C++11(列表初始化+变量类型推导+类型转换+左右值概念、引用+完美转发和万能应用+定位new+可变参数模板+emplace接口)
列表初始化
用法
在C++98中,{}只能够对数组元素进行统一的列表初始化,但是对应自定义类型,无法使用{}进行初始化,如下所示:
// 数组类型
int arr1[] = { 1,2,3,4 };
int arr2[6]{ 1,2,3,4,5,6 };
// 自定义类型(C++98不支持下面这种初始化的方式)
vector<int> v{ 1,2,3 };
在C++11中,扩大了用大括号括起的列表(初始化列表)的使用范围,使其可用于所有的内置类型和用户自定义的类型,使用初始化列表时,可添加等号(=),也可不添加,如下所示:
// 内置类型变量
int a{ 2 };
int b = { 3 };
int c = { a + b };
// 动态数组 C++98不支持
int* arr = new int[5]{ 1,2,3,4,5 };
// 容器使用{}进行初始化
// vector<int> v = { 1,2,3 };
vector<int> v{ 1,2,3 };// 等号可以省略不写
map<int, int> m{ {1,1},{2,2},{3,3} };
自定义类型的列表初始化:
下面是自己定义的一个类:
class Point
{
public:
Point(int x, int y)
:_x(x)
,_y(y)
{}
void PrintPoint()
{
printf("点的坐标为:(%d, %d)\n", _x, _y);
}
private:
int _x;
int _y;
};
创建一个Point类并使用{}对其进行列表初始化,具体如下:
int main()
{
// 自定义类型列表初始化
Point p{ 1, 2 };
p.PrintPoint();
size_t i = 0;
return 0;
}
initializer_list
initializer_list容器没有提供对应的增删查改等接口,因为initializer_list并不是专门用于存储数据的,而是为了让其他容器支持列表初始化的。
initializer_list一般是作为构造函数的参数,C++11对STL中的不少容器就增加initializer_list作为参数的构造函数,这样初始化容器对象就更方便了。也可以作为operator=的参数,这样就可以用大括号赋值对应多个对象的列表初始化,必须支持一个带有initializer_list类型参数的构造函数。
注意: 这种类型的对象由编译器根据初始化列表声明自动构造,初始化列表声明是用{}和,容器使用initializer_list作为构造函数的参数的例子
实例演示: 简单模拟一个vector中的构造函数和赋值重载
template<class T>
class Vector
{
public:
Vector(initializer_list<T> l)
:_size(0)
,_capacity(l.size())
{
_a = new T[_capacity];
for (auto e : l)
{
_a[_size++] = e;
}
}
Vector<T>& operator=(initializer_list<T> l)
{
delete _a;
_size = 0;
_capacity = l.size();
_a = new T[_capacity];
for (auto e : l)
{
_a[_size++] = e;
}
return *this;
}
private:
T* _a;
size_t _size;
size_t _capacity;
};
int main()
{
Vector<int> v1 = { 1,2,3 };
Vector<int> v2 = { 3,5,7,9 };
v2 = { 1,2,3 };
return 0;
}
补充:
- C++98并不支持直接用列表对容器进行初始化,这种初始化方式是在C++11引入initializer_list后才支持的。
- 这些容器之所以支持使用列表进行初始化,根本原因是因为C++11给这些容器都增加了一个构造函数,这个构造函数就是以initializer_list作为参数的。
- 当用列表对容器进行初始化时,这个列表被识别成initializer_list类型,于是就会调用这个新增的构造函数对该容器进行初始化。
- 这个新增的构造函数要做的就是遍历initializer_list中的元素,然后将这些元素依次插入到要初始化的容器当中即可。
initializer_list使用示例:
- 如果要让vector支持列表初始化,就需要增加一个以initializer_list作为参数的构造函数。
- 在构造函数中遍历initializer_list时可以使用迭代器遍历,也可以使用范围for遍历,因为范围for底层实际采用的就是迭代器方式遍历。
- 使用迭代器方式遍历时,需要在迭代器类型前面加上typename关键字,指明这是一个类型名字。因为这个迭代器类型定义在一个类模板中,在该类模板未被实例化之前编译器是无法识别这个类型的。
- 最好也增加一个以initializer_list作为参数的赋值运算符重载函数,以支持直接用列表对容器对象进行赋值,但实际也可以不增加。
template<class T>
class vector
{
public:
typedef T* iterator;
vector(initializer_list<T> il)
{
_start = new T[il.size()];
_finish = _start;
_endofstorage = _start + il.size();
//迭代器遍历
//typename initializer_list<T>::iterator it = il.begin();
//while (it != il.end())
//{
// push_back(*it);
// it++;
//}
//范围for遍历
for (auto e : il)
{
push_back(e);
}
}
vector<T>& operator=(initializer_list<T> il)
{
vector<T> tmp(il);
std::swap(_start, tmp._start);
std::swap(_finish, tmp._finish);
std::swap(_endofstorage, tmp._endofstorage);
return *this;
}
private:
iterator _start;
iterator _finish;
iterator _endofstorage;
};
变量类型推导
auto类型推导
在C++98中auto是一个存储类型的说明符,表明变量是局部自动存储类型,但是局部域中定义局部的变量默认就是自动存储类型,所以auto就没什么价值了。C++11中废弃auto原来的用法,将其用于实现自动类型推导。这样要求必须进行显示初始化,让编译器将定义对象的类型设置为初始化值的类型。
注意: auto声明的类型必须要进行初始化,否则编译器无法推导出auto的实际类型。auto不能作为函数的参数和返回值,且不能用来直接声明数组类型。
int main()
{
int a = 10;
auto pa = &a;
auto& ra = a;// 声明引用类型要加&
cout << typeid(a).name() << endl;
cout << typeid(pa).name() << endl;
cout << typeid(ra).name() << endl;
return 0;
}
decltype类型推导
decltype是根据表达式的实际类型推演出定义变量时所用的类型。且还可以使用推导出来的类型进行变量声明
int Add(int x, int y)
{
return x + y;
}
int main()
{
int a = 10;
int b = 20;
// 用decltype自动推演a+b的实际类型
decltype(a + b) c = 10;
cout << typeid(c).name() << endl;
// 不带参数,推导函数类型
cout << typeid(decltype(Add)).name() << endl;
// 带参数,推导函数返回值类型,注意这里不会调用函数
cout << typeid(decltype(Add(1,1))).name() << endl;
return 0;
}
注意: decltype不可以作为函数的参数,编译时推导类型
nullptr
