python反爬之网页局部刷新1
# ajax动态加载网页
# 怎样判断一个网页是不是动态加载的呢?
# 查看网页源代码,如果源码中没有你要的数据,尝试访问下一页,当你点击下一页的时候,整个页面没有刷新, 只是局部刷新了,很大的可能是ajax加载
# 遇到ajax加载,一般的解决步骤就,通过浏览器或者软件抓包分析响应的请求,查看response里面哪个有你需要的数据,
# 然后再分析headers请求的网址,直接向哪个网址请求即可,当然还会有一些接口需要构建post请求
import json
import jsonpath
import requests
headers = {
'User-Agent':"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10",
}
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize=60&cityId=489&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=python&kt=3&_v=0.11045029&x-zp-page-request-id=7d6ccc963ff14b1d995b6f21942f2295-1542632726829-135321'
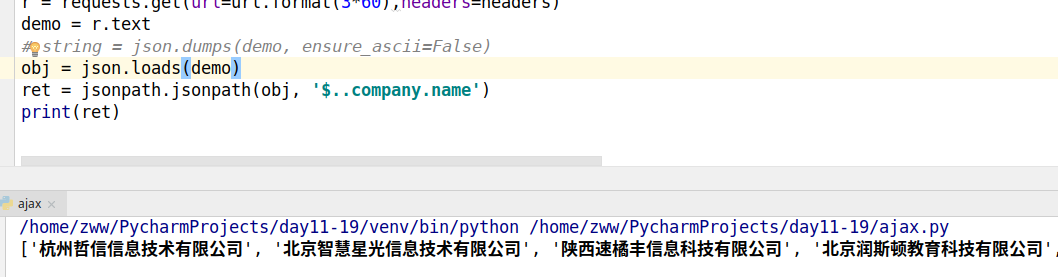
r = requests.get(url=url.format(3*60),headers=headers)
demo = r.text
# string = json.dumps(demo, ensure_ascii=False)
obj = json.loads(demo)
ret = jsonpath.jsonpath(obj, '$..company.name')
print(ret)# ajax动态加载网页
# 怎样判断一个网页是不是动态加载的呢?
# 查看网页源代码,如果源码中没有你要的数据,尝试访问下一页,当你点击下一页的时候,整个页面没有刷新,
# 只是局部刷新了,很大的可能是ajax加载
# 遇到ajax加载,一般的解决步骤就,通过浏览器或者软件抓包分析响应的请求,查看response里面哪个是需要的数据,
# 然后再分析headers请求的网址,直接向哪个网址请求即可,当然还会有一些接口需要构建post请求
#导入的包如果下面出现红色波浪线,pip install 名字 即可
import json
import jsonpath
import requests
headers = {
'User-Agent':"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10",
}
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize=60&cityId=489&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=python&kt=3&_v=0.11045029&x-zp-page-request-id=7d6ccc963ff14b1d995b6f21942f2295-1542632726829-135321'
r = requests.get(url=url.format(3*60),headers=headers)
demo = r.text
# string = json.dumps(demo, ensure_ascii=False)
obj = json.loads(demo)
ret = jsonpath.jsonpath(obj, '$..company.name')
print(ret)
-----网页抓包----
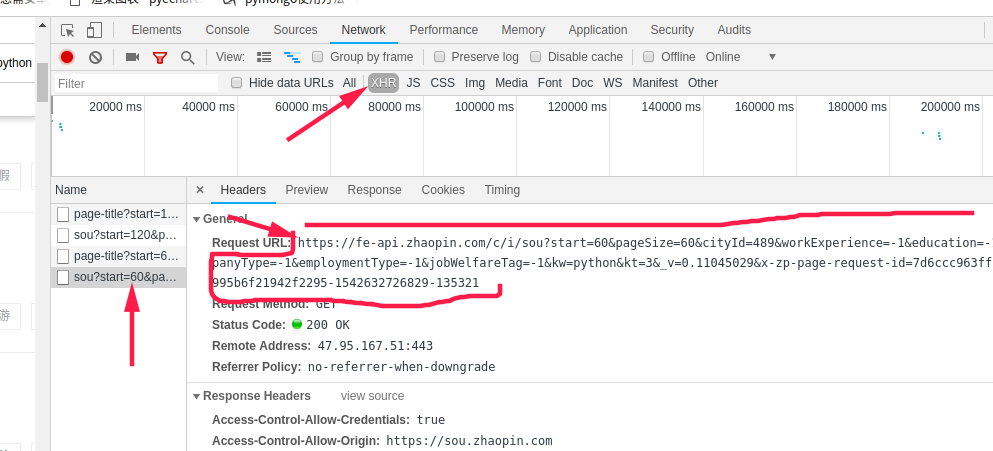
通过观察,改变start后面数字,会出现不同的数据,第一页是0,第二页是60,依次递增,pagesize则是每一页出现多少条,最好不要改变
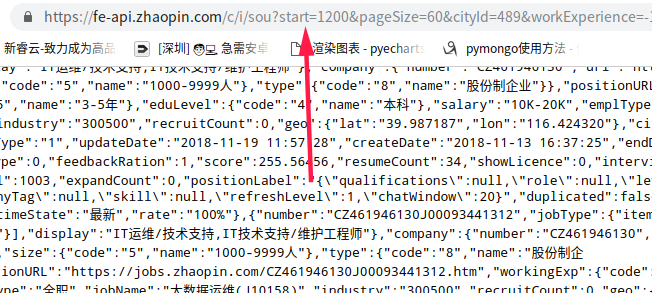
将网页中的内容粘贴到在线json解析中,可以看到,这是一个标准的json数据,通过在线解析可以看到清晰的结构

获取到的数据是一个json格式的字符串,需要使用jsonpath进行解析,获取里面的内容,图中选取了当前请求的公司名
python反爬之网页局部刷新1的更多相关文章
- python之爬取网页数据总结(一)
今天尝试使用python,爬取网页数据.因为python是新安装好的,所以要正常运行爬取数据的代码需要提前安装插件.分别为requests Beautifulsoup4 lxml 三个插件 ...
