Datawhale组队学习_Task02:详读西瓜书+南瓜书第3章
第3章 线性模型
家人们又来吃瓜了!

3.1 基本形式
线性模型的本质是通过一个所有属性的线性组合进行预测的函数,即
$\mathcal{f(x)=w_1x_1+w_2x_2+...+w_dx_d+b}$
一般用向量形式写成
$\mathcal{f(x)=w^Tx+b}$
其中$\mathcal{w}$直观表达了个属性在预测中的重要性。
3.2 线性回归
从最简单的单属性的情形入手。若属性值之间存在“序”关系。可将其连续化转化为连续值,如“身高”的取值“高”“矮”可以转化为{1.0,0.0}。
若属性之间不存在序关系,则需将其转化为\(\mathcal{k}\)维向量。斤首先我们需要明晰:我们最终想要做到的是通过线性回归最终学得
$\mathcal{f(x_i)=wx_i+b}$,使得$\mathcal{f(x_i)≈y_i}$
而在此式中,未知量是$\mathcal{w,b}$,所以线性回归得最终目标应该就是使得学习器中二者的误差最小,以使得最终的学习结果更加接近于真实值。这里我们使用**均方误差**来作为其性能度量,即
$\mathcal{(w^*,b^*)=arg min\sum_{i=1}^m{(f(x_i)-y_i)^2}=arg min\sum_{i=1}^m{(y_i-wx_i-b)^2}}$
通过对\(\mathcal{w,b}\)求导,我们可以得到
$\mathcal{\frac{\partial E_(w,b)}{\partial w}=2(w\sum_{i=1}^m{x_i^2}-\sum_{i=1}^m{(y_i-b)x_i})}$
$\mathcal{\frac{\partial E_(w,b)}{\partial b}=2(mb-\sum_{i=1}^m{(y_i-wx_i)}}$
进而令偏导数为0,我们就可以得到\(\mathcal{w}\)和\(\mathcal{b}\)最优解
$\mathcal{w=\frac{\sum_{i=1}^m{y_1(x_i-\overline{x})}}{\sum_{i=1}^m{x_i^2}-\frac{1}{m}(\sum_{i=1}^m{x_i})^2}}$
$\mathcal{b=\frac{1}{m}\sum_{i=1}^m(y_i-wx_i)}$
而更一般的情况是,样本是由\(\mathcal{d}\)个元素来描述的,这时也就是“多元线性回归”,同理,我们可以用最小二乘法来对\(\mathcal{w,b}\)来进行估计。为便于讨论,我们把\(\mathcal{w}\)和\(\mathcal{b}\)吸收入向量形式\(\mathcal{\hat w=(w;b)}\),相应的,把数据集D可以表示为\(\mathcal{m×(d+1)}\)大小的矩阵X,即
\left\{
\begin{matrix}
x_{11} & x_{12} & \cdots & x_{1d} & 1\\
x_{21} & x_{22} & \cdots & x_{2d} & 1\\
\vdots & \vdots & \ddots & \vdots & 1\\
x_{m1} & x_{m2} & \cdots & x_{md} & 1\\
\end{matrix}
\right\}
=
\left\{
\begin{matrix}
x_1^T & 1\\
x_2^t & 1\\
\vdots & \vdots\\
x_m^T & 1\\
\end{matrix}
\right\}
\]
则此时“唯一的”未知量即为\(\mathcal{\hat w}\),类似的有
${\hat w^*=arg min(y-X\hat w)^T(y-X\hat w)}$
对$\mathcal{\hat w}$求导得到
${\frac{\partial E_\hat w}{\partial \hat w}=2X^T(X\hat w-y)}$
令上式为零可以得到$\mathcal{\hat w}$最优解的闭式解,可以进行一个简单的讨论。
当\(X^TX\)为满秩矩阵或正定矩阵式,令上式为零可以得到
${\hat w^*=(X^TX)^{-1}X^Ty}$
这里的解法还需要学习一下,矩阵解法已经完全还给老师了!