①C++中NULL被定义成字面量0,这样就可能会带来一些问题,因为0既能表示指针常量,又能表示整型常量。所以出于清晰和安全的角度考虑,C++11中新增了nullptr,用于表示空指针
/* Define NULL pointer value */
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else /* __cplusplus */
#define NULL ((void *)0)
#endif /* __cplusplus */
#endif /* NULL */
②在大部分情况下使用NULL不会存在什么问题,但是在某些极端场景下就可能会导致匹配错误
- NULL和nullptr的含义都是空指针,所以这里调用函数时肯定希望匹配到的都是参数类型为
int*的重载函数,但最终却因为NULL本质是字面量0,而导致NULL匹配到了参数为int类型的重载函数,因此在C++中一般推荐使用nullptr
void f(int arg)
{
cout << "void f(int arg)" << endl;
}
void f(int* arg)
{
cout << "void f(int* arg)" << endl;
}
int main()
{
f(NULL); //void f(int arg)
f(nullptr); //void f(int* arg)
return 0;
}
类型转换
C语言中的类型转换
在C语言中,如果赋值运算符左右两侧类型不同,或者形参与实参类型不匹配,或者返回值类型与接收返回值类型不一致时,就需要发生类型转化,C语言中总共有两种形式的类型转换:隐式类型转换和显式类型转换。
(1) 两种形式的类型转换
- 隐式类型转化:编译器在编译阶段自动进行,能转就转,不能转就编译失败
- 显式类型转化:需要用户自己处理
- 类型转换应为相近类型 : int, short, char之间就可以互相转换,因为他们都是用来表示数据的大小,只是范围不一样;char因为编码的原因用来表示字符,严格来说如果是有符号的话,它是从-128 - 127这个范围的整数
void Test()
{
int i = 1;
// 隐式类型转换
double d = i;
printf("%d, %.2f\n", i, d);
// 显示的强制类型转换
int* p = &i;
int address = (int)p;
printf("%x, %d\n", p, address);
}
C语言类型转换的缺陷 : 转换的可视性比较差,所有的转换形式都是以一种相同形式书写,难以跟踪错误的转换
C++四种类型转换
C风格的转换格式很简单,但是有不少缺点的:
- ①隐式类型转化有些情况下可能会出问题:比如数据精度丢失
- ② 显式类型转换将所有情况混合在一起,代码不够清晰
因此C++提出了自己的类型转化风格,注意因为C++要兼容C语言,所以C++中还可以使用C语言的转化风格
C++强制类型转换
(1)static_cast
- static_cast用于非多态类型的转换(静态转换),编译器隐式执行的任何类型转换都可用static_cast,但它不能用于两个不相关的类型进行转换
int main()
{
double d = 12.34;
int a = static_cast<int>(d); //相近类型转换
cout << a << endl;
int *p = static_cast<int*>(a); //不相近类型转换 -- 报错
return 0;
}
(2)reinterpret_cast
- reinterpret_cast操作符通常为操作数的位模式提供较低层次的重新解释,用于将一种类型转换为另一种不同的类型
int main()
{
double d = 12.34;
int a = static_cast<int>(d);
cout << a << endl;
// 这里使用static_cast会报错,应该使用reinterpret_cast
//int *p = static_cast<int*>(a);
int *p = reinterpret_cast<int*>(a); //不相近类型转换
return 0;
}
(3)const_cast
- const_cast最常用的用途就是删除变量的const属性,方便赋值
- C++把这个单独分出来,意思提醒用的人注意,const属性被去掉以后,会被修改。小心跟编译器优化冲突误判
void Test1()
{
//const修饰的叫常变量
const int a = 2;
//a = 10; //a不可修改
//const int* p = &a; //还是不能改变
// *p = 10;
int* p = const_cast<int*>(&a); //const_cast用于去掉const属性
*p = 10; //可修改
cout << a << endl; //2 从寄存器中取
cout << *p << endl; //10 从内存中取
}
(4)dynamic_cast
①dynamic_cast用于将一个父类对象的指针/引用转换为子类对象的指针或引用(动态转换)
- 向上转型:子类对象指针/引用 -> 父类指针/引用(不需要转换,赋值兼容规则)
- 向下转型:父类对象指针/引用 -> 子类指针/引用(用dynamic_cast转型是安全的)
②注意:
- dynamic_cast只能用于含有虚函数的类 ,因为运行时类型检查需要运行时的类型信息,而这个信息是存储在虚函数表中的,只有定义了虚函数的类才有虚函数表
- dynamic_cast会先检查是否能转换成功,能成功则转换,不能则返回0
③测试用例
- pa有两种情况 :pa指向父类对象,pa指向子类对象
- 如果pa是指向父类对象,那么不做任何处理
- 如果pa是指向子类对象,那么请转回子类,并访问子类对象中_b成员
dynamic_cast :如果pa指向的父类对象,那么则转换不成功,返回nullptr; 如果 - pa指向的子类对象,那么则转换成功,返回对象指针
- dynamic_cast会先检查是否能转换成功,能成功则转换,不能则返回
class A
{
virtual void f() {}
public:
};
class B : public A
{
public:
int _b = 0;
};
void func(A* pa)
{
B* pb1 = static_cast<B*>(pa);
B* pb2 = dynamic_cast<B*>(pa);
if (pb2 == nullptr)
{
cout << "转换失败!" << endl;
}
else
{
pb2->_b++;
}
cout << "pb1:" << pb1 << endl;
cout << "pb2:" << pb2 << endl;
}
int main()
{
A aa;
B bb;
func(&aa);
func(&bb);
}

explicit
- explicit用来修饰构造函数,从而禁止单参数构造函数的隐式转换
class A
{
public:
explicit A(int a)
{
cout << "A(int a)" << endl;
}
A(const A& a)
{
cout << "A(const A& a)" << endl;
}
private:
int _a;
};
int main()
{
A a1(1);
//A a2 = 1; //error
return 0;
}
①在语法上,代码中的A a2 = 1等价于以下两句 :
A tmp(1); //构造
A a2(tmp); //拷贝构造
②在早期的编译器中,当编译器遇到A a2 = 1这句代码时,会先构造一个临时对象,再用这个临时对象拷贝构造a2。但是现在的编译器已经做了优化,当遇到A a2 = 1这句代码时,会直接按照A a2(1)的方式进行处理,这也叫做隐式类型转换
③但对于单参数的自定义类型来说,A a2 = 1这种代码的可读性不是很好,因此可以用explicit修饰单参数的构造函数,从而禁止单参数构造函数的隐式转换
右值引用和移动语义
左值VS右值
在之前的博客中,我已经介绍过了引用的语法,那里的引用都是左值引用。C++11新增了右值引用的语法特性,给右值取别名。左值引用和右值引用都是给对象取别名,只不过二者对象的特性不同
注意: 左值引用用符号&,右值引用的符号是&&
| 专有名词 | 概念 |
|---|---|
| 左值 | 一个表示数据的表达式,可以取地址和赋值,且左值可以出现在赋值符号的左边,也可以出现在赋值符号的右边,例如:普通变量、指针等,const修饰后的左值不可以赋值,但是可以取地址,所以还是左值 |
| 左值引用 | 给左值的引用,给左值取别名 ,例如:int& ra = a; |
