Apache Beam WordCount编程实战及源代码解读
概述:Apache Beam WordCount编程实战及源代码解读,并通过intellij IDEA和terminal两种方式调试执行WordCount程序,Apache Beam对大数据的批处理和流处理,提供一套先进的统一的编程模型,并能够执行大数据处理引擎上。完整项目Github源代码
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvZHJlYW1fYW4=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast" alt="Apache Beam WordCount编程实战及源代码解读" title="">
负责公司大数据处理相关架构,可是具有多样性,极大的添加了开发成本,急需统一编程处理,Apache Beam。一处编程,处处执行。故将折腾成果分享出来。
1.Apache Beam编程实战–前言,Apache Beam的特点与关键概念。
Apache Beam 于2017年1月10日成为Apache新的顶级项目。
1.1.Apache Beam 特点:
- 统一:对于批处理和流媒体用例使用单个编程模型。
- 方便:支持多个pipelines环境执行。包含:Apache Apex, Apache Flink, Apache Spark, 和 Google Cloud Dataflow。
- 可扩展:编写和分享新的SDKs,IO连接器和transformation库
部分翻译摘自官网:Apacher Beam 官网
1.2.Apache Beam关键概念:
1.2.1.Apache Beam SDKs
主要是开发API。为批处理和流处理提供统一的编程模型。眼下(2017)支持JAVA语言。而Python正在紧张开发中。
1.2.2. Apache Beam Pipeline Runners(Beam的执行器/执行者们)。支持Apache Apex,Apache Flink。Apache Spark。Google Cloud Dataflow多个大数据计算框架。可谓是一处Apache Beam编程,多计算框架执行。
1.2.3. 他们的对例如以下的支持情况详见
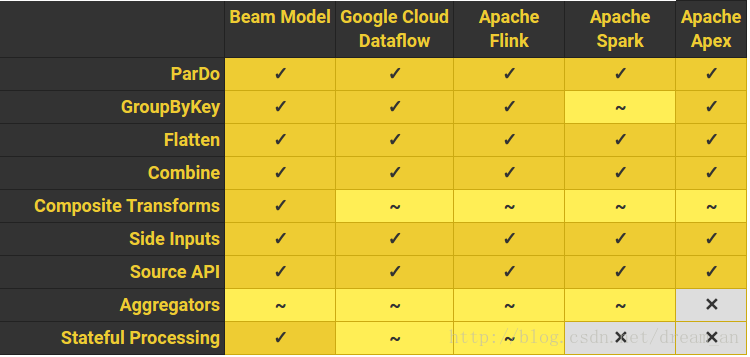
2.Apache Beam编程实战–Apache Beam源代码解读
基于maven,intellij IDEA。pom.xm查看 完整项目Github源代码 。直接通过IDEA的项目导入功能就可以导入完整项目,等待MAVEN下载依赖包,然后依照例如以下解读步骤就可以顺利执行。
2.1.源代码解析-Apache Beam 数据流处理原理解析:
关键步骤:
- 创建Pipeline
- 将转换应用于Pipeline
- 读取输入文件
- 应用ParDo转换
- 应用SDK提供的转换(比如:Count)
- 写出输出
- 执行Pipeline
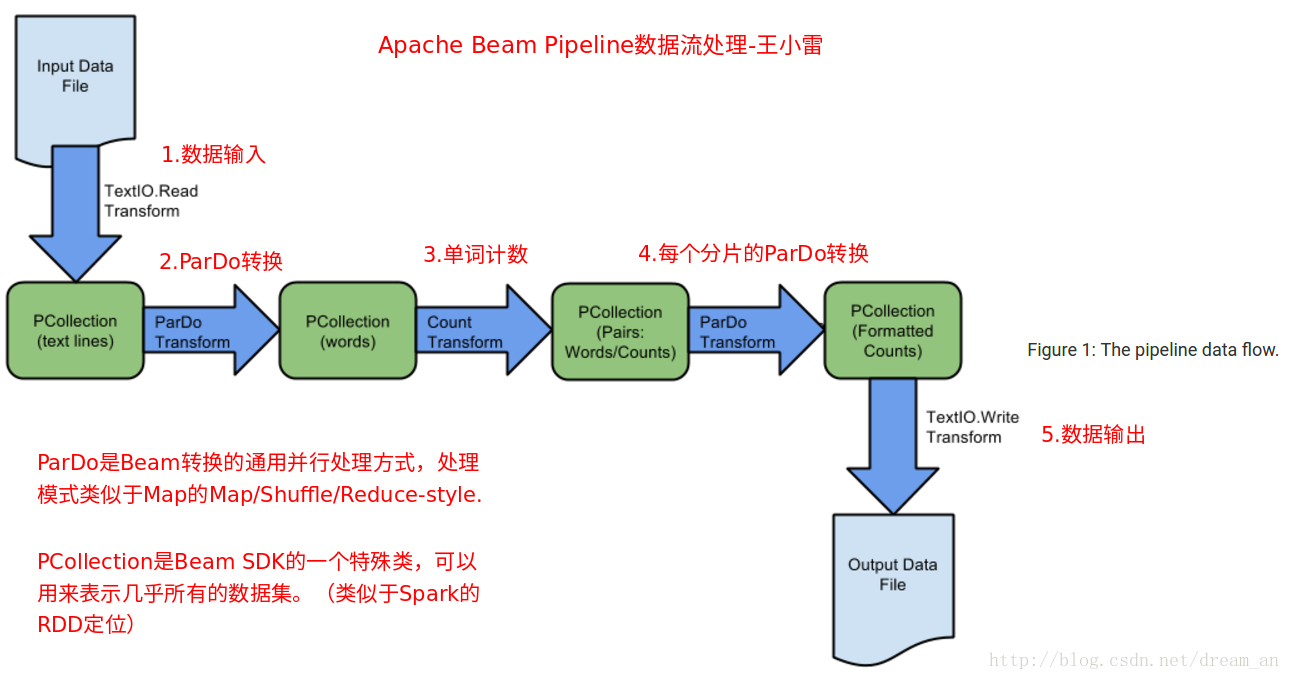
2.2.源代码解析。完整项目Github源代码,附WordCount,pom.xml等
/**
* MIT.
* Author: wangxiaolei(王小雷).
* Date:17-2-20.
* Project:ApacheBeamWordCount.
*/
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.options.Default;
