【爬虫+数据清洗+可视化分析】舆情分析哔哩哔哩"狂飙"的评论
一、背景介绍
您好,我是@马哥python说,一枚10年程序猿。
2023开年这段时间,《狂飙》这部热播剧引发全民追剧,不仅全员演技在线,更是符合反黑主旋律,因此创下多个收视率记录!
基于此热门事件,我用python抓取了B站上千条评论,并进行可视化舆情分析,下面详细讲解代码。
二、爬虫代码
2.1 展示爬取结果
首先,看下部分爬取数据:
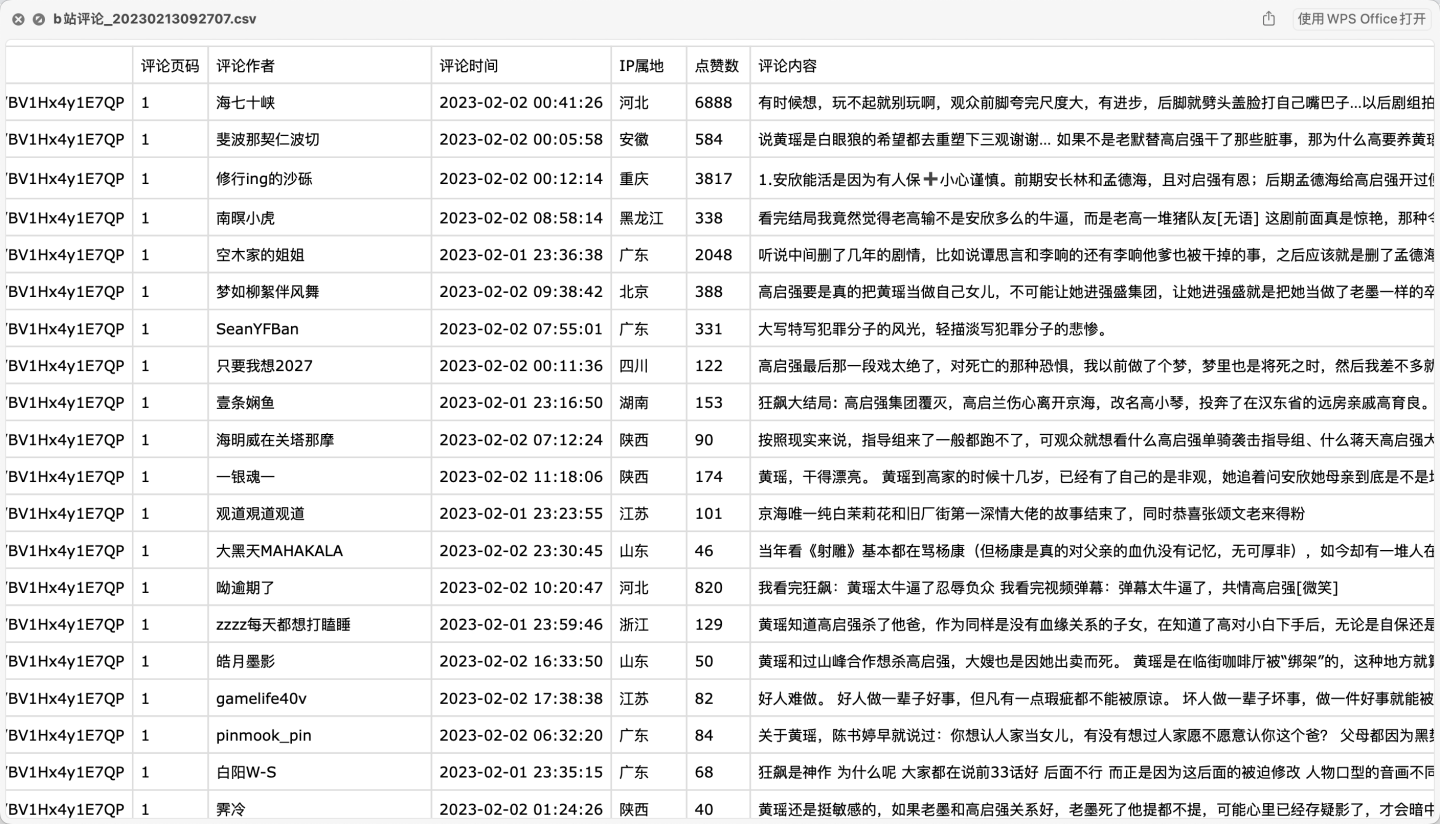
爬取字段含:视频链接、评论页码、评论作者、评论时间、IP属地、点赞数、评论内容。
2.2 爬虫代码讲解
导入需要用到的库:
import requests # 发送请求
import pandas as pd # 保存csv文件
import os # 判断文件是否存在
import time
from time import sleep # 设置等待,防止反爬
import random # 生成随机数
定义一个请求头:
# 请求头
headers = {
'authority': 'api.bilibili.com',
