall()
tb_hurt = selector_1.css('.merit_rt_tb li::text').getall()
print('--'*50)
print('武器名字: ', lis[int(arms_num)]['物品名称'])
print('武器的类型: ', kind)
print('子弹', bullet)
print('最佳配件: ', skin_name)
print('优点: ', advantage)
print('缺点: ', defect)
print('--'*50)
print('武器击中身体伤害:')
print(f'裸装击中身体:{st_hurt[0]}枪淘汰')
print(f'一级甲击中身体:{st_hurt[1]}枪淘汰')
print(f'二级甲击中身体:{st_hurt[2]}枪淘汰')
print(f'三级甲击中身体:{st_hurt[3]}枪淘汰')
print('--' * 50)
print('武器击中头部伤害:')
print(f'裸装击中头部:{tb_hurt[0]}枪淘汰')
print(f'一级头击中头部:{tb_hurt[1]}枪淘汰')
print(f'二级头击中头部:{tb_hurt[2]}枪淘汰')
print(f'三级头击中头部:{tb_hurt[3]}枪淘汰')
print('--' * 50)
else:
print('输入有误')配件的数据解析
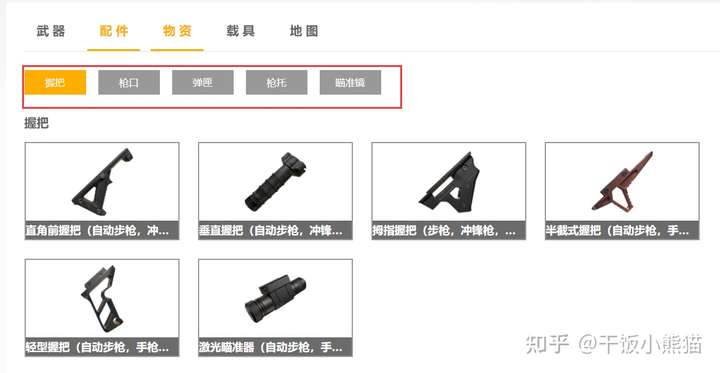
python答疑 咨询 学习交流群2:660193417###
def get_fitting_info():
"""配件"""
html_url = '和平精英-官方网站-腾讯游戏'
response = get_response(html_url)
selector = parsel.Selector(response.text)
titles = selector.css('#section-container2 .clear li a::attr(title)').getall()
href = selector.css('#section-container2 .clear li a::attr(href)').getall()
zip_data_1 = zip(titles, href)
lis = []
for index in zip_data_1:
title = index[0]
index_url = index[1]
dit = {
'物品名称': title,
'详情页': index_url,
}
lis.append(dit)
pd_data = pd.DataFrame(lis)
pd.set_option('display.max_columns', None)
print('配件分类如下所示:')
print(pd_data)
fitting_num = input('请输入你要查询的配件序号:')
fitting_url = lis[int(fitting_num)]['详情页']
html_data = get_response(fitting_url).text
sel = parsel.Selector(html_data)
fitting_sx = sel.css('.intro_sx dd::text').get()
fitting_sy = sel.css('.intro_sy dd::text').get()
print('--' * 50)
print('配件名字:', lis[int(fitting_num)]['物品名称'])
print('配件属性:', fitting_sx)
print('配件适用:', fitting_sy)
print('--' * 50)物资的数据解析
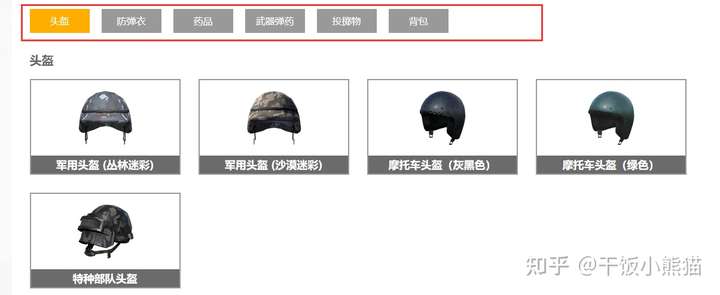
python答疑 咨询 学习交流群2:660193417###
def get_supplies_info():
"""物资"""
html_url = '和平精英-官方网站-腾讯游戏'
response = get_response(html_url)
selector = parsel.Selector(response.text)
titles = selector.css('#section-container3 .clear li a::attr(title)').getall()
href = selector.css('#section-container3 .clear li a::attr(href)').getall()
zip_data_2 = zip(titles, href)
lis = []
for index in zip_data_2:
title = index[0]
index_url = index[1]
dit = {
'物品名称': title,
'详情页': index_url,
}
lis.append(dit)
pd_data = pd.DataFrame(lis)
