PyTorch复现VGG学习笔记
PyTorch复现ResNet学习笔记
一篇简单的学习笔记,实现五类花分类,这里只介绍复现的一些细节
如果想了解更多有关网络的细节,请去看论文《VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION》
简单说明下数据集,下载链接,这里用的数据与AlexNet的那篇是一样的所以不在说明
一、环境准备
可以去看之前的一篇博客,里面写的很详细了,并且推荐了一篇炮哥的环境搭建环境
- Anaconda3(建议使用)
- python=3.6/3.7/3.8
- pycharm (IDE)
- pytorch=1.11.0 (pip package)
- torchvision=0.12.0 (pip package)
- cudatoolkit=11.3
二、模型搭建、训练
1.整体框图
模型输入为224*224,采用的预处理方式:从每个像素中减去在训练集上计算的RGB均值
vgg11层到19层的结构
其中最常用的是VGG-16,在本文中用的也是16层的D网络,全是步长为3的卷积
计算层数:只计算有参数的层,池化层没参数不计入这里16=13(卷积层)+3(全连接)
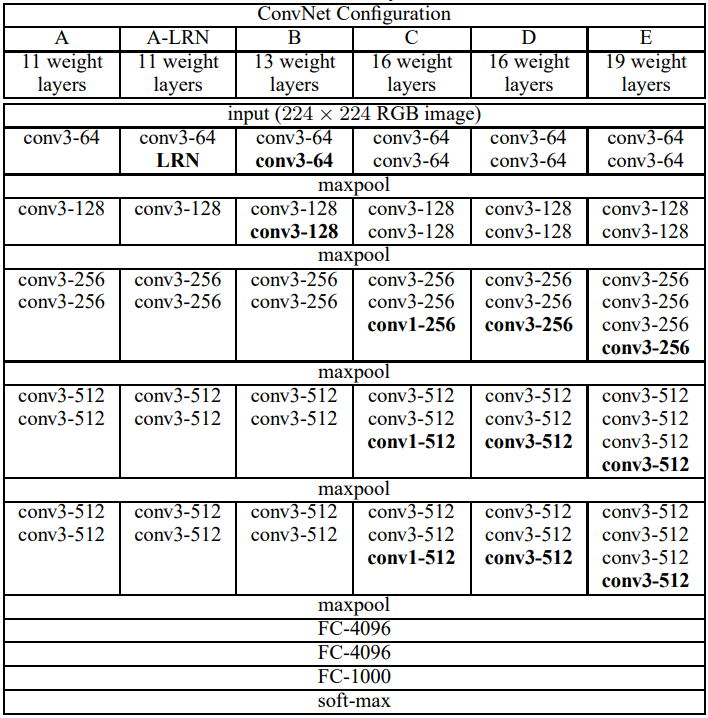
总结:
1.局部相应归一化LRN对模型没有改善,A与A-LRN比较
2.1×1的卷积核带来非线性函数有帮助(C优于B),但也可以用(non-trivial receptive fields)来代替,非平凡,无法证明
3.具有小滤波器的深层网络优于具有较大滤波器的浅层网络。
4.深度越深效果越好(A 与 B, C, D, E 比较),19层饱和(需要更多的数据集)
2.net.py
网络整体结构代码


1 #迁移学习,使用vgg与训练权重vgg16.pth
2 import torch.nn as nn
3 import torch
4
5 # official pretrain weights
6 model_urls = {
7 'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
8 'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
9 'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
10 'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'
11 }
12
13 class VGG(nn.Module):
14 def __init__(self, features, num_classes=1000, init_weights=False):
15 super(VGG, self).__init__()
16 self.features = features
17 self.classifier = nn.Sequential(
18 nn.Linear(512*7*7, 4096),
19 nn.ReLU(True),
20 nn.Dropout(p=0.5),
21 nn.Linear(4096, 4096),
22 nn.ReLU(True),
23 nn.Dropout(p=0.5),
24 nn.Linear(4096, num_classes)
25 )
26 if init_weights:
27 self._initialize_weights()
28
29 def forward(self, x):
30 # N x 3 x 224 x 224
31 x = self.features(x)
32 # N x 512 x 7 x 7
33 x = torch.flatten(x, start_dim=1)
34 # N x 512*7*7
35 x = self.classifier(x)
36 return x
37
38 def _initialize_weights(self):
39 for m in self.modules():
40 if isinstance(m, nn.Conv2d):
41 # nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
42 nn.init.xavier_uniform_(m.weight)
43 if m.bias is not None:
44 nn.init.constant_(m.bias, 0)
45 elif isinstance(m, nn.Linear):
46 nn.init.xavier_uniform_(m.weight)
47 # nn.init.normal_(m.weight, 0, 0.01)
48 nn.init.constant_(m.bias, 0)
49
50
51 def make_features(cfg: list):
52 layers = []
53 in_channels = 3
54 for v in cfg:
55 if v == "M":
56 layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
57 else:
58 conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
59 layers += [conv2d, nn.ReLU(True)]
60 in_channels = v
61 return nn.Sequential(*layers)
62
63
64 cfgs = {
65 'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
66 'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
