循序渐进,了解Hive是什么!
一直想抽个时间整理下最近的所学,断断续续接触hive也有半个多月了,大体上了解了很多Hive相关的知识。那么,一般对陌生事物的认知都会经历下面几个阶段:
- 为什么会出现?解决了什么问题?
- 如何搭建?如何使用?
- 如何精通?
我会在本篇粗略的介绍下前两个问题,然后给一些相关的资料。第三个问题,就得慢慢靠实践和时间积累了。
如果有什么问题,可以直接留言!
为什么出现?解决了什么问题?
背景
说到这个问题,还得先说个小故事,在很久很久以前....
有一个叫facebook的贼有名的公司,他们内部搭建了数据仓库(你可以理解成把一大堆数据放到一个地方,然后做报表给老板看!),是基于mysql的。后来随着数据量的不断增加,这种传统的数据库扛不住了...于是经过一系列的折腾换到了hadoop上(hadoop是个大数据体系,用的是里面的hdfs,做存储的。你可以理解成搞一堆破烂机器凑成个集群,然后存储超级多的数据)。
问题来了!
以前基于数据库的数据仓库用sql就能做查询,现在换到hdfs上面,得跑Mapreduce任务去做分析,这样以前做分析的人还得学mapreduce,好难呀!
于是...他们就开发了一套框架就是用sql来做hdfs的查询(用户输入的是sql,框架内部把sql转成mapreduce的任务,然后再去跑分析)。

于是,Hive诞生了...看看上面同样是wordcount,mapreduce和hive的区别,能看到效果了吧。
解决的问题
Hive基于类似SQL的语言完成对hdfs数据的查询分析。
那么它到底做了什么呢?
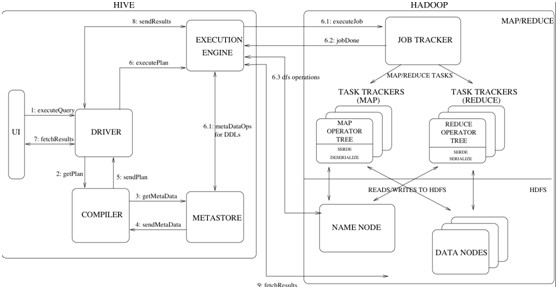
- 1 它支持各种命令,比如dfs的命令、脚本的执行
- 2 如果你输入的是sql,它会交给一个叫做Driver的东东,去编译解析。
- 3 把编译出来的东西交给hadoop去跑...然后返回查询结果。
说了这么多,其实你就可以把hive理解成搭建在hadoop(hdfs和mapreduce)之上的语言壳子...
如何搭建?如何使用?
搭建的可以参考这篇,感觉已经写的很详细了。
学习如何使用Hive还是个很重要的部分的!这里就不详细的说了,都举个小例子,具体的还是去撸官网吧!
创建
在Hive里面创建表和在普通的数据库中创建表示类似的,都是先创建(或者使用默认的)数据库,然后创建表。
create database xxx; -- 创建数据库
use xxx; --使用数据库
create table student(id string,name string,age int); --创建表
导入导出数据
数据的导入最常用的就是从hdfs的文件导入或者本地文件导入,也可以从某个查询结果直接创建或者导入。
Hive还支持把查询结果导出到文件...
查询
最普通的查询,就是select from句式了,Hive还是做得比较通用的
--普通查询
select * from xxx;
--带条件的查询
select * from xxx where age>30;
--限制返回列
select name,age from xxx;
--内连接
select a.*,b.* from tablea a join tableb b on a.id=b.sid;
--左连接
select * from a left outer join b on a.id=b.sid;
--右连接
select * from a right outer join b on a.id=b.sid;
函数
Hive支持一大堆的函数,比如普通的函数UDF:
floor、ceil、rand、cast等等
还支持聚合类型的函数UDAF:
count、avg、min、max、sum
还支持生成多行的函数。
更厉害的是,支持自定义扩展~~ 比如你们公司有个mapreduce的专家,可以封装很多的函数,然后别的会sql的分析人员,就可以使用这些函数做数据仓库的分析了。
存储
首先需要说明的是,Hive在存储的时候是不做任何处理的。不像是数据库,存进去的数据要先进行特定的解析,比如解析成一个一个的字段,然后挨个存储。每个数据库的存储引擎不同,解析的方式就不太一样。
在Hive中的数据都是存储在hdfs中的,如果没有特殊的声明,会以文本的形式存储,即不会再存储前做任何操作。简直就相当于是原封不动的拷贝。当你执行查询的时候,会按照预先指定的解析规则解析,然后返回。
举个例子更好理解点:
你的文件:
1,a
2,b
3,c
那么创建表的时候会这样:
create table xxx(a string,b string) row format delimited fields terminated by ',';
这个fields terminated by ','就声明了字段按照逗号进行分割。
那么当hive执行查询的时候,就会遍历文件,遇到逗号就分隔成一个字段~最后把结果返回。
毕竟hdfs还是按照块来存储数据的....这也是为什么Hive不支持局部的修改和删除,只能整体的覆盖、删除。
除了前面说的文本格式(TextFile),Hive还支持SequenceFile、RCFile,各有各的优势。sequenceFile相当于把数据切分了,然后可以局部的记录或者块进行压缩。RCFile则是列式存储,这样可以提高压缩比;还可以在查询的时候跳过不必要的列。
分区
在Hive中数据库和表其实都是hdfs中的一个目录,比如你的a数据库下的表b,存储的路径是这样的:
/user/hive/warehouse/a.db/b
后面两个部分a.db/b是很关键的,即“数据库名.db/表名”
在Hive还支持分区的概念。即按照某个特定的字段,对表进行划分。通常这个字段都是虚拟的,比如时间....
create table aa(a string,b string) partitioned by(c string);
这样就创建了分区表,如果c字段有"aaa"和"bbb"两个值,最终的目录就是酱婶的!
