Hadoop2.x伪分布式环境搭建(一)
1、安装hadoop环境,以hadoop-2.5.0版本为例,搭建伪分布式环境,所需要工具包提供网盘下载:http://pan.baidu.com/s/1o8HR0Qu
2、上传所需要的工具包到linux相对就应的目录中
3、接上篇(Linux基础环境的各项配置(三)中最后一部分,需卸载系统自带的jdk,以免后续安装的jdk产生冲突),卸载jdk完成后,安装jdk-7u67-linux-x64.tar.gz版本,上述工具包可下载
(1)、解压JDK
tar -zxf jdk-7u67-linux-x64.tar.gz -C ../model/
(2)、配置环境变量,在/etc/profile配置文件末尾加入如下内容(需要管理员权限才能操作此文件)
##JAVA_HOME
export JAVA_HOME=/opt/model/jdk1.7.0_67
export PATH=$PATH:$JAVA_HOME/bin
(3)、让文件生效执行如下命令
source /etc/profile
(4)、执行java -version命令,出现如下图所示则jdk配置成功

4、hadoop-2.5.0安装与配置
(1)、解压下载好的hadoop-2.5.0.tar.gz包
tar -zxf hadoop-2.5.0.tar.gz -C ../model/
(2)、进入hadoop-2.5.0目录,在当前路径的share目录下,有个doc目录,此目录存放的都是官方英文说明文档,基本没用且占用空间及大,建议删除此目录,为后续发送集群节点节省时间
rm -rf share/doc
(3)、修改/opt/model/hadoop-2.5.0/etc/hadoop目录下hadoop-env.sh、mapred-env.sh、yarn-env.sh这三个配置文件,设置JAVA_HOME安装目录,如下所示
export JAVA_HOME=/opt/model/jdk1.7.0_67
(4)、修改core-site.xml配置文件,内容如下
<configuration>
<!--指定namenode主节点所在的位置以及交互端口号-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-senior01.dinghong.com:8020</value>
</property>
<!--更改hadoop.tmp.dir的默认临时目录路径-->
<!-- /opt/model/hadoop-2.5.0/data/tmp 这个路径需自己先行创建 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/model/hadoop-2.5.0/data/tmp</value>
</property>
</configuration>
(5)、修改slaves配置文件,内容修改如下
#定义datanode从节点所在哪台机器,由于此次笔记是伪分布式安装,所有主从节点都在一台机器上,所以主机名都是一样
hadoop-senior01.dinghong.com
(6)、修改hdfs-site.xml配置文件,内容如下
<configuration>
<!--指定副本个数,默认值是3个-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
(7)、修改yarn-site.xml配置文件,内容如下
<configuration>
<!-- 指定yarn上运行的是mapreduce程序 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定ResourceManager的位置-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-senior01.dinghong.com</value>
</property>
</configuration>