| 右值 | 一个表示数据的表达式,右值不能取地址,右值可以出现在赋值符号的右边,但是不能出现出现在赋值符号的左边如:字面常量、表达式返回值,函数返回值(这个不能是左值引用返回)等等 |
| 右值引用 | 给右值的引用,给右值取别名,例如:int&& ra = Add(a,b) |
实例1:
int Add(int x, int y)
{
return x + y;
}
int main()
{
int a = 10;// 左值,可以取地址
int& ra = a;// 左值引用
int&& ret = Add(3, 4);// 函数的返回值是一个临时变量,是一个右值
return 0;
}
总结:
左值
普通类型的变量,可以取地址
const修饰的常量,可以取地址,也是左值
如果表达式运行结果或单个变量是一个引用,则认为是右值
右值(本质就是一个临时变量或常量值)
- 纯右值:基本类型的常量或临时对象,如:a+b,字面常量
- 将亡值:自定义类型的临时对象用完自动完成析构,如:函数以值的方式返回一个对象
- 这些纯右值和将亡值并没有被实际存储起来,这也就是为什么右值不能被取地址的原因,因为只有被存储起来后才有地址
左值引用VS右值引用
传统的C++语法中就有引用的语法,而C++11中新增了右值引用的语法特性,为了进行区分,于是将C++11之前的引用就叫做左值引用。但是无论左值引用还是右值引用,本质都是给对象取别名。
①左值引用就是对左值的引用,给左值取别名,通过“&”来声明
int main()
{
//以下的p、b、c、*p都是左值
int* p = new int(0);
int b = 1;
const int c = 2;
//以下几个是对上面左值的左值引用
int*& rp = p;
int& rb = b;
const int& rc = c;
int& pvalue = *p;
return 0;
}
②右值引用就是对右值的引用,给右值取别名,通过“&&”来声明
int main()
{
double x = 1.1, y = 2.2;
//以下几个都是常见的右值
10;
x + y;
fmin(x, y);
//以下几个都是对右值的右值引用
int&& rr1 = 10;
double&& rr2 = x + y;
double&& rr3 = fmin(x, y);
return 0;
}
③需要注意的是,右值是不能取地址的,但是给右值取别名后,会导致右值被存储到特定位置,这时这个右值可以被取到地址,并且可以被修改,如果不想让被引用的右值被修改,可以用const修饰右值引用。
int main()
{
double x = 1.1, y = 2.2;
int&& rr1 = 10;
const double&& rr2 = x + y;
rr1 = 20;
rr2 = 5.5; //报错
return 0;
}
④左值引用总结
- 左值引用不能引用右值,因为这涉及权限放大的问题,右值是不能被修改的,而左值引用是可以修改。
- 但是const左值引用可以引用右值,因为const左值引用能够保证被引用的数据不会被修改。
- 因此const左值引用既可以引用左值,也可以引用右值
int main()
{
int a = 10;
int& r1 = a;// 左值引用
//int& r2 = 10;// error,左值引用不可以引用右值 (这是因为权限放大了,所以不行)
const int& r2 = 10;// const的左值引用可以引用右值(这是因为权限不变,所以可以)
return 0;
}
⑤右值引用总结
- 右值引用只能引用右值,不能引用左值。
- 但是右值引用可以引用move以后的左值。
- move函数是C++11标准提供的一个函数,被move后的左值能够赋值给右值引用。
int main()
{
int&& r1 = 10;// 对字面常量进行引用(右值引用)
r1 = 20;// 10原本是一个字面常量,无空间存储,右值引用后会开一块空间把值存起来,可以取地址
cout << &r1 << endl;
int a = 10;
// int&& r2 = a; // error,右值引用不可以引用左值
int&& r2 = move(a);// move后的左值可以引用,a的属性不变,引用的是move的返回值
return 0;
}
右值引用的移动语义
移动语义: 将一个对象中资源移动到另一个对象中的方式,可以有效减少拷贝,减少资源浪费,提供效率
问题提出:
先看下面简单的移动代码:
class String
{
public:
String(const char* str = "")
:_str(new char[strlen(str) + 1])
, _size(0)
{
strcpy(_str, str);
_str[_size] = '\0';
}
String(const String& s)
:_str(new char[strlen(s._str) + 1])
, _size(s._size)
{
cout << "深拷贝" << endl;
strcpy(_str, s._str);
}
String& operator=(String& s)
{
if (this != &s)
{
cout << "深拷贝" << endl;
delete _str;
_str = new char[strlen(s._str) + 1];
strcpy(_str, s._str);
_size = s._size;
_str[_size] = '\0';
}
return *this;
}
~String()
{
delete _str;
}
private:
char* _str;
size_t _size;
};
String func(String& str)
{
String tmp(str);
return tmp;
}
int main()
{
String s1("123");//
String s2(s1);
String s3(func(s1));
return 0;
}
/*
输出:
深拷贝
深拷贝
深拷贝
*/
分析结果:
第一次深拷贝是因为s1拷贝构造s2,这里都不难理解。主要看后两次,s1传参过程不发生深拷贝,因为这里是传引用,接着就是str拷贝构造tmp,这里会发生一次深拷贝,紧接着就是返回tmp,tmp会先拷贝构造一个临时对象(这里会发生一次深拷贝),然后临时对象拷贝构造给s3(这里会发生一次深拷贝),连续两次拷贝构造会被编译器优化成一次,这也就是我们上面看到的两次深拷贝
分析问题:
在上面的代码中,可以发现,func中的tmp、返回是构造的临时对象和s3都有一个独立的空间,且内容是相同的,这里相当于创建了3个内容完全相同的对象,这是一种极大的浪费,且效率也会降低
如何解决?
移动语义来解决
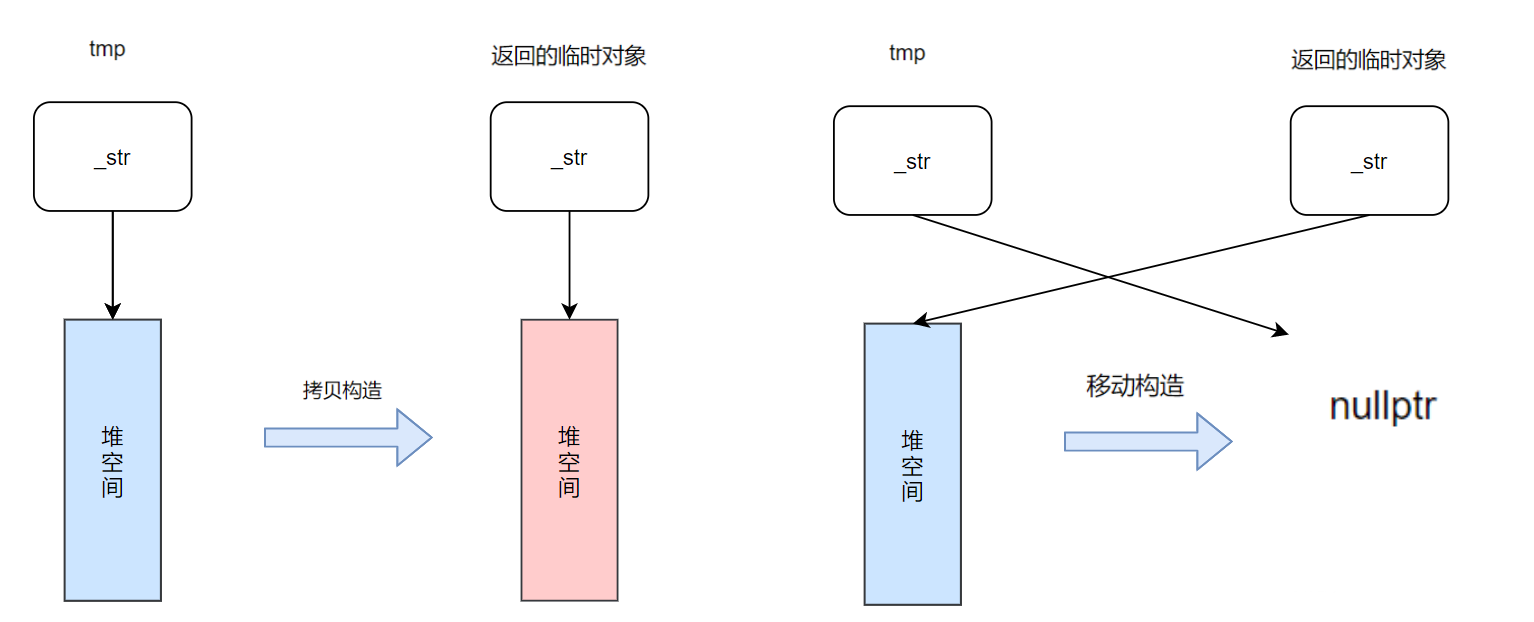
这里解决其实就是进行资源的转移,这里加上一份移动构造的代码,如下:
String(String&& s)
:_str(s._str)
{
// 对于将亡值,内部做移动拷贝
cout << "移动拷贝" << endl;
s._str = nullptr;
}
/*
输出结果:
深拷贝
深拷贝
移动拷贝
*/
因为返回的临时对象是一个右值,所以会调用上面的移动构造的代码对返回的临时对象进行构造,本质是资源进行转移,此时tmp指向的是一块空的资源。最后返回的临时对象拷贝构造给s3时还是调用了移动构造,两次移动构造被编译器优化为一个。可以看出的是这里解决的是减少接受函数返回对象时带来的拷贝,极大地提高了效率
除了移动构造,我们还可以增加移动赋值,具体如下:
String& operator=(String&& s)
{
cout << "移动赋值" << endl;
_str = s._str;
_size = s._size;
s._str = nullptr;
return *this;
}
演示:
int main()
{
String s1("123");
String s2("ABC");
s2 = func(s1);
return 0;
}
/*
输出结果:
深拷贝
移动拷贝
移动赋值
*/
可以看出的是func返回的临时对象是通过移动赋值给s2的,也是一次资源的转义
注意:
- 移动构造和移动赋值函数的参数千万不能设置成const类型的右值引用,因为资源无法转移而导致移动语义失效。
- 在C++11中,编译器会为类默认生成一个移动构造和移动赋值,该移动构造和移动赋值为浅拷贝,因此当类中涉及到资源管理时,用户必须显式定义自己的移动构造和移动赋值。
总结: 右值引用本身没有多大意义,引入了移动构造和移动赋值就有意义了
右值引用和左值引用减少拷贝的场景:
- 作参数时: 左值引用减少传参过程中的拷贝。右值引用解决的是传参后,函数内部的拷贝构造