import org.apache.beam.sdk.options.Description;
import org.apache.beam.sdk.options.PipelineOptions;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.options.Validation.Required;
import org.apache.beam.sdk.transforms.Aggregator;
import org.apache.beam.sdk.transforms.Count;
import org.apache.beam.sdk.transforms.DoFn;
import org.apache.beam.sdk.transforms.MapElements;
import org.apache.beam.sdk.transforms.PTransform;
import org.apache.beam.sdk.transforms.ParDo;
import org.apache.beam.sdk.transforms.SimpleFunction;
import org.apache.beam.sdk.transforms.Sum;
import org.apache.beam.sdk.values.KV;
import org.apache.beam.sdk.values.PCollection;
public class WordCount {
/**
*1.a.通过Dofn编程Pipeline使得代码非常简洁。
b.对输入的文本做单词划分,输出。
*/
static class ExtractWordsFn extends DoFn<String, String> {
private final Aggregator<Long, Long> emptyLines =
createAggregator("emptyLines", Sum.ofLongs());
@ProcessElement
public void processElement(ProcessContext c) {
if (c.element().trim().isEmpty()) {
emptyLines.addValue(1L);
}
// 将文本行划分为单词
String[] words = c.element().split("[^a-zA-Z']+");
// 输出PCollection中的单词
for (String word : words) {
if (!word.isEmpty()) {
c.output(word);
}
}
}
}
/**
*2.格式化输入的文本数据,将转换单词为并计数的打印字符串。
*/
public static class FormatAsTextFn extends SimpleFunction<KV<String, Long>, String> {
@Override
public String apply(KV<String, Long> input) {
return input.getKey() + ": " + input.getValue();
}
}
/**
*3.单词计数,PTransform(PCollection Transform)将PCollection的文本行转换成格式化的可计数单词。
*/
public static class CountWords extends PTransform<PCollection<String>,
