python网络爬虫之scrapy 调试以及爬取网页
Shell调试:
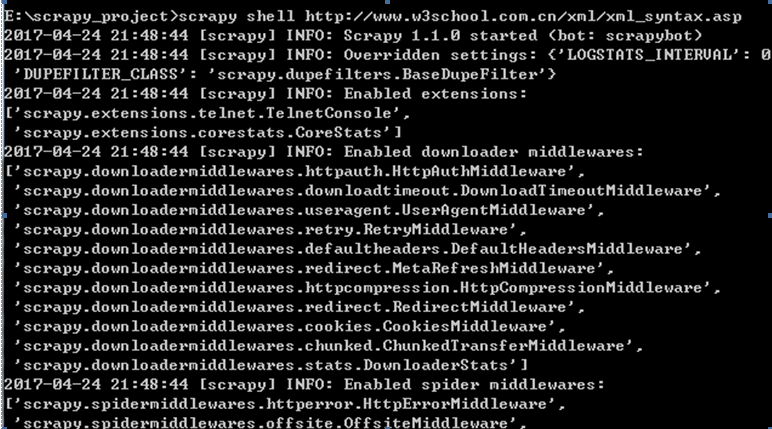
进入项目所在目录,scrapy shell “网址”
如下例中的:
scrapy shell http://www.w3school.com.cn/xml/xml_syntax.asp
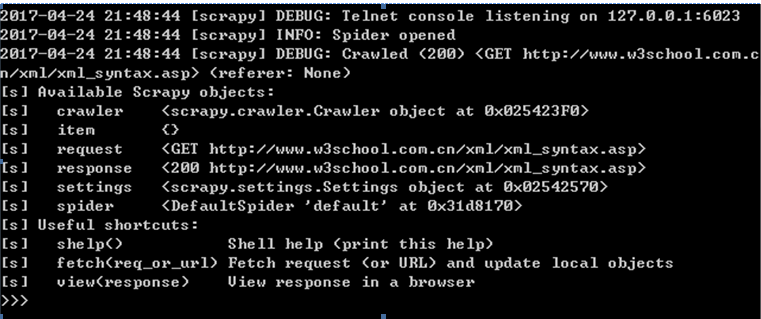
可以在如下终端界面调用过程代码如下所示:

相关的网页代码:

我们用scrapy来爬取一个具体的网站。以迅读网站为例。
如下是首页的内容,我想要得到文章列表以及对应的作者名称。
首先在items.py中定义title, author. 这里的Test1Item和Django中的modul作用类似。这里可以将Test1Item看做是一个容器。这个容器继承自scrapy.Item.
而Item又继承自DictItem。因此可以认为Test1Item就是一个字典的功能。其中title和author可以认为是item中的2个关键字。也就是字典中的key
class Item(DictItem):
class Test1Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=Field()
author=Field()
下面就在test_spider.py中开始写网页解析代码
from scrapy.spiders import Spider
from scrapy.selector import Selector
from test1.items import Test1Item
class testSpider(Spider):
name="test1" #这里的name必须和创建工程的名字一致,否则会提示找不到爬虫项目
allowd_domains=['http://www.xunsee.com']
start_urls=["http://www.xunsee.com/"]
def parse(self, response):
items=[]
sel=Selector(response)
sites = sel.xpath('//*[@id="content_1"]/div') #这里是所有数据的入口。下面所有的div都是存储的文章列表和作者
for site in sites:
item=Test1Item()
title=site.xpath('span[@class="title"]/a/text()').extract()
h=site.xpath('span[@class="title"]/a/@href').extract()
item['title']=[t.encode('utf-8') for t in title]
author=site.xpath('span[@class="author"]/a/text()').extract()
item['author']=[a.encode('utf-8') for a in author]
items.append(item)
return items
获取到title以及author的内容后,存储到item中。再将所有的item存储在items的列表中
在pipelines.py中修改Test1Pipeline如下。这个类中实现的是处理在testSpider中返回的items数据。也就是存储数据的地方。我们将items数据存储到json文件中去
class Test1Pipeline(object):
def __init__(self):
self.file=codecs.open('xundu.json','wb',encoding='utf-8')
def process_item(self, item, spider):
line=json.dumps(dict(item)) + '\n'
self.file.write(line.decode("unicode_escape"))
return item
工程运行后,可以看到在目录下生成了一个xundu.json文件。其中运行日志可以在log文件中查看