- 作返回值时: 如果出了函数作用域,对象还存在,那么可以使用左值引用减少拷贝。如果不存在,那么产生的临时对象可以通过右值引用提供的移动构造生成,然后通过移动赋值或移动构造的方式将临时对象的资源给接受返回值者
move
move: 当需要用右值引用引用一个左值时,可以通过move来获得绑定到左值上的右值引⽤。C++11中,std::move()函数位于头文件中,该函数名字具有迷惑性,它并不搬移任何东西,唯一的功能就是将一个左值强制转化为右值引用,然后实现移动语义
move函数的定义
template<class _Ty>
inline typename remove_reference<_Ty>::type&& move(_Ty&& _Arg) _NOEXCEPT
{
//forward _Arg as movable
return ((typename remove_reference<_Ty>::type&&)_Arg);
}
- move函数中_Arg参数的类型不是右值引用,而是万能引用。万能引用跟右值引用的形式一样,但是右值引用需要是确定的类型。
- 一个左值被move以后,它的资源可能就被转移给别人了,因此要慎用一个被move后的左值。
注意:
- 被转化的左值,其生命周期并没有随着左值的转化而改变,即std::move转化的左值变量value不会被销毁。move告诉编译器:我们有⼀个左值,但我们希望像⼀个右值⼀样处理它
- STL中也有另一个move函数,就是将一个范围中的元素搬移到另一个位置
使用如下:
int main()
{
String s1("123");
// 这里我们把s1 move处理以后, 会被当成右值,调用移动构造
// 但是这里要注意,一般是不要这样用的,因为我们会发现s1的
// 资源被转移给了s2,s1被置空了
String s2(move(s1));
return 0;
}
//输出:移动拷贝
需要知道的是,move后的s1变成了一个右值,所以会调用移动构造去构造s2,这样s1的资源就被转移给了s2,s1本身也没有资源了
STL增加了右值引用
列举一部分:
- list的尾插
void push_back(const value_type& val);
void push_back(value_type&& val);
- vector的尾插
void push_back(const value_type& val);
void push_back(value_type&& val);
如果要插入的对象是一个纯右值或将亡值,就会调用下面这个版本的插入,如果为左值就会调用上面这个版本的插入
完美转发和万能引用
- 完美转发:是指在函数模板中,完全依照模板的参数的类型,将参数传递给函数模板中调用的另外一个函数。
- 万能引用: 模板中的&&不代表右值引用,而是万能引用,其既能接收左值又能接收右值,但是引用类型的唯一缺点就是限制了接收的类型,后续使用中都退化成了左值。
问题: 右值引用的对象再作为实参传递时,属性会退化为左值,只能匹配左值引用(右值引用后可以取地址,底层会开一块空间把这样的值存起来,所以属性发生了改变)
如下:由于PerfectForward函数的参数类型是万能引用,因此既可以接收左值也可以接收右值,而我们在PerfectForward函数中调用Fun函数,就是希望调用PerfectForward函数时传入左值、右值、const左值、const右值,能够匹配到对应版本的Fun函数
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }
void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }
// std::forward<T>(t)在传参的过程中保持了t的原生类型属性。
template<typename T>
void PerfectForward(T&& t)
{
Fun(t);
}
int main()
{
PerfectForward(10); // 右值
int a;
PerfectForward(a); // 左值
PerfectForward(std::move(a)); // 右值
const int b = 8;
PerfectForward(b); // const 左值
PerfectForward(std::move(b)); // const 右值
return 0;
}
/*
输出结果:属性丢失
左值引用
左值引用
左值引用
const 左值引用
const 左值引用
*/
- 但实际调用PerfectForward函数时传入左值和右值,最终都匹配到了左值引用版本的Func函数,调用PerfectForward函数时传入const左值和const右值,最终都匹配到了const左值引用版本的Func函数。
- 根本原因就是,右值被引用后会导致右值被存储到特定位置,这时这个右值可以被取到地址,并且可以被修改,所以在PerfectForward函数中调用Func函数时会将t识别成左值。
- 也就是说,右值经过一次参数传递后其属性会退化成左值,如果想要在这个过程中保持右值的属性,就需要用到完美转发
解决:要想在参数传递过程中保持其原有的属性,需要在传参时调用forward函数,使用完美转发能够在传递过程中保持它的左值或者右值的属性
template<typename T>
void PerfectForward(T&& t)
{
Fun(std::forward<T>(t));
}
/*
输出结果:属性保持了
右值引用
左值引用
右值引用
const 左值引用
const 右值引用
*/
总结: 右值引用在传参的过程中移动要进行完美转发,否则会丢失右值属性
完美转发的使用场景
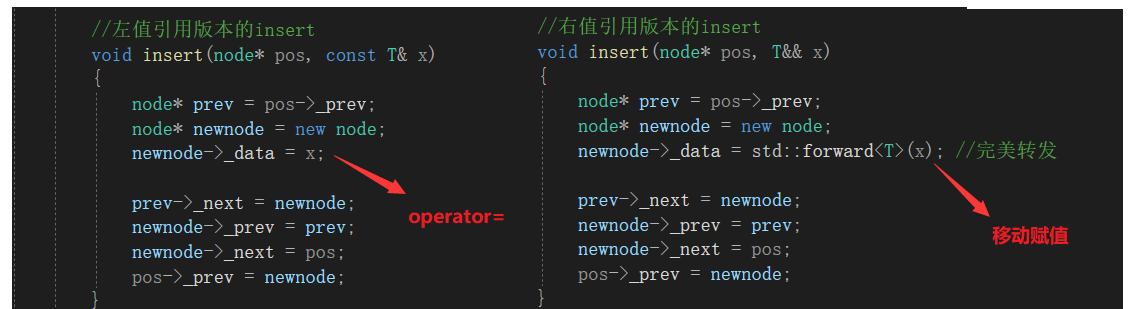
①模拟实现了一个简化版的list类,类当中分别提供了左值引用版本和右值引用版本的push_back和insert函数
namespace XM
{
template<class T>
struct ListNode
{
T _data;
ListNode* _next = nullptr;
ListNode* _prev = nullptr;
};
template<class T>
class list
{
typedef ListNode<T> node;
public:
//构造函数
list()
{
_head = new node;
_head->_next = _head;
_head->_prev = _head;
}
//左值引用版本的push_back
void push_back(const T& x)
{
insert(_head, x);
}
//右值引用版本的push_back
void push_back(T&& x)
{
insert(_head, std::forward<T>(x)); //完美转发
}
//左值引用版本的insert
void insert(node* pos, const T& x)
{
node* prev = pos->_prev;
node* newnode = new node;
newnode->_data = x;
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = pos;
pos->_prev = newnode;
}
//右值引用版本的insert
void insert(node* pos, T&& x)
{
node* prev = pos->_prev;
node* newnode = new node;
newnode->_data = std::forward<T>(x); //完美转发
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = pos;
pos->_prev = newnode;
}
private:
node* _head; //指向链表头结点的指针
};
}
int main()
{
XM::list<XM::string> lt;
XM::string s("1111");
lt.push_back(s); //调用左值引用版本的push_back
lt.push_back("2222"); //调用右值引用版本的push_back
return 0;
}
②调用左值引用版本的push_back函数插入元素时,会调用string原有的operator=函数进行深拷贝;调用右值引用版本的push_back函数插入元素时,只会调用string的移动赋值进行资源的移动。
