高效字符串匹配算法——BM 算法详解(C++)
定义
BM 算法是由 Boyer 和 Moore 两人提出的一种高效的字符串匹配算法,被认为是一种亚线性算法(即平均的时间复杂度低于线性级别),其时间效率在一般情况下甚至比 KMP 还要快 3 ~ 5 倍。
原理
BM 算法跟其他的字符串匹配算法相比,其中一个不同之处是在比对字符的时候,扫描的顺序不是从左往右,而是从右往左的。
暴力匹配
所谓暴力匹配,就是从右向左比对字符,当遇到不匹配的字符时,就将模式串往右移动一个字符,循环执行,直到所有字符都能匹配上(成功),或模式串的右边界超过了文本串的右边界(失败)。如图:



代码实现:
int brute(std::string t, std::string p) {
const int m = p.length(), n = t.length();
int align; // 模式串的对齐位置
int i; // 模式串中的下标
// 循环执行以下步骤,直到全部字符比对成功或模式串的右边界超过了文本串的右边界
for (align = 0; align + i < n && i >= 0; align++) {
// 从右向左逐个比对,直到全部字符比对成功或某个字符比对失败
for (i = m - 1; i >= 0 && t[align + i] == p[i]; i--);
// 如果全部字符比对成功,则退出循环,否则就将模式串向右移动一个字符
if (i < 0) break;
}
return i < 0 // 如果比对成功的话
? align // 就返回模式串的对齐位置
: -1; // 否则就返回-1
}
设文本串的长度为 n,模式串的长度为 m,那么显然暴力匹配算法的时间复杂度为 \(O(mn)\)。
BM 算法利用了坏字符规则和好后缀规则,排除掉肯定不可能匹配上的位置,使得匹配失败的时候模式串能够跳跃尽可能多的距离,时间复杂度能够大大降低。
坏字符规则
如果某次扫描比对的时候发现匹配失败,那么就称文本串中匹配失败的那个字符为坏字符(Bad character)。
