Go语言基础之9--指针类型详解
一、 变量和内存地址
每个变量都有内存地址,可以说通过变量来操作对应大小的内存
注意:通过&符号可以获取变量的内存地址
通过下面例子来理解下:
实例1-1
package main import (
"fmt"
) func main() {
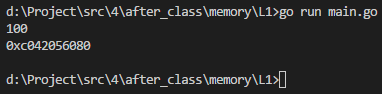
var a int32 =
fmt.Printf("%d\n", a)
fmt.Printf("%p\n", &a)
}
执行结果如下图所示:
二、 指针类型
2.1 定义
普通变量存储的是对应类型的值,这些类型就叫值类型;
指针类型的变量存储的是一个地址,所以又叫指针类型或引用类型;(任何类型都可以有指针类型,对于所有类型指针类型都生效)
32位操作系统内存占4字节,64位操作系统占8字节;
指针类型默认值为nil(空内存地址0x0)

a就是一个指针类型,存储的是内存地址,b是一个值类型,存储的是对应的值。
下面通过一个实例再来理解一下:
实例2-1
package main import (
"fmt"
) func main() {
var b int32 //b为值类型,存储的是对应的值
b =
var a *int32 //a为指针类型,存储的是内存地址
fmt.Printf("addr of a:%v\n", a) //指针a未赋值,其的默认值为nil,也就是空内存地址0x0
a = &b //a目前是一个指针,打印出来的也就是b(通过&取的内存地址)的内存地址
fmt.Printf("%v\n", a)
fmt.Printf("%v\n", *a) //*a表示取指针类型里指向的那块内存地址所对应的值
}
执行结果如下:

2.2 声明
指针类型定义, var 变量名 *类型
实例2-2
package main import (
"fmt"
) func main() {
var a *int
var b int = a = &b
fmt.Printf("value of a %v\n", a) //打印的是指针a的值
fmt.Printf("address of b %v\n", &b) //打印的是变量b的内存地址
fmt.Printf("address of a %v\n", &a) //打印指针a的内存地址 *a = //修改指针a存的内存地址所对应的值的值(其实就是修改b)
fmt.Printf("value of b %v\n", b) //打印变量b看是否修改成功
fmt.Printf("type of a %T\n", a) //%T能够打印变量的类型
}
执行结果如下:

2.3 指针初始化
2.3.1 方法1
var a *int = &b
再定义指针a之后,我们必须要为其初始化(不初始化,是一个空内存地址,程序会直接崩溃),也就是为其赋值,这里我们为指针a传入的是一个内存地址(也就分配了内存了),因为变量b在定义时已经为其分配了内存,这里是把变量b的内存地址赋值给了指针a;
2.3.2 方法2 new
var p *int = new(int)
变量p此时为指针,其指向的是一个类型为int的内存地址(底层new为其分配内存地址,做了初始化),然后就可以对指针p进行操作了
2.4 指针类型变量的默认值
指针类型变量的默认值为nil,也就是空地址0x0。所有操作都是有内存才能操作。
下面通过一个实例来验证下对一个空地址操作,程序就会崩溃:
实例2-3
package main import (
"fmt"
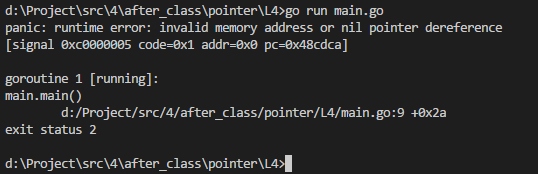
) func main() {
var a *int //只是定义了一个指针a
*a = //现在修改指针a,但指针a是空,必然会报错
fmt.Printf("%d\n", *a)
}
执行结果如下:
所以我们写程序一定要严谨,加上判断,可见如下例子:
实例2-4
package main import (
"fmt"
) func main() {
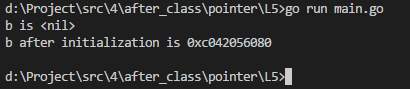
a :=
var b *int
if b == nil { //如果指针a是空地址,就为其赋值,不然程序会崩溃
fmt.Printf("b is %v\n", b)
b = &a
fmt.Printf("b after initialization is %v\n", b)
}
}
执行结果如下:
2.5 操作指针变量指向的地址里面的值
注意:通过* 符号可以获取指针变量指向的变量
*指针变量:就能够获得指针变量中存的内存地址对应的值。
如果想要修改指针变量的存的内存地址所对应的值?
方法:*指针变量 = 要修改的值
实例2-5
package main import (
"fmt"
) func main() {
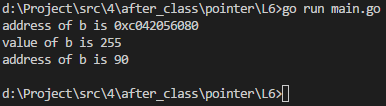
b :=
a := &b
fmt.Println("address of b is", a)
fmt.Println("value of b is", *a) //获取指针变量中存的内存地址对应的值 *a = //修改指针变量的存的内存地址所对应的值
fmt.Println("address of b is", b)
}
执行结果如下图所示:
2.6 通过指针修改变量的值
如果想要修改指针变量的存的内存地址所对应的值?
方法:*指针变量 = 要修改的值
实例2-6
package main import (
"fmt"
) func main() {
b :=
a := &b
fmt.Println("address of b is", a)
fmt.Println("value of b is", *a)
*a++ //修改指针变量的存的内存地址所对应的值
fmt.Println("new value of b is", b)
}
执行结果如下:

2.7 指针变量传参
1、如果是一个值类型,通过函数是改不了他的值。
2、无论是指针类型还是值类型,函数传参都是会拷贝,只不过指针类型拷贝的是内存地址,无论指针类型的内存地址指向的那个值有多大,指针类型永远是拷贝8个字节(64位操作系统 int64 32位操作系统是4个字节 int32),所以说如果指针类型指向的那块内存地址存的值很大的话,指针传值性能更高。
下面通过这个例子来详细解释下:
实例2-7 实例1
package main import (
"fmt"
) func modify(a int) {
fmt.Printf("2. address of a=%p, value of a:%v\n", &a, a)
a =
} func modify2(a *int) {
fmt.Printf("4. address of a:%v, value of a :%v\n", &a, a)
*a =
} func main() {
var b int =
fmt.Printf("1. address of b=%p, value of b:%v\n", &b, b)
modify(b) var p *int = &b
fmt.Printf("3. address of p:%v, value of p:%v\n", &p, p) modify2(p)
fmt.Printf("b=%d\n", b)
}
执行结果如下:

解释:
1、函数传参是值的拷贝,只不过值类型传递的是值,指针类型(引用类型)传递的是内存地址。
2、定义b为100,当首先执行modify函数时,传递的是b的副本,所以无论函数中怎么修改,是不影响变量b值本身的。在经过modify2函数执行后,虽然传递的也是副本,但是传递的是b的内存地址,而函数又是基于该内存地址进行修改的,所以值由100修改为了1000
实例2-8 实例2
package main import (
"fmt"
) func change(val *int) {
*val = //修改指针多存的内存地址对应的值
}
func main() {
a :=
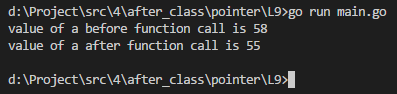
fmt.Println("value of a before function call is", a)
b := &a //传入a的内存地址
change(b)
fmt.Println("value of a after function call is", a)
}
执行结果如下:
实例2-9 实例3
package main import (
"fmt"
) func modify(arr *[]int) {
(*arr)[] =
}
func main() {
a := []int{, , }
modify(&a) //传递的是内存地址所以可以修改
fmt.Println(a)
}
执行结果如下:

2.8 切片传参
实例2-10
package main import (
"fmt"
) func modify(sls []int) {
sls[] =
}
func main() {
a := []int{, , }
modify(a[:]) //切片是引用类型,所以底层也是指针,所以是可以修改的,修改是生效的
fmt.Println(a)
}
执行结果如下:

三、 make和new的区别
1、make用来分配引用类型的内存,比如 map、 slice以及channel,make除了分配内存外,还为这些复杂的数据类型(底层结构复杂,有很多字段在里面)做初始化
2、new用来分配除引用类型的所有其他类型的内存,比如 int、数组等,其实new可以为任何类型的分配内存,只不过针对引用类型(切片、map)来说,new虽然可以为其分配内存,但是其还是需要借助make去初始化。
通过下面这个实例深入理解:
实例3-1
package main import (
"fmt"
) type User struct {
Name string
age int
} func test1() {
var p *int = new(int)
*p =
fmt.Printf("p:%v address:%v\n", *p, p) var pUser *User = new(User)
(*pUser).age =
pUser.Name = "user01" //正常来说规范写应该是(*pUser).Name,但是go语言针对结构体这里做了优化(切片、map不可以,依然需要规范写),可以简化写。 fmt.Printf("user:%v\n", *pUser)
} func test2() {
var p *[]int = new([]int) //new为切片分配内存
*p = make([]int, ) //切片需要make为其初始化才能使用 (*p)[] =
(*p)[] = fmt.Printf("p:%#v\n", *p) var p1 *map[string]int = new(map[string]int) //new为map分配内存
*p1 = make(map[string]int, ) //map需要make为其初始化才可以使用
(*p1)["key"] =
(*p1)["key2"] = fmt.Printf("p:%#v\n", *p1)
} func main() {
test1()
test2()
}
执行结果如下:

四、 值拷贝和引用拷贝
4.1 值拷贝
值类型拷贝,相当于完全拷贝一份(有副本存在),当对副本进行修改时,无论如何是不影响变量本身的。
实例4-1
package main import (
"fmt"
) func main() {
var a int =
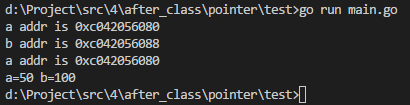
fmt.Printf("a addr is %p\n", &a)
b := a
fmt.Printf("b addr is %p\n", &b)
a =
fmt.Printf("a addr is %p\n", &a)
fmt.Printf("a=%d b=%d", a, b)
}
执行结果如下:
解释:
正如此题,a赋值给b,其做的就是一个值拷贝,b就相当于是拷贝的这个副本,无论b如何变化,是不影响a本身的,本身他们就是2块独立的内存地址。所以a的值在变化后,b是不受影响的。
4.2 引用拷贝
引用拷贝,拷贝的是内存地址,所以当其中一个变量修改了,另一个变量也会修改,因为他们对应的是同一个内存地址。
通过如下例子再来理解一下:
实例4-2
package main import (
"fmt"
) func main() {
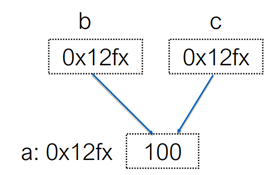
var a int =
var b *int = &a
var c *int = b
*c =
fmt.Printf("a=%v b=%v c=%v", a, *b, *c)
}
执行结果如下:

解释:
我们可以发现a、b和c都是同事指向同一内存地址,一旦对任何一个变量修改,另外两个变量也会修改。
Go语言基础之9--指针类型详解的更多相关文章
- Go语言基础之2--字符串详解
一.字符串原理解析 1. 字符串底层就是一个byte数组,所以可以和[]byte类型互相转换:(字符串可以存文本,也可以存二进制,因为其本来就是一个字节流) 2. 字符串之中的字符是不能修改的,那怎 ...
- GO语言基础(结构+语法+类型+变量)
GO语言基础(结构+语法+类型+变量) Go语言结构 Go语言语法 Go语言类型 Go语言变量 Go 语言结构 Go 语言的基础组成有以下几个部分: 包声明 引入包 函数 变量 语句 &a ...
- C#进阶系列——WebApi 接口返回值不困惑:返回值类型详解
前言:已经有一个月没写点什么了,感觉心里空落落的.今天再来篇干货,想要学习Webapi的园友们速速动起来,跟着博主一起来学习吧.之前分享过一篇 C#进阶系列——WebApi接口传参不再困惑:传参详解 ...
- C++11 并发指南六(atomic 类型详解四 C 风格原子操作介绍)
前面三篇文章<C++11 并发指南六(atomic 类型详解一 atomic_flag 介绍)>.<C++11 并发指南六( <atomic> 类型详解二 std::at ...
- C++11 并发指南六(atomic 类型详解三 std::atomic (续))
C++11 并发指南六( <atomic> 类型详解二 std::atomic ) 介绍了基本的原子类型 std::atomic 的用法,本节我会给大家介绍C++11 标准库中的 std: ...
- C++11 并发指南六( <atomic> 类型详解二 std::atomic )
C++11 并发指南六(atomic 类型详解一 atomic_flag 介绍) 一文介绍了 C++11 中最简单的原子类型 std::atomic_flag,但是 std::atomic_flag ...
- C++之string类型详解
C++之string类型详解 之所以抛弃char*的字符串而选用C++标准程序库中的string类,是因为他和前者比较起来,不必担心内存是否足够.字符串长度等等,而且作为一个泛型类出现,他集成的操作函 ...
- (转)C# WebApi 接口返回值不困惑:返回值类型详解
原文地址:http://www.cnblogs.com/landeanfen/p/5501487.html 正文 前言:已经有一个月没写点什么了,感觉心里空落落的.今天再来篇干货,想要学习Webapi ...
- 基础 | batchnorm原理及代码详解
https://blog.csdn.net/qq_25737169/article/details/79048516 https://www.cnblogs.com/bonelee/p/8528722 ...
随机推荐
- SQLAchemy ORM框架
SQLAchemy SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行S ...
- C#正则表达式匹配双引号
html: <img class="bubble large" src="/images/hero-logos/cog.svg" width=" ...
- 算法Sedgewick第四版-第1章基础-010一检查括号是否成对出现
/****************************************************************************** * Compilation: javac ...
- python 简单的数据库操作之转账
介绍:本文是关于数据库的简单操作,实现转账(只是修改数据库中用户的账户金额)的功能 模块介绍:首先是入口主函数 主函数中实现转账方法 以及异常的处理: if __name__ == "__ ...
- head first 设计模式 策略模式
HEAD FIRST:策略模式定义了算法族,分别封装起来,让它们之间可以互相替换,此模式让算法的变化独立于使用算法的客户. 设计模式:定义一系列的算法,把它们一个个封装起来,并且使它们可以相互替换.本 ...
- 339E Three Swaps
传送门 题目大意 给出由1-n组成的序列,每次可将一个区间翻转.问如何从1-n的递增序列变成给出的序列,输出操作次数以及每次操作的区间.最多翻转3次,保证有解,输出任意方案即可. 分析 我们对于每一次 ...
- 最新解决VS2017+ Mysql + EF 创建实体数据模型 闪退的办法
研究下来,就是最新的版本兼容性不好啊. 1.找到MySql管网,下载历史版本: mysql-connector-net-6.9.12 mysql-for-visualstudio-1.2.8 2.Nu ...
- Sequoiadb该如何选择合适的SQL引擎
Sequoiadb作为一个文档型NoSQL数据既可以存储结构化数据也可以存储非结构化数据,对于非结构化数据只能使用原生的API进行查询,对结构化数据我们可以选择使用原生的API和开源SQL引擎,目前P ...
- ConcurrentHashMap的putIfAbsent
这个方法在key不存在的时候加入一个值,如果key存在就不放入,等价: if (!map.containsKey(key)) return map.put(key, value); else retu ...
- Day Day Up—— ——fseek()函数的用法
在牛客网遇到的一个程序题中用到了函数fseek()故查阅了一下该函数的功能及用法,整理如下: fseek函数功能是把文件指针指向文件的开头,需要包含头文件stdio.h 功 能: 重定位流上的文件指针 ...