【Kafka】《Kafka权威指南》入门
发布与订阅消息系统
在正式讨论Apache Kafka (以下简称Kafka)之前,先来了解发布与订阅消息系统的概念, 并认识这个系统的重要性。数据(消息)的发送者(发布者)不会直接把消息发送给接收 者,这是发布与订阅消息系统的一个特点。发布者以某种方式对消息进行分类,接收者 (订阅者)订阅它们,以便接收特定类型的消息。发布与订阅系统一般会有一个 broker,也就是发布消息的中心点。
发布与订阅消息系统的大部分应用场景都是从一个简单的消息队列或一个进程间通信开始的。比如电商系统中,包含会员模块、订单模块、商品模块、推荐模块、配送物流模块等,多个模块(子系统)间涉及消息的传递。
最早的应用解决方案就是采用(子系统间)直连的方式,使得很多子系统交错复杂。这种点对点的连接方式,形成网状的连接,弊端很多,不一一赘述。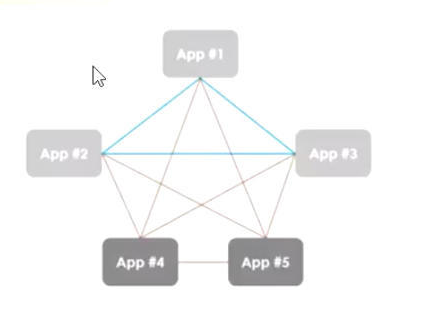
后来,为了解决子系统间直连交错的问题,出现了队列系统。下图所示的架构包含了 3 个独立的发布与订阅系统。

这种方式比直接使用点对点的连接要好得多,但这里有太多重复的地方。你的公司因此要为数据队列维护多个系统,每个系统又有各自的缺陷和不足。而且,接下来可能会有更多的场景需要用到消息系统。 此时,你真正需要的是一个单一的集中式系统,它可以用来发布通用类型的数据,其规模可以随着公司业务的增长而增长。这时Kafka登场了。
Kafka登场
Kafka就是为了解决上述问题而设计的一款基于发布与订阅的消息系统。它一般被称为 “分布式提交日志”或者“分布式流平台”。文件系统或数据库提交日志用来提供所有事务 的持久记录 , 通过重放这些日志可以重建系统的状态。同样地, Kafka 的数据是按照 一定顺序持久化保存的,可以按需读取 。 此外, Kafka 的数据分布在整个系统里,具备数据故障保护和性能伸缩能力。
消息和批次
Kafka的数据单元被称为消息。如果你在使用 Kafka之前已经有数据库使用经验,那么可 以把消息看成是数据库里的一个“数据行”或一条“记录”。消息由字节数组组成,所以 对于 Kafka来说,消息里的数据没有特别的格式或含义。消息可以有一个可选的元数据, 也就是键(key)。键也是一个字节数组,与消息一样,对于 Kafka来说也没有特殊的含义。 当消息以一种可控的方式写入不同的分区时,会用到键。最简单的例子就是为键生成一个一致 性散列值,然后使用散列值对主题分区数进行取模,为消息选取分区 。这样可 以保证具有 相同键的消息总是被写到相同的分区上。
为了提高效率,消息被分批次写入 Kafka。 批次就是一组消息,这些消息属于同一个主题 和分区。如果每一个消息都单独穿行于网络,会导致大量的网络开销,把消息分成批次传 输可以减少网络开销。不过,这要在时间延迟和吞吐量之间作出权衡;批次越大,单位时间内处理的消息就越多,单个消息的传输时间就越长。批次数据会被压缩,这样可以提升 数据的传输和存储能力,但要做更多的计算处理。
主题(topic)和分区(partition)
Kafka 的悄息通过 主题进行分类。主题就好比数据库的表,或者文件系统里的文件夹。主题可以被分为若干个分区 , 一个分区就是一个提交日志。消息以追加的方式写入分区,然后以先入先出的顺序读取。要注意,由于一个主题一般包含几个分区,因此无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。下图 所示的主题有 4 个分区,消息被迫加写入每个分区的尾部。 Kaflca通过分区来实现数据冗余和伸缩性。分区可以分布在不同的服务器上,也就是说, 一个主题可以横跨多个服务器,以此来提供比 单个服务器更强大的性能。