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
# 需定期更换cookie,否则location爬不到
'cookie': "需换成自己的cookie值",
'origin': 'https://www.bilibili.com',
'referer': 'https://www.bilibili.com/video/BV1FG4y1Z7po/?spm_id_from=333.337.search-card.all.click&vd_source=69a50ad969074af9e79ad13b34b1a548',
'sec-ch-ua': '"Chromium";v="106", "Microsoft Edge";v="106", "Not;A=Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.47'
}
请求头中的cookie是个很关键的参数,如果不设置cookie,会导致数据残缺或无法爬取到数据。
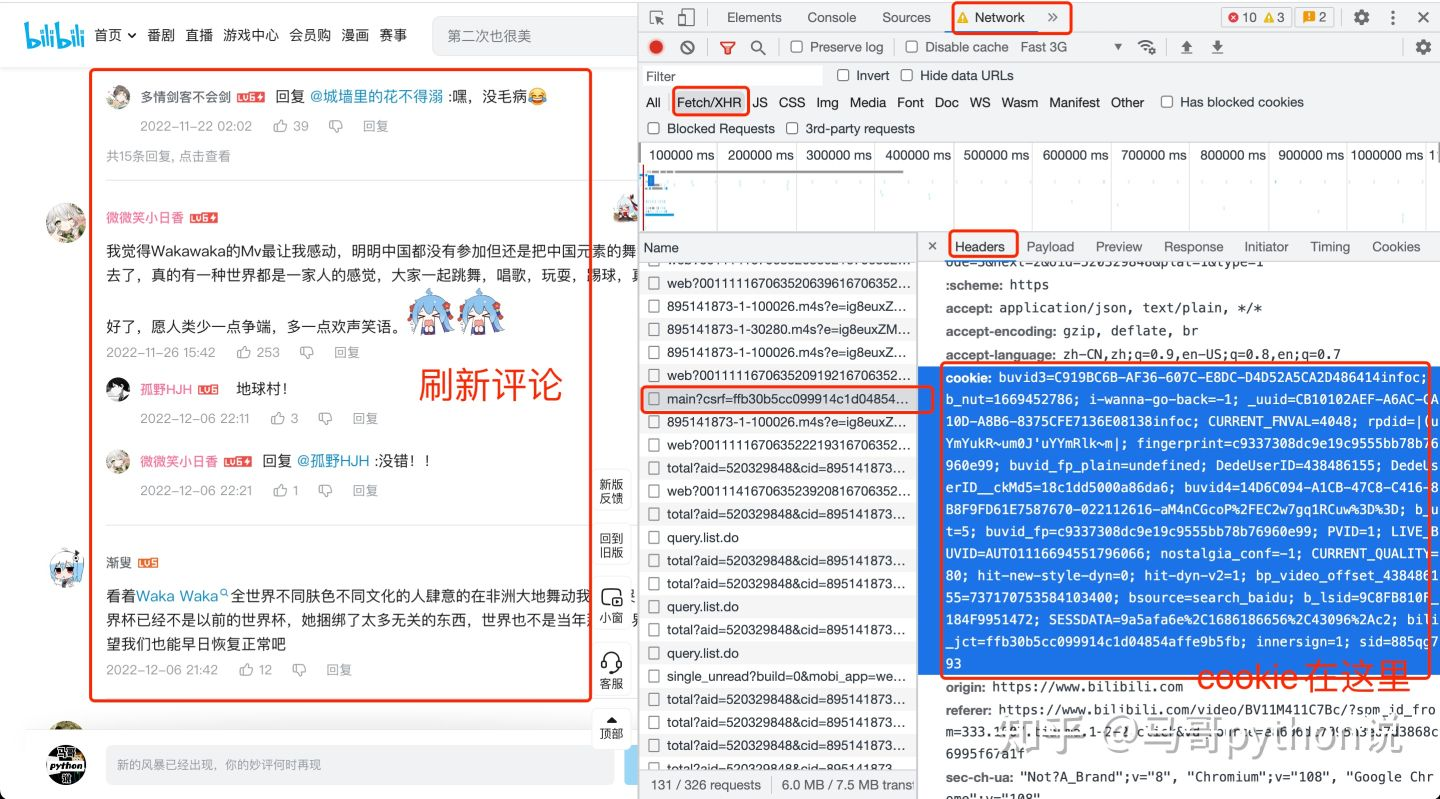
那么cookie如何获取呢?打开开发者模式,见下图:
由于评论时间是个十位数:
所以开发一个函数用于转换时间格式:
def trans_date(v_timestamp):
"""10位时间戳转换为时间字符串"""
timeArray = time.localtime(v_timestamp)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return otherStyleTime
向B站发送请求:
response = requests.get(url, headers=headers, ) # 发送请求
接收到返回数据了,怎么解析数据呢?看一下json数据结构:
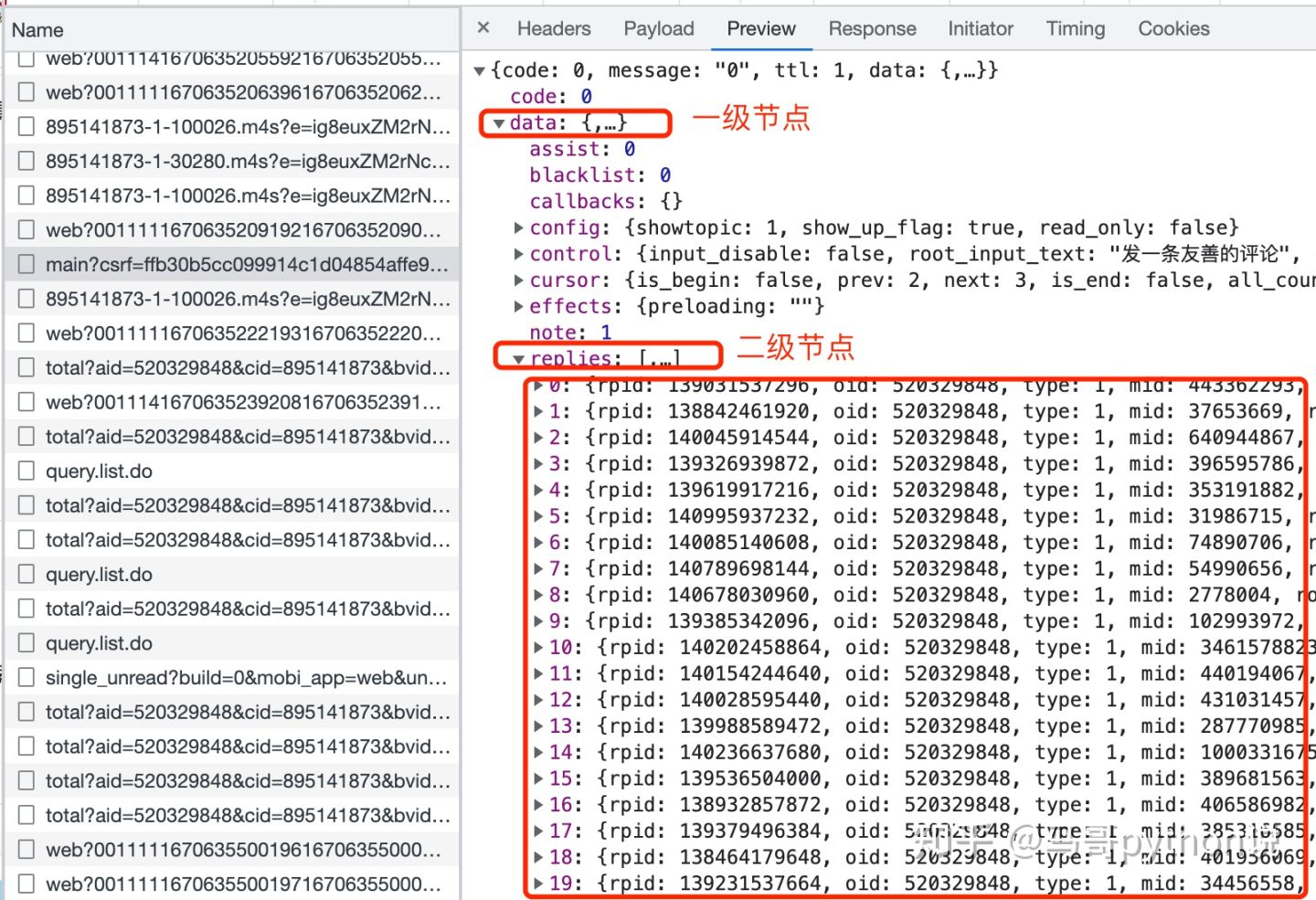
0-19个评论,都存放在replies下面,replies又在data下面,所以,这样解析数据:
data_list = response.json()['data']['replies'] # 解析评论数据
