【Redis场景拓展】秒杀问题-全局唯一ID生成策略
全局唯一ID
为什么要使用全局唯一ID:
当用户抢购时,就会生成订单并保存到订单表中,而订单表如果使用数据库自增ID就存在一些问题:
- 受单表数据量的限制
- id的规律性太明显
场景分析一:如果我们的id具有太明显的规则,用户或者说商业对手很容易猜测出来我们的一些敏感信息,比如商城在一天时间内,卖出了多少单,这明显不合适。
场景分析二:随着我们商城规模越来越大,mysql的单表的容量不宜超过500W,数据量过大之后,我们要进行拆库拆表,但拆分表了之后,他们从逻辑上讲他们是同一张表,所以他们的id是不能一样的, 于是乎我们需要保证id的唯一性。
场景分析三:如果全部使用数据库自增长ID,那么多张表都会出现相同的ID,不满足业务需求。
在分布式系统下全局唯一ID需要满足的特点:
- 唯一性
- 递增性
- 安全性
- 高可用(服务稳定)
- 高性能(生成速度够快)
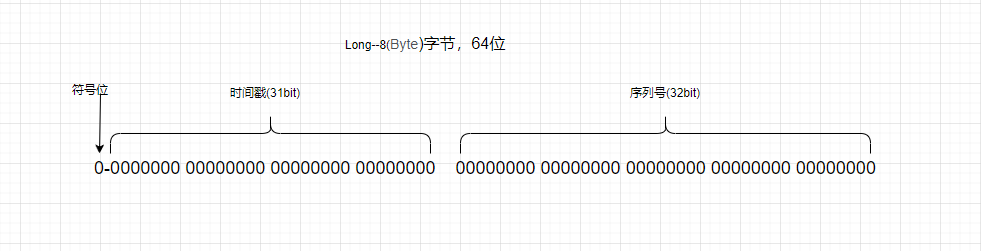
为了提高数据库性能,这里采用Java中的数值类型(Long--8(Byte)字节,64位),
- ID的组成部分:符号位:1bit,永远为0
- 时间戳:31bit,以秒为单位,可以使用69年
- 序列号:32bit,秒内的计数器,支持每秒产生2^32个不同ID
类雪花算法开发
我们的生成策略是基于redis的自增长,及序列号部分,在实现的时候需要传入不同的前缀(即不同业务不同序列号)
我们开始实现时间戳位数,先设置一个基准值,即某一时间的秒数,使用的时候用当前时间秒数-基准时间=所得秒数即时间戳;
基准值计算:这里我是用2023/1/1 0:0:0;秒数为:1672531200
public static void main(String[] args) {
LocalDateTime time = LocalDateTime.of(2023, 1, 1, 0, 0, 0);
//设置时区
long l = time.toEpochSecond(ZoneOffset.UTC);
System.out.println(l);
}
开始生成时间戳:获得当前时间的秒数-基准值(BEGIN_TIMESTAMP=1672531200)
LocalDateTime dateTime = LocalDateTime.now();
//秒数设置时区
long nowSecond = dateTime.toEpochSecond(ZoneOffset.UTC);
long timestamp = nowSecond - BEGIN_TIMESTAMP;
然后生成序列号,采用Redis的自增操作实现。keyPrefix业务Key(传入的)
long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix);
这一行代码的使用问题是,同一个业务使用的同一个key,但是redis的自增上限为2^64,总有时候会超过32位,所以最好是让其同一业务也要有不同的key值,这里我们可以加上当前时间。
//获取当日日期,精确到天
String date = dateTime.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
//自增长上限2^64
long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);
这样做的好处是:
- 在redis中缓存是分层的,方便查看,也方便统计每天、每月的订单量或者其他数据等
- 不会超过Redis的自增长的值,安全性提高
最后将时间戳和序列号进行拼接即可,位运算。COUNT_BITS=32
timestamp << COUNT_BITS | count;
首先将时间戳左移32位,低处补零,然后进行或运算(遇1得1),这样实现整个的全局唯一ID。
测试
在同一个业务中使用全局唯一ID生成。
/**
* 测试全局唯一ID生成器
* @throws InterruptedException
*/
@Test
public void testIdWorker() throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(300);
ExecutorService executorService = Executors.newFixedThreadPool(300);
Runnable task = ()->{
for (int i = 0; i < 100; i++) {
long id = redisIdWorker.nextId("order");
System.out.println("id:"+id);
}
//计数-1
countDownLatch.countDown();
};
long begin = System.currentTimeMillis();
for (int i = 0; i < 300; i++) {
executorService.submit(task);
}
//等待子线程结束
countDownLatch.await();
long endTime = System.currentTimeMillis();
System.out.println("time= "+(endTime-begin));
}
time= 2608ms=2.68s,生成数量:30000
取两个相近的十进制转为二进制对比:
id : 148285184708444304
0010 0000 1110 1101 0000 1001 0111 0000 0000 0000 0000 0000 0000 1001 0000
id : 148285184708444305
0010 0000 1110 1101 0000 1001 0111 0000 0000 0000 0000 0000 0000 1001 0001
短码生成策略
仅支持很小的调用量,用于生成活动配置类编号,保证全局唯一
import java.util.Calendar;
import java.util.Random;
/**
* @author xbhog
* @describe:短码生成策略,仅支持很小的调用量,用于生成活动配置类编号,保证全局唯一
* @date 2022/9/18
*/
@Slf4j
@Component
public class ShortCode implements IIdGenerator {
@Override
public synchronized long nextId() {
Calendar calendar = Calendar.getInstance();
int year = calendar.get(Calendar.YEAR);
int week = calendar.get(Calendar.WEEK_OF_YEAR);
int day = calendar.get(Calendar.DAY_OF_WEEK);
int hour = calendar.get(Calendar.HOUR_OF_DAY);
log.info("年:{},周:{},日:{},小时:{}",year, week,day,hour);
//打乱顺序:2020年为准 + 小时 + 周期 + 日 + 三位随机数
StringBuilder idStr = new StringBuilder();
idStr.append(year-2020);
idStr.append(hour);
idStr.append(String.format("%02d",week));
idStr.append(day);
idStr.append(String.format("%03d",new Random().nextInt(1000)));
log.info("查看拼接之后的值:{}",idStr);
return Long.parseLong(idStr.toString());
}
public static void main(String[] args) {
long l = new ShortCode().nextId();
System.out.println(l);
}
}
日志记录:
14:40:22.336 [main] INFO ShortCode - 年:2023,周:5,日:7,小时:14
14:40:22.341 [main] INFO ShortCode - 查看拼接之后的值:314057012
314057012
【Redis场景拓展】秒杀问题-全局唯一ID生成策略的更多相关文章
- 分布式全局唯一ID生成策略
为什么分布式系统需要用到ID生成系统 在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识.如在美团点评的金融.支付.餐饮.酒店.猫眼电影等产品的系统中,数据日渐增长,对数据库的分库分表后需要有 ...