我们通常会使用流这个词来描绘Kafka这类系统对数据。很多时候,人们把一个主题的数据看成一个流,不管它有多少个分区。流是一组从生产者移动到消费者的数据。当我们讨 论流式处理时,一般都是这样描述消息的。 Kaflca Streams、 Apache Samza 和 Storm 这些框 架以实时的方式处理消息,也就是所谓的流式处理。我们可以将流式处理与离线处理进行比较,比如 Hadoop 就是被设计用于在稍后某个时刻处理大量的数据。
生产者和消费者
Kafka 的客户端就是 Kafka 系统的用户,它们被分为两种基本类型 : 生产者和消费者。除此之外,还有其他高级客户端 API——用于数据集成的 Kaflca Connect API 和用于流式处理 的 Kaflca Streams。这些高级客户端 API 使用生产者和消费者作为内部组件,提供了高级的 功能。
生产者创建消息。在其他发布与订阅系统中,生产者可能被称为发布者或写入者。一般情 况下,一个消息会被发布到一个特定的主题(topic)上。生产者在默认情况下把消息均衡地分布到主题的所有分区上,而并不关心特定消息会被写到哪个分区。不过,在某些情况下,生产者会把消息直接写到指定的分区。这通常是通过消息键和分区器来实现的,分区器为键生 成一个散列值,并将其映射到指定的分区上。这样可以保证包含同一个键的消息会被写到 同一个分区上。生产者也可以使用自定义的分区器,根据不同的业务规则将消息映射到分 区。下一章将详细介绍生产者。
消费者读取消息。在其他发布与订阅系统中,消费者可能被称为订阅者或读者 。 消费者订阅一个或多个主题,并按照消息生成的顺序读取它们。消费者通过检查消息的偏移盘来区 分已经读取过的消息。 偏移量是另一种元数据,它是一个不断递增的整数值,在创建消息 时, Kafka 会把它添加到消息里。在给定的分区里,每个悄息的偏移量都是唯 一 的。消费 者把每个分区最后读取的悄息偏移量保存在 Zookeeper或 Kafka上,如果悄费者关闭或重 启,它的读取状态不会丢失。
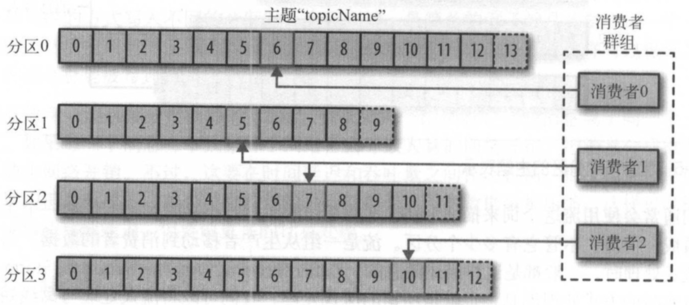
消费者是消费者群组的一部分,也就是说,会有一个或多个消费者共同读取一个主题。 群组保证每个分区只能被一个消费者使用 。下图所示的群组中,有 3 个消费者同时读取一 个主题。其中的两个消费者各自读取一个分区,另外一个消费者读取其他两个分区。消费 者与分区之间的映射通常被称为悄费者对分区的所有权关系 。
通过这种方式,消费者可以消费包含大量消息的主题。而且,如果一个消费者失效,群组 里的其他消费者可以接管失效悄费者的工作。第 4章将详细介绍消费者和悄费者群组。
broker和集群
一个独立的 Kafka服务器被称为 broker。 broker接收来自 生产者的消息,为消息设置偏移 量,并提交消息到磁盘保存。 broker 为消费者提供服务,对读取分区的请求作出响应,返 回已经提交到磁盘上的消息。根据特定的硬件及其性能特征,单个 broker可以轻松处理数 千个分区以及每秒百万级的消息量。
Broker可以看作是消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群。
broker是集群的组成部分。每个集群都有一个 broker 同时充当了集群控制器的角色(自动 从集群的活跃成员中选举出来)。控制器负责管理工作,包括将分区分配给 broker和监控 broker. 在集群中, 一个分区从属于一个 broker, i亥 broker被称为分区的首领。一个分区 可以分配给多个 broker,这个时候会发生分区复制(见下图)。这种复制机制为分区提供 了消息冗余,如果有一个 broker失效,其他 broker可以接管领导权。不过,相关的消费者 和生产者都要重新连接到新的首领。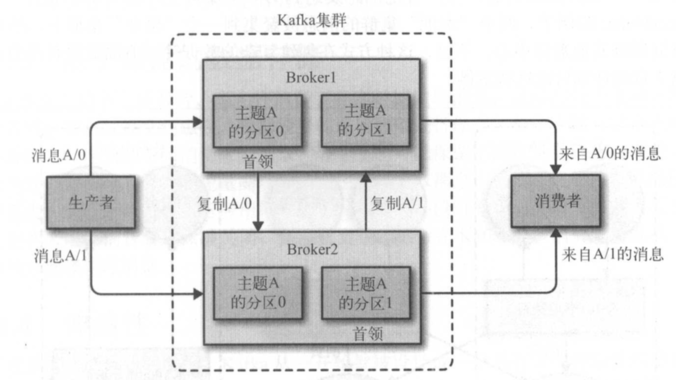