这样,data_list里面就是存储的每条评论数据了。
接下来吗,就是解析出每条评论里的各个字段了。
我们以评论内容这个字段为例:
comment_list = [] # 评论内容空列表
# 循环爬取每一条评论数据
for a in data_list:
# 评论内容
comment = a['content']['message']
comment_list.append(comment)
其他字段同理,不再赘述。
最后,把这些列表数据保存到DataFrame里面,再to_csv保存到csv文件,持久化存储完成:
# 把列表拼装为DataFrame数据
df = pd.DataFrame({
'视频链接': 'https://www.bilibili.com/video/' + v_bid,
'评论页码': (i + 1),
'评论作者': user_list,
'评论时间': time_list,
'IP属地': location_list,
'点赞数': like_list,
'评论内容': comment_list,
})
# 把评论数据保存到csv文件
df.to_csv(outfile, mode='a+', encoding='utf_8_sig', index=False, header=header)
注意,加上encoding='utf_8_sig',否则可能会产生乱码问题!
下面,是主函数循环爬取部分代码:(支持多个视频的循环爬取)
# 随便找了几个"狂飙"相关的视频ID
bid_list = ['BV1Hx4y1E7QP', 'BV1Ev4y1r737', 'BV19x4y177ni']
# 评论最大爬取页(每页20条评论)
max_page = 50
# 循环爬取这几个视频的评论
for bid in bid_list:
# 输出文件名
outfile = 'b站评论_{}.csv'.format(now)
# 转换aid
aid = bv2av(bid=bid)
# 爬取评论
get_comment(v_aid=aid, v_bid=bid)
三、可视化代码
为了方便看效果,以下代码采用jupyter notebook进行演示。
3.1 读取数据
用read_csv读取刚才爬取的B站评论数据:
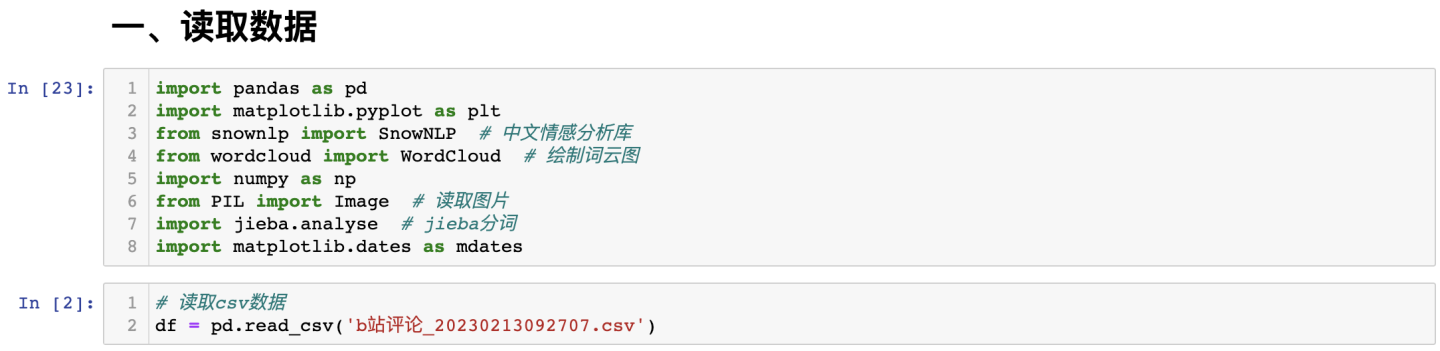