- 因为实现push_back函数时复用了insert函数的代码,对于左值引用版本的push_back函数,在调用insert函数时只能调用左值引用版本的insert函数,而在insert函数中插入元素时会先new一个结点,然后将对应的左值赋值给该结点,因此会调用string原有的operator=函数进行深拷贝。
- 而对于右值引用版本的push_back函数,在调用insert函数时就可以调用右值引用版本的insert函数,在右值引用版本的insert函数中也会先new一个结点,然后将对应的右值赋值给该结点,因此这里就和调用string的移动赋值函数进行资源的移动。
- 这个场景中就需要用到完美转发,否则右值引用版本的push_back接收到右值后,该右值的右值属性就退化了,此时在右值引用版本的push_back函数中调用insert函数,也会匹配到左值引用版本的insert函数,最终调用的还是原有的operator=函数进行深拷贝。
- 此外,除了在右值引用版本的push_back函数中调用insert函数时,需要用完美转发保持右值原有的属性之外,在右值引用版本的insert函数中用右值给新结点赋值时也需要用到完美转发,否则在赋值时也会将其识别为左值,导致最终调用的还是原有的operator=函数。
也就是说,只要想保持右值的属性,在每次右值传参时都需要进行完美转发,实际STL库中也是通过完美转发来保持右值属性的。
③代码中push_back和insert函数的参数T&&是右值引用,而不是万能引用,因为在list对象创建时这个类就被实例化了,后续调用push_back和insert函数时,参数T&&中的T已经是一个确定的类型了,而不是在调用push_back和insert函数时才进行类型推导的。
与STL中的list的区别
①将刚才测试代码中的list换成STL当中的list
调用左值引用版本的push_back插入结点,在构造结点时会调用string的拷贝构造函数。
调用右值引用版本的push_back插入结点,在构造结点时会调用string的移动构造函数。
而用我们模拟实现的list时,调用的却不是string的拷贝构造和移动构造,而对应是string原有的operator=和移动赋值。
②我们模拟实现的list容器,是通过new操作符为新结点申请内存空间的,在申请内存后会自动调用构造函数对进行其进行初始化,因此在后续用左值或右值对其进行赋值时,就会调用对应的 operator= 或移动赋值 进行深拷贝或资源的转移。
③STL库中的容器都是通过空间配置器获取内存的,因此在申请到内存后不会调用构造函数对其进行初始化,而是后续用左值或右值对其进行拷贝构造,因此最终调用的就是拷贝构造或移动构造。
- 如果想要得到与STL相同的实验结果,可以使用malloc函数申请内存,这时就不会自动调用构造函数进行初始化,然后在用定位new(下面会介绍)的方式用左值或右值对申请到的内存空间进行构造,这时调用的对应就是拷贝构造或移动构造。

定位new
定位new表达式是在已分配的原始内存空间中调用构造函数初始化一个对象。换句话说就是,现在空间已经有了,不需要定位new像常规new一样去给申请空间,只需要定位new在已有的空间上调用构造函数构造对象而已。
定位new的使用格式:
1.new (place_address) type
2.new (palce_address) type (initializer_list)
用法1与用法2的区别在于对象是否需要初始化,其中place_address必须是一个指针,initializer_list是type类型的初始化列表。
注意事项:
#include <iostream>
#include <string>
#include <new>
using namespace std;
const int BUF = 512;
class JustTesting {
private:
string words;
int number;
public:
JustTesting(const string& s = "Just Testing", int n = 0) {
words = s;
number = n;
cout << words << " constructed" << endl;
}
~JustTesting() { cout << words << " destroyed!" << endl; }
void Show()const { cout << words << " , " << number << endl; }
};
int main() {
char* buffer = new char[BUF];//常规new在堆上申请空间
JustTesting* pc1, * pc2;
pc1 = new (buffer) JustTesting;//定位new
pc2 = new JustTesting("Heap1", 20);//常规new
cout << "Memory block address:\n" << "buffer: " << (void*)buffer << " heap: " << pc2 << endl;
cout << "Memory contents:\n" << pc1 << ": ";
pc1->Show();
cout << pc2 << ": ";
pc2->Show();
JustTesting* pc3, * pc4;
pc3 = new (buffer)JustTesting("Bad Idea", 6);//定位new
pc4 = new JustTesting("Heap2", 10);//常规new
cout<< "Memory contents:\n" << pc3 << ": ";
pc3->Show();
cout << pc4 << ": ";
pc4->Show();
delete pc2;//释放pc2申请的空间
delete pc4;//释放pc4申请的空间
delete[] buffer;//释放buffer指向的空间
cout << "Done!" << endl;
return 0;
}
该例程首先使用常规new创建了一块512字节的内存缓冲区(buffer指向),然后使用new在堆上创建两个JustTesting对象,并且尝试使用定位new在buffer指向的内存缓冲区上创建两个JustTesting对象。最后使用delete释放new分配的内存。以下是该例程的运行结果:
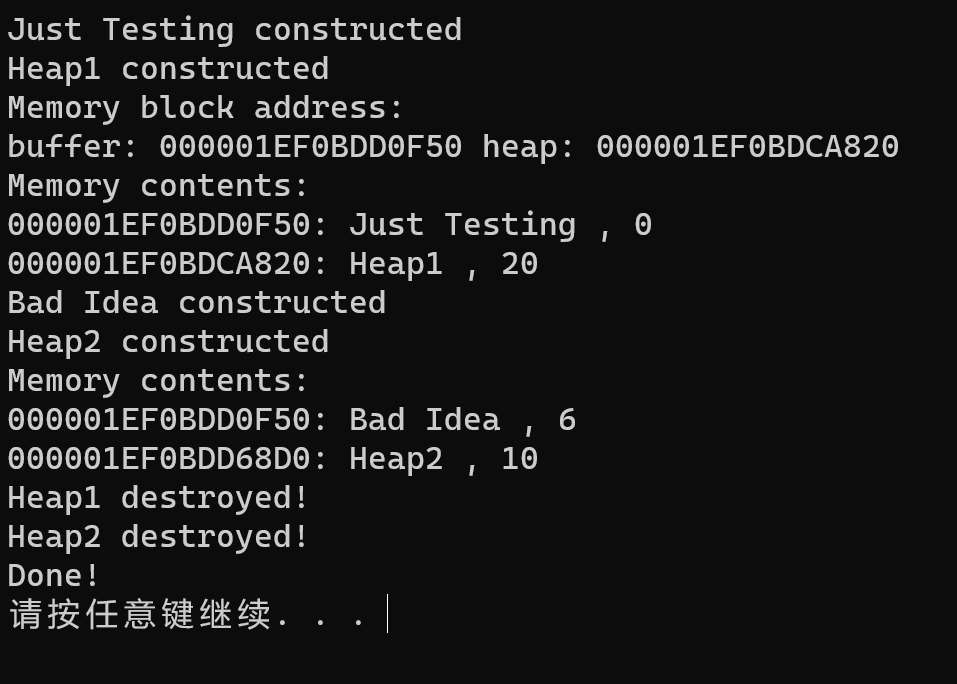
我们一步一步分析以下结果:
1.Justing Testing constructed是由定位new在内存缓冲区上构造第一个对象时,调用构造函数引发的结果;
2.Heap1 constructed是常规new自己在堆上申请空间,构造第二个对象调用构造函数引发的结果
3.Memory block address:是main函数中第一个cout的结果
4.buffer:00D117C0 heap:00D0EE98是main函数中第一个cout的结果,表明第一个JustTesting对象与第二个JustTesting对象不在同一内存区域
5.Memory contents:是main函数中第二个cout的结果
6.00D117C0: Just Testing , 0:第三个cout及pc1->Show()的结果,可以发现pc1就是内存缓冲区的地址
7.00D0EE98: Heap1 , 20:第四个cout及pc2->Show()的结果
8.Bad Idea constructed:是由定位new在内存缓冲区上构造第三个对象时,调用构造函数引发的结果;
9.Heap2 constructed:是常规new自己在堆上申请空间,构造第四个对象调用构造函数引发的结果
10.Memory contents:第五个cout的结果
11.00D117C0: Bad Idea , 6:第六个cout及pc3->Show()的结果,可以发现pc3就是内存缓冲区的地址
12.00D0F078: Heap2 , 10:第七个cout及pc4->Show()的结果
13.Heap1 destroyed!:delete pc2引发第二个对象的析构函数引发
14.Heap2 destroyed!:delete pc4引发第四个对象的析构函数引发
15.Done!:最后一个cout的结果
由例程代码及结果分析可以看出:
1.使用定位new创建的对象的地址与内存缓冲区地址一致,说明定位new并没有申请新空间,而构造函数的调用说明定位new的确调用了构造函数。
2.在使用delete回收空间时,可以发现并未回收pc1与pc3,其原因在于pc1与pc3指向的对象位于内存缓冲区,该空间并不是定位new申请,而是常规new申请的,因此我们需要delete[]回收内存缓冲区,而不是delete pc1与delete pc3