所谓坏字符规则(Bad character shift),就是指当遇到坏字符的时候,在模式串中寻找能够与之匹配的字符并将两者对齐。


如果模式串中找不到能够与之匹配的字符,那就直接将模式串越过匹配失败的位置。


如果模式串中有多个字符能够与坏字符匹配上,那就将最右边的那个字符与坏字符对齐,这样就能避免遗漏对齐位置。


好后缀规则
如果某次扫描比对的时候发现匹配失败,那么就称模式串中匹配失败的那个字符右侧比对成功的字符所构成的后缀称为好后缀(Good suffix)。
所谓好后缀规则(Good suffix shift),分为以下3种情况:
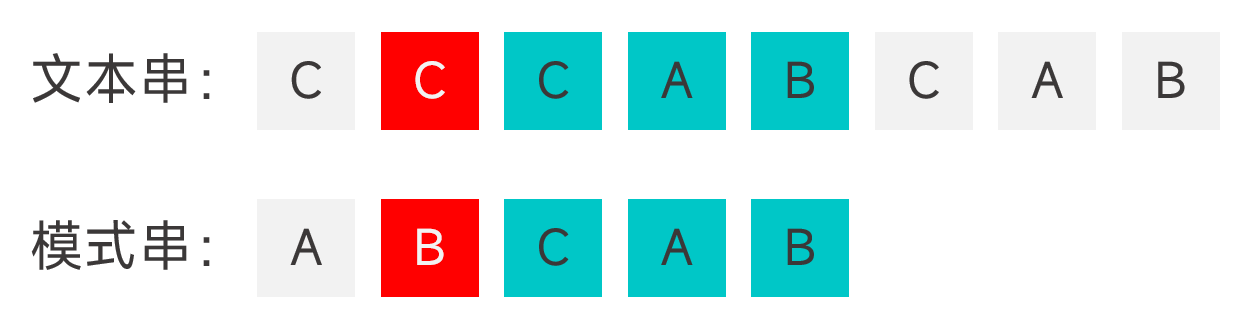
- 模式串中有能够与好后缀匹配上的子串,将该子串与好后缀对齐。如果有多个能够与好后缀匹配上的子串,选择最靠右的那一个。


- 模式串中没有能够与好后缀匹配上的子串,但是模式串的某个前缀能够与好后缀的真后缀匹配,将该前缀的最后一个字符与好后缀的最后一个字符对齐。
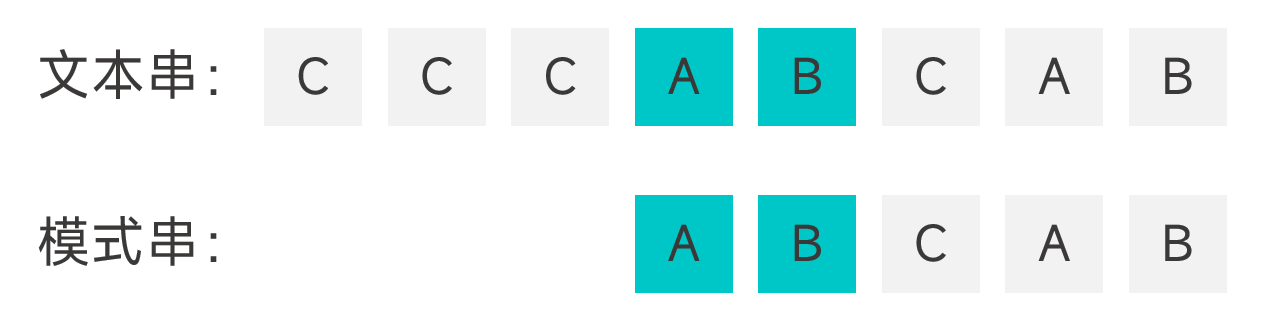
- 模式串中没有能够与好后缀匹配上的子串,且没有哪个前缀能够与好后缀的真后缀匹配,直接将模式串越过好后缀的位置。

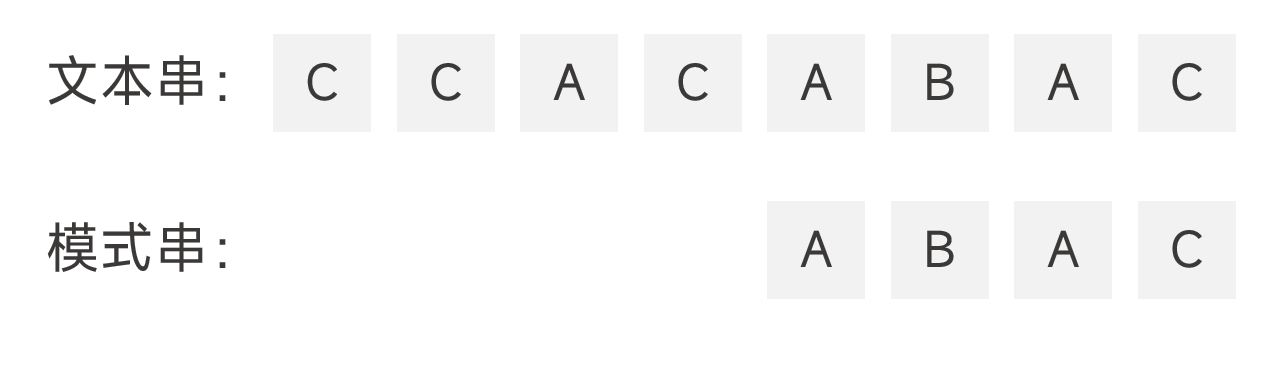
算法步骤
整个 BM 算法的步骤为:从后往前比对字符,如果遇到不匹配的字符,看坏字符规则和好后缀规则中哪个规则会使得模式串移动的距离更大,并相应的移动。
举例:

(其中x为无关紧要的字符)
第一轮比对在倒数第2个字符的位置失败了:

此时,分别运用好后缀规则和坏字符规则,发现运用坏字符规则移动的距离更远:

重新开始新一轮的比对:

再次运用这两个规则,发现好后缀规则移动的距离更远。

开始第三轮比对,发现这次比对成功了。

至此,算法宣告结束。
代码实现
为了能够快速得到某次比对失败时,按照这两个规则,模式串需要移动的位置,我们需要对模式串进行预处理,构建两个辅助数组。
预处理:构造 bc 数组