- python反爬之懒加载
# 在平时的爬虫中,如果遇到没有局部刷新,没有字体加密,右键检查也能看到清晰的数据,但是按照已经制定好的解析规则进行解析时,会返回空数据,这是为什么呢,这时可以在网页右键查看一下网页源代码,可以发现, ...
- python爬虫——爬取网页数据和解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序.只要浏览器能够做的事情,原则上,爬虫都能够做到. 2 ...
- python动态爬取网页
简介 有时候,我们天真无邪的使用urllib库或Scrapy下载HTML网页时会发现,我们要提取的网页元素并不在我们下载到的HTML之中,尽管它们在浏览器里看起来唾手可得. 这说明我们想要的元素是在我 ...
- python 嵌套爬取网页信息
当需要的信息要经过两个链接才能打开的时候,就需要用到嵌套爬取. 比如要爬取起点中文网排行榜的小说简介,找到榜单网址:https://www.qidian.com/all?orderId=&st ...
- Python爬虫爬取网页图片
没想到python是如此强大,令人着迷,以前看见图片总是一张一张复制粘贴,现在好了,学会python就可以用程序将一张张图片,保存下来. 今天逛贴吧看见好多美图,可是图片有点多,不想一张一张地复制粘贴 ...
- python反爬之动态字体相关文档
web_font的一些基本原理 https://blog.csdn.net/fdipzone/article/details/68166388 实例1 猫眼电影 http://www.cnblogs. ...
- python反爬之封IP
# requests是第三方库,需要安装 pip install requests import requests # 在日常的爬虫中,封ip也是一个很常用的反爬虫手段,遇到这种情况,我们只需要在每次 ...
- 1.记我的第一次python爬虫爬取网页视频
It is my first time to public some notes on this platform, and I just want to improve myself by reco ...
随机推荐
- 树状数组 P3605 [USACO17JAN]Promotion Counting晋升者计数
P3605 [USACO17JAN]Promotion Counting晋升者计数 题目描述 奶牛们又一次试图创建一家创业公司,还是没有从过去的经验中吸取教训--牛是可怕的管理者! 为了方便,把奶牛从 ...
- 关于如何在Windows下测交互题
这里的交互题指的NOI风格的交互题,即交互库 codeforces风格的交互题...只能自己实现评测插件了 使用Cena,Lemon没有附加文件功能不能评测交互题 在编译选项g++编译命令源文件中加入 ...
- 10.11cdy考试题
鸣谢cdy math [题目描述] 众所周知, xkj是GH的得意门生, 可是xkj的数学成绩并不是很理想: 每次GH在批评完数学限训做的差的人时, 总会在后面加一句:咱们班还有一位做的最差的同学-- ...
- Nginx02---指令集实现静态文件服务器
location 实现静态服务器,就是root和alias命令,他们位于location文件块中,详细:https://www.jianshu.com/p/4be0d5882ec5 root root ...
- php 多语言(UTF-8编码)导出Excel、CSV乱码解决办法之导出UTF-8编码的Excel、CSV
新项目,大概情况是这样的:可能存在多国.不同语种使用者,比喻有中文.繁体中文,韩文.日本等等,开发时选择了UTF-8编码,开发顺利,没有问题.昨天做了一个csv导出功能,导出的东西完全乱了: 设置mb ...
- 1972 HH的项链
传送门 主席树解法设las[ i ]表示数列中第 i 个数的值 上一次出现的位置,num[ i ]为原数列中第 i 个数的值1. 把 从第 1 到第 i 个数的 las 的值 的出现次数 建立一个线 ...
- poj 1664放苹果(递归)
放苹果 Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 37377 Accepted: 23016 Description ...
- Jenkins自动化CI CD流水线之4--Master-Slave架构
一.介绍 jenkins的Master-slave分布式架构主要是为了解决jenkins单点构建任务多.负载较高.性能不足的场景. Master/Slave相当于Server和agent的概念.Mas ...
- 阿里云ECS服务器FileZilla'被动模式失败'的处理办法
现象:FileZilla客户端连接服务器报错:“状态: 服务器发回了不可路由的地址.被动模式失败.” 解决办法:1.在[FileZilla Server]-Edit-Settings-Passi ...
- linux下pid命令
ps aux | grep tomcat| awk '{if(NR==1)print $2}' Linux:批量修改分隔符(awk.BEGIN.FS.OFS.print.tr命令) 批量修改文件的分 ...