查看前3行及数据形状:
3.2 数据清洗
处理空值及重复值:
3.3 可视化
3.3.1 IP属地分析-柱形图
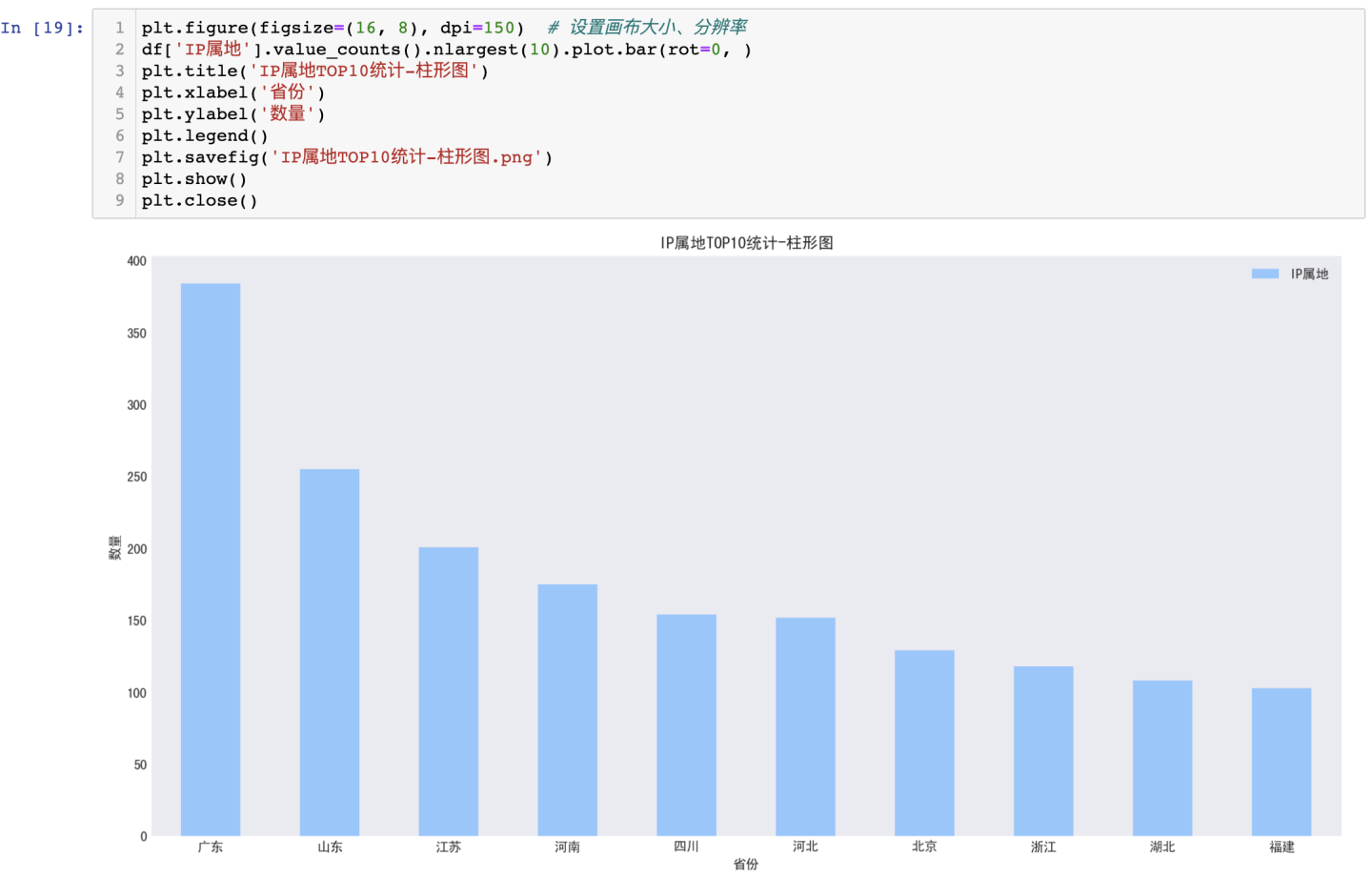
可得结论:TOP10地区中,评论里关注度最高为广东、山东、江苏等地区,其中,广东省的关注度最高。
3.3.2 评论时间分析-折线图
分析出评论时间的分布情况:
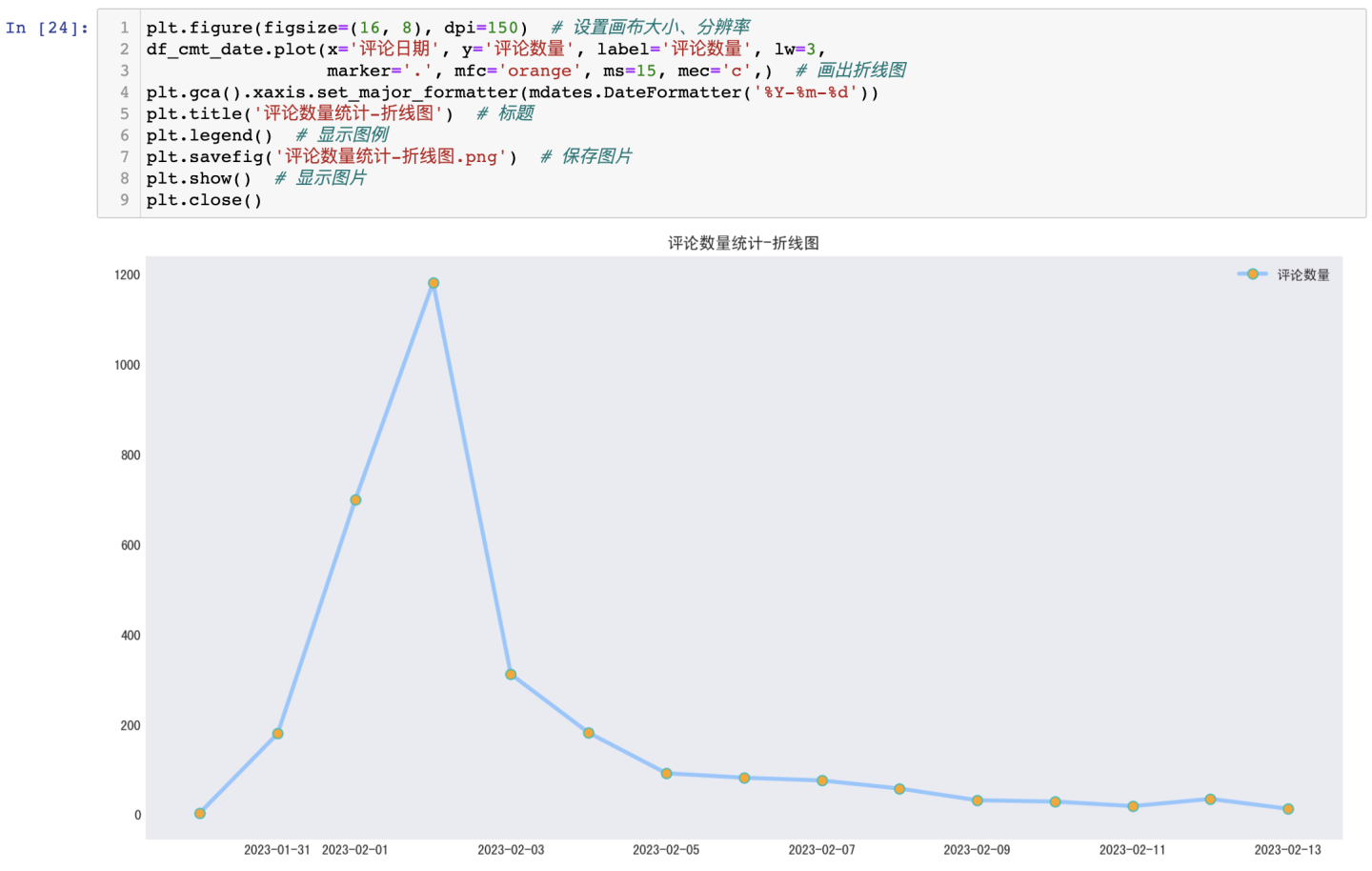
可得结论:关于"狂飙"这个话题,在抓取到的数据范围内,2月2日的评论数据量最大,网友讨论最热烈,达到了将近1200的数量峰值。
3.3.3 点赞数分布-直方图
由于点赞数大部分为0或个位数情况,个别点赞数到达成千上万,直方图展示效果不佳,因此,仅提取点赞数<30的数据绘制直方图。
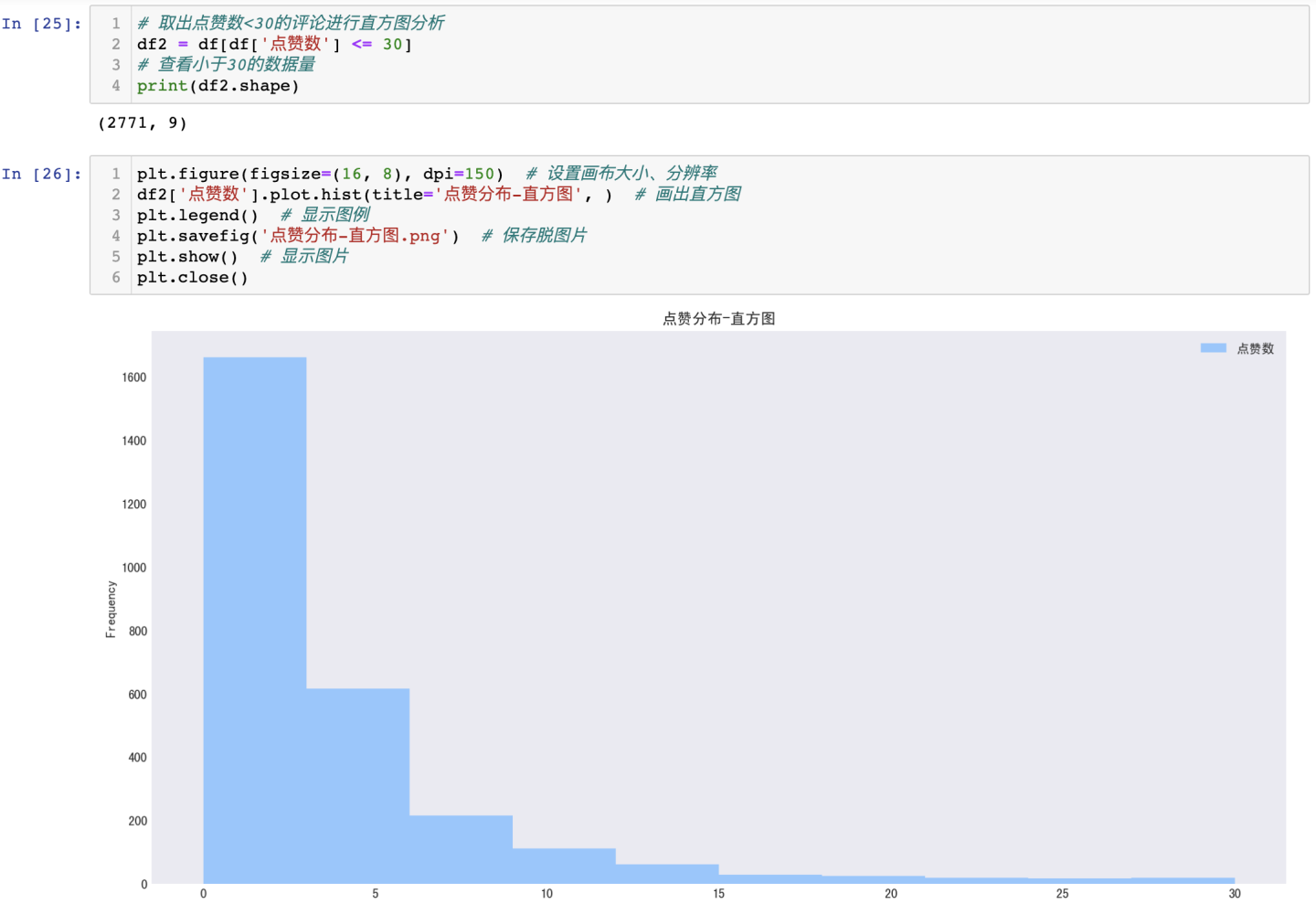
可得结论:从直方图的分布来看,点赞数在0-3个的评论占据大多数,很少点赞数达到了上千上万的情况。证明网友对狂飙这部作品的态度分布比较均匀,没有出现态度非常聚集的评论内容。