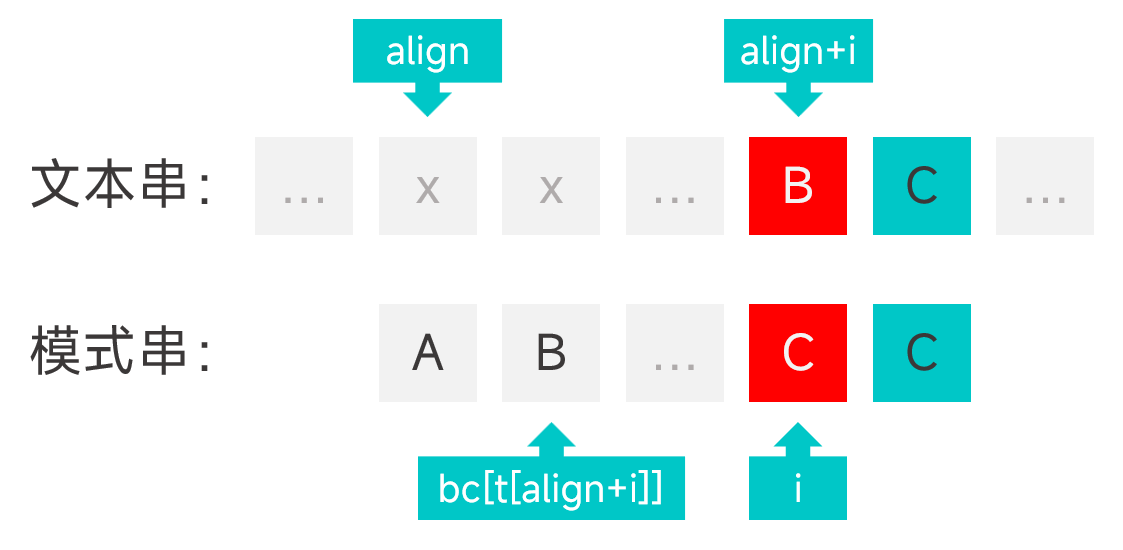
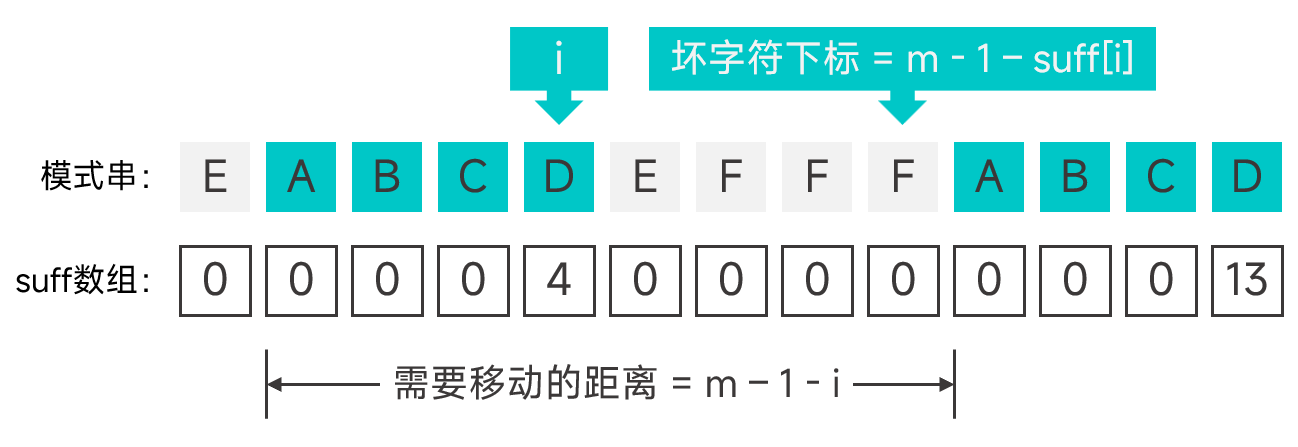
构造 bc 数组用于坏字符规则,其中 bc[c] 表示坏字符 c 在模式串中的最大下标。如果模式串中不存在字符 c 则为 -1,这样才能确保模式串移动的时候能够刚好越过坏字符的位置。当然数组的大小要足够大,这样才能容纳文本串中的所有字符。
这样,当遇到坏字符时,假设模式串中匹配失败的字符的下标为 i,模式串的头部在文本串中的对齐位置为 align,那么模式串需要移动的距离为 i - bc[t[align + i]],如图。
代码实现:
void buildBC(std::string &p, int range) { // range为字符集大小。对于英文的话,128就足够了
const int m = p.length();
std::vector<int> bc(range, -1);
for (int i = 0; i < m; ++i) {
char c = p[i];
bc[c] = i;
}
return bc;
}
为什么是从左往右呢,因为这样的话,对于同一个字符,如果存在多个下标,大的下标才能覆盖小的下标。
预处理:构造 gs 数组
构造 gs 数组用于好后缀规则,其中 gs[i] 表示如果模式串中下标为i的字符与文本串中的相应字符比对失败的话,为了使好后缀对齐,模式串应该移动的距离。
然而,如果我们直接构造的话,时间成本为 \(O(m^3)\)!这显然是不能接受的,于是我们需要用“空间换时间”的策略将时间成本降低。
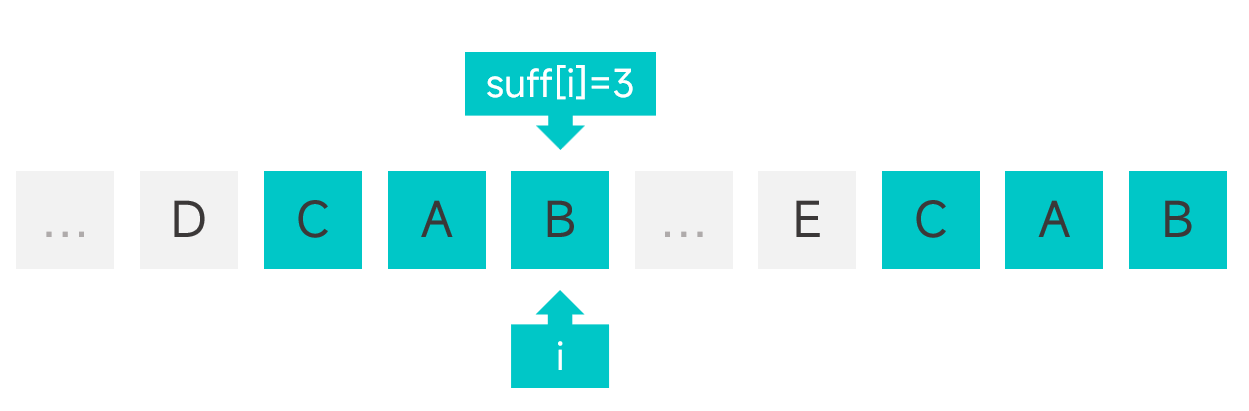
为此我们需要引入另外一个辅助数组 suff,其中 suff[i] 为模式串中下标为i的字符左侧(包括下标为 i 的字符)最多能有多少个字符能够与模式串的后缀匹配,如图:
代码如下:
std::vector<int> buildSuff(std::string &p) {
const int m = p.length();