(8)、将mapred-site.xml.template文件重命名为mapred-site.xml,并修改其内容如下
<configuration>
<!--指定MapReduce运行在YARN上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(9)、对于NameNode进行格式化操作,命令如下(只需要一次格式化,多次格式化会出错):
bin/hdfs namenode -format
出现如下图所示,表示格式化成功,若格式化出现错误,则需要仔细查找日志信息,查找出错原因,再次格式之前,一定把/opt/model/hadoop-2.5.0/data/tmp目录下的文件删除干净

5、hadoop-2.5.0上述步骤操作完毕后,即可启动相关进程
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
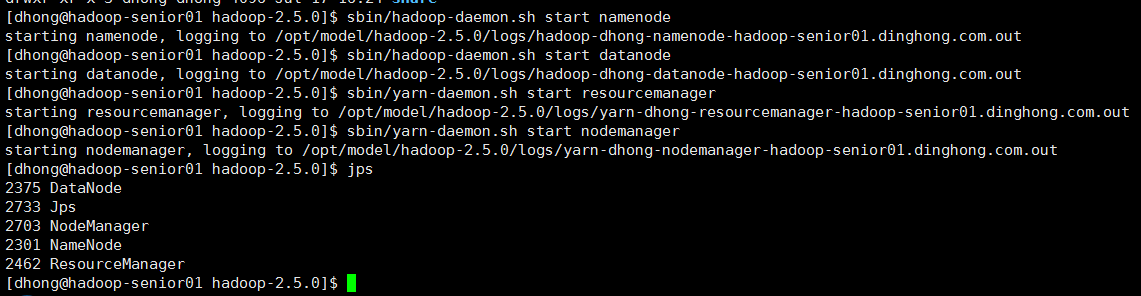
在web页面访问hdfs以及yarn信息页面,说明启动成功了,如下图所示
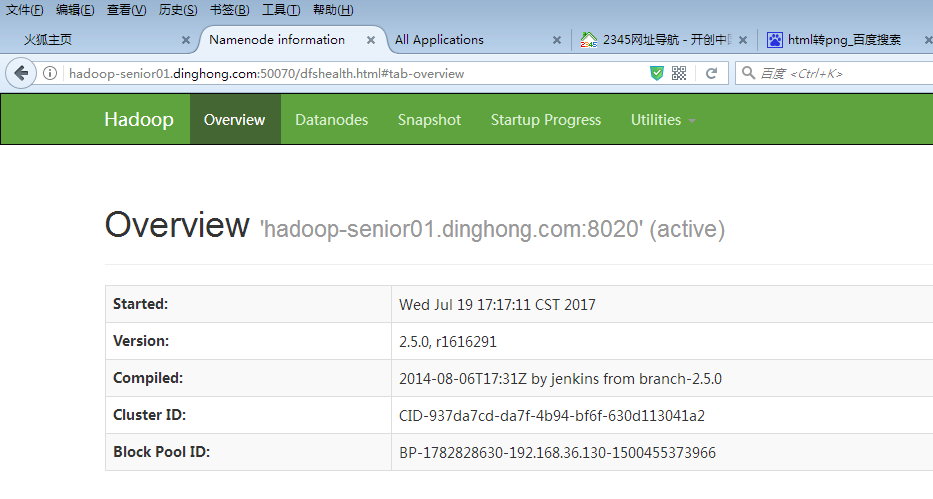
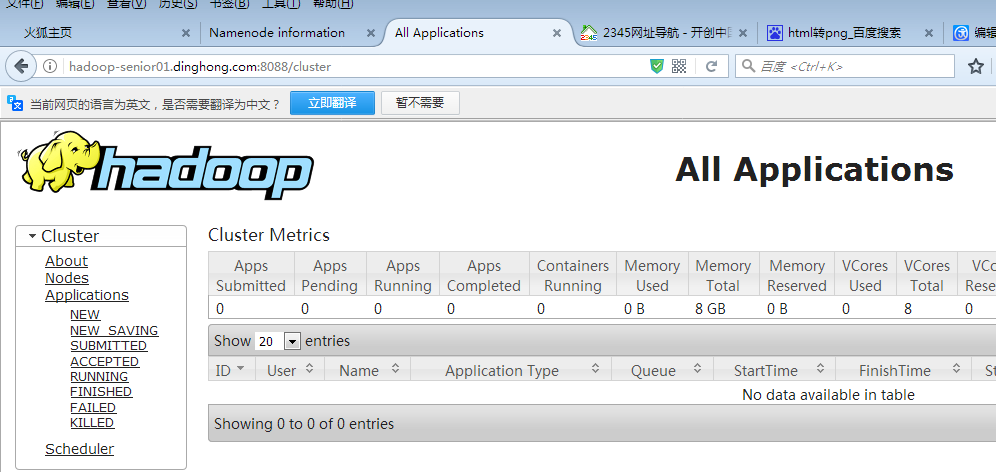
6、继续开启自带历史服务器和日志聚集功能
(1)、修改mapred-site.xml配置文件,配置历史服务器,添加如下内容
<!-- 指定历史服务器的所在机器 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-senior01.ibeifeng.com:10020</value>
</property>
<!-- 指定历史服务器外部访问地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-senior01.ibeifeng.com:19888</value>
</property>
(2)、修改yarn-site.xml配置文件,开启日志聚集功能,添加如下内容
<!-- 指定是否开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志在HDFS上保留的时间期限 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
7、HDFS文件权限的修改
(1)、修改hdfs-site.xml配置文件,设置不检查文件权限,添加如下内容
<!--设置不启用HDFS文件系统的权限检查-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
(2)、修改core-site.xml配置文件,设置不检查文件权限,添加如下内容
<!--指定修改Hadoop静态用户名,建议设为hadoop启动用户-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>dhong</value>
</property>
8、重启上述6、7步修改过配置文件的相关进程,并运行程序测试,修改是否正确
总结:
以上步骤是hadoop环境的基本配置,可以在上面跑wordcount程序了,由于是用伪分布式搭建的环境,配置比较简单,仅供搭建实验环境参考,在真实的工作当中,hadoop要配置的信息远不止这些,也为自己学习大数据记录一些简单的笔记
Hadoop2.x伪分布式环境搭建(一)的更多相关文章
- Hadoop2.5.0伪分布式环境搭建
本章主要介绍下在Linux系统下的Hadoop2.5.0伪分布式环境搭建步骤.首先要搭建Hadoop伪分布式环境,需要完成一些前置依赖工作,包括创建用户.安装JDK.关闭防火墙等. 一.创建hadoo ...
- Hadoop学习笔记1:伪分布式环境搭建
在搭建Hadoop环境之前,请先阅读如下博文,把搭建Hadoop环境之前的准备工作做好,博文如下: 1.CentOS 6.7下安装JDK , 地址: http://blog.csdn.net/yule ...