pd.set_option('display.max_columns', None)
print('物资分类如下所示:')
print(pd_data)
supplies_num = input('请输入你要查询的物资序号:')
supplies_url = lis[int(supplies_num)]['详情页']
html_data = get_response(supplies_url).text
sel = parsel.Selector(html_data)
supplies_sx = sel.css('.intro_sx dd::text').get()
print('--' * 50)
print('配件名字:', lis[int(supplies_num)]['物品名称'])
print('配件属性:', supplies_sx)
print('--' * 50)载具的数据解析

python答疑 咨询 学习交流群2:660193417###
def get_car_info():
"""载具"""
html_url = '和平精英-官方网站-腾讯游戏'
response = get_response(html_url)
selector = parsel.Selector(response.text)
titles = selector.css('#section-container4 .clear li a::attr(title)').getall()
href = selector.css('#section-container4 .clear li a::attr(href)').getall()
zip_data_2 = zip(titles, href)
lis = []
for index in zip_data_2:
title = index[0]
index_url = index[1]
dit = {
'物品名称': title,
'详情页': index_url,
}
lis.append(dit)
pd_data = pd.DataFrame(lis)
pd.set_option('display.max_columns', None)
print('物资分类如下所示:')
print(pd_data)
supplies_num = input('请输入你要查询的物资序号:')
supplies_url = lis[int(supplies_num)]['详情页']
html_data = get_response(supplies_url).text
sel = parsel.Selector(html_data)
supplies_sx = sel.css('.intro_sx dd::text').get()
print('--' * 50)
print('配件名字:', lis[int(supplies_num)]['物品名称'])
print('配件属性:', supplies_sx)
print('--' * 50)调用函数,判断
python答疑 咨询 学习交流群2:660193417###
if __name__ == '__main__':
while True:
string = """===================================
和平精英资料查询助手V1.0版本
0.武器 1.配件 2.物资 3.载具
==================================="""
print(string)
word = input('请输入你要查询的内容(输入n退出): ')
if word == '0':
get_arms_info()
elif word == '1':
get_fitting_info()
elif word == '2':
get_supplies_info()
elif word == '3':
get_car_info()
elif word == 'n':
break
else:
print('请正确输入~~')结果展示
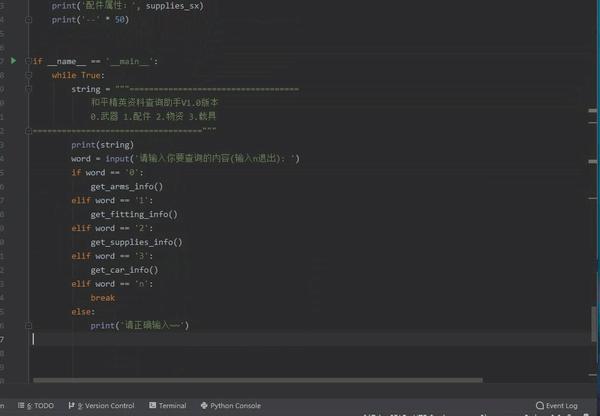
Python制作手游《和平精英》游戏资料查询助手的更多相关文章
- Testin云測手游质量管家 七大兵器助CP称霸江湖
Testin云測手游质量管家 七大兵器助CP称霸江湖 2014/09/29 · Testin · 产品评測 在武侠江湖里,高手不须要武功高强.亦要具备厉害的武器.有人的地方就有江湖.手游行业相同腥风血 ...
- Python制作回合制手游外挂简单教程(下)
引入: 接着上篇的博文,今天我们讲如何实现助人为乐 前期准备: 如何获取图片中指定文字的坐标? 我的思路是截取一个小区域,再根据小区域左上角的坐标获取中央坐标 例如: 获取坐上角的x和y坐标,测量x到 ...
- Python制作回合制手游外挂简单教程(上)
引入: 每次玩回合制游戏的时候,反反复复的日常任务让人不胜其烦 玩问道的时候,我们希望能够自动刷道,玩梦幻希望能自动做师门.捉鬼等等 说明: 该外挂只能模拟鼠标键盘操作,并不能修改游戏数据 我这里使用 ...