std::vector<int> suff(m, 0);
suffix[m - 1] = m; // 对于最后一个字符,显然该字符以左的所有字符都能与模式串的后缀匹配
for (int i = m - 2; i >= 0; i--) { // 从右往左扫描
int j = i, k = m - 1;
for (; j >= 0 && p[j] == p[k]; j--, k--); // 双指针同步向左扫描
suffix[i] = i - j;
}
return suff;
}
时间复杂度为 \((n^2)\),但是最坏情况只有当模式串所有字符全都一样的时候才会出现,一般情况下只会比 \(O(n)\) 略微多一点点,因此是可以接受的。
然后我们就可以利用 suff 数组求得 gs 数组了。构建 gs 数组的部分也有讲究。
我们首先需要计算第 3 种情况,然后是第二种,最后是第一种。为什么呢,因为如果同一个字符同时满足以上三种情况中的至少 2 种的话,位移距离:第三种情况 > 第二种 > 第一种,为了不遗漏对齐位置,我们要选择最靠右的那个好后缀,那只能用小的位移距离覆盖大的位移距离。
第三种情况比较简单,直接全都设为 m 就可以了。(C++ 里面这一步在初始化的时候就可以完成)
std::vector<int> gs(m, m);
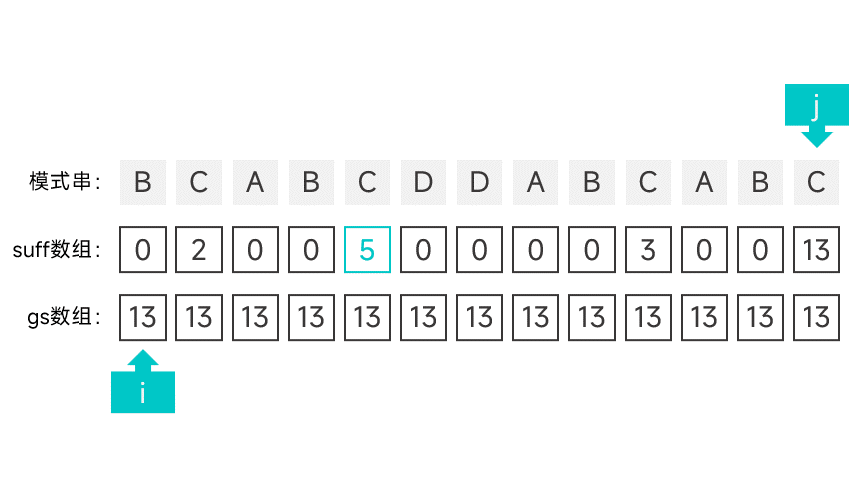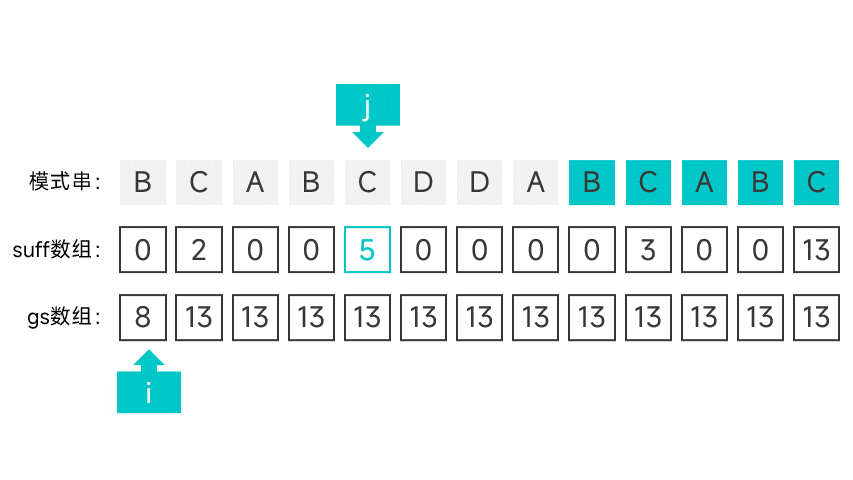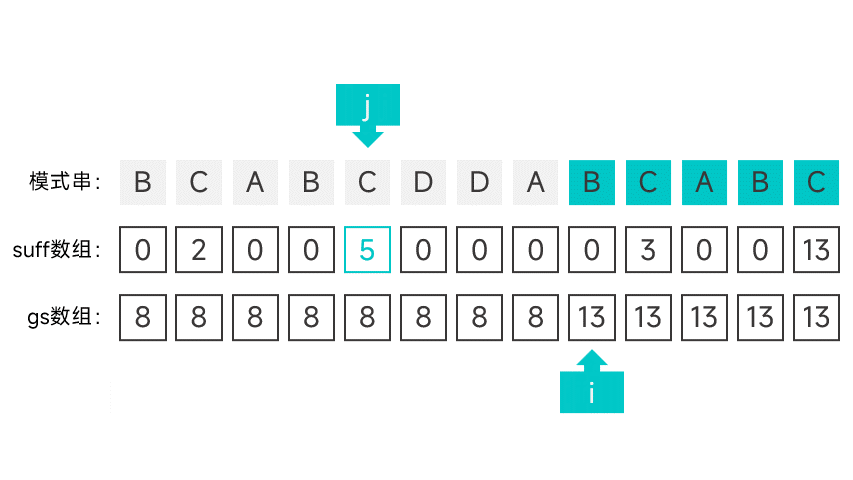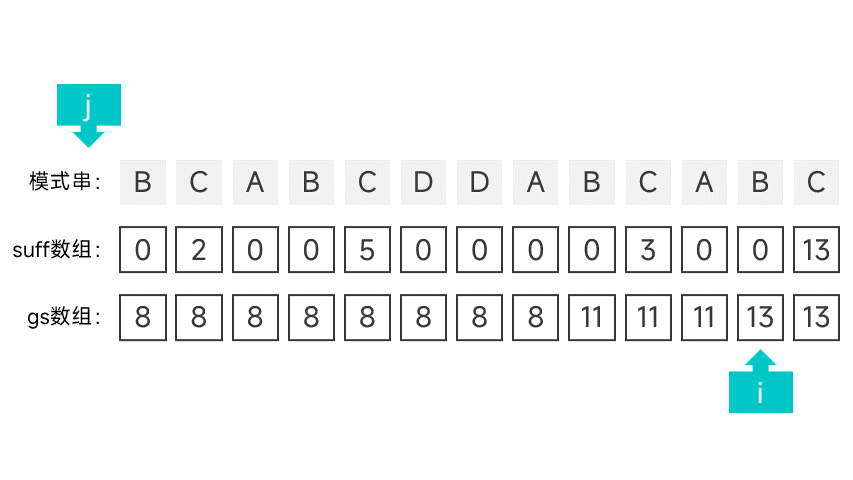
第二种情况有点讲究,首先需要维护一个指针 i,初始时指向模式串的第一个字符。从右往左扫描字符串,根据对应的 suff 数组项判断是否满足第二种情况。怎么判断呢,看图就知道了:

如果某个字符的 suff 数组项刚好等于下标 + 1 的话(此时的数组项记作 sufLen),那就说明该字符以左的所有字符组成的前缀都能与模式串的后缀匹配。如果该后缀为某次比对中的好后缀的后缀,那就说明符合第二种情况。这就说明模式串中倒数第 sufLen 个字符(也就是下标为 m - suflen 的字符)的左边某个字符如果发生匹配失败,模式串应该右移 m - sufLen 个字符。
如果遇到符合第二种情况的字符的话,就将指针 i 指向的字符的 gs 数组项设为 m - suflen,并向后移动一个字符,直到指针指向了 m - sufLen。
继续向左扫描,重复以上操作,直到扫描到模式串的最左端。
动画表示:
代码实现:
for (int i = 0, j = m - 1; j >= 0; j--) {
int sufLen = suff[j];
if (sufLen == j + 1) {
for (; i < m - sufLen; i++) {
if (gs[i] == m) { // 加上这一句条件判断的目的是为了防止重复设置
gs[i] = m - sufLen;
}
}
}
}
有人会问,为什么是从右向左扫描字符串呢,是因为如果存在多个字符满足第二种情况,那必然是右边字符的 sufLen 大于左边字符的 sufLen。sufLen 越大,m - sufLen 越小。而如果某个字符发生匹配失败需要用到第二种情况的话,那必然优先选择 m - sufLen 小的那个,也就是 sufLen 大的那个。那为什么不像 bc 数组和 suff 数组构建算法那样采用 “大的覆盖小的” 的方法呢,是因为这样的话每次都要设置一大片字符的 gs,反而会使时间复杂度上升到 \(O(n^2)\),不划算。
最后再来看第一种情况,从左往右扫描模式串,根据扫描到的字符的下标及 suff 数组项可以方便的求出对应坏字符的下标及 gs 数组项,如图:
代码实现:
for (int i = 0; i < m - 1; ++i) {
int sufLen = suff[i];
gs[m - 1 - sufLen] = m - 1 - i;
}
至此,通过 suff 数组构建 gs 数组的完整实现代码:
std::vector<int> buildGS(std::string &p) {
