NameNode内存优化---基于缓存相同文件名的方法
1. Hadoop中有多少文件的文件名是重复的?
| File names used > 100000 times | 24 |
| File names used between 10001 to 100000 times | 467 |
| File names used between 1001 to 10000 times | 4335 |
| File names used between 101 to 1000 times | 40031 |
| File names used between 10 to 100 times | 403975 |
| File names used between 2 to 9 times | 606579 |
| File names used between 1 times | 4114531 |
| Total file names | 5169942 |
从上表能够看出有516万的文件中有大约100万的文件重复了,在这重复的100万中又有40多万的文件名被重复用了10次以上,所以说文件名相同的情况还是很频繁的。
2. 如果缓存文件名大概能节省多少内存?
bin/hadoop oiv -i fsimage_0000000015589116819 -o ovils -p NameDistribution Total unique file names 241275868
21 names are used by 2620832 files between 100000-214114 times. Heap savings ~89107574 bytes.
634 names are used by 20434805 files between 10000-99999 times. Heap savings ~703887328 bytes.
7593 names are used by 19447534 files between 1000-9999 times. Heap savings ~734908710 bytes.
49057 names are used by 16697480 files between 100-999 times. Heap savings ~729947272 bytes.
399464 names are used by 7812965 files between 10-99 times. Heap savings ~381085471 bytes.
638085 names are used by 4261035 files between 5-9 times. Heap savings ~223499710 bytes.
628335 names are used by 2513340 files 4 times. Heap savings ~118476621 bytes.
2550503 names are used by 7651509 files 3 times. Heap savings ~319960524 bytes.
3698086 names are used by 7396172 files 2 times. Heap savings ~230703725 bytes. Total saved heap ~3531576935bytes.
通过分析fsimage,可以减少3531576935bytes=3.289g的内存空间,还是很可观的
3. 代码实现
public class ByteArray {
private int hash = 0; // 字节数组的hashcode
private final byte[] bytes;
public ByteArray(byte[] bytes) {
this.bytes = bytes;
}
public byte[] getBytes() {
return bytes;
}
@Override
public int hashCode() {
if (hash == 0) {
hash = Arrays.hashCode(bytes);
}
return hash;
}
@Override
public boolean equals(Object o) {
if (!(o instanceof ByteArray)) {
return false;
}
return Arrays.equals(bytes, ((ByteArray)o).bytes);
}
}
