【BOOK】数据存储—文件存储(TXT、JSON、CSV)
数据存储
文本文件—TXT、JSON、CSV
关系型数据库—MySQL、SQLite、Oracle、SQL Server、DB2
非关系型数据库—MongoDB、Redis
文件打开 open(),第二个参数设置文件打开方式
※ r:只读,文件指针在文件开头
※ rb:二进制只读,文件指针在文件开头
※ r+:读写方式,文件指针在文件开头
※ w:写入,如果文件已存在,则覆盖;若文件不存在,则新建
※ wb:二进制写入,如果文件已存在,则覆盖;若文件不存在,则新建
※ w+:读写,如果文件已存在,则覆盖;若文件不存在,则新建
※ a:追加方式,如果文件已存在,将内容新增再最后;若文件不存在,则新建写入
※ ab:二进制追加方式,如果文件已存在,将内容新增再最后;若文件不存在,则新建写入
※ a+:读写追加,如果文件已存在,将内容新增再最后;若文件不存在,则新建写入
一、TXT文本存储
实例:爬取知乎--热门专题页面
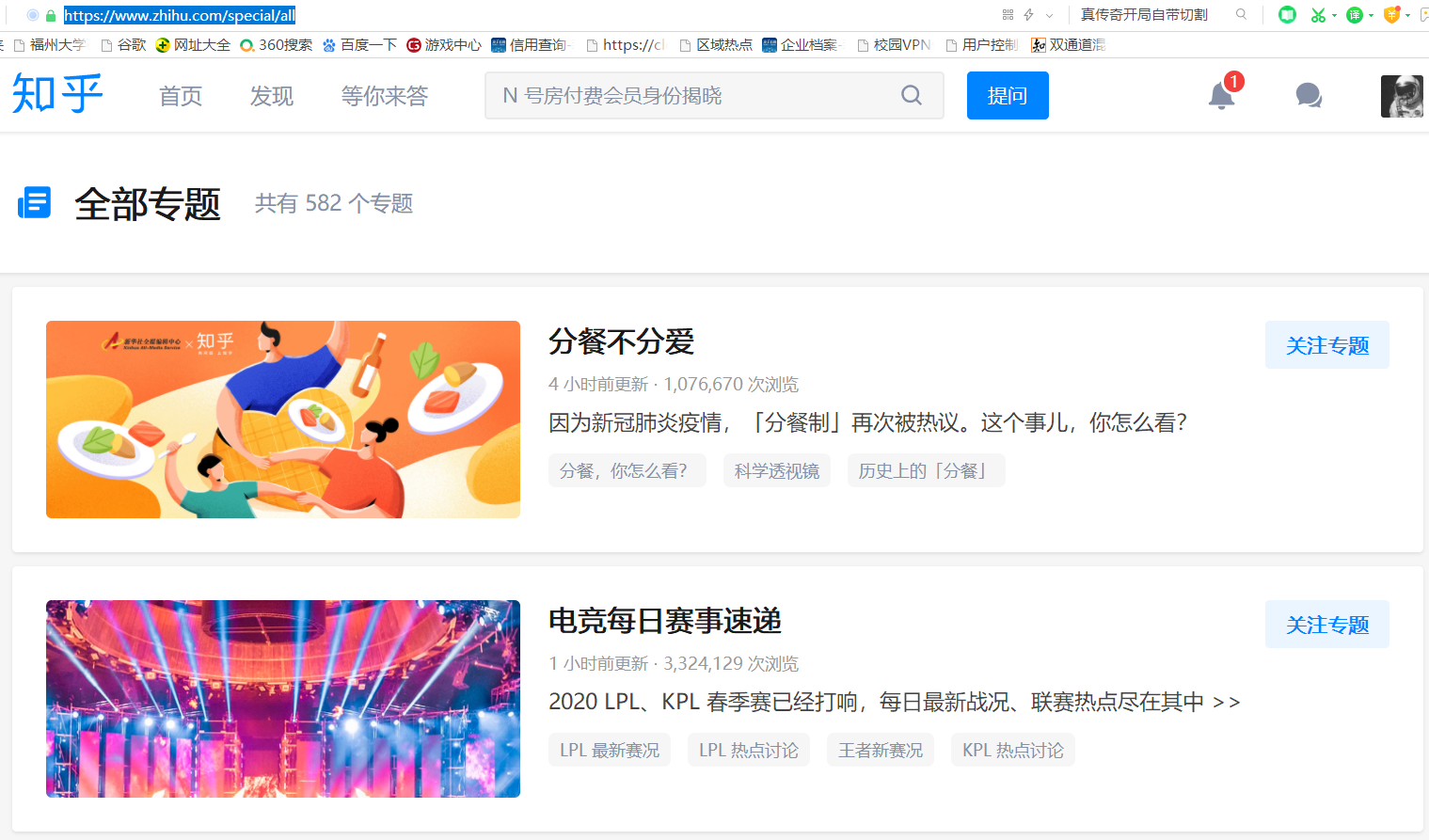
## 爬取知乎热门专题
import requests
from pyquery import PyQuery as pq url = 'https://www.zhihu.com/special/all' try:
headers = {
'cookie': 'miid=421313831459957575; _samesite_flag_=true; cookie2=1cd225d128b8f915414ca1d56e99dd42; t=5b4306b92a563cc96ffb9e39037350b4; _tb_token_=587ae39b3e1b8; cna=DmpEFqOo1zMCAdpqkRZ0xo79; unb=643110845; uc3=nk2=30mP%2BxQ%3D&id2=VWsrWqauorhP&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&vt3=F8dBxdz4jRii0h%2Bs3pw%3D; csg=f54462ca; lgc=%5Cu5939zhi; cookie17=VWsrWqauorhP; dnk=%5Cu5939zhi; skt=906cb7efa634723b; existShop=MTU4MjI5Mjk4NQ%3D%3D; uc4=id4=0%40V8o%2FAfalcPHRLJCDGtb%2Fdp1gVzM%3D&nk4=0%403b07vSmMRqc2uEhDugyrBg%3D%3D; publishItemObj=Ng%3D%3D; tracknick=%5Cu5939zhi; _cc_=UIHiLt3xSw%3D%3D; tg=0; _l_g_=Ug%3D%3D; sg=i54; _nk_=%5Cu5939zhi; cookie1=AnPBkeBRJ7RXH1lHWy9jEkFiHPof0dsM6sKE2hraCKY%3D; enc=gTfBHQmDAXUW0nTwDZWT%2BXlVfPmDqVQdFSKTby%2BoWsATGTG4yqih%2FJwqG7BvGfl1N%2Bc1FeptT%2BWNjgCnd3%2FX9Q%3D%3D; __guid=154677242.2334981537288746500.1582292984682.7253; mt=ci=25_1; v=0; thw=cn; hng=CN%7Czh-CN%7CCNY%7C156; JSESSIONID=6A1CD727C830F88997EE7A11C795F670; uc1=cookie14=UoTUOLFGTPNtWQ%3D%3D&lng=zh_CN&cookie16=URm48syIJ1yk0MX2J7mAAEhTuw%3D%3D&existShop=false&cookie21=URm48syIYn73&tag=8&cookie15=URm48syIIVrSKA%3D%3D&pas=0; monitor_count=4; isg=BGRk121i5pgW-RJU8ZZzF7W5NWJW_Yhn96AFLn6F6C_yKQXzpgzI9-XL6IExt8C_; l=cBjv7QE7QsWpTNssBOCiNQhfh1_t7IRf6uSJcRmMi_5p21T_QV7OoWj0Ve96DjWhTFLB4IFj7TyTxeW_JsuKHdGJ4AadZ',