const int m = p.length();
auto suff = buildSS(p);
std::vector<int> gs(m, m);
for (int i = 0, j = m - 1; j >= 0; j--) {
int sufLen = suffix[j];
if (sufLen == j + 1) {
for (; i < m - sufLen; i++) {
if (gs[i] == m) {
gs[i] = m - sufLen;
}
}
}
}
for (int i = 0; i < m - 1; ++i) {
int sufLen = suffix[i];
gs[m - 1 - sufLen] = m - 1 - i;
}
return gs;
}
主算法实现
int match(std::string t, std::string p, int range) {
const int m = p.length(), n = t.length();
// 两个预处理数组
auto bc = buildBC(p, range);
auto gs = buildGS(p);
int align = 0; // 模式串的对齐位置
int i = m - 1; // 模式串中的下标
while (align + i < n && i >= 0) {
for (; i >= 0 && t[align + i] == p[i]; i--); // 从右往左比对
if (i < 0) break; // 比对成功就退出循环
// 以下处理比对失败的情况
int distBc = i - bc[t[align + i]]; // 根据坏字符规则得到的移动距离
int distGs = gs[i]; // 根据好后缀规则得到的移动距离
align += std::max(distBc, distGs); // 模式串的位移距离取两者之间的较大者
i = m - 1; // 重新开始新一轮的比对
}
return i < 0 ? align : -1;