有了缓存项,还要有管理缓存项的缓存类NameCache,NameCache有两个重要的成员cache和transientMap,transientMap用来记录每个文件名被使用的次数,每次addFile时,先把文件名放入transientMap,当文件被重用的次数大于一个阀值时(dfs.namenode.name.cache.threshold配置项),文件名从transientMap 迁移到cache对象中。NameCache中最重要的方法是 K put(final K name),在该方法中,首先检查cache,如果cache中已经缓存了文件名,那么直接返回cache中的文件名;如果cache中没有那么先把文件名放入transientMap,文件的重用次数加1,如果加1后大于阀值,则执行void promote(final K name)方法,该方法中将transientMap中的对应项remove掉,然后放到cache中。该过程的时序图如下所示:
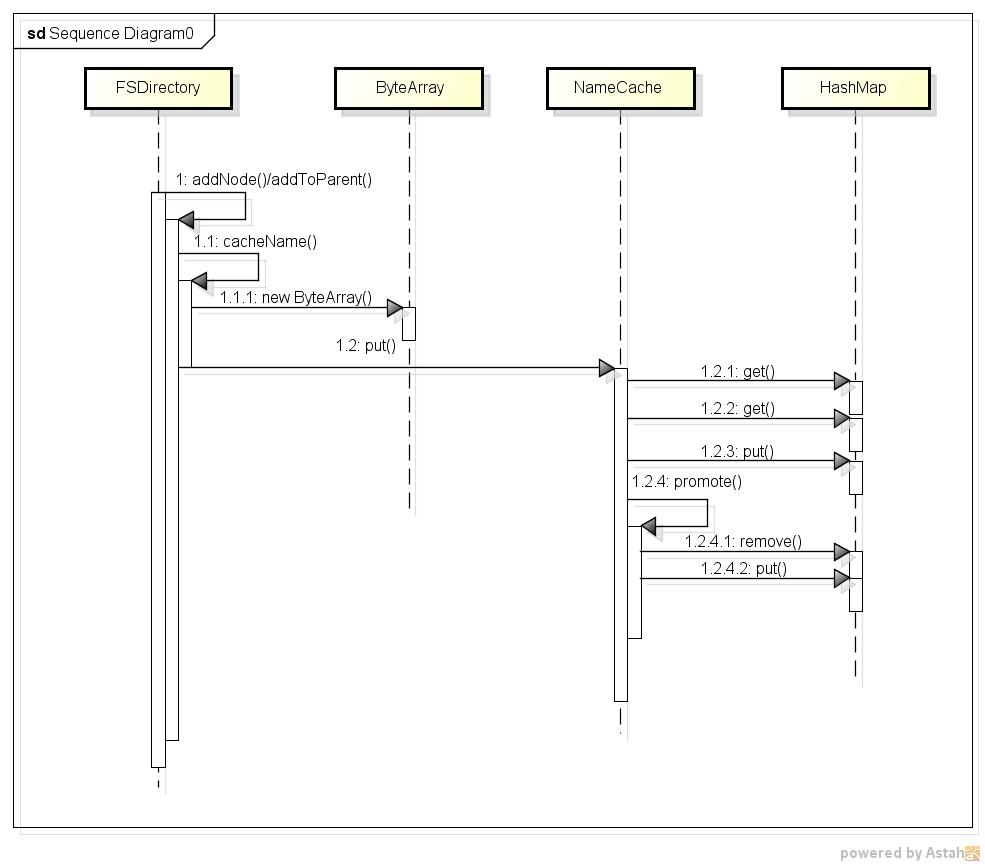
查看大图:大图
需要注意的是HashMap相关方法的调用,并不是每次都调用所有的HashMap的方法。
1. 当cache中已经缓存了文件名,则直接返回,这个过程只调用了一次get方法;
2. 当cache中没有缓存文件名(判断过程调用一次get),并且transientMap中也没有这个文件名(判断过程再一次调用get),则向transientMap中put文件名和使用次数(调用一次put),共计2次get,1次put;
3. 当cache中没有缓存文件名(判断过程调用一次get),并且transientMap中也有这个文件名(判断过程再一次调用get)时,把transientMap中的对应文件名的的重用次数加1,如果文件名重用次数小于阀值不大于阀值则返回,共计调用2次get;
4. 当cache中没有缓存文件名(判断过程调用一次get),并且transientMap中也有这个文件名(判断过程再一次调用get)时,把transientMap中的对应文件名的的重用次数加1,如果文件名重用次数大于等于阀值,则调用promotion,把transientMap中的对应项remove掉,并把该文件名put到cache中,此过程共计调用2次get,1次remove,1次put。
还需要注意的是boolean型成员initialized,代表NameNode是否加载完fsimage了,初值为false,当fsimage加载完并回放了editlog,会调用NameCache的initialized()方法,将其设置为true,代码如下:
// <K> name to be added to the cache
class NameCache<K> {
/**
* Class for tracking use count of a name
*/
private class UseCount {
int count;
final K value; // Internal value for the name UseCount(final K value) {
count = 1;
this.value = value;
} void increment() {
count++;
} int get() {
return count;
}
} static final Log LOG = LogFactory.getLog(NameCache.class.getName()); /** indicates initialization is in progress */
private boolean initialized = false; /** names used more than {@code useThreshold} is added to the cache */
private final int useThreshold; /** of times a cache look up was successful */
private int lookups = 0; /** Cached names */
final HashMap<K, K> cache = new HashMap<K, K>(); /** Names and with number of occurrences tracked during initialization */
Map<K, UseCount> transientMap = new HashMap<K, UseCount>(); /**
* Constructor
* @param useThreshold names occurring more than this is promoted to the
* cache
*/
NameCache(int useThreshold) {
this.useThreshold = useThreshold;
} /**
* Add a given name to the cache or track use count.