'user-agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
html = requests.get(url, headers=headers, timeout=30).text
except:
print('爬取失败!') doc = pq(html)
## pyquery进行页面解析,class属性用 . 匹配
## 调用items()得到一个生成器,for in 进行遍历
items = doc('.SpecialListCard.SpecialListPage-specialCard').items()
for item in items:
title = item.find('.SpecialListCard-title').text()
intro = item.find('.SpecialListCard-intro').text()
with open('special.txt', 'a', encoding='utf-8') as file:
file.write('\n'.join([title,intro]) + '\n')
sections = item.find('.SpecialListCard-sections').items()
for section in sections:
special = section.find('a').text()
file.write('\n'.join([special]))
file.write('\n' + '='*50 + '\n')
file.close()
运行结果:
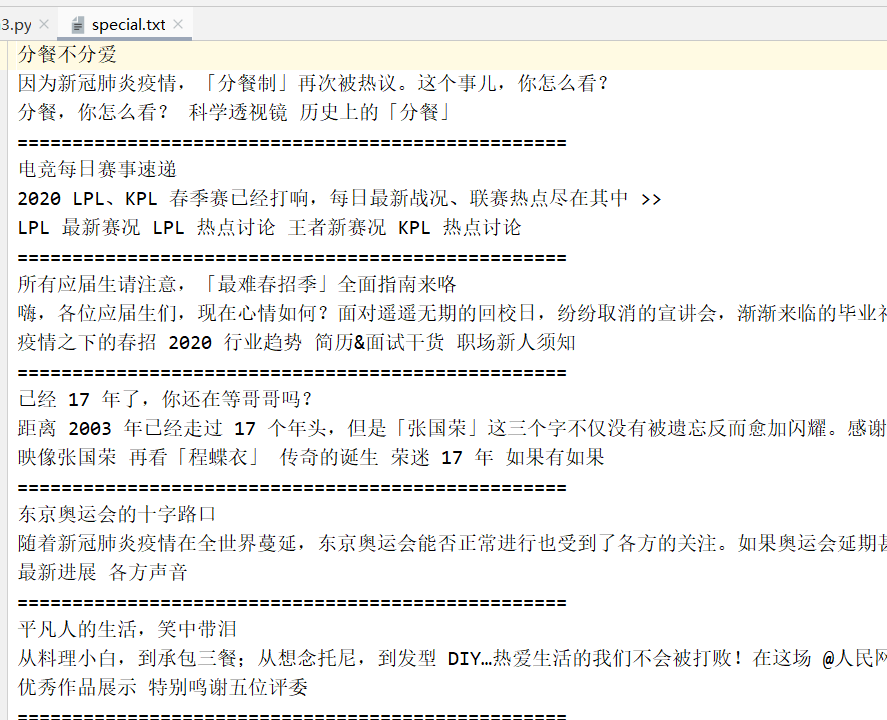
二、JSON文件存储
JavaScript Object Notation—JavaScript对象标记
1、用对象和数组表示数据,结构化程度高
※对象—键值对 {key : value}
※数组—[‘a’, ‘b’, ’c’]
—> [{key 1: value1}, {key2 : value2}]
2、JSON库实现JSON文件的读写操作
※读取JSON
loads() 将字符串类型转换成JSON对象
import json ## JSON对象中的数据需要双引号 "" 包围
str = '''
[{"name":"呱呱", "gender":"男", "age":"5"},
{"name":"嘎嘎", "gender":"女", "age":"22"}
]
'''
## loads() 将字符串类型转换成JSON对象
data = json.loads(str)
print(type(data)) ## <class 'list'>,字符串类型转换成列表类型
print(data[0]['name'])
print(data[0].get('name'))
## 读取JSON文件
import json with open('data.json', 'r') as file:
str = file.read()
data = json.loads(str)
print(data)
※输出JSON
dumps() 将JSON对象换成字符串
import json ## JSON对象中的数据需要双引号 "" 包围
data = [{"name":"呱呱", "gender":"男", "age":"5"},
{"name":"嘎嘎", "gender":"女", "age":"22"}
] ## dumps() 将JSON对象换成字符串
with open('data.json', 'w', encoding='utf-8') as file:
## indent=2 保存的JSON对象自带缩进
## ensure_ascii=False,JSON文件中包含中文
file.write(json.dumps(data, indent=2, ensure_ascii=False))
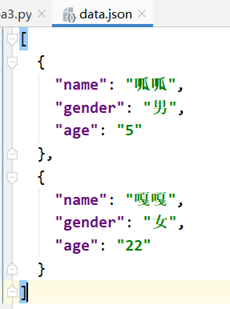
三、CSV文件存储【!!可以用excel打开!!】