}
复杂度分析
空间复杂度
不计文本串和模式串本身所占用的空间,算法的空间复杂度为 \(O(m + |\Sigma|)\),其中 m 为模式串的长度,\(|\Sigma|\) 为字符集的大小。其中 bc 数组所占用的空间为 \(O(|\Sigma|)\),gs 数组则为 \(O(m)\)。
时间复杂度
最好:\(O(n/m)\),最坏:\(O(n+m)\),其中 n 和 m 分别为文本串和模式串的长度。
最好情况的一个实例:
文本串:AAAAAA...AAAA
模式串:AAB
每次比对,都会在倒数第一个字符发生匹配失败。按照坏字符规则,模式串应该向右移动 m 个字符。所以,模式串的移动次数最多为 n / m。而每次比对的次数都是 1 次,因此这种情况下的时间复杂度为 \(O(n/m)\)。
最坏情况的一个实例:
文本串:AAAAAA...AAAA
模式串:BAA
每次比对,都会在第一个字符发生匹配失败。按照好后缀规则,模式串应该向右移动 m 个字符。所以,模式串的移动次数最多为 n / m。而每次比对的次数都是 m 次,因此这种情况下的时间复杂度为 \(O(n/m*m)=O(n)\)。
高效字符串匹配算法——BM 算法详解(C++)的更多相关文章
- 数据结构4.3_字符串模式匹配——KMP算法详解
next数组表示字符串前后缀匹配的最大长度.是KMP算法的精髓所在.可以起到决定模式字符串右移多少长度以达到跳跃式匹配的高效模式. 以下是对next数组的解释: 如何求next数组: 相关链接:按顺序 ...
- 字符串匹配算法(二)-BM算法详解
我们在字符串匹配算法(一)学习了BF算法和RK算法,那有没更加高效的字符串匹配算法呢.我们今天就来聊一聊BM算法. BM算法 我们把模式串和主串的匹配过程,可以看做是固定主串,然后模式串不断在往后滑动 ...
- BM算法详解
http://www-igm.univ-mlv.fr/~lecroq/string/node14.html http://www.cs.utexas.edu/users/moore/publicati ...