* exist. If the name already exists, then the internal value is returned.
*
* @param name name to be looked up
* @return internal value for the name if found; otherwise null
*/
K put(final K name) {
K internal = cache.get(name);
if (internal != null) {
lookups++;
return internal;
} // Track the usage count only during initialization
if (!initialized) {
UseCount useCount = transientMap.get(name);
if (useCount != null) {
useCount.increment();
if (useCount.get() >= useThreshold) {
promote(name);
}
return useCount.value;
}
useCount = new UseCount(name);
transientMap.put(name, useCount);
}
return null;
} /**
* Lookup count when a lookup for a name returned cached object
* @return number of successful lookups
*/
int getLookupCount() {
return lookups;
} /**
* Size of the cache
* @return Number of names stored in the cache
*/
int size() {
return cache.size();
} /**
* Mark the name cache as initialized. The use count is no longer tracked
* and the transient map used for initializing the cache is discarded to
* save heap space.
*/
void initialized() {
LOG.info("initialized with " + size() + " entries " + lookups + " lookups");
this.initialized = true;
transientMap.clear();
transientMap = null;
} /** Promote a frequently used name to the cache */
private void promote(final K name) {
transientMap.remove(name);
cache.put(name, name);
lookups += useThreshold;
} public void reset() {
initialized = false;
cache.clear();
if (transientMap == null) {
transientMap = new HashMap<K, UseCount>();
} else {
transientMap.clear();
}
}
}
最后在FSDrectory中添加一个NameCache类型成员,在addNode和addToParent方法中调用cacheName方法,在cacheName方法中用byte[]类型的文件名构造ByteArray实例,并调用nameCache的put方法,代码如下:
private <T extends INode> T addNode(String src, T child,
long childDiskspace)
throws QuotaExceededException, UnresolvedLinkException {
byte[][] components = INode.getPathComponents(src);
byte[] path = components[components.length-1];
child.setLocalName(path);
cacheName(child);
INode[] inodes = new INode[components.length];
writeLock();
try {
rootDir.getExistingPathINodes(components, inodes, false);
return addChild(inodes, inodes.length-1, child, childDiskspace);
} finally {
writeUnlock();
}
} INodeDirectory addToParent(byte[] src, INodeDirectory parentINode,
INode newNode, boolean propagateModTime) throws UnresolvedLinkException {
// NOTE: This does not update space counts for parents
INodeDirectory newParent = null;
writeLock();
try {
try {
newParent = rootDir.addToParent(src, newNode, parentINode,
propagateModTime);
cacheName(newNode);
} catch (FileNotFoundException e) {
return null;
}
if(newParent == null)
return null;
if(!newNode.isDirectory() && !newNode.isLink()) {
// Add file->block mapping
INodeFile newF = (INodeFile)newNode;
BlockInfo[] blocks = newF.getBlocks();
for (int i = 0; i < blocks.length; i++) {
newF.setBlock(i, getBlockManager().addBlockCollection(blocks[i], newF));
}
}
} finally {
writeUnlock();
}
return newParent;
} void cacheName(INode inode) {
// Name is cached only for files
if (inode.isDirectory() || inode.isLink()) {
return;
}
ByteArray name = new ByteArray(inode.getLocalNameBytes());
name = nameCache.put(name);
if (name != null) {
inode.setLocalName(name.getBytes());
}
}
}
4. 优化结果及分析
| 优化前 | 优化后 | |
| fsimage加载时间 | 898秒 | 1102秒 |
| Heap Used |
115.252G
|
112.148G |
5. 异步缓存

public class FSDirectoryNameCache {
// buffer this many elements in temporary queue
private static final int MAX_QUEUE_SIZE = 10000;
// actual cache
private final NameCache<ByteArray> nameCache;
private volatile boolean imageLoaded;
// initial caching utils
private ExecutorService cachingExecutor;
private List<Future<Void>> cachingTasks;
private List<INode> cachingTempQueue;
public FSDirectoryNameCache(int threshold) {
nameCache = new NameCache<ByteArray>(threshold);
imageLoaded = false;
// executor for processing temporary queue (only 1 thread!!)