Comma-Separated Values—逗号分隔值/字符分隔值
纯文本形式存储表格数据
1、 写入
import csv ## newline='' ,保证每行之间没有空格
with open('data.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
## writerow() 每行写入
writer.writerow(['id', 'name', 'age'])
writer.writerow(['1001', '呱呱', '20'])
writer.writerow(['1002', '啦啦', '36'])
writer.writerow(['1003', '哈哈', '14'])
## writerows() 写入多行,效果同上
writer.writerows([['1004', '卡卡', '6'],['1005', '哇哇', '65']])
import csv ## 字典写入
with open('data1.csv', 'w', newline='') as csvfile:
fieldnames = ['id', 'name', 'age'] ## 给csv表的表头赋值
## DictWriter初始化一个字典写入对象
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'id':'1001', 'name':'呱呱', 'age':20})
writer.writerow({'id': '1002', 'name': '啦啦', 'age': 36})
writer.writerow({'id': '1003', 'name': '哈哈', 'age': 14})
## 追加数据
with open('data1.csv', 'a', newline='') as csvfile:
fieldnames = ['id', 'name', 'age']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writerow({'id':'1004', 'name':'八八', 'age':20})
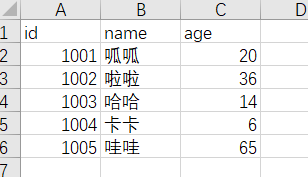
2、 读取
import csv
with open('data.csv', 'r') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
print(row)

【实例】知乎--热门专题--存储到excel
## 爬取知乎热门专题
import requests
from pyquery import PyQuery as pq
import csv url = 'https://www.zhihu.com/special/all' try:
headers = {
'cookie': 'miid=421313831459957575; _samesite_flag_=true; cookie2=1cd225d128b8f915414ca1d56e99dd42; t=5b4306b92a563cc96ffb9e39037350b4; _tb_token_=587ae39b3e1b8; cna=DmpEFqOo1zMCAdpqkRZ0xo79; unb=643110845; uc3=nk2=30mP%2BxQ%3D&id2=VWsrWqauorhP&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&vt3=F8dBxdz4jRii0h%2Bs3pw%3D; csg=f54462ca; lgc=%5Cu5939zhi; cookie17=VWsrWqauorhP; dnk=%5Cu5939zhi; skt=906cb7efa634723b; existShop=MTU4MjI5Mjk4NQ%3D%3D; uc4=id4=0%40V8o%2FAfalcPHRLJCDGtb%2Fdp1gVzM%3D&nk4=0%403b07vSmMRqc2uEhDugyrBg%3D%3D; publishItemObj=Ng%3D%3D; tracknick=%5Cu5939zhi; _cc_=UIHiLt3xSw%3D%3D; tg=0; _l_g_=Ug%3D%3D; sg=i54; _nk_=%5Cu5939zhi; cookie1=AnPBkeBRJ7RXH1lHWy9jEkFiHPof0dsM6sKE2hraCKY%3D; enc=gTfBHQmDAXUW0nTwDZWT%2BXlVfPmDqVQdFSKTby%2BoWsATGTG4yqih%2FJwqG7BvGfl1N%2Bc1FeptT%2BWNjgCnd3%2FX9Q%3D%3D; __guid=154677242.2334981537288746500.1582292984682.7253; mt=ci=25_1; v=0; thw=cn; hng=CN%7Czh-CN%7CCNY%7C156; JSESSIONID=6A1CD727C830F88997EE7A11C795F670; uc1=cookie14=UoTUOLFGTPNtWQ%3D%3D&lng=zh_CN&cookie16=URm48syIJ1yk0MX2J7mAAEhTuw%3D%3D&existShop=false&cookie21=URm48syIYn73&tag=8&cookie15=URm48syIIVrSKA%3D%3D&pas=0; monitor_count=4; isg=BGRk121i5pgW-RJU8ZZzF7W5NWJW_Yhn96AFLn6F6C_yKQXzpgzI9-XL6IExt8C_; l=cBjv7QE7QsWpTNssBOCiNQhfh1_t7IRf6uSJcRmMi_5p21T_QV7OoWj0Ve96DjWhTFLB4IFj7TyTxeW_JsuKHdGJ4AadZ',
'user-agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
html = requests.get(url, headers=headers, timeout=30).text
except:
print('爬取失败!') doc = pq(html)
## pyquery进行页面解析,class属性用 . 匹配
## 调用items()得到一个生成器,for in 进行遍历 with open('data1.csv', 'a', newline='') as csvfile:
header = ['专题标题', '说明', '子专题']
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
items = doc('.SpecialListCard.SpecialListPage-specialCard').items()
for item in items:
title = item.find('.SpecialListCard-title').text()
intro = item.find('.SpecialListCard-intro').text()
sections = item.find('.SpecialListCard-sections').items()
for section in sections:
special = section.find('a').text()
writer.writerow({'专题标题': title, '说明': intro, '子专题': special})
csvfile.close()
运行结果:

【BOOK】数据存储—文件存储(TXT、JSON、CSV)的更多相关文章
- File存储 - 文件存储
博客地址 http://www.cnblogs.com/mmyblogs/p/6107472.html(转载请保留) 文件存储 文件存储是 Android 中最基本的一种数据存储方式,它不对存储的内容 ...
- Python常用的数据文件存储的4种格式(txt/json/csv/excel)及操作Excel相关的第三方库(xlrd/xlwt/pandas/openpyxl)(2021最新版)
序言:保存数据的方式各种各样,最简单的方式是直接保存为文本文件,如TXT.JSON.CSV等,除此之外Excel也是现在比较流行的存储格式,通过这篇文章你也将掌握通过一些第三方库(xlrd/xlwt/ ...
