scrapy--boss直聘
Hi,大家好。有段时间没来更新scrapy爬取实例信息了,前2天同事说爬取拉勾,boss直聘等网站信息比较困难。昨天下午开始着手爬取boss直聘内Python爬虫的信息,比想象中的简单很多。
需要解决的问题:
boss直聘网的信息是大部分以静态加载和少许动态加载方式显示网站。 1.静态加载:公司的具体信息和岗位职责(1_1) 2.动态加载:首页搜索框,搜索python爬虫(1_2)
解决的思路:
1.静态加载:常规爬取信息(简单) 2.动态加载:selenium(简单)

图(1_1)
图(1_2)
老规矩,给各位爬取结果的图,大家也可以去尝试一下:
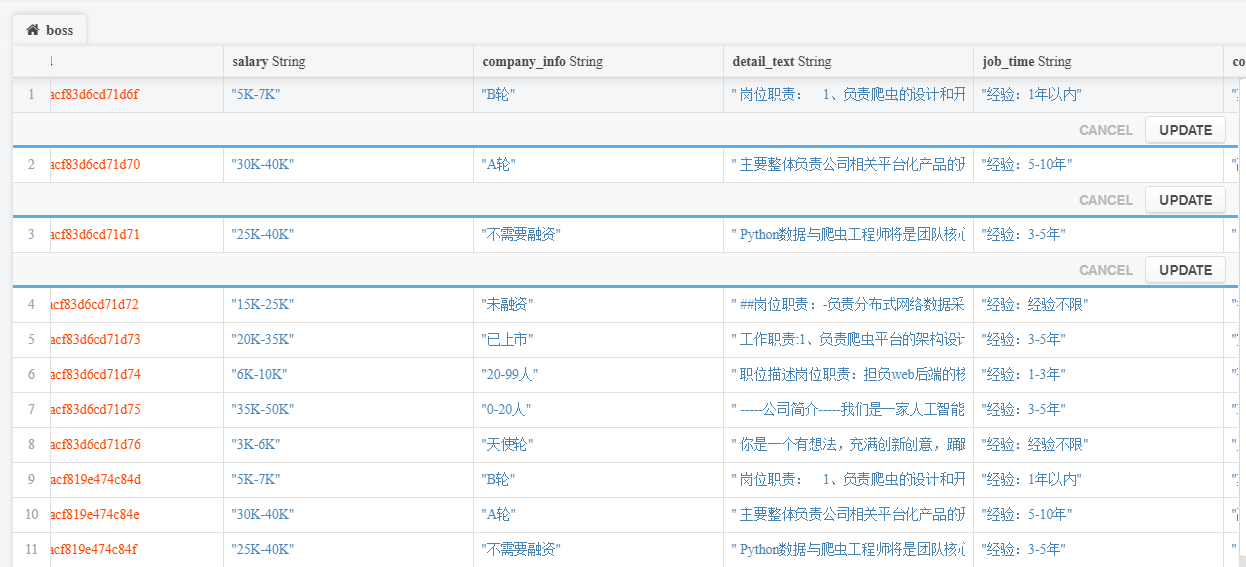
(三)开始正题
3_1.需要提取的信息:items.py
import scrapy class BossItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#pass
job_title = scrapy.Field()
salary = scrapy.Field()
address = scrapy.Field()
job_time = scrapy.Field()
education = scrapy.Field()
company = scrapy.Field()
company_info= scrapy.Field()
detail_text = scrapy.Field()
3_2.设置代理:middlewares.py
class BossSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects. def __init__(self,ip=''):
self.ip = ip
def process_request(self,request,spider):
print('http://10.240.252.16:911')
request.meta['proxy']= 'http://10.240.252.16:911' @classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider. # Should return None or raise an exception.
return None def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response. # Must return an iterable of Request, dict or Item objects.
for i in result:
yield i def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception. # Should return either None or an iterable of Response, dict
# or Item objects.
pass def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated. # Must return only requests (not items).