67 'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
68 'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
69 }
70
71
72 def vgg(model_name="vgg16", **kwargs):
73 assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
74 cfg = cfgs[model_name]
75
76 model = VGG(make_features(cfg), **kwargs)
77 return model
78 if __name__ =="__main__":
79 x = torch.rand([1, 3, 224, 224])
80 model = vgg(num_classes=5)
81 y = model(x)
82 #print(y)
83
84 #统计模型参数
85 sum = 0
86 for name, param in model.named_parameters():
87 num = 1
88 for size in param.shape:
89 num *= size
90 sum += num
91 #print("{:30s} : {}".format(name, param.shape))
92 print("total param num {}".format(sum))#total param num 134,281,029
net.py
写完后保存,运行可以检查是否报错
如果需要打印模型参数,将代码注释去掉即可,得到googlenet的参数为134,281,029,有一亿多的参数,可以说是很多了
3.数据划分
这里与AlexNet用的一样
分好后的数据集

运行下面代码将数据按一定比例,划分为训练集和验证集
数据划分的代码4.train.py
这里训练我们使用迁移学习,来减少训练时间
因为要自己训练的话不仅要花大量时间,而且博主也尝试了训练大概有50个epoch,发现模型一直没在训练

可以看到训练集和验证集的准确率一直在24%左右跳动
所以我们加载vgg的预训练权重,这里给上vgg16的预训练权重
链接:https://pan.baidu.com/s/1U-fOe2Hll368CQIFLS-SNw?pwd=gfxp
提取码:gfxp
1 import torch
2 from torch import nn
3 from torchvision import transforms,datasets
4 from torch import optim
5 from torch.optim import lr_scheduler
6 from net import vgg
7 import os
8 import sys
9 import json
10 from torch.utils.data import DataLoader
11 from tqdm import tqdm#用于画进度条
12 import matplotlib.pyplot as plt
13 from matplotlib.ticker import MaxNLocator
14
15 # 如果显卡可用,则用显卡进行训练
16 device = 'cuda' if torch.cuda.is_available() else 'cpu'
17 print("using {} device".format(device))
18 print(device)
19
20 data_transform = {
21 "train":transforms.Compose([
22 transforms.RandomResizedCrop(224),#随机裁剪
23 transforms.RandomVerticalFlip(),#随机垂直翻转
24 transforms.ToTensor(),#转换为tensor格式
25 transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5))#RGB三通道
26 ]),
27 "val":transforms.Compose([
28 transforms.Resize((224,224)),
29 transforms.ToTensor(),
30 transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5))
31 ])
32 }
33 #数据集路径
34 ROOT_TRAIN = 'data/train'
35 ROOT_TEST = 'data/val'
36
37 batch_size = 16
38
39 train_dataset = datasets.ImageFolder(ROOT_TRAIN,transform=data_transform["train"])
40 val_dataset = datasets.ImageFolder(ROOT_TEST,transform=data_transform["val"])
41
42 train_dataloader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True)
43 val_dataloader = DataLoader(val_dataset,batch_size=batch_size,shuffle=True)
44
45 train_num = len(train_dataset)#计数
46 val_num = len(val_dataset)
47 print("using {} images for training, {} images for validation.".format(train_num,val_num))
48
49 #将#{'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}键值对值反转,并保存