3.pc1与pc3一致,说明第一个对象被第三个覆盖!显然,如果类动态地为其成员分配内存,这将引发问题!,所以,当我们使用定位new创建对象必须自己保证不会覆盖任何不想丢失的数据!,就这个例程而言,避免覆盖,最简单的做法如下:
pc1 = new (buffer) JustTesting;
pc3 = new (buffer + sizeof(JustTesting)) JustTesting("Better Idea!",6);
4.delete[] buffer并未引发对象的析构!,虽然对象1及3的空间被回收,但对象1与3并未析构!这一点将时刻提醒我们使用定位new需要自己显式调用析构函数,完成对象的析构!,但该析构并不能通过delete pc1或delete pc3实现!(因为delete与定位new不能配合使用!,否则会引发运行时错误!),只能通过显式析构,如下:
pc3->~JustTesting();
pc1->~JustTesting();
使用定位new创建对象,显式调用析构函数是必须的,这是析构函数必须被显式调用的少数情形之一!,另有一点!!!析构函数的调用必须与对象的构造顺序相反!切记!!!
新增的两个默认成员函数
在类和对象的博客中,已经介绍了类的6个默认成员函数:
- 构造函数
- 析构函数
- 拷贝构造函数
- 拷贝赋值重载
- 取地址重载
- const 取地址重载
在C++11中由新增了两个默认成员函数:
- 移动构造函数
- 移动赋值运算符重载
这两个函数相信大家都不陌生,上面介绍右值引用中也介绍了这两个函数,右值引用和这两个函数结合使用才能够彰显出右值引用的实际意义。需要注意的几点是:
如果没有实现移动构造函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个。那么编译器会自动生成一个默认移动构造。
默认生成的移动构造函数,对于内置类型成员会按照字节序进行浅拷贝,自定义类型成员,则需要看这个成员是否实现移动构造,如果实现了就调用移动构造,没有实现就调用拷贝构造。
如果没有实现移动赋值重载函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个,那么编译器会自动生成一个默认移动赋值。
默认生成的移动构造函数,对于内置类型成员会按照字节序进行浅拷贝,自定义类型成员,则需要看这个成员是否实现移动赋值,如果实现了就调用移动赋值,没有实现就调用拷贝赋值。
可以看出,想让编译器自动生成移动构造和移动赋值要求还是很严格的。
默认生成的移动构造和移动赋值会做什么
- 默认生成的移动构造函数:对于内置类型的成员会完成值拷贝(浅拷贝),对于自定义类型的成员,如果该成员实现了移动构造就调用它的移动构造,否则就调用它的拷贝构造。
- 默认生成的移动赋值重载函数:对于内置类型的成员会完成值拷贝(浅拷贝),对于自定义类型的成员,如果该成员实现了移动赋值就调用它的移动赋值,否则就调用它的拷贝赋值。
实例演示: 为了方便观察,这里我使用自己简单模拟实现的string来进行演示。拿析构函数做演示,有析构函数和没有析构函数,两种情况下,使用右值对象构造一个对象和使用右值对象给一个对象赋值,观察会调用哪个函数
namespace XM
{
class string
{
public:
//构造函数
string(const char* str = "")
{
_size = strlen(str); //初始时,字符串大小设置为字符串长度
_capacity = _size; //初始时,字符串容量设置为字符串长度
_str = new char[_capacity + 1]; //为存储字符串开辟空间(多开一个用于存放'\0')
strcpy(_str, str); //将C字符串拷贝到已开好的空间
}
//交换两个对象的数据
void swap(string& s)
{
//调用库里的swap
::swap(_str, s._str); //交换两个对象的C字符串
::swap(_size, s._size); //交换两个对象的大小
::swap(_capacity, s._capacity); //交换两个对象的容量
}
//拷贝构造函数(现代写法)
string(const string& s)
:_str(nullptr)
, _size(0)
, _capacity(0)
{
cout << "string(const string& s) -- 深拷贝" << endl;
string tmp(s._str); //调用构造函数,构造出一个C字符串为s._str的对象
swap(tmp); //交换这两个对象
}
//移动构造
string(string&& s)
:_str(nullptr)
, _size(0)
, _capacity(0)
{
cout << "string(string&& s) -- 移动构造" << endl;
swap(s);
}
//拷贝赋值函数(现代写法)
string& operator=(const string& s)
{
cout << "string& operator=(const string& s) -- 深拷贝" << endl;
string tmp(s); //用s拷贝构造出对象tmp
swap(tmp); //交换这两个对象
return *this; //返回左值(支持连续赋值)
}
//移动赋值
string& operator=(string&& s)
{
cout << "string& operator=(string&& s) -- 移动赋值" << endl;
swap(s);
return *this;
}
//析构函数
~string()
{
//delete[] _str; //释放_str指向的空间
_str = nullptr; //及时置空,防止非法访问
_size = 0; //大小置0
_capacity = 0; //容量置0
}
private:
char* _str;
size_t _size;
size_t _capacity;
};
}
简单的Person类,Person类中的成员name的类型就是我们模拟实现的string类
class Person
{
public:
//构造函数
Person(const char* name = "", int age = 0)
:_name(name)
, _age(age)
{}
//拷贝构造函数
Person(const Person& p)
:_name(p._name)
, _age(p._age)
{}
//拷贝赋值函数
Person& operator=(const Person& p)
{
if (this != &p)
{
_name = p._name;
_age = p._age;
}
return *this;
}
//析构函数
~Person()
{}
private:
XM::string _name; //姓名
int _age; //年龄
};
Person类当中没有实现移动构造和移动赋值,但拷贝构造、拷贝赋值和析构函数Person类都实现了,因此Person类中不会生成默认的移动构造和移动赋值
int main()
{
Person s1("张三", 100);
Person s2 = std::move(s1); //想要调用Person默认生成的移动构造
return 0;
}
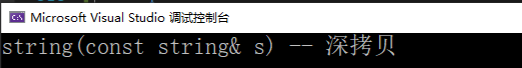
- 上述代码中用一个右值去构造s2对象,但由于Person类没有生成默认的移动构造函数,因此这里会调用Person的拷贝构造函数(拷贝构造既能接收左值也能接收右值),这时在Person的拷贝构造函数中就会调用string的拷贝构造函数对name成员进行深拷贝。
- 如果要让Person类生成默认的移动构造函数,就必须将Person类中的拷贝构造、拷贝赋值和析构函数全部注释掉,这时用右值去构造s2对象时就会调用Person默认生成的移动构造函数。
- Person默认生成的移动构造,对于内置类型成员age会进行值拷贝,而对于自定义类型成员name,因为我们的string类实现了移动构造函数,因此它会调用string的移动构造函数进行资源的转移。
- 而如果我们将string类当中的移动构造函数注释掉,那么Person默认生成的移动构造函数,就会调用string类中的拷贝构造函数对name成员进行深拷贝。
验证Person类中默认生成的移动赋值函数
int main()
{
Person s1("张三", 100);
Person s2;
s2 = std::move(s1); //想要调用Person默认生成的移动赋值
return 0;
}

两个关键字——default和delete