- 主流数据文件类型(.dat/.txt/.json/.csv)导入到python
手写很累,复制的同学请点赞犒劳下在下哦 ^_^ 一.对于.CSV类型的数据 它们的数据导入都很简单 且看下面一顿操作: 我平时一般是读取整个文件,直接这样就可以了: import pandas as ...
- 保存数据到文件的模块(json,pickle,shelve,configparser,xml)_python
一.各模块的主要功能区别 json模块:将数据对象从内存中完成序列化存储,但是不能对函数和类进行序列化,写入的格式是明文. (与其他大多语言交互的类型) pickle模块:将数据对象从内存中完成序列 ...
- 预读(读取文件前几行)文件(txt,dat,csv等)程序
需求: txt.dat.csv文件很大,需要花很长的时间打开, 但实际上我们只需要查看文件的前几行,查看数据的内容和格式 exe & code : https://github.com/co ...
- solr6.6 导入 pdf/doc/txt/json/csv/xml文件
文本主要介绍通过solr界面dataimport工具导入文件,包括pdf.doc.txt .json.csv.xml等文件,看索引结果有什么不同.其实关键是managed-schema.solrcon ...
- 爬虫文件存储:txt文档,json文件,csv文件
5.1 文件存储 文件存储形式可以是多种多样的,比如可以保存成 TXT 纯文本形式,也可以保存为 Json 格式.CSV 格式等,本节我们来了解下文本文件的存储方式. 5.1.1 TXT文本存储 将数 ...
- python爬虫系列之数据的存储(二):csv库的使用
上一篇我们讲了怎么用 json格式保存数据,这一篇我们来看看如何用 csv模块进行数据读写. 一.csv简介 CSV (Comma Separated Values),即逗号分隔值(也称字符分隔值,因 ...
- IOS开发--数据持久化篇之文件存储(一)
前言:个人觉得开发人员最大的悲哀莫过于懂得使用却不明白其中的原理.在代码之前我觉得还是有必要简单阐述下相关的一些知识点. 因为文章或深或浅总有适合的人群.若有朋友发现了其中不正确的观点还望多多指出,不 ...
- 写文件的工具类,输出有格式的文件(txt、json/csv)
import java.io.BufferedWriter; import java.io.File; import java.io.FileOutputStream; import java.io. ...
随机推荐
- NSFW.js 前端使用教程
引用js + 下载模型 先看文档 https://github.com/infinitered/nsfwjs 非常好,一点也看不懂.总之,先引js,不知道去哪里下载js就上jsdelivr搜一搜 按顺 ...
- WOW事件大全(翻译对照)
魔兽世界(WOW)插件开发事件大全 ACHIEVEMENT_EARNED 取得的成就 ACHIEVEMENT_SEARCH_UPDATED 已更新成就搜索 ACTIONBAR_HIDEGRID 动作条 ...
- 剑指 Offer II 回溯法
086. 分割回文子字符串 用substr枚举 因为是连续的 不是放与不放的问题 class Solution { public: vector<vector<string>> ...
- System.Diagnostics.Process.Start(); 用法详解
来源:https://news.68idc.cn/buildlang/ask/20150104156981.html 实例代码:http://www.cppcns.com/ruanjian/cshar ...
- tidb 杂记
tidb_biuil_stats_concurrency 执行analyze table时会分成多个小任务,可以同时执行的任务数量.tidb_distsql_scan_concurrency 在执行分 ...
- 【C和指针】6.指针
1.指针变量的内容 int a=112, b=-1; float c=3.14; int *d=&a; int *e=&c; (1) 变量d和e被声明为指针,并用其他变量的地址予以初始 ...
- (转载)史上最详细的docker学习手册
原文链接:https://my.oschina.net/u/1388595/blog/5078146 一.docker入门 1.docker的安装及入门示例 环境准备:docker需要安装在cento ...
- excel 巧用功能
1. 分类汇总 数据-->分类汇总--> 解决问题:解决了我按字段分类并分页打印的问题,例如几十个村数据,要按村分页打印相关数据这时不能把村分别复制粘贴到一个一个工作薄,太麻烦了. 处理方 ...
- jmeter取样器之KafkaProducerSampler(往kafka插入数据)
项目背景 性能测试场景中有一个业务场景的数据抽取策略是直接使用kafka队列,该场景需要准备的测试数据是kafka队列里的数据,故需要实现插入数据到kafka队列,且需要实现控制每分钟插入多少条数据. ...
- VS2017创建Linux项目实现远程GDB调试
vs2017新增linux for C++的模块,尝试安装了一下环境. 首先,安装VS2017,安装时注意选择以下模块: 安装完成后,需要配置Linux服务端的部分,我的配置过程如下: 第一步,安装V ...