50 flower_list = train_dataset.class_to_idx
51 cla_dict = dict((val, key) for key, val in flower_list.items())
52 # write dict into json file
53 json_str = json.dumps(cla_dict, indent=4)
54 with open('class_indices.json', 'w') as json_file:
55 json_file.write(json_str)#保存json文件(好处,方便转换为其它类型数据)用于预测用
56
57 model_name = "vgg16"
58 model = vgg(model_name,num_classes=5,init_weights=True)
59
60 # 加载预训练模型
61 model_weights_path = './vgg16.pth'
62 ckpt = torch.load(model_weights_path)
63 ckpt.pop('classifier.6.weight')
64 ckpt.pop('classifier.6.bias')
65 missing_keys, unexpected_keys = model.load_state_dict(ckpt, strict=False)
66
67 model.to(device)
68
69 loss_fn = nn.CrossEntropyLoss()
70 #定义优化器
71 optimizer = optim.SGD(model.parameters(),lr=0.003)
72 #学习率每隔10epoch变为原来的0.1
73 lr_s = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
74
75 #定义训练函数
76 def train(dataloader,model,loss_fn,optimizer):
77 model.train()
78 loss,acc,n = 0.0,0.0,0
79 train_bar = tqdm(dataloader,file=sys.stdout)
80 for batch,(x,y) in enumerate(train_bar):
81 #前向传播
82 x,y = x.to(device),y.to(device)
83 output = model(x)
84 cur_loss = loss_fn(output,y)
85 _,pred = torch.max(output,axis=-1)
86 cur_acc = torch.sum(y==pred)/output.shape[0]
87 #反向传播
88 optimizer.zero_grad()#梯度清零
89 cur_loss.backward()
90 optimizer.step()
91 loss += cur_loss
92 acc += cur_acc
93 n += 1
94 train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(i+1,epoch,cur_loss)
95 train_loss = loss / n
96 train_acc = acc / n
97 print(f"train_loss:{train_loss}")
98 print(f"train_acc:{train_acc}")
99 return train_loss,train_acc
100
101 def val(dataloader,model,loss_fn):
102 #验证模式
103 model.eval()
104 loss, current,n = 0.0, 0.0,0
105 with torch.no_grad():
106 val_bar = tqdm(dataloader, file=sys.stdout)
107 for batch, (x, y) in enumerate(val_bar):
108 # 前向传播
109 image, y = x.to(device), y.to(device)
110 output = model(image)
111 cur_loss = loss_fn(output, y)
112 _, pred = torch.max(output, axis=-1)
113 cur_acc = torch.sum(y == pred) / output.shape[0]
114 loss += cur_loss
115 current += cur_acc
116 n += 1
117 val_bar.desc = "val epoch[{}/{}] loss:{:.3f}".format(i + 1, epoch, cur_loss)
118 val_loss = loss / n
119 val_acc = current / n
120 print(f"val_loss:{val_loss}")
121 print(f"val_acc:{val_acc}")
122 return val_loss,val_acc
123
124 # 解决中文显示问题
125 plt.rcParams['font.sans-serif'] = ['SimHei']
126 plt.rcParams['axes.unicode_minus'] = False
127
128 #画图函数
129 def matplot_loss(train_loss,val_loss):
130 plt.figure() # 声明一个新画布,这样两张图像的结果就不会出现重叠
131 plt.plot(train_loss,label='train_loss')#画图