从这个爬虫可以看到,scrapy的结构还是比较简单。主要是三步:
1 items.py定义内容存储的关键字
2 自定义的test_spider.py中进行网页数据的爬取并返回数据
3 pipelines.py中对tes_spider.py中返回的内容进行存储
python网络爬虫之scrapy 调试以及爬取网页的更多相关文章
- 爬虫(二)Python网络爬虫相关基础概念、爬取get请求的页面数据
什么是爬虫 爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程. 哪些语言可以实现爬虫 1.php:可以实现爬虫.php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆 ...
- 【Python网络爬虫四】通过关键字爬取多张百度图片的图片
最近看了女神的新剧<逃避虽然可耻但有用>,同样男主也是一名程序员,所以很有共鸣 被大只萝莉萌的一脸一脸的,我们来爬一爬女神的皂片. 百度搜索结果:新恒结衣 本文主要分为4个部分: 1.下载 ...
- Python网络爬虫第三弹《爬取get请求的页面数据》
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- Python网络爬虫案例(二)——爬取招聘信息网站
利用Python,爬取 51job 上面有关于 IT行业 的招聘信息 版权声明:未经博主授权,内容严禁分享转载 案例代码: # __author : "J" # date : 20 ...
- [Python]网络爬虫(一):抓取网页的含义和URL基本构成
一.网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字. 把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛.网络蜘蛛是通过网页的链接地址来寻找网页的. 从网站某一个 ...
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- Python使用urllib,urllib3,requests库+beautifulsoup爬取网页
Python使用urllib/urllib3/requests库+beautifulsoup爬取网页 urllib urllib3 requests 笔者在爬取时遇到的问题 1.结果不全 2.'抓取失 ...
- python网络爬虫之scrapy 工程创建以及原理介绍
执行scrapy startproject XXXX的命令,就会在对应的目录下生成工程 在pycharm中打开此工程目录:并在Run中选择Edit Configuration 点击+创建一个Pytho ...
- 16.Python网络爬虫之Scrapy框架(CrawlSpider)
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
随机推荐
- AndroidStudio快捷键大全
很多近期学习移动开发的朋友都是通过Eclipse集成ADT开发安卓程序.但是谷歌已经推出了自己的亲儿子--Android Studio.可以说比原来的开发工具强大很多,现在各大公司也已经逐渐淘汰了Ec ...
- 使用JMeter录制手机App脚本
Apache JMeter是100%的Java桌面应用程序,用于对软件做压力测试.它最初被设计用于Web应用测试,但后来扩展到其他测试领域.现如今这款软件越来越受到测试人员的青睐,相比于LoadRun ...
- functools.wraps
我们在使用 Decorator 的过程中,难免会损失一些原本的功能信息.直接拿 stackoverflow 里面的栗子 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ...
- C语言中使用库函数解析命令行参数
在编写需要命令行参数的C程序的时候,往往我们需要先解析命令行参数,然后根据这些参数来启动我们的程序. C的库函数中提供了两个函数可以用来帮助我们解析命令行参数:getopt.getopt_long. ...
- css3中的新特性经典应用
这篇文章主要分析css3新特性的典型应用,都是干活,没得水分. 1.动画属性:animation. 利用animation可以实现元素的动画效果,他是一个简写属性,用于设置6个动画属性:aminati ...
- 定制一个类似地址选择器的view
代码地址如下:http://www.demodashi.com/demo/12832.html 前言: 这几天也是闲来无事,看看有什么和Scroller相关的控件需要巩固下,原因很简单,前几天看到相关 ...
- (十)Thymeleaf用法——Themeleaf内联
5. 内联 [[...]]是内联文本的表示格式,但需要使用th:inline属性(分为text,javascript,none)激活. 5.1 文本内联 <p th:inline=&quo ...
- java 乱码问题解决思路
"编码一致的条件下,在处理运行正常的情况下,是不会出现乱码的",记住这句金言. 如上所说,如果编码一致是不会出现这种乱码问题,所以解决办法就是仔细再仔细的检查所设置的编码是否是一致 ...
- xcode 项目证书跟签名都正确的时候,还报证书错误
原因,安装证书错误,导致无法匹配证书, 方案:删除原来的证书,重新安装 打开终端 1.cd Library/ 2.cd MobileDevice/ 3.open Provisioning\ Profi ...
- 01-2制作U盘启动盘--装机助理工具
在可以上网的电脑上执行制作启动盘的操作: 打开浏览器输入:http://www.zhuangjizhuli.com/upan.html 1.制作U盘启动盘: 2.下载 装机助理 软件 3.步骤: 第一 ...