则最终学得的多元线性回归模型为
${f(\hat x_i)=\hat x_i^T(X^TX)^{-1}X^Ty}$
但现实任务中往往不是那么容易就会出现满秩矩阵,其属性数目超过样例数的情况也是大有存在,这时也就需要引入正则化项来决定学习算法的归纳偏好
广义线性模型:考虑单调可微函数g(·),令
${y=g^{-1}(w^{T}x+b)}$
这样得到的模型称为“广义线性模型”,其中g(·)称为“联系函数”。
3.3 对数几率回归
在处理分类任务时,可以找一个单调可微函数将分类任务的真实标记y与线性回归模型的预测值联系起来。
若仅考虑二分类任务,则其输出标记y∈{0,1},而线性回归模型产生的预测值是实值,故需要进行一个转换,最理想的是“单位阶跃函数”。
\begin{cases}
0 ,z<0; \\
0.5 ,z=0;(表示可以任判) \\
1 ,z>0,
\end{cases}
\]
为能够代入到广义线性模型中,我们需要一个类似的单点可微函数,也就有了这样一个替代函数:
${y=\frac{1}{1+e^{-z}}}$
带入“广义线性模型”则有:
${y=\frac{1}{1+e^{-(w^Tx+b)}}}$
则做对数变换有:
${ln\frac{y}{1-y}=w^Tx+b}$
若将y视为样本x作为正例的可能性,则1-y是其反例可能性,两者的比值(即等号左对数部分内容)称为“几率”,反映了**x作为正例的相对可能性**
优点:
直接对分类可能性进行建模,无需实现假设数据分布,可以避免假设分布不准确带来的问题
可以得到近似概率预测
是对率函数任意阶可导
3.4 线性判别分析(LDA)
主要思想:给定训练样例集,设法将样例投影到一条直线(\({y=w^Tx}\))上,使得同类样例的投影点尽可能接近、异类样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的未知来确定新样本的类别。即如图所示:
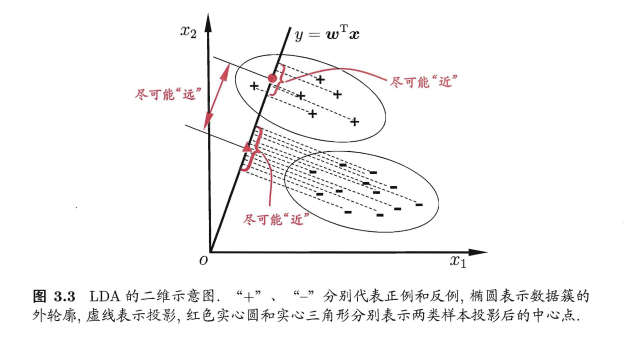
若给定数据集D=\({{(x_i,y_i)}^m_{i=1},y_i∈{0,1}}\),令\({X_i,M_i,\sum_i}\)分别表示示例的集合、均值向量、协方差矩阵。若想达到分类的目的,从图像的角度想要达到的是使同类样例的投影点尽可能接近,即让同类样例投影点的协方差(\({w^T\sum_0w+b^T\sum_1w}\))尽可能小,以及让异类样例的投影点尽可能远离,即让类中心之间的距离(\({∣∣w^TM_0-w^TM_1∣∣^2_2}\))尽可能大,则同时考虑二者,我们可以得到最大化目标:
${J=\frac{∣∣w^TM_0-w^TM_1∣∣^2_2}{w^T\sum_0w+w^T\sum_1w}=\frac{w^T(M_0-M_1)(M_0-M_1)^Tw}{w^T(\sum_0+\sum_1)w}}$
定义“类内散度矩阵”(有时间再敲公式)
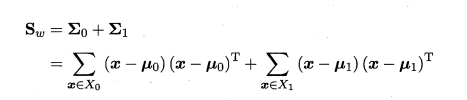
以及“类间散度矩阵”

则上式可以写作:
${J=\frac{w^TS_bw}{w^TS_ww}}$
可以注意到上式中的有关于W长度的项可以消去,故该解只与其方向有关,最终可以解出
${w=S^{-1}_w(M_0-M_1)}$
若将LDA推广到多分类问题中,则可以同理定义一个“**全局散度矩阵**”同理进行求解。
3.5 多分类学习
多分类学习的基本思路是将多分类任务拆为若干个二分类任务进行求解(类似于折半)
关键问题:如何对多分类任务进行拆分,如何对多个分类器进行集成。
拆分策略
- OvO:将类别两两配对,从而产生N(N-1)/2个二分类任务,将被预测得最多的类别作为最终分类结果
- OvR:每次将一个类的样例作为正例其他类的样例作为反例训练N个分类器。测试时若仅有一个分类器预测为正类,则对应的类别标记作为最终分类结果;若有多个分类器预测为正类,则选择置信度最大的类别标记作为分类结果。
- MvM:每次将若干类作为正类,若干类作为范雷,通常使用纠错输出码来对正反类构造进行特殊的设计
3.6 类别不平衡问题
处理类别不平衡学习的一个基本策略——“再缩放”
实际操作的三种方法:
- 欠采样:去除反例使二者数量相当
- 过采样:增加正例使二者数量相当(增加部分不应与原始有过大重叠
- 阈值移动:基于原始训练集进行学习

家人们晚安( ̄o ̄) . z Z
Datawhale组队学习_Task02:详读西瓜书+南瓜书第3章的更多相关文章
- Flink 从0到1学习—— 分享四本 Flink 国外的书和二十多篇 Paper 论文
前言 之前也分享了不少自己的文章,但是对于 Flink 来说,还是有不少新入门的朋友,这里给大家分享点 Flink 相关的资料(国外数据 pdf 和流处理相关的 Paper),期望可以帮你更好的理解 ...