PCollection<KV<String, Long>>> {
@Override
public PCollection<KV<String, Long>> expand(PCollection<String> lines) {
// 将文本行转换成单个单词
PCollection<String> words = lines.apply(
ParDo.of(new ExtractWordsFn()));
// 计算每一个单词次数
PCollection<KV<String, Long>> wordCounts =
words.apply(Count.<String>perElement());
return wordCounts;
}
}
/**
*4.能够自己定义一些选项(Options)。比方文件输入输出路径
*/
public interface WordCountOptions extends PipelineOptions {
/**
* 文件输入选项,能够通过命令行传入路径參数,路径默觉得gs://apache-beam-samples/shakespeare/kinglear.txt
*/
@Description("Path of the file to read from")
@Default.String("gs://apache-beam-samples/shakespeare/kinglear.txt")
String getInputFile();
void setInputFile(String value);
/**
* 设置结果文件输出路径,在intellij IDEA的执行设置选项中或者在命令行中指定输出文件路径,如./pom.xml
*/
@Description("Path of the file to write to")
@Required
String getOutput();
void setOutput(String value);
}
/**
* 5.执行程序
*/
public static void main(String[] args) {
WordCountOptions options = PipelineOptionsFactory.fromArgs(args).withValidation()
.as(WordCountOptions.class);
Pipeline p = Pipeline.create(options);
p.apply("ReadLines", TextIO.Read.from(options.getInputFile()))
.apply(new CountWords())
.apply(MapElements.via(new FormatAsTextFn()))
.apply("WriteCounts", TextIO.Write.to(options.getOutput()));
p.run().waitUntilFinish();
}
}3.支持Spark。Flink,Apex等大数据数据框架来执行该WordCount程序。完整项目Github源代码(推荐,注意pom.xml模块载入是否成功,在工具中开发大数据程序,利于调试,开发体验较好)
3.1.intellij IDEA(社区版)中Spark大数据框架执行Pipeline计算程序
Spark执行
设置VM options
-DPspark-runner设置Programe arguments
--inputFile=pom.xml --output=counts