保留消息(在一定期限内)是 Kafka的一个重要特性。 Kafka broker默认的消息保留策略 是这样的:要么保留一段时间(比如 7天),要么保留到消息达到一定大小的字节数(比 如 1GB)。当消息数量达到这些上限时,旧消息就会过期井被删除,所以在任何时刻, 可 用消息的总量都不会超过配置参数所指定的大小。主题可以配置自己的保留策略,可以将 悄息保留到不再使用它们为止。例如,用于跟踪用户活动的数据可能需要保留几天,而应 用程序的度量指标可能只需要保留几个小时。可以通过配置把主题当作 紧凑型日志, 只有 最后一个带有特定键的消息会被保留下来。这种情况对于变更日志类型的数据来说比较适 用,因为人们只关心最后时刻发生的那个变更。
为什么选择 Kafka
多个生产者
Kafka 可以无缝地支持多个生产者,不管客户端在使用单个 主题还是多个主题。所以它很 适合用来从多个前端系统收集数据,并以统一的格式对外提供数据。例如, 一个包含了 多 个微服务的网站,可以为页面视图创建一个单独的主题,所有服务都以相同的消息格式向 该主题写入数据。消费者应用程序会获得统一的页面视图,而无需协调来自不同生产者的 数据流。
多个消费者
除了支持多个生产者外, Kafka也支持多个消费者从一个单独的消息流上读取数据,而且 消费者之间直不影响。这与其他队列系统不同,其他队列系统的消息一旦被一个客户端读 取,其他客户端就无法再读取它。另外,多个消费者可以组成一个群组,它们共享一个消息流,并保证整个群组对每个给定的消息只处理一次。
基于磁盘的数据存储
Kafka不仅支持多个消费者,还允许消费者非实时地读取消息,这要归功于 Kafka的数据 保留特性。?肖息被提交到磁盘,根据设置的保留规则进行保存。每个主题可以设置单独的 保留规则,以便满足不同消费者的需求,各个主题可以保留不同数量的消息。消费者可能 会因为处理速度慢或突发的流量高峰导致无陆及时读取消息,而持久化数据可以保证数据 不会丢失。?肖费者可以在进行应用程序维护时离线一小段时间,而无需担心消息丢失或堵 塞在生产者端。 消费者可以被关闭,但消息会继续保留在 Kafka里。消费者可以从上次中 断的地方继续处理消息。
伸缩性
为了能够轻松处理大量数据, Kafka 从一开始就被设计成一个具有灵活伸缩性的系统。用 户在开发阶段可以先使用单个 broker,再扩展到包含 3 个 broker 的小型开发集群,然后随 着数据盐不断增长,部署到生产环境的集群可能包含上百个 broker。对在线集群进行扩展 丝毫不影响整体系统的可用性。也就是说, 一个包含多个 broker的集群,即使个别 broker 失效,仍然可以持续地为客户提供服务。要提高集群的容错能力,需要配置较高的复制系 数。
高性能
上面提到的所有特性,让 Kafka成为了一个高性能的发布与订阅消息系统。通过横向扩展 生产者、消费者和 broker, Kafka可以轻松处理巨大的消息流。在处理大量数据的同时, 它还能保证亚秒级的消息延迟。
【Kafka】《Kafka权威指南》入门的更多相关文章
- elasticsearch 权威指南入门阅读笔记(一)
相关文档 esapi:https://es.xiaoleilu.com/010_Intro/10_Installing_ES.html https://esdoc.bbossgroups.co ...
- Kafka权威指南——broker的常用配置
前面章节中的例子,用来作为单个节点的服务器示例是足够的,但是如果想要把它应用到生产环境,就远远不够了.在Kafka中有很多参数可以控制它的运行和工作.大部分的选项都可以忽略直接使用默认值就好,遇到一些 ...