for r in start_requests:
yield r def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name) class BossDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects. @classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware. # Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None def process_response(self, request, response, spider):
# Called with the response returned from the downloader. # Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception. # Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
3_3.下载数据(存储到mongodb):pipelines.py
import scrapy
import pymongo
from scrapy.item import Item class BossPipeline(object):
def process_item(self, item, spider):
return item class MongoDBPipeline(object): #存储到mongodb中
@classmethod
def from_crawler(cls,crawler):
cls.DB_URL = crawler.settings.get("MONGO_DB_URL",'mongodb://localhost:27017/')
cls.DB_NAME = crawler.settings.get("MONGO_DB_NAME",'scrapy_data')
return cls() def open_spider(self,spider):
self.client = pymongo.MongoClient(self.DB_URL)
self.db = self.client[self.DB_NAME] def close_spider(self,spider):
self.client.close() def process_item(self,item,spider):
collection = self.db[spider.name]
post = dict(item) if isinstance(item,Item) else item
collection.insert(post) return item
3_4.settings.py
MONGO_DB_URL = 'mongodb://localhost:27017/'
MONGO_DB_NAME = 'boss_detail' USER_AGENT ={ #设置浏览器的User_agent
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
} FEED_EXPORT_FIELDS = ['job_title','salary','address','job_time','education','company','company_info'] # Obey robots.txt rules
ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 10 # See also autothrottle settings and docs
DOWNLOAD_DELAY = 0.5 # Disable cookies (enabled by default)
COOKIES_ENABLED = False DOWNLOADER_MIDDLEWARES = {
#'Boss.middlewares.BossDownloaderMiddleware': 543,
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':543,
'Boss.middlewares.BossSpiderMiddleware':123,
} ITEM_PIPELINES = {
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':1,
'Boss.pipelines.MongoDBPipeline': 300,
}
3_5.spider/boss.py
#-*- coding:utf-8 -*-
import time
from selenium import webdriver
import pdb
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from lxml import etree
import re
from bs4 import BeautifulSoup
import scrapy
from Boss.items import BossItem
from Boss.settings import USER_AGENT
from scrapy.linkextractors import LinkExtractor chrome_options = Options()
driver = webdriver.Chrome() class BossSpider(scrapy.Spider):
name = 'boss'
allowed_domains = ['www.zhipin.com']
start_urls = ['http://www.zhipin.com/'] headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'www.zhipin.com',
'Origin': 'www.zhipin.com',
'Referer': 'http://www.zhipin.com/',
'User-Agent': USER_AGENT,
'X-Requested-With': 'XMLHttpRequest',
} def start_requests(self):
driver.get(
self.start_urls[0]
)
time.sleep(3) #搜索python爬虫
driver.find_element_by_name('query').send_keys(u'python爬虫')
time.sleep(3)
driver.find_element_by_class_name('btn-search').click()
time.sleep(3) new_url = driver.current_url.encode('utf8') #获取跳转之后的url
yield scrapy.Request(new_url) def parse(self, response):
#提取网页链接url
links = LinkExtractor(restrict_css="div.info-primary>h3>a")
link = links.extract_links(response)
for each_link in link:
yield scrapy.Request(each_link.url,callback=self.job_detail) #sels = LinkExtractor(restrict_css='div.page')
#yield scrapy.Request(sels.extract_links(response)[0].url,callback=self.parse) def job_detail(self,response):
spiderItem = BossItem()
#想要提取的信息
spiderItem['job_title'] = response.css('div.job-primary.detail-box div.name h1::text').extract()[0]
#pdb.set_trace()
salar = response.css('div.job-primary.detail-box span.badge ::text').extract()[0]
spiderItem['salary'] = re.findall(r'(\d.*?)\n',salar)[0] #re提取金额
spiderItem['address'] = response.css('div.job-primary.detail-box p::text').extract()[0]
spiderItem['job_time'] = response.css('div.job-primary.detail-box p::text').extract()[1]
spiderItem['education'] = response.css('div.job-primary.detail-box p::text').extract()[2]
spiderItem['company'] = response.css('div.job-primary.detail-box div.info-company h3.name a::text').extract()[0]
spiderItem['company_info'] = response.css('div.job-primary.detail-box div.info-company>p::text').extract()[0] detail = response.css('div.job-sec div.text ::text').extract()
details = ''.join(detail).replace(' ','') ##将列表内所有字符串提取成一个整的字符串,并且去除空格
spiderItem['detail_text'] = details print spiderItem
yield spiderItem
scrapy--boss直聘的更多相关文章
- 爬虫系列---scrapy post请求、框架组件和下载中间件+boss直聘爬取
一 Post 请求 在爬虫文件中重写父类的start_requests(self)方法 父类方法源码(Request): def start_requests(self): for url in se ...
- Scrapy 爬取BOSS直聘关于Python招聘岗位
年前的时候想看下招聘Python的岗位有多少,当时考虑目前比较流行的招聘网站就属于boss直聘,所以使用Scrapy来爬取下boss直聘的Python岗位. 1.首先我们创建一个Scrapy 工程 s ...
- Python爬虫——Scrapy整合Selenium案例分析(BOSS直聘)
概述 本文主要介绍scrapy架构图.组建.工作流程,以及结合selenium boss直聘爬虫案例分析 架构图 组件 Scrapy 引擎(Engine) 引擎负责控制数据流在系统中所有组件中流动,并 ...