- iPhone应用开发 UITableView学习点滴详解
iPhone应用开发 UITableView学习点滴详解是本文要介绍的内容,内容不多,主要是以代码实现UITableView的学习点滴,我们来看内容. -.建立 UITableView DataTab ...
- android 智能指针的学习先看邓凡平的书扫盲 再看前面两片博客提升
android 智能指针的学习先看邓凡平的书扫盲 再看前面两片博客提升
- Eclipse IDE for C/C++ Developers和MinGW安装配置C/C++开发学习环境详解
Eclipse IDE for C/C++ Developers和MinGW安装配置C/C++开发学习环境详解 操作系统:Windows 7 JDK版本:1.6.0_33 Eclipse版本:Juno ...
- 《C++ Primer》学习总结;兼论如何使用'书'这种帮助性资料
6.25~ 6.27,用了3天翻了一遍<C++ Primer>. ▶书的 固有坏处 一句话: 代码比 文字描述 好看多了.————> 直接看习题部分/ 看demo就行了 看文字在描述 ...
- 《C++ Primer Plus》啃书计 第1~4章
<C++ Primer Plus>啃书计 第1~4章 第一章 预备知识 1.1-1.3略过 1.4 程序创建的技巧 1. cfront,它将C++源代码翻译成C源代码,然后再使用标准C编译 ...
- JAVA学习之Ecplise IDE 使用技巧(2)第二章:键盘小快手,代码辅助
上一篇:JAVA学习之Ecplise IDE 使用技巧(1)第一章:我的地盘我做主,工作空间 第二章:键盘小快手,代码辅助 内容包括: 第一:显示行号 如何设置行号:Ecplice菜单Windows& ...
- noj 2033 一页书的书 [ dp + 组合数 ]
传送门 一页书的书 时间限制(普通/Java) : 1000 MS/ 3000 MS 运行内存限制 : 65536 KByte总提交 : 53 测试通过 : 1 ...
- 《如何正确学习JavaScript》读后小结
在segmentfault上读的一篇学习JavaScript路线的文章,做个小结. 一.简介.数据类型.表达式和操作符 (1)<JavaScript权威指南>前言1-2章&< ...
- Gradle学习系列之三——读懂Gradle语法
在本系列的上篇文章中,我们讲到了创建Task的多种方法,在本篇文章中,我们将学习如何读懂Gradle. 请通过以下方式下载本系列文章的Github示例代码: git clone https://git ...
随机推荐
- Nginx反代服务器基础配置实践案例
转载自:https://www.bilibili.com/read/cv16149433?spm_id_from=333.999.0.0 方式1: 轮询 RR(默认轮询)每个请求按时间顺序逐一分配到不 ...
- mysql8 安装与配置文件添加时区
mysql默认时区选择了CST mysql>show variables like '%time_zone%'; 解决办法:(建议通过修改配置文件来解决) 通过命令在线修改: mysql> ...
- 第一章:模型层 - 5:模型的元数据Meta
模型的元数据,指的是"除了字段外的所有内容",例如排序方式.数据库表名.人类可读的单数或者复数名等等.所有的这些都是非必须的,甚至元数据本身对模型也是非必须的.但是,我要说但是,有 ...
- Pixar 故事公式
文章转载自:https://mp.weixin.qq.com/s/wMfFVh9tAM5Qo4ED658yUg
- k8s中pod的容器日志查看命令
如果容器已经崩溃停止,您可以仍然使用 kubectl logs --previous 获取该容器的日志,只不过需要添加参数 --previous. 如果 Pod 中包含多个容器,而您想要看其中某一个容 ...
- NAT模式下的虚拟机连接主机网络
基于NAT模式的VMware虚拟机(Linux CentOS 7)连接主机(Windows 11)网络 一.什么是NAT模式 虚拟机连接主机网络的三种方式: Bridged(桥接) NAT(网络地址转 ...
- MES系统和ERP系统的区别是什么?
首先得明白一点:MES(Manufacturing Execution System,即制造执行系统)系统跟ERP(Enterprise Resource Planning,企业资源计划)系统是两个完 ...
- 5G 与数字化转型的关系是怎样的?
5G提供的是通信网络服务,数字化转型需要网络服务,但并不是必须使用5G网络,也就是说5G在数字化转型中并不是必虚的,但可以作为备选项,不过在某些行业比如农业.林业.牧业.港口.建筑等布设有线网络.无线 ...
- Tubian-Win上线!Tubian官方的Windows软件适配项目
Sourceforge.net下载:https://sourceforge.net/projects/tubian/ 123网盘下载: https://www.123pan.com/s/XjkKVv- ...
- C#-10 事件
一 发布者和订阅者 很多时候都有这种需求,当一个特定的程序事件发生时,程序的其他部分可以得到该事件已经发生的通知. 发布者/订阅者模式可以满足这种需求. 发布者:发布某个事件的类或结构,其他类可以在该 ...