3.3.4 评论内容-情感分布饼图
针对中文评论数据,采用snownlp开发情感判定函数:
情感分布饼图,如下:
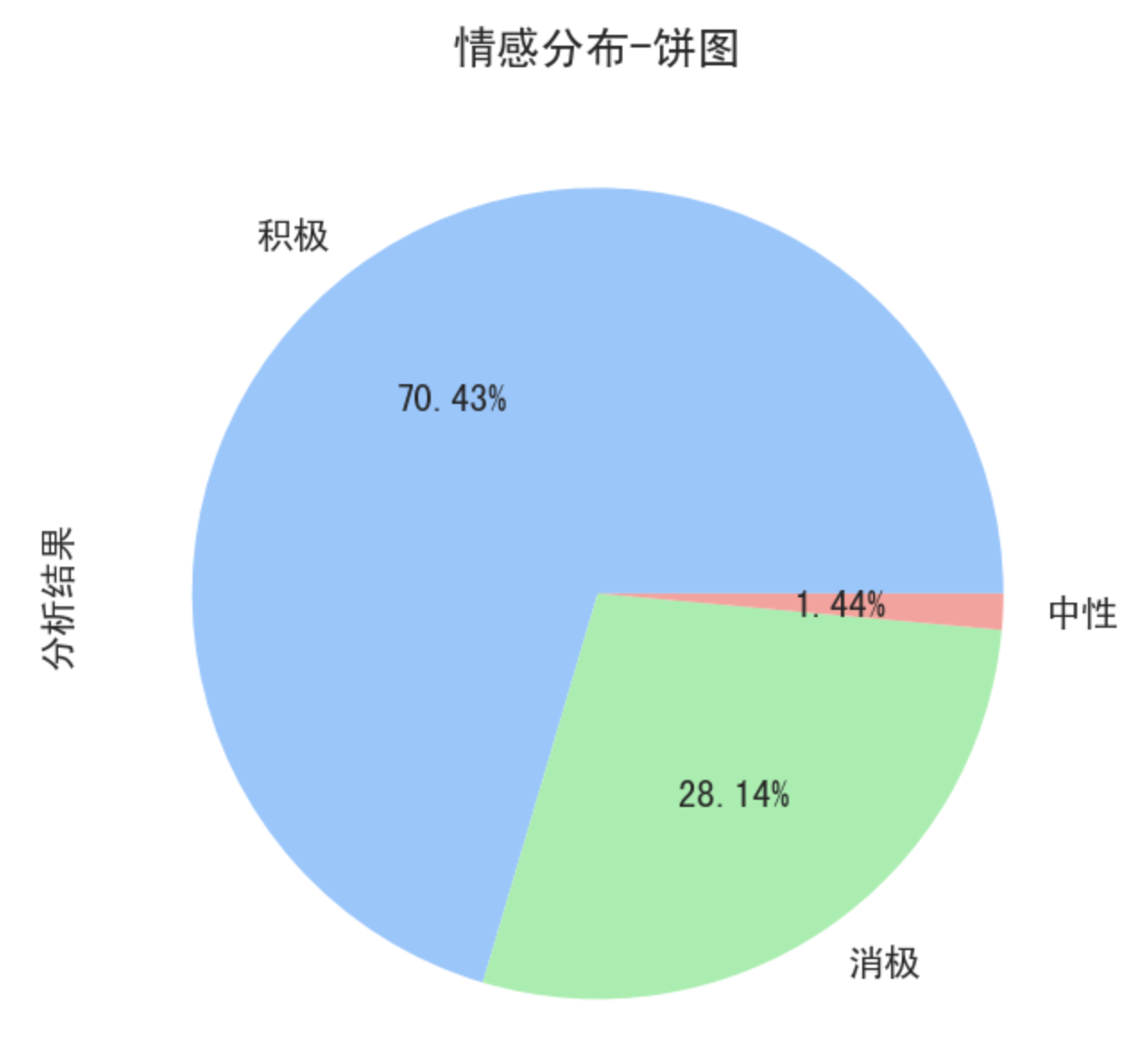
可得结论:关于狂飙这部电视剧,网友的评论情感以正面居多,占据了70.43%,说明这部电视剧获得了网友们很高的评价。
3.3.5 评论内容-词云图
除了哈工大停用词之外,还新增了自定义停用词:

jieba分词之后,对分词后数据进行绘制词云图:
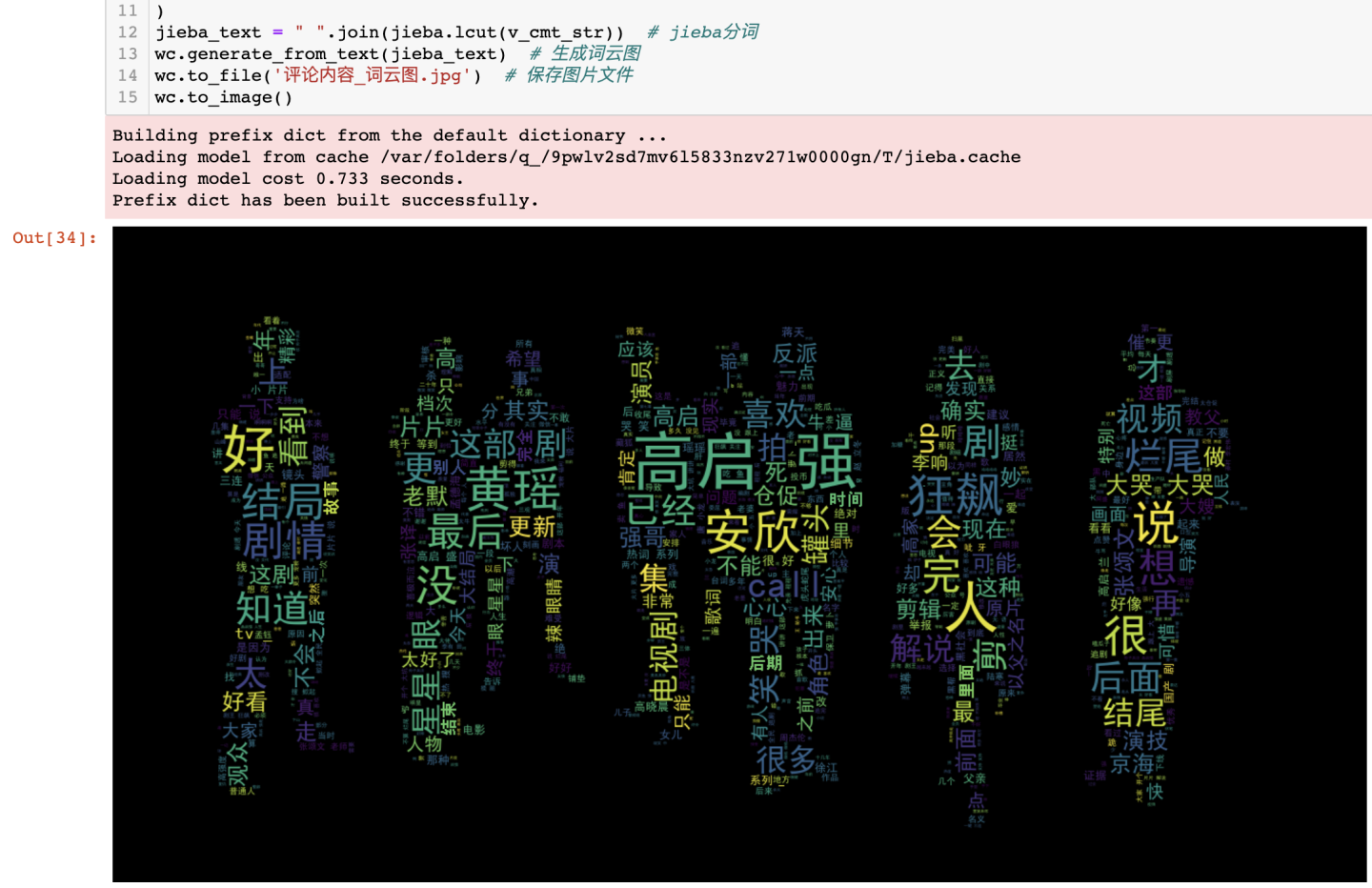
可得结论:在词云图中,阳、感染、发烧、症状、疼、嗓子等词汇较大,出现频率较高,反应出众多网友对确诊阳性后描述病症、积极探讨病情的现状。
附原始背景图,可对比看:(需要先人物抠图)

四、演示视频
代码演示视频:
https://www.zhihu.com/zvideo/1608856878666231808
五、附完整源码
完整源码:【爬虫+数据清洗+可视化分析】舆情分析哔哩哔哩"狂飙"的评论
我是 @马哥python说 ,持续分享python源码干货中!