- Python的scrapy之爬取boss直聘网站
在我们的项目中,单单分析一个51job网站的工作职位可能爬取结果不太理想,所以我又爬取了boss直聘网的工作,不过boss直聘的网站一次只能展示300个职位,所以我们一次也只能爬取300个职位. jo ...
- scrapy——7 scrapy-redis分布式爬虫,用药助手实战,Boss直聘实战,阿布云代理设置
scrapy——7 什么是scrapy-redis 怎么安装scrapy-redis scrapy-redis常用配置文件 scrapy-redis键名介绍 实战-利用scrapy-redis分布式爬 ...
- Pyhton爬虫实战 - 抓取BOSS直聘职位描述 和 数据清洗
Pyhton爬虫实战 - 抓取BOSS直聘职位描述 和 数据清洗 零.致谢 感谢BOSS直聘相对权威的招聘信息,使本人有了这次比较有意思的研究之旅. 由于爬虫持续爬取 www.zhipin.com 网 ...
- 基于‘BOSS直聘的招聘信息’分析企业到底需要什么样的PHP程序员
原文地址:http://www.jtahstu.com/blog/scrapy_zhipin_php.html 基于'BOSS直聘的招聘信息'分析企业到底需要什么样的PHP程序员 标签(空格分隔): ...
- iOS开发之功能模块--高仿Boss直聘的IM界面交互功能
本人公司项目属于社交类,高仿Boss直聘早期的版本,现在Boss直聘界面风格,交互风格都不如Boss直聘以前版本的好看. 本人通过iPhone模拟器和本人真机对聊,将完成的交互功能通过Mac截屏模拟器 ...
- iOS开发之功能模块--高仿Boss直聘的常用语的开发
首先上Boss直聘的功能界面截图,至于交互请读者现在Boss直聘去交互体验: 本人的公司项目要高仿Boss直聘的IM常用语的交互功能,居然花费了我前后17个小时完成,这回自己测试了很多遍,代码 ...
- 使用VUE模仿BOSS直聘APP
一.碎碎念: 偶尔在群里看到一个小伙伴说:最近面试的人好多都说用vue做过一个饿了么.当时有种莫名想笑. 为何不知道创新一下?于是想写个DEMO演练一下.那去模仿谁呢?还是BOSS直聘(跟我没关系,不 ...
随机推荐
- DB2错误码大全
sqlcode sqlstate 说明 000 00000 SQL语句成功完成 01xxx SQL语句成功完成,但是有警告 +012 01545 未限定的列名被解释为一个有相互关系的引用 +098 0 ...
- EasyUI 数据网格 - 设置排序并自定义排序
数据网格(DataGrid)的所有列可以通过点击列表头来排序.您可以定义哪列可以排序.默认的,列是不能排序的,除非您设置 sortable 属性为 true. 当排序时,数据网格(DataGrid)将 ...
- mysql-数据库模式定义语言(DDL)
库的管理 /* 一.库的管理 创建.修改.删除 二.表的管理 创建.修改.删除 创建: create 修改: alter 删除: drop */ #一.库的管理 #.库的创建 /* 语法: creat ...
- 我的Android开发之路——百度地图开源工具获取定位信息
定位技术在现在的移动设备上是必不可少的,许多app都会使用定位功能. 通常定位方式有两种:GPS定位:网络定位. Android系统对这两种定位方式都提供了相应的API支持,但是因为google的网络 ...
- 关于java@Override错误
重写的接口的方法,编译的时候一直报@override is not override a method from superclass,查了一下资料,这个@override报错是因为版本的原因. 在J ...
- 笨办法学Python(三十三)
习题 33: While 循环 接下来是一个更在你意料之外的概念: while-loop``(while 循环).``while-loop 会一直执行它下面的代码片段,直到它对应的布尔表达式为 Fal ...
- Leetcode back(215) to be continue
solution discussion https://leetcode.com/problems/kth-largest-element-in-an-array/description/ -- 21 ...
- Selenium入门11 滚动条控制(通过js)
这一节要有js基础.做web端的UI自动化必须要有html,css,javascript前端基础. 滚动条控制: 1 移动垂直滚动条 document.documentElement.scrollTo ...
- 【PHP 模板引擎】Prototype 原型版发布!
在文章的开头,首先要向一直关注我的人说声抱歉!因为原本是打算在前端框架5.0发布之后,就立马完成 PHP 模板引擎的初版.但我没能做到,而且一直拖到了15年元旦才完成,有很严重的拖延症我很惭愧,再次抱 ...
- IOS 拦截所有push进来的子控制器
/** * 能拦截所有push进来的子控制器 */ - (void)pushViewController:(UIViewController *)viewController animated:(BO ...