132 plt.plot(val_loss, label='val_loss')
133 plt.legend(loc='best')#图例
134 plt.gca().xaxis.set_major_locator(MaxNLocator(integer=True))
135 plt.ylabel('loss',fontsize=12)
136 plt.xlabel('epoch',fontsize=12)
137 plt.title("训练集和验证集loss对比图")
138 folder = 'result'
139 if not os.path.exists(folder):
140 os.mkdir('result')
141 plt.savefig('result/loss.jpg')
142
143 def matplot_acc(train_acc,val_acc):
144 plt.figure() # 声明一个新画布,这样两张图像的结果就不会出现重叠
145 plt.plot(train_acc, label='train_acc') # 画图
146 plt.plot(val_acc, label='val_acc')
147 plt.legend(loc='best') # 图例
148 plt.gca().xaxis.set_major_locator(MaxNLocator(integer=True))
149 plt.ylabel('acc', fontsize=12)
150 plt.xlabel('epoch', fontsize=12)
151 plt.title("训练集和验证集acc对比图")
152 plt.savefig('result/acc.jpg')
153
154 #开始训练
155 train_loss_list = []
156 val_loss_list = []
157 train_acc_list = []
158 val_acc_list = []
159
160 epoch = 20
161
162 max_acc = 0
163
164 for i in range(epoch):
165 lr_s.step()#学习率迭代,10epoch变为原来的0.1
166 train_loss,train_acc=train(train_dataloader,model,loss_fn,optimizer)
167 val_loss,val_acc=val(val_dataloader,model,loss_fn)
168
169 train_loss_list.append(train_loss)
170 train_acc_list.append(train_acc)
171 val_loss_list.append(val_loss)
172 val_acc_list.append(val_acc)
173 # 保存最好的模型权重
174 if val_acc > max_acc:
175 folder = 'save_model'
176 if not os.path.exists(folder):
177 os.mkdir('save_model')
178 max_acc = val_acc
179 print(f'save best model,第{i + 1}轮')
180 torch.save(model.state_dict(), 'save_model/best_model.pth') # 保存网络权重
181 # 保存最后一轮
182 if i == epoch - 1:
183 torch.save(model.state_dict(), 'save_model/last_model.pth') # 保存
184 print("done")
185
186 # 画图
187 matplot_loss(train_loss_list, val_loss_list)
188 matplot_acc(train_acc_list, val_acc_list)
train.py
训练结束后可以得到训练集和验证集的loss,acc对比图


简单的评估下:可以看到加载预训练权重后,即使只训练20轮,验证集的准确率高达90%多,这足以证明迁移学习的强大之处。
总结
VGG-16除了参数很多,需要较长的训练时间外,模型相比AlexNet还是进步挺大的
自己敲一下代码,会学到很多不懂的东西
最后,多看,多学,多试,总有一天你会称为大佬!
PyTorch复现VGG学习笔记的更多相关文章
- Pytorch线性规划模型 学习笔记(一)
Pytorch线性规划模型 学习笔记(一) Pytorch视频学习资料参考:<PyTorch深度学习实践>完结合集 Pytorch搭建神经网络的四大部分 1. 准备数据 Prepare d ...
- Note | PyTorch官方教程学习笔记
目录 1. 快速入门PYTORCH 1.1. 什么是PyTorch 1.1.1. 基础概念 1.1.2. 与NumPy之间的桥梁 1.2. Autograd: Automatic Differenti ...
- pytorch文档学习笔记(2)
三.CUDA semantics 二.Broadcasting semantics 广播机制 广播机制要第一项对齐,第一项对齐后(相等)才能广播,或者某个第一项为1. 但如果两个size个数相等,则 ...
- Pytorch CNN网络MNIST数字识别 [超详细记录] 学习笔记(三)
目录 1. 准备数据集 1.1 MNIST数据集获取: 1.2 程序部分 2. 设计网络结构 2.1 网络设计 2.2 程序部分 3. 迭代训练 4. 测试集预测部分 5. 全部代码 1. 准备数据集 ...
- 【PyTorch深度学习】学习笔记之PyTorch与深度学习
第1章 PyTorch与深度学习 深度学习的应用 接近人类水平的图像分类 接近人类水平的语音识别 机器翻译 自动驾驶汽车 Siri.Google语音和Alexa在最近几年更加准确 日本农民的黄瓜智能分 ...