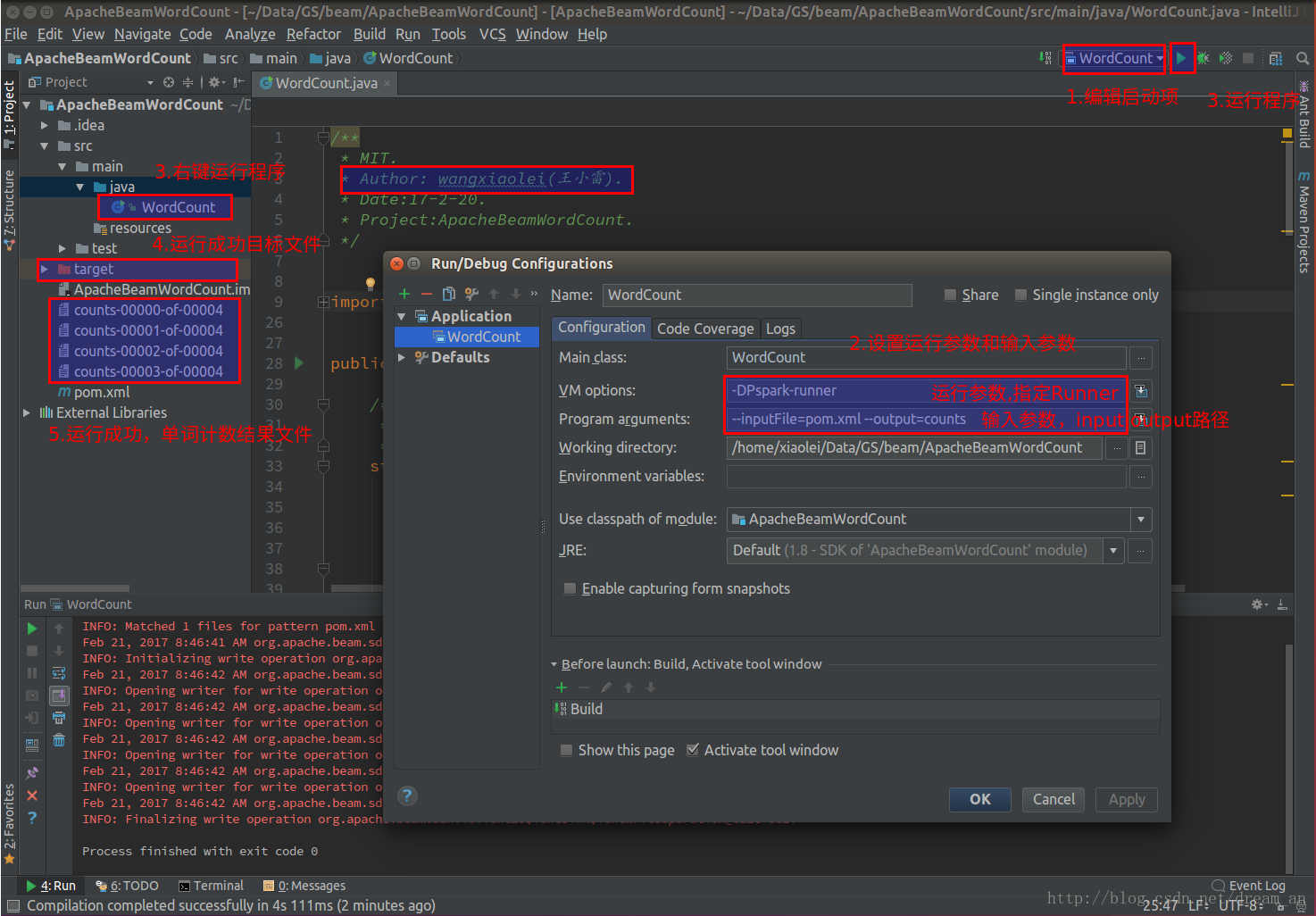
3.2.intellij IDEA(社区版)中Apex。Flink等支持的大数据框架均可执行WordCount的Pipeline计算程序,完整项目Github源代码
Apex执行
设置VM options
-DPapex-runner设置Programe arguments
--inputFile=pom.xml --output=counts
Flink执行等等
设置VM options
-DPflink-runner设置Programe arguments
--inputFile=pom.xml --output=counts
4.终端执行(Terminal)(不推荐,第一次下载过程非常慢。开发体验较差)
4.1.下面命令是下载官方演示样例源代码。第一次执行下载较慢,假设失败了就多执行几次。(推荐下载,完整项目Github源代码)直接用上述解读在intellij IDEA中执行。
mvn archetype:generate -DarchetypeRepository=https://repository.apache.org/content/groups/snapshots -DarchetypeGroupId=org.apache.beam -DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples -DarchetypeVersion=LATEST -DgroupId=org.example -DartifactId=word-count-beam -Dversion="0.1" -Dpackage=org.apache.beam.examples -DinteractiveMode=false
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvZHJlYW1fYW4=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast" alt="Apache Beam WordCount编程实战及源代码解读" title="">
4.2.打包并执行
mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount -Dexec.args="--runner=SparkRunner --inputFile=pom.xml --output=counts" -Pspark-runner
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvZHJlYW1fYW4=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast" alt="Apache Beam WordCount编程实战及源代码解读" title="">
4.3.成功执行结果
4.3.1.显示执行成功
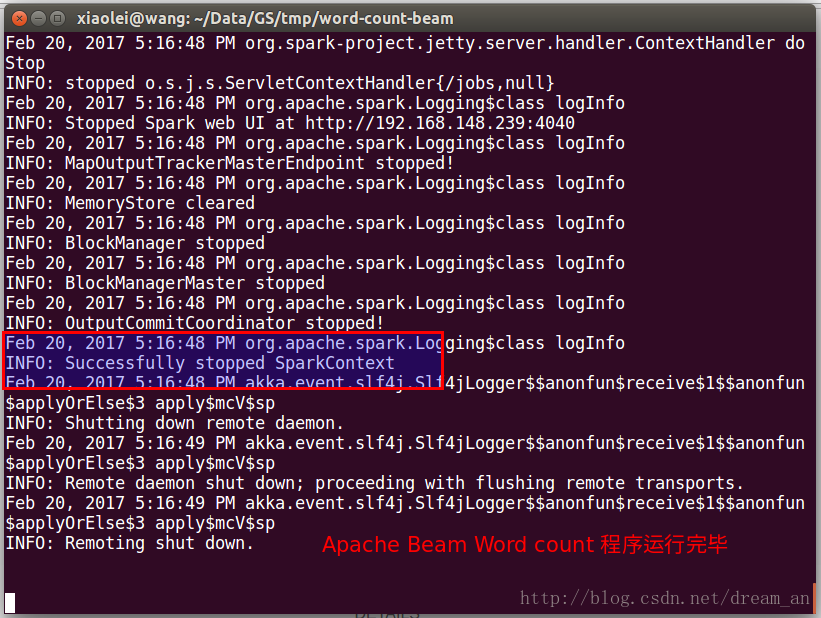
4.3.2.WordCount输出计算结果

Apache Beam WordCount编程实战及源代码解读的更多相关文章
- Apache Beam WordCount编程实战及源码解读
概述:Apache Beam WordCount编程实战及源码解读,并通过intellij IDEA和terminal两种方式调试运行WordCount程序,Apache Beam对大数据的批处理和流 ...