- 常见分布式全局唯一ID生成策略
全局唯一的 ID 几乎是所有系统都会遇到的刚需.这个 id 在搜索, 存储数据, 加快检索速度 等等很多方面都有着重要的意义.工业上有多种策略来获取这个全局唯一的id,针对常见的几种场景,我在这里进行 ...
- 分布式全局唯一ID生成策略
一.背景 分布式系统中我们会对一些数据量大的业务进行分拆,如:用户表,订单表.因为数据量巨大一张表无法承接,就会对其进行分库分表. 但一旦涉及到分库分表,就会引申出分布式系统中唯一主键ID的生成问题. ...
- 关于全局唯一ID生成方法
引:最近业务开发过程中需要涉及到全局唯一ID生成.之前零零总总的收集过一些相关资料,特此整理以便后用 本博客已经迁移至:http://cenalulu.github.io/ 本篇博文已经迁移,阅读全文 ...
- (4.24)【mysql、sql server】分布式全局唯一ID生成方案
参考:分布式全局唯一ID生成方案:https://blog.csdn.net/linzhiqiang0316/article/details/80425437 分表生成唯一ID方案 sql serve ...
- 分布式系统全局唯一ID生成
一 什么是分布式系统唯一ID 在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识. 如在金融.电商.支付.等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息, ...
- 常见分布式唯一ID生成策略
方法一: 用数据库的 auto_increment 来生成 优点: 此方法使用数据库原有的功能,所以相对简单 能够保证唯一性 能够保证递增性 id 之间的步长是固定且可自定义的 缺点: 可用性难以保证 ...
- mysql全局唯一ID生成方案(二)
MySQL数据表结构中,一般情况下,都会定义一个具有‘AUTO_INCREMENT’扩展属性的‘ID’字段,以确保数据表的每一条记录都可以用这个ID唯一确定: 随着数据的不断扩张,为了提高数据库查询性 ...
- 十位用户唯一ID生成策略
新浪微博和twitter 等系统都有一窜数字ID来标示一个唯一的用户,这篇文章就是记录如何实现这种唯一数字ID 原理:使用MYSQL 自增ID 拼接任意字符..然后使用进制转换打乱规则 一般来说实现唯 ...
- Snowflake 全局唯一Id 生成
/// <summary> /// From: https://github.com/twitter/snowflake /// An object that generates IDs. ...
随机推荐
- String常用API
String常用API 1. 获取字符串长度 int length = str.length(); 2. 根据索引,返回字符串中对应的字符 char c = str.chaeAt(length-1); ...
- 如何查看mysql数据目录位置
mysql> show global variables like "%datadir%"; +---------------+-----------------+ | Va ...
- 2022春每日一题:Day 12
题目:[SDOI2006]线性方程组 显然,高斯消元模板题 代码: #include <cstdio> #include <cstdlib> #include <cstr ...
- Go语言核心36讲08
在上一篇文章,我们一直都在围绕着可重名变量,也就是不同代码块中的重名变量,进行了讨论. 还记得吗?最后我强调,如果可重名变量的类型不同,那么就需要引起我们的特别关注了,它们之间可能会存在"屏 ...
- Java—猜数字
package cn.day03.demo01; import java.util.Random; import java.util.Scanner; public class RandomGame ...
- mysql不需要密码,乱输入密码就能进去。。。。解决
为什么MySQL 不用输入用户名和密码也能访问 今天后天连接数据库时密码写错了,却发现后台能够拿到数据库中的数据,又故意把用户名和密码都写错,结果还是可以.这就意味着任何一个人只要登入服务器,就可以轻 ...
- vue cli2安装
安装nodejs npm install -g npm npm自动更新到最新版本 node -v或者npm -v 查看nodejs是否安装成功 1 2 配置淘宝镜像 npm config set ...
- chrome设置socket5代理
利用自带的参数命令打破一个死循环. chrome可执行文件 --show-app-list --proxy-server="SOCKS5://127.0.0.1:1080"
- GitHub 开源了多款字体「GitHub 热点速览 v.22.48」
本期 News 快读有 GitHub 官方大动作一下子开源了两款字体,同样大动作的还有 OpenAI 发布的对话模型 ChatGPT,引燃了一波人机对话. 项目这块,也许会成为新的 Web 开发生产力 ...
- VSCode解决Python中空格和制表符混用报错
Python对缩进的要求非常严格,缩进控制不正确可能会造成代码执行不正确甚至报错. 遇到报错"TabError: inconsistent use of tabs and spaces in ...