C++11可以让你更好的控制要使用的默认函数。你可以强制生成某个默认成员函数,也可以禁止生成某个默认成员函数,分别用的的关键字是——default和delete
class Person
{
public:
Person(const char* name = "", int age = 0)
:_name(name)
,_age(age)
{}
Person(Person&& p) = default;// 强制生成默认的
Person& operator=(Person&& p) = default;
Person(Person& p) = delete;// 强制删除默认的
~Person()
{}
private:
Simulation::string _name;
int _age;
};
可变参数模板
C++11的新特性可变参数模板能够让您创建可以接受可变参数的函数模板和类模板,相比C++98/03,类模版和函数模版中只能含固定数量的模版参数,可变模版参数无疑是一个巨大的改进。
语法规范如下:
template <class ...Args>
void fun(Args ...args)
{}
说明几点:
- Args和args前面有省略号,所以它们是可变参数,带省略号的参数称为“参数包”,它里面包含了0到N(N>=0)个模版参数
- Args是一个模板参数包,args是一个函数形参参数包
如何获取参数包中的每一个参数呢?下面介绍两种方法:
我们无法直接获取参数包中的每个参数,只能通过展开参数包的方式来获取,这是使用可变参数模板的一个主要特点,也是最大的难点
- 方法一:递归函数展开参数包
①递归展开参数包的方式如下
- 给函数模板增加一个模板参数,这样就可以从接收到的参数包中分离出一个参数出来。
- 在函数模板中递归调用该函数模板,调用时传入剩下的参数包。
- 如此递归下去,每次分离出参数包中的一个参数,直到参数包中的所有参数都被取出来。
②打印调用函数时传入的各个参数,这样编写函数模板
template<class T, class ...Args>
void ShowList(T value, Args ...args)
{
cout << value << " ";
// 递归调用ShowList,当参数包中的参数个数为0时,调用上面无参的ShowList
// args中第一个参数作为value传参,参数包中剩下的参数作为新的参数包传参
ShowList(args...);
}
int main()
{
ShowList(1, 'A');
ShowList(3, 'a', 1.23);
ShowList('a', 4, 'B', 3.3);
return 0;
}
/*
输出结果:
1 A
3 a 1.23
a 4 B 3.3
*/
③现在面临的问题是,如何终止函数的递归调用
- 我们可以在刚才的基础上,编写只有一个带参的递归终止函数,该函数的函数名与展开函数的函数名相同,构成函数重载
- 当递归调用ShowList函数模板时,如果传入的参数包中参数的个数为1,那么就会匹配到这一个参数递归终止函数,这样就结束了递归。
- 但是需要注意,这里的递归调用函数需要写成函数模板,因为我们并不知道最后一个参数是什么类型的。
//递归终止函数
//可以认为是重载版本,当参数包里面只有一个参数的时候就会调用这个重载函数
template<class T>
void ShowList(const T& val)
{
cout << val << endl << endl;
}
//展开函数
template<class T, class ...Args>
void ShowList(T value, Args ...args)
{
cout << value << " ";
// 递归调用ShowList,当参数包中的参数个数为0时,调用上面无参的ShowList
// args中第一个参数作为value传参,参数包中剩下的参数作为新的参数包传参
ShowList(args...);
}
int main()
{
ShowList(1, 'A');
ShowList(3, 'a', 1.23);
ShowList('a', 4, 'B', 3.3);
return 0;
}
/*
输出结果:
1 A
3 a 1.23
a 4 B 3.3
*/
- 方法二:逗号表达式展开参数包
①通过列表获取参数包中的参数
- 1.数组可以通过列表进行初始化
int a[] = {1,2,3,4};
- 2.如果参数包中各个参数的类型都是整型,那么也可以把这个参数包放到列表当中初始化这个整型数组,此时参数包中参数就放到数组中了(如果一个参数包中都是一个的类型,那么可以使用该参数包对数组进行列表初始化,参数包会展开,然后对数组进行初始化。)
//展开函数
template<class ...Args>
void ShowList(Args... args)
{
int arr[] = { args... }; //列表初始化
//打印参数包中的各个参数
for (auto e : arr)
{
cout << e << " ";
}
cout << endl;
}
- 4.C++并不像Python这样的语言,C++规定一个容器中存储的数据类型必须是相同的,因此如果这样写的话,那么调用ShowList函数时传入的参数只能是整型的,并且还不能传入0个参数,因为数组的大小不能为0,因此我们还需要在此基础上借助逗号表达式来展开参数包。
②通过逗号表达式展开参数包
- 逗号表达式会从左到右依次计算各个表达式,并且将最后一个表达式的值作为返回值进行返回。
- 将逗号表达式的最后一个表达式设置为一个整型值,确保逗号表达式返回的是一个整型值。
- 将处理参数包中参数的动作封装成一个函数,将该函数的调用作为逗号表达式的第一个表达式。
1.在执行逗号表达式时就会先调用处理函数处理对应的参数,然后再将逗号表达式中的最后一个整型值作为返回值来初始化整型数组。
- 我们这里要做的就是打印参数包中的各个参数,因此处理函数当中要做的就是将传入的参数进行打印即可。
- 可变参数的省略号需要加在逗号表达式外面,表示需要将逗号表达式展开,如果将省略号加在args的后面,那么参数包将会被展开后全部传入PrintArg函数,代码中的{ (PrintArg(args), 0)... }将会展开成{ (PrintArg(arg1), 0), (PrintArg(arg2), 0), (PrintArg(arg3), 0), ... }。
template<class T>
void PrintArg(T value)
{
cout << value << " ";
}
template<class ...Args>
void ShowList(Args ...args)
{
int arr[] = { (PrintArg(args), 0)... };
cout << endl;
}
2.这时调用ShowList函数时就可以传入多个不同类型的参数了,但调用时仍然不能传入0个参数,因为数组的大小不能为0,如果想要支持传入0个参数,也可以写一个无参的ShowList函数。
//支持无参调用
void ShowList()
{
cout << endl;
}
template<class T>
void PrintArg(T value)
{
cout << value << " ";
}
template<class ...Args>
void ShowList(Args ...args)
{
int arr[] = { (PrintArg(args), 0)... };//列表初始化+逗号表达式
cout << endl;
}
emplace系列接口


上面的&&是万能引用,实参是左值,参数包的这个形参就是左值引用,实参是右值,参数包的这个形参就是右值引用
以list容器的emplace_back和push_back为例
- 调用push_back函数插入元素时,可以传入左值对象或者右值对象,也可以使用列表进行初始化。
- 调用emplace_back函数插入元素时,也可以传入左值对象或者右值对象,但不可以使用列表进行初始化。
- 除此之外,emplace系列接口最大的特点就是,插入元素时可以传入用于构造元素的参数包,emplace_back可以支持可变参数包,然后调用定位new,使用参数包对空间进行初始化。
int main()
{
list<pair<int, string>> mylist;
pair<int, string> kv(1, "A");
mylist.push_back(kv); //传左值
mylist.push_back(pair<int, string>(1, "A")); //传右值
mylist.push_back({ 1, "A" }); //列表初始化