- 手游[追忆之青]动画导演:2D动画制作技巧
转自:http://www.gamelook.com.cn/2016/09/264591 GameLook报道/由一般法人计算机娱乐协会(CESA)主办的CEDEC2016日前在日本横滨举行,诸多开发 ...
- Unity制作王者荣耀商业级手游
<王者荣耀>这种现象级手机游戏是如何制作出来的呢?本文以<王者荣耀>MOBO类型的多人在线战术竞技游戏为入口,覆盖Unity游戏制作开发前端与Node.js服务器端的开发必备知 ...
- 真正从0开始用Unity3D制作类战地2玩法的类龙之谷、王者荣耀的手游(暨全平台游戏)
如题,(从2017年10月18日开始)正在利用业余时间研发一款神泣Shaiya2手游,引擎用Unity3D. 原因主要有2点: 对神泣太多感情,希望能做点什么来纪念乃至留下神泣这款网游: 时机已到,是 ...
- python爬虫练手项目快递单号查询
import requests def main(): try: num = input('请输入快递单号:') url = 'http://www.kuaidi100.com/autonumber/ ...
- 类传奇手游简单Demo
这是一年多前自己闲时以Unity2D制作的很粗糙简单的传奇类手游Demo(单机),已很久未作继续开发. 此小Demo初步完成或实现了如下功能(有诸多考虑欠妥甚至不完善之处): 1).图片资源打包方式. ...
- Unity3D手游开发实践
<腾讯桌球:客户端总结> 本次分享总结,起源于腾讯桌球项目,但是不仅仅限于项目本身.虽然基于Unity3D,很多东西同样适用于Cocos.本文从以下10大点进行阐述: 架构设计 原生插件/ ...
随机推荐
- 使用Lua 脚本实现redis 分布式锁,报错:ERR Error running script (call to f_8ea1e266485534d17ddba5af05c1b61273c30467): @user_script:10: @user_script: 10: Lua redis() command arguments must be strings or integers .
在使用SpringBoot开发时,使用RedisTemplate执行 redisTemplate.execute(lockScript, redisList); 发现报错: ERR Error run ...
- echarts踩坑总结
1,有关echarts引用的相关报错直接写这句 import * as echarts from 'echarts' 2,折线图 chartsObj = { tooltip: { trigger: ...
- ValidForm5.3.2 忽略表单项校验详解
ValidForm 官方文档 项目的需求是这样的:一个checkbox,一个input,选中checkbox的时候,需要校验input,取消选中的时候,不要校验input. <input typ ...
- zookeeper篇-zookeeper客户端和服务端的基础命令
点赞再看,养成习惯,微信搜索「小大白日志」关注这个搬砖人. 文章不定期同步公众号,还有各种一线大厂面试原题.我的学习系列笔记. 前提:我把zookeepee安装在了服务器/usr/local/java ...
- XCTF练习题---MISC---神奇的Modbus
XCTF练习题---MISC---神奇的Modbus flag:sctf{Easy_Modbus} 解题步骤: 1.观察题目,下载附件 2.打开下载文件,发现可以用WireShark打开,打开看看是啥 ...
- 《Streaming Systems》第三章: Watermarks
定义 对于一个处理无界数据流的 pipeline 而言,非常需要一个衡量数据完整度的指标,用于标识什么时候属于某个窗口的数据都已到齐,窗口可以执行聚合运算并放心清理,我们暂且就给它起名叫 waterm ...
- K8s 如何提供更高效稳定的编排能力?K8s Watch 实现机制浅析
关于我们 更多关于云原生的案例和知识,可关注同名[腾讯云原生]公众号~ 福利: ①公众号后台回复[手册],可获得<腾讯云原生路线图手册>&<腾讯云原生最佳实践>~ ②公 ...
- Libco Hook 机制浅析
Libco Hook 机制浅析 之前的文章里我们提到过 Libco 有一套 Hook 机制,可以通过协程的让出(yield)原语将系统的阻塞系统调用改造为非阻塞的,这篇文章我们将深入解析 Hook 机 ...
- 谁动了我的主机? 之活用History命令
点击上方"开源Linux",选择"设为星标" 回复"学习"获取独家整理的学习资料! Linux系统下可通过history命令查看用户所有的历 ...
- C++进阶-3-5-list容器
C++进阶-3-5-list容器 1 #include<iostream> 2 #include<list> 3 #include<algorithm> 4 usi ...