cachingExecutor = Executors.newFixedThreadPool(1);
cachingTempQueue = new ArrayList<INode>(MAX_QUEUE_SIZE);
cachingTasks = new ArrayList<Future<Void>>();
}
/**
* Adds cached entry to the map and updates INode
*/
private void cacheNameInternal(INode inode) {
// Name is cached only for files
if (inode.isDirectory()) {
return;
}
ByteArray name = new ByteArray(inode.getLocalNameBytes());
name = nameCache.put(name);
if (name != null) {
inode.setLocalName(name.getBytes());
}
}
void cacheName(INode inode) {
if (inode.isDirectory()) {
return;
}
if (this.imageLoaded) {
// direct caching
cacheNameInternal(inode);
return;
}
// otherwise add it to temporary queue
cachingTempQueue.add(inode);
// if queue is too large, submit a task
if (cachingTempQueue.size() >= MAX_QUEUE_SIZE) {
cachingTasks.add(cachingExecutor
.submit(new CacheWorker(cachingTempQueue)));
cachingTempQueue = new ArrayList<INode>(MAX_QUEUE_SIZE);
}
}
/**
* Worker for processing a list of inodes.
*/
class CacheWorker implements Callable<Void> {
private final List<INode> inodesToProcess;
CacheWorker(List<INode> inodes) {
this.inodesToProcess = inodes;
}
@Override
public Void call() throws Exception {
for (INode inode : inodesToProcess) {
cacheNameInternal(inode);
}
return null;
}
}
/**
* Inform that from now on all caching is done synchronously.
* Cache remaining inodes from the queue.
* @throws IOException
*/
void imageLoaded() throws IOException {
if(cachingTasks == null) {
return;
}
for (Future<Void> task : cachingTasks) {
try {
task.get();
} catch (InterruptedException e) {
throw new IOException("FSDirectory cache received interruption");
} catch (ExecutionException e) {
throw new IOException(e);
}
}
// will not be used after startup
this.cachingTasks = null;
this.cachingExecutor.shutdownNow();
this.cachingExecutor = null;
// process remaining inodes
for(INode inode : cachingTempQueue) {
cacheNameInternal(inode);
}
this.cachingTempQueue = null;
this.imageLoaded = true;
}
void initialized() {
this.nameCache.initialized();
}
int size() {
return nameCache.size();
}
int getLookupCount() {
return nameCache.getLookupCount();
}
public void reset() {
nameCache.reset();
}
}
6. 异步实验结果及分析
加载淘宝云梯fsimage,测试结果如下所以:
| 优化前 | 同步cache | 异步cache | |
| fsimage加载时间 | 898秒 | 1102秒 | 956秒 |
| Heap Used | 115.252G | 112.148G | 112.147G |
NameNode内存优化---基于缓存相同文件名的方法的更多相关文章
- Unity内存优化
[Unity内存优化] 1.在Update方法或循环中,少用string类,因为string类的每次操作都会调用new生成新字符串对象.用StringBuilder代替string,StringBui ...
- 使用内存映射文件MMF实现大数据量导出时的内存优化
前言 导出功能几乎是所有应用系统必不可少功能,今天我们来谈一谈,如何使用内存映射文件MMF进行内存优化,本文重点介绍使用方法,相关原理可以参考文末的连接 实现 我们以单次导出一个excel举例(csv ...