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- 算法进阶面试题01——KMP算法详解、输出含两次原子串的最短串、判断T1是否包含T2子树、Manacher算法详解、使字符串成为最短回文串
1.KMP算法详解与应用 子序列:可以连续可以不连续. 子数组/串:要连续 暴力方法:逐个位置比对. KMP:让前面的,指导后面. 概念建设: d的最长前缀与最长后缀的匹配长度为3.(前缀不能到最后一 ...
- kmp算法详解
转自:http://blog.csdn.net/ddupd/article/details/19899263 KMP算法详解 KMP算法简介: KMP算法是一种高效的字符串匹配算法,关于字符串匹配最简 ...
- 【转】AC算法详解
原文转自:http://blog.csdn.net/joylnwang/article/details/6793192 AC算法是Alfred V.Aho(<编译原理>(龙书)的作者),和 ...
- KMP算法详解&&P3375 【模板】KMP字符串匹配题解
KMP算法详解: KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt(雾)提出的. 对于字符串匹配问题(such as 问你在abababb中有多少个 ...
- [转] KMP算法详解
转载自:http://www.matrix67.com/blog/archives/115 KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的K ...
- KMP算法详解(转自中学生OI写的。。ORZ!)
KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的KMP不是拿来放电影的(虽然我很喜欢这个软件),而是一种算法.KMP算法是拿来处理字符串匹配的.换句 ...
随机推荐
- 2022春每日一题:Day 38
题目[USACO17JAN]Promotion Counting P 从根节点dfs一遍,树状数组维护进入和出去时这个节点的贡献,一减就是答案 代码: #include <cstdio> ...
- Spring Cloud Circuit Breaker 使用示例
Spring Cloud Circuit Breaker 使用示例 作者: Grey 原文地址: 博客园:Spring Cloud Circuit Breaker 使用示例 CSDN:Spring C ...
- 一行代码实现shell if else逻辑
前言 前几天学习 shell 脚本,发现这种好用的写法,简单记录一下. if else 一行实现 if [ 1=1 ] ;then echo "条件成立";else echo &q ...
- NOIP 口胡
因为没准备啥东西 这两天口胡一下近年 NOIP 的题 大概会一道不落?没什么很寄的考点主要是 2021 T1 报数 打一个 \(O(\log n)\) 查询 \(n\) 中是否有 \(7\),打一个类 ...
- Nginx 安装篇-1.19.9版本源码安装
系统环境:CentOS 8.5 64位 [开始安装](此步骤引自网络教程) https://www.cnblogs.com/torchstar/p/16027538.html 教程比较详细,一步步操作 ...
- Boolean.getBoolean() 与 Boolean.parseBoolean()
1. 问题回顾 当在不了解 Boolean 中的 getBoolean() 方法与 parseBoolean() 方法的区别时,在使用过程中就会出现不明所以的bug. 比如如下使用情况: // isA ...
- Dijkstra 算法说明与实现
Dijkstra 算法说明与实现 作者:Grey 原文地址: 博客园:Dijkstra 算法说明与实现 CSDN:Dijkstra 算法说明与实现 问题描述 问题:给定出发点,出发点到所有点的距离之和 ...
- Linux 下的输入输出和重定向示例
Linux 下的输入输出和重定向示例 作者:Grey 原文地址: 博客园:Linux 下的输入输出和重定向示例 CSDN:Linux 下的输入输出和重定向示例 说明 Linux 下的输入输出有如下三种 ...
- vscode问题:由于找不到ffmpag.dll文件,无法继续执行代码
工作中发现VS code打不开了,显示如下: 解决方法: 一.打开Microsoft VS Code 文件夹,发现一部分文件被打包进了一个叫"_"的文件夹(第一个) 二.把该文 ...
- JavaScript:显式转换数据类型:如何转换为数值、字符串和布尔值类型?
JS的运算符以及某些内置函数,会自动进行数据类型的转换,方便计算,即隐式转换数据类型: 但是很多时候,我们希望可以手动控制数据类型的转换,即显示转换数据类型: 转换为字符串 String()函数 使用 ...