- Beam编程系列之Apache Beam WordCount Examples(MinimalWordCount example、WordCount example、Debugging WordCount example、WindowedWordCount example)(官网的推荐步骤)
不多说,直接上干货! https://beam.apache.org/get-started/wordcount-example/ 来自官网的: The WordCount examples demo ...
- Apache Beam中的函数式编程理念
不多说,直接上干货! Apache Beam中的函数式编程理念 Apache Beam的编程范式借鉴了函数式编程的概念,从工程和实现角度向命令式妥协. 编程的领域里有三大流派:函数式.命令式.逻辑式. ...
- Apache Beam: 下一代的大数据处理标准
Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金会的Apache孵化项目,被认为是继MapReduce,GFS和BigQuery等之后 ...
- Apache Beam实战指南 | 手把手教你玩转KafkaIO与Flink
https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247492538&idx=2&sn=9a2bd9fe2d7fd6 ...
- Apache Beam编程指南
术语 Apache Beam:谷歌开源的统一批处理和流处理的编程模型和SDK. Beam: Apache Beam开源工程的简写 Beam SDK: Beam开发工具包 **Beam Java SDK ...
- Apache Beam实战指南 | 大数据管道(pipeline)设计及实践
Apache Beam实战指南 | 大数据管道(pipeline)设计及实践 mp.weixin.qq.com 策划 & 审校 | Natalie作者 | 张海涛编辑 | LindaAI 前 ...
- Apache OFbiz entity engine源代码解读
简单介绍 近期一直在看Apache OFbiz entity engine的源代码.为了能够更透彻得理解,也由于之前没有看人别人写过分析它的文章,所以决定自己来写一篇. 首先,我提出一个问题,假设你有 ...
- Apache Beam 剖析
1.概述 在大数据的浪潮之下,技术的更新迭代十分频繁.受技术开源的影响,大数据开发者提供了十分丰富的工具.但也因为如此,增加了开发者选择合适工具的难度.在大数据处理一些问题的时候,往往使用的技术是多样 ...
随机推荐
- BZOJ5158 [Tjoi2014]Alice and Bob 【贪心 + 拓扑】
题目链接 BZOJ5158 题解 题中所给的最长上升子序列其实就是一个限制条件 我们要构造出最大的以\(i\)开头的最长下降子序列,就需要编号大的点的权值尽量小 相同时当然就没有贡献,所以我们不妨令权 ...
- Problem b
Problem b 题目描述 对于给出的n个询问,每次求有多少个数对(x,y),满足a≤x≤b,c≤y≤d,且gcd(x,y) = k,gcd(x,y)函数为x和y的最大公约数. 输入 第一行一个整数 ...
- NOIP2017赛前考试注意事项总结
考前: 考试前把读入优化和库以及对拍文件打好做好准备工作,另外注意放松心态,太紧张了肯定考不好··将自己的注意力集中起来 考场策略: 考试的基本策略是对每于道题先想个20分钟,如果想不出个靠谱的方 ...
- JavaEE中Filter实现用户登录拦截
实现思路是编写过滤器,如果用户登录之后session中会存一个user.如果未登录就为null,就可以通过过滤器将用户重定向到登陆页面,让用户进行登陆,当然过滤器得判断用户访问的如果是登陆请求需要放行 ...
- windows实时监测热插拔设备的变化2
//动态监测设备插拔 #include <Dbt.h> BEGIN_MESSAGE_MAP(ParticipateMeeting, CDialogEx) ON_WM_DEVICECHANG ...
- UML笔记(3):顺序图、Sequence Diagram
http://www.cnblogs.com/xueyuangudiao/archive/2011/09/22/2185364.html 目录 含义 要素: 1 活动者 2 对象 3 生命线 4 控制 ...
- python enumerate元素的时候可以获取下标,并且可以指定开始的下标值。
list=["a","b","c","d","e"] for i,item in enumerate ...
- android与java的关系
摘自:http://bbs.51cto.com/thread-944897-1.html 相信学习android的人都会想过或者想知道这个问题,那就请你耐心的看完这篇文章吧,你会对android与 ...
- undefined reference to XXX 问题原因
原文地址:http://blog.csdn.net/cserchen/article/details/5503556 Linux下编译程序时,经常会遇到“undefined reference to ...
- 为什么js引入页面后不起作用?
为什么js引入页面后不起作用? 例如常见的报错:Uncaught ReferenceError: $ is not defined. 可能出现这种情况的原因如下: 原因一: 引入js的位置不对,应在使 ...