- 如何用分布式缓存服务实现Redis内存优化
Redis是一种支持Key-Value等多种数据结构的存储系统,其数据特性是“ALL IN MEMORY”,因此优化内存十分重要.在对Redis进行内存优化时,先要掌握Redis内存存储的特性比如字符 ...
- 转 cocos2d-x 优化(纹理渲染优化、资源缓存、内存优化)
概述 包括以下5种优化:引擎底层优化.纹理优化.渲染优化.资源缓存.内存优化 引擎优化 2.0版本比1.0版本在算法上有所优化,效率更高.2.0版本使用OpenGl ES 2.0图形库,1.0版本 ...
- ANDROID内存优化——大汇总(转)
原文作者博客:转载请注明本文出自大苞米的博客(http://blog.csdn.net/a396901990),谢谢支持! ANDROID内存优化(大汇总——上) 写在最前: 本文的思路主要借鉴了20 ...
- 【腾讯Bugly干货分享】Android内存优化总结&实践
本文来自于腾讯Bugly公众号(weixinBugly),未经作者同意,请勿转载,原文地址:https://mp.weixin.qq.com/s/2MsEAR9pQfMr1Sfs7cPdWQ 导语 智 ...
- Hadoop:HDFS NameNode内存全景
原文转自:https://tech.meituan.com/namenode.html 感谢原作者 一.概述 从整个HDFS系统架构上看,NameNode是其中最重要.最复杂也是最容易出现问题的地方, ...
- HDFS NameNode内存详解
前言 <HDFS NameNode内存全景>中,我们从NameNode内部数据结构的视角,对它的内存全景及几个关键数据结构进行了简单解读,并结合实际场景介绍了NameNode可能遇到的问题 ...
- HDFS NameNode内存全景
一.概述 从整个HDFS系统架构上看,NameNode是其中最重要.最复杂也是最容易出现问题的地方,而且一旦NameNode出现故障,整个Hadoop集群就将处于不可服务的状态,同时随着数据规模和集群 ...
随机推荐
- 监听并保存ssh账号密码
有时候渗透搞下一台服务器的权限,想通过此服务器抓取其他服务器的ssh密码.就可以用以下方法,如果管理员通过这台服务器作为跳板登录其他服务器,密码就会记录下来. alias ssh='strace -o ...
- 【翻译自mos文章】在重建控制文件之前应该考虑的事情
在重建控制文件之前应该考虑的事情 来源于: Things to Consider Before Recreating the Controlfile (文档 ID 1475632.1) 适用于: Or ...
- MySQL5.7.26 忘记Root密码小计
以前直接修改mysql.user就ok了,现在不行了,正好虚拟机MySQL的root密码忘记了,就简单记录下:(本方法不适合互联网线上项目,除非你不在意这段时间的损失) PS:以UbuntuServe ...
- 搜索ABAP程序代码中的字符串
标准程序名:RPR_ABAP_SOURCE_SCAN /BEV1/NERM07DOCS
- ARDUINO W5100 WebServer测试
1.直接下载官方的enternet->WebServer代码 /* Web Server A simple web server that shows the value of the anal ...
- PAT 天梯赛 L2-003. 月饼 【贪心】
题目链接 https://www.patest.cn/contests/gplt/L2-003 思路 用贪心思路 最后注意一下 总售价有可能是浮点数 AC代码 #include <cstdio& ...
- Data Structure Binary Tree: Construct Tree from given Inorder and Preorder traversals
http://www.geeksforgeeks.org/construct-tree-from-given-inorder-and-preorder-traversal/ #include < ...
- 【leetcode刷题笔记】Permutations II
Given a collection of numbers that might contain duplicates, return all possible unique permutations ...
- mutation与action
mutation 作用: 更改state的状态 说明: 每个mutation对象都有字符串类型(type)与回调函数,在回调函数内进行状态修改,回调函数的第一个参数为state eg: mutatio ...
- 双向链表(C++实现)
////////////////////////////////////////////////////////////////////////////////////// /////// 这里建立两 ...