mylist.emplace_back(kv); //传左值
mylist.emplace_back(pair<int, string>(1, "A")); //传右值
mylist.emplace_back(1, "A"); //传参数包
return 0;
}
emplace系列接口的工作流程
- 先通过空间配置器为新结点获取一块内存空间,注意这里只会开辟空间,不会自动调用构造函数对这块空间进行初始化。
- 然后调用allocator_traits::construct函数对这块空间进行初始化,调用该函数时会传入这块空间的地址和用户传入的参数(需要经过完美转发)。
- 在allocator_traits::construct函数中会使用定位new表达式,显示调用构造函数对这块空间进行初始化,调用构造函数时会传入用户传入的参数(需要经过完美转发)。
- 将初始化好的新结点插入到对应的数据结构当中,比如list容器就是将新结点插入到底层的双链表中。
emplace系列接口的意义
(1)由于emplace系列接口的可变模板参数的类型都是万能引用,因此既可以接收左值对象,也可以接收右值对象,还可以接收参数包
- 如果调用emplace系列接口时传入的是左值对象,那么首先需要先在此之前调用构造函数实例化出一个左值对象,最终在使用定位new表达式调用构造函数对空间进行初始化时,会匹配到拷贝构造函数。
- 如果调用emplace系列接口时传入的是右值对象,那么就需要在此之前调用构造函数实例化出一个右值对象,最终在使用定位new表达式调用构造函数对空间进行初始化时,就会匹配到移动构造函数。
- 如果调用emplace系列接口时传入的是参数包,那就可以直接调用函数进行插入,并且最终在使用定位new表达式调用构造函数对空间进行初始化时,匹配到的是构造函数。
(2)小结
- 传入左值对象,需要调用构造函数+拷贝构造函数。
- 传入右值对象,需要调用构造函数+移动构造函数。
- 传入参数包,只需要调用构造函数。
(3)emplace接口的意义
- emplace系列接口最大的特点就是支持传入参数包,用这些参数包直接构造出对象,这样就能减少一次拷贝,这就是为什么有人说emplace系列接口更高效的原因。
- 但emplace系列接口并不是在所有场景下都比原有的插入接口高效,如果传入的是左值对象或右值对象,那么emplace系列接口的效率其实和原有的插入接口的效率是一样的。
- emplace系列接口真正高效的情况是传入参数包的时候,直接通过参数包构造出对象,避免了中途的一次拷贝。
C++11(列表初始化+变量类型推导+类型转换+左右值概念、引用+完美转发和万能应用+定位new+可变参数模板+emplace接口)的更多相关文章
- C++11 列表初始化
在我们实际编程中,我们经常会碰到变量初始化的问题,对于不同的变量初始化的手段多种多样,比如说对于一个数组我们可以使用 int arr[] = {1,2,3}的方式初始化,又比如对于一个简单的结构体: ...
- 018 01 Android 零基础入门 01 Java基础语法 02 Java常量与变量 12 数据类型转换的基本概念
018 01 Android 零基础入门 01 Java基础语法 02 Java常量与变量 12 数据类型转换的基本概念 本文知识点:Java中的数据类型转换 类型转换 类型转换分类 2类,分别是: ...
- c++11——列表初始化
1. 使用列表初始化 在c++98/03中,对象的初始化方法有很多种,例如 int ar[3] = {1,2,3}; int arr[] = {1,2,3}; //普通数组 struct A{ int ...
- 初窥C++11:自己主动类型推导与类型获取
auto 话说C语言还处于K&R时代,也有auto a = 1;的写法.中文译过来叫自己主动变量.跟c++11的不同.C语言的auto a = 1;相当与 auto int a = 1;语句. ...
- JS基础-变量类型和类型转换
JS 变量类型 JS中有 6 种原始值,分别是: boolean number string undefined symbol null 引用类型: 对象 数组 函数 JS中使用typeof能得到哪些 ...
- PHP判断变量类型和类型转换的三种方式
前言: PHP 在变量定义中不需要(不支持)明确的类型定义.变量类型是根据使用该变量的上下文所决定的.所以,在面对页码跳转.数值计算等严格的格式需求时,就要对变量进行类型转换. 举例如下: $foo ...
- C++:只用初始化列表初始化变量的几种情况
1.类成员函数中const变量的初始化(也就是第一点) 有几个容易混淆的地方: (1)const 的变量只能通过构造函数的初始化列表进行初始化:(貌似在C++11中可以正常编译) (2)static ...
- 变量类型,-数据类型(值类型,引用类型)uint 不有存负数,int,可以存负数,
俩种命名方法 1.Pascal 命名法,第一个字母大写其它字母小写Userid 2.Camel命名法,所有单第一方写大写,其它小写,骆峰命名法,userId 程序中元素的命名规范项目名:公司名.项目名 ...
- 《Effective Modern C++》翻译--条款2: 理解auto自己主动类型推导
条款2: 理解auto自己主动类型推导 假设你已经读过条款1关于模板类型推导的内容,那么你差点儿已经知道了关于auto类型推导的所有. 至于为什么auto类型推导就是模板类型推导仅仅有一个地方感到好奇 ...
- Effective Modern C++翻译(2)-条款1:明白模板类型推导
第一章 类型推导 C++98有一套单一的类型推导的规则:用来推导函数模板,C++11轻微的修改了这些规则并且增加了两个,一个用于auto,一个用于decltype,接着C++14扩展了auto和dec ...
随机推荐
- Upscayl,免费开源的 AI 图像增强软件
有的时候我们找遍了全网却难以找到一张模糊图片的原图,这时候我们想如果能够一键将图片变成高清的就好了.其实这正是计算机视觉的一大研究反向--图形增强,通过AI计算将模糊的图片增强,将几百kb的低像素图片 ...
- C++运算符重载(简单易懂)
转载:https://www.cnblogs.com/liuchenxu123/p/12538623.html 运算符重载,就是对已有的运算符重新进行定义,赋予其另一种功能,以适应不同的数据类型. 你 ...
- ByPass
WebShell-ByPass php一句话木马 <?php eval($_REQUEST['a']]);?> 拦截进行替换 替换eval() assert() 替换$_REQUEST[' ...
- LeetCode------移动零(5)【数组】
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/move-zeroes 1.题目 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末 ...
- 二十八、Helm
使用Helm3管理复杂应用的部署 认识Helm 为什么有helm? Helm是什么? kubernetes的包管理器,"可以将Helm看作Linux系统下的apt-get/yum" ...
- iphoneApp Fidder设置
使用iphone 打开fidder 按照如上配置 安装完毕 然后访问计算机地址- 比如我的计算机ip地址是 192.168.2.10那么我需要在我的safari浏览器中输入192.168.2.10:8 ...
- 【深入浅出 Yarn 架构与实现】2-1 Yarn 基础库概述
了解 Yarn 基础库是后面阅读 Yarn 源码的基础,本节对 Yarn 基础库做总体的介绍.并对其中使用的第三方库 Protocol Buffers 和 Avro 是什么.怎么用做简要的介绍. 一. ...
- PHP 代码解一元二次方程
1 function php_getSolutionOVQE($a,$b,$c=0){ 2 $x1=0; 3 $x2=0; 4 $detal=0; 5 if($a==0 && $b== ...
- Go语言核心36讲19
你好,我是郝林,今天我们继续分享go语句执行规则的内容. 在上一篇文章中,我们讲到了goroutine在操作系统的并发编程体系,以及在Go语言并发编程模型中的地位和作用等一系列内容,今天我们继续来聊一 ...
- 重新认识下JVM级别的本地缓存框架Guava Cache——优秀从何而来
大家好,又见面了. 本文是笔者作为掘金技术社区签约作者的身份输出的缓存专栏系列内容,将会通过系列专题,讲清楚缓存的方方面面.如果感兴趣,欢迎关注以获取后续更新. 不知不觉,这已经是<深入理解缓存 ...