- 【pytorch】学习笔记(四)-搭建神经网络进行关系拟合
[pytorch学习笔记]-搭建神经网络进行关系拟合 学习自莫烦python 目标 1.创建一些围绕y=x^2+噪声这个函数的散点 2.用神经网络模型来建立一个可以代表他们关系的线条 建立数据集 im ...
- 【pytorch】学习笔记(三)-激励函数
[pytorch]学习笔记-激励函数 学习自:莫烦python 什么是激励函数 一句话概括 Activation: 就是让神经网络可以描述非线性问题的步骤, 是神经网络变得更强大 1.激活函数是用来加 ...
- 【pytorch】学习笔记(二)- Variable
[pytorch]学习笔记(二)- Variable 学习链接自莫烦python 什么是Variable Variable就好像一个篮子,里面装着鸡蛋(Torch 的 Tensor),里面的鸡蛋数不断 ...
- tensorflow学习笔记——VGGNet
2014年,牛津大学计算机视觉组(Visual Geometry Group)和 Google DeepMind 公司的研究员一起研发了新的深度卷积神经网络:VGGNet ,并取得了ILSVRC201 ...
- Vue学习笔记-2
前言 本文非vue教程,仅为学习vue过程中的个人理解与笔记,有说的不正确的地方欢迎指正讨论 1.computed计算属性函数中不能使用vm变量 在计算属性的函数中,不能使用Vue构造函数返回的vm变 ...
随机推荐
- “kill -9”一时爽,秋后算账泪两行
接受两个参数.第一个参数是pid,第二个参数是等待的秒数. #!/bin/bash # 接受两个参数.第一个参数是pid,第二个参数是等待的秒数. pid=$1 count=$2 n=0 if [ ! ...
- Django命令
(venv) E:\Py_CODE\myapp>python manage.py --help Type 'manage.py help <subcommand>' for help ...
- STM32F10x SPL V3.6.2 集成 FreeRTOS v202112
STM32F10x SPL 集成 FreeRTOS 在整理 GCC Arm 工具链的Bluepill代码示例, 常用外设都差不多了, 接下来是 FreeRTOS, 网上查到的基本上都是基于旧版本的集成 ...
- NSIS V3.08 简体中文增强版
说明: 该3.08版本属本人业余时间集成修改制作,首发博客园,欢迎反馈安装与使用中出现的BUG,转载请注明出处! 本版本母版源自NSIS(Nullsoft Scriptable Install Sys ...
- javaweb 导出文件名乱码的问题解决方案
fileName = new String(fileName.getBytes("ISO8859-1"), "UTF-8"); 或者 String finalF ...
- day10-习题
习题 1.Homework01 (1) D -- 没有在别名上加引号(ps:别名的as可以省略) (2) B -- 判断null或非空不能用不等于号 (3) C 2.Homework02 写出查看de ...
- 使用FreeMarker配置动态模板
FreeMarker动态模板 目录 FreeMarker动态模板 前言 准备工作 FreeMarker 代码构建 项目结构 创建 Configuration 实例 调用 模板文件 调用结果 Tips ...
- vue中将验证表单输入框的方法写在一个js文件中(表达式验证邮箱、身份证、号码、两次输入的密码是否一致)
文章目录 1.实现的效果 2.编写的js文件(这里写在了api文件下) 3.在vue页面中引入(script) 4.页面代码 1.实现的效果 20220606_154646 2.编写的js文件(这里写 ...
- NLP之TextRNN(预测下一个单词)
TextRNN @ 目录 TextRNN 1.基本概念 1.1 RNN和CNN的区别 1.2 RNN的几种结构 1.3 多对多的RNN 1.4 RNN的多对多结构 1.5 RNN的多对一结构 1.6 ...
- day02-HTML02
4.HTML 4.3HTML基本标签 4.3.9表格(table)标签 基本语法: <table border="边框宽度" cellspacing="空隙大小&q ...