- 【Hadoop】伪分布式环境搭建、验证
Hadoop伪分布式环境搭建: 自动部署脚本: #!/bin/bash set -eux export APP_PATH=/opt/applications export APP_NAME=Ares ...
- 大数据:Hadoop(JDK安装、HDFS伪分布式环境搭建、HDFS 的shell操作)
所有的内容都来源与 Hadoop 官方文档 一.Hadoop 伪分布式安装步骤 1)JDK安装 解压:tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/app 添加到系 ...
- 【Hadoop离线基础总结】CDH版本Hadoop 伪分布式环境搭建
CDH版本Hadoop 伪分布式环境搭建 服务规划 步骤 第一步:上传压缩包并解压 cd /export/softwares/ tar -zxvf hadoop-2.6.0-cdh5.14.0.tar ...
- HDFS 伪分布式环境搭建
HDFS 伪分布式环境搭建 作者:Grey 原文地址: 博客园:HDFS 伪分布式环境搭建 CSDN:HDFS 伪分布式环境搭建 相关软件版本 Hadoop 2.6.5 CentOS 7 Oracle ...
- hive-2.2.0 伪分布式环境搭建
一,实验环境: 1, ubuntu server 16.04 2, jdk,1.8 3, hadoop 2.7.4 伪分布式环境或者集群模式 4, apache-hive-2.2.0-bin.tar. ...
- CentOS7下Hadoop伪分布式环境搭建
CentOS7下Hadoop伪分布式环境搭建 前期准备 1.配置hostname(可选,了解) 在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵活的(p ...
- 《OD大数据实战》Hadoop伪分布式环境搭建
一.安装并配置Linux 8. 使用当前root用户创建文件夹,并给/opt/下的所有文件夹及文件赋予775权限,修改用户组为当前用户 mkdir -p /opt/modules mkdir -p / ...
- Spark2.4.0伪分布式环境搭建
一.搭建环境的前提条件 环境:ubuntu-16.04 hadoop-2.6.0 jdk1.8.0_161. spark-2.4.0-bin-hadoop2.6.这里的环境不一定需要和我一样,基本版 ...
随机推荐
- Linux的串口非标准波特率设置更改
用的是全志的R528 SDK,Linux内核是5.4,新增加一个250000的非标准波特率 参考网络大神文档,实践并记录宝贵的经验. 方法: 1.修改内核的/include/uapi/asm-gene ...
- Linux 查找某一线程是否已运行,并启动的方法
参考资料:(3条消息) [Linux]守护线程自动重启某个程序的3种常用办法_L7256的博客-CSDN博客_守护进程 自动重启 方法一:使用编写一个监控APP的脚本 start.sh脚本如下:exp ...
- (转载)零日攻击(Zero-Day Attacks)
零日攻击是网络安全行业中十分常见的攻击方式之一,其具有很大的突发性与破坏性,那么零日攻击是什么?如何防范零日攻击?以下是详细的内容介绍. 零日攻击是什么? 零日漏洞或零时差漏洞通常是指还没有补丁的安全 ...
- 大公司为什么禁止SpringBoot项目使用Tomcat?
本文已经收录到Github仓库,该仓库包含计算机基础.Java基础.多线程.JVM.数据库.Redis.Spring.Mybatis.SpringMVC.SpringBoot.分布式.微服务.设计模式 ...
- Unity之详解Texture
[Texture]详解什么是Texture 前言 开篇废话 嗨咯大家好呀,时隔多日,小黑又和大家见面咯,最近懒癌犯了,而且技术上边倍受打击,所以回了家只想着睡觉休息,所以希望大家见谅见谅啦. Unit ...
- 前端基础知识-html(一)个人学习记录
待补充 块级元素与行内元素,常见举例 html5新特性?
- ADC-单通道DMA到多通道DMA ADC采集修改事项
1. 使能通道IO,因为从单通道到多通道,需要添加规则转换通道数,故需要使能扫描模式,否则只能扫描第一个通道: 2. DMA模式配置需修改为循环传输模式,否则只转换一次: 3. 开启ADC规则转换通道 ...
- bash原样输出字符串中的换行
➜ code $ cat test.sh #!/bin/bash nr="`cat -`"\" echo "$nr" echo $nr echo &q ...
- 11月30日内容总结——前端简介、http协议概念、html协议概念及基础知识和部分标签的讲解
目录 一.前端与后端的概念 什么是前端开发? 什么是后端? 学习前端的目的 前端三剑客 二.前端前戏 三.HTTP协议 1.四大特性 2.报文格式 3.响应状态码 四.HTML概览 1.HTML简介 ...
- 基于GenericAPIView以及五个视图扩展类写接口
目录 基于GenericAPIView以及五个视图扩展类写接口 一.基于GenericAPIView写接口 二 .基于GenericAPIView以及五个视图扩展类写接口 基于GenericAPIVi ...