- 《Kafka权威指南》读书笔记-操作系统调优篇
<Kafka权威指南>读书笔记-操作系统调优篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 大部分Linux发行版默认的内核调优参数配置已经能够满足大多数应用程序的运 ...
- 【Kafka】《Kafka权威指南》——分区partition
在上篇的例子里([Kafka]<Kafka权威指南>--写数据), ProducerRecord 对象包含了目标主题.键和值. Kafka 的消息是 一个个 键值对, ProducerRe ...
- 【转】Spark Streaming和Kafka整合开发指南
基于Receivers的方法 这个方法使用了Receivers来接收数据.Receivers的实现使用到Kafka高层次的消费者API.对于所有的Receivers,接收到的数据将会保存在Spark ...
- Spark Streaming和Kafka整合开发指南(二)
在本博客的<Spark Streaming和Kafka整合开发指南(一)>文章中介绍了如何使用基于Receiver的方法使用Spark Streaming从Kafka中接收数据.本文将介绍 ...
- kafka技术分享02--------kafka入门
kafka技术分享02--------kafka入门 1. 消息系统 所谓的Messaging System就是一组规范,企业利用这组规范在不同的系统之间传递语义准确对的消息,实现松耦合的异步数据 ...
- ELK+KAFKA安装部署指南
一.ELK 背景 通常,日志被分散的储存不同的设备上.如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志.这样是不是感觉很繁琐和效率低下.当务之急我们使用集中化的日志管理,例如: ...
- netty权威指南学习笔记二——netty入门应用
经过了前面的NIO基础知识准备,我们已经对NIO有了较大了解,现在就进入netty的实际应用中来看看吧.重点体会整个过程. 按照权威指南写程序的过程中,发现一些问题:当我们在定义handler继承Ch ...
- ARM Cortex-M0权威指南高清中文版pdf免费分享下载
版 次:1 页 数:433 字 数:655000 印刷时间:2013-8-1 开 本:16开 纸 张:胶版纸 印 次:1 包 装:平装 丛书名:清华开发者书库 国际标准书号ISBN:978730233 ...
随机推荐
- 2018.5.31 nRF905 test
1 试电机:自动控制测试流程(Labview程序,加载扫描仪,自动测试夹具,测试数据保存) 2 USB RF收发器: 含S/N码发送读取功能(S/N:) The specific use please ...
- eslipse 修改tomcat server location 解决HTTP Status 404 – Not Found
Eclipse中tomcat service设置选择window ----show view---services可以看到服务的面板双击tomcat进入配置界面Service Locations(Sp ...
- Excel文本获取拼音
[说明] 版本:Excel 2010 文件后缀:.xls 有在.xlsb文件下使用未成功.建议使用.xls后缀. 1.调出“开发工具” 步骤:文件-->选项-->自定义功能区-->勾 ...
- bzoj 3158 千钧一发 —— 最小割
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=3158 \( a[i] \) 是奇数则满足条件1,是偶数则显然满足条件2: 因为如果把两个奇数 ...
- SSH不允许Root登陆的方法
不允许Root登陆的方法如下: vim /etc/ssh/sshd_config 把PermitRootLogin yes 改成: PermitRootLogin no 然后重启sshd服务: Ser ...
- MySQL(介绍1)
数据库(Database)是按照数据结构来组织.存储和管理数据的仓库: 也可以将数据存储在文件中,但是在文件中读写数据速度相对较慢. 在WEB应用方面MySQL是最好的RDBMS(Relational ...
- GIF助手激活教程(购买+激活)图文版
GIF助手首页==>设置(右上角) ==>输入激活码会弹出购买或者激活的对话框.(如果不明白操作,可以点击如何购买激活码先查看购买帮助指南再进行购买) 点击复制设备码并购买. 此时会进入到 ...
- javadoc 工具生成开发API文档
=====================先来一点成就感===================== package com.springMybatis.dao; import com.springMy ...
- File 类 操作实例
File 操作 <介绍> 尽管java.io定义的大多数类是实行流式操作的,File类不是.它直接处理文件和文件系统.也就是说,File类没有指定信息怎样从文件读取或向文件存储:它描述了文 ...
- 字符串(String)
字符串是由字符组成的数组,但在JavaScript中字符串是不可变的:可以访问字符串任意位置的文本,但是JavaScript并未提供修改已知字符串内容的方法. 常见功能: obj.length ...