【爬虫+数据清洗+可视化分析】舆情分析哔哩哔哩"狂飙"的评论的更多相关文章
- Python爬虫+数据可视化教学:分析猫咪交易数据
猫猫这么可爱 不会有人不喜欢吧: 猫猫真的很可爱,和我女朋友一样可爱~你们可以和女朋友一起养一只可爱猫猫女朋友都有的吧?啊没有的话当我没说-咳咳网上的数据太多.太杂,而且我也不知道哪个网站的数据比较好 ...
- 爬虫综合大作业——网易云音乐爬虫 & 数据可视化分析
作业要求来自于https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075 爬虫综合大作业 选择一个热点或者你感兴趣的主题. 选择爬取的对象 ...
- NLP(十二)依存句法分析的可视化及图分析
依存句法分析的效果虽然没有像分词.NER的效果来的好,但也有其使用价值,在日常的工作中,我们免不了要和其打交道.笔者这几天一直在想如何分析依存句法分析的结果,一个重要的方面便是其可视化和它的图分析 ...
- 可视化数据包分析工具-CapAnalysis
可视化数据包分析工具-CapAnalysis 我们知道,Xplico是一个从pcap文件中解析出IP流量数据的工具,本文介绍又一款实用工具-CapAnalysis(可视化数据包分析工具),将比Xpli ...
- 基于flask的可视化动漫分析网站【python入门必学】
课程设计项目名称:基于flask的可视化动漫分析网站,如果你在学习Python的过程中,往往因为没有好的教程或者没人指导从而导致自己容易放弃,为此我建了个Python交流.裙 :一久武其而而流一思(数 ...
- G6:AntV 的图可视化与图分析
导读 G6 是 AntV 旗下的一款专业级图可视化引擎,它在高定制能力的基础上,提供简单.易用的接口以及一系列设计优雅的图可视化解决方案,是阿里经济体图可视化与图分析的基础设施.今年 AntV 11. ...
- 基于flask框架的高校舆情分析系统
系统分析: 高校舆情分析拟实现如下功能,采集微博.贴吧.学校官网的舆情信息,对这些舆情进行数据分析.情感分析,提取关键词,生成词云分析,情感分析图,实时监测舆情动态. 系统设计: 前端:采用layui ...
- 爬虫(八):分析Ajax请求抓取今日头条街拍美图
(1):分析网页 分析ajax的请求网址,和需要的参数.通过不断向下拉动滚动条,发现请求的参数中offset一直在变化,所以每次请求通过offset来控制新的ajax请求. (2)上代码 a.通过aj ...
- Python之路,Day22 - 网站用户访问质量分析监测分析项目开发
Python之路,Day22 - 网站用户访问质量分析监测分析项目开发 做此项目前请先阅读 http://3060674.blog.51cto.com/3050674/1439129 项目实战之 ...
- python预课05 爬虫初步学习+jieba分词+词云库+哔哩哔哩弹幕爬取示例(数据分析pandas)
结巴分词 import jieba """ pip install jieba 1.精确模式 2.全模式 3.搜索引擎模式 """ txt ...
随机推荐
- AIR32F103(六) ADC,I2S,DMA和ADPCM实现录音播放功能
目录 AIR32F103(一) 合宙AIR32F103CBT6开发板上手报告 AIR32F103(二) Linux环境和LibOpenCM3项目模板 AIR32F103(三) Linux环境基于标准外 ...
- C温故补缺(六):C反汇编常用的AT&Tx86语法
C语言反汇编用到的AT&T x86汇编语法 参考:CSDN1,CSDN2 默认gcc -S汇编出的,以及反汇编出的,都是AT&T x86代码,可以用-masm=intel指定为inte ...
- oracle 分析函数——ration_to_report 求占有率(百分比)
oracle 的分析函数有很多,但是这个函数总是会忘记,我想通过这种方式能让自己记起来,不至于下次还要百度. 创表.表数据(平时练手的表): prompt PL/SQL Developer impor ...
- 【SQL知识】SQL中的join操作总结:内连接、外连接(左右全)
一.含义 基于表之间的共同字段,把来自两个或多个表的行结合起来 二.分类 内连接:join / inner join 外连接:left join / right join / full outer j ...
- 全都会!预测蛋白质标注!创建讲义!解释数学公式!最懂科学的智能NLP模型Galactica尝鲜 ⛵
作者:韩信子@ShowMeAI 机器学习实战系列:https://www.showmeai.tech/tutorials/41 深度学习实战系列:https://www.showmeai.tech/t ...
- Bootstrap响应式相关
bootstrap响应式布局实现原理:百分比布局+媒体查询 | 栅格系统 bootstrap和vue响应式布局的区别: 1. bootstrap 栅格系统,简,缺少组件 2. vue 速度快,组件多 ...
- 【LeetCode】剑指 Offer 30. 包含min函数的栈
题目描述 定义栈的数据结构,请在该类型中实现一个能够得到栈的最小元素的 min 函数在该栈中,调用 min.push 及 pop 的时间复杂度都是 O(1). 思路 最初看到O(1)复杂度的时候,就想 ...
- 分支路径图调度框架在 vivo 效果广告业务的落地实践
作者:vivo 互联网AI团队- Liu Zuocheng.Zhou Baojian 本文根据周保建老师在"2022 vivo开发者大会"现场演讲内容整理而成.公众号回复[2022 ...
- js逆向到加密解密入口的多种方法
一.hook hook又称钩子. 可以在调用系统函数之前, 先执行我们的函数. 例如, hook eval eval_ = eval; // 先保存系统的eval函数 eval = function( ...
- nuxt.js中登录、注册(密码登录和手机验证码登录)
<!-- 登录弹框 --> <div class="mask" v-show="flag"> <div class="m ...