/user/hive/warehouse/a.db/b/c=aaa
/user/hive/warehouse/a.db/b/c=bbb
注意都是目录哦!真正的文件在这些目录下面。
由于都是目录,就很好理解,为什么分区查询会快了!因为在hive中所有的查询,基本都相当于是全表的扫描,因此要是能通过分区字段进行过滤,那么可以跳过很多不必要的文件了。
在Hive中支持静态分区(即你导数据的时候指定分区字段的值)、动态分区(按照字段的值来定分区的名称)。需要注意的是,动态分区会有很多潜在的风险,比如太多了!所以一定要合理规划你的表存储的设计。
索引
在hive0.7.0+的版本中,也是支持索引的。比如:
CREATE INDEX table02_index ON TABLE table02 (column3) AS 'COMPACT' WITH DEFERRED REBUILD;
CREATE INDEX table03_index ON TABLE table03 (column4) AS 'BITMAP' WITH DEFERRED REBUILD;
你也可以自定义索引的实现类,只要替换AS ''里面的东西,变成自己的包名类名就行。
不过一样的,添加索引虽然会加快索引。可是也意味着增加了存储的负担...所以自己衡量吧!
资源共享
安利个论坛,自愿传播的东西才是好东西——about云,加里面的群,每天都有精华分享。
无论是学习什么,官方文档总是最好的材料。

另外推荐一本书,反正也没其他的书可以看——《Hive编程指南》
循序渐进,了解Hive是什么!的更多相关文章
- 初识Hadoop、Hive
2016.10.13 20:28 很久没有写随笔了,自打小宝出生后就没有写过新的文章.数次来到博客园,想开始新的学习历程,总是被各种琐事中断.一方面确实是最近的项目工作比较忙,各个集群频繁地上线加多版 ...
- Hive安装配置指北(含Hive Metastore详解)
个人主页: http://www.linbingdong.com 本文介绍Hive安装配置的整个过程,包括MySQL.Hive及Metastore的安装配置,并分析了Metastore三种配置方式的区 ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- HIVE教程
完整PDF下载:<HIVE简明教程> 前言 Hive是对于数据仓库进行管理和分析的工具.但是不要被“数据仓库”这个词所吓倒,数据仓库是很复杂的东西,但是如果你会SQL,就会发现Hive是那 ...
- 基于Ubuntu Hadoop的群集搭建Hive
Hive是Hadoop生态中的一个重要组成部分,主要用于数据仓库.前面的文章中我们已经搭建好了Hadoop的群集,下面我们在这个群集上再搭建Hive的群集. 1.安装MySQL 1.1安装MySQL ...
- hive
Hive Documentation https://cwiki.apache.org/confluence/display/Hive/Home 2016-12-22 14:52:41 ANTLR ...
- 深入浅出数据仓库中SQL性能优化之Hive篇
转自:http://www.csdn.net/article/2015-01-13/2823530 一个Hive查询生成多个Map Reduce Job,一个Map Reduce Job又有Map,R ...
- Hive读取外表数据时跳过文件行首和行尾
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 有时候用hive读取外表数据时,比如csv这种类型的,需要跳过行首或者行尾一些和数据无关的或者自 ...
- Hive索引功能测试
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 从Hive的官方wiki来看,Hive0.7以后增加了一个对表建立index的功能,想试下性能是 ...
随机推荐
- ubuntu14.04禁用自动待机保持屏幕亮度
http://jingyan.baidu.com/article/9989c7461fd041f648ecfe05.html
- 从零点壹开始学JAVA(DAY 1 笔记)<补充记录>
一个同事的先生(下面称呼其为耿大神)是做开发的,比较资深的那种,在他们公司的核心技术部门. 幸运的是,耿大神很乐意帮助我这株小白菜,在业余时间指导我,这里深表感谢. 耿大神隔段时间会给我提一些问题,让 ...
- HDU5909 Tree Cutting(树形DP + FWT)
题目 Source http://acm.hdu.edu.cn/showproblem.php?pid=5909 Description Byteasar has a tree T with n ve ...
- 【转】Java提高篇(三四)-----fail-fast机制
转自:http://blog.csdn.net/chenssy/article/details/38151189 在JDK的Collection中我们时常会看到类似于这样的话: 例如 ...
- windows 10 开始菜单和cortana无法工作的问题
过了个周末,到了实验室一开机发现报了个关键错误:开始菜单和cortana无法工作. 经过一番google ,发现问题,原来是360禁用了一个服务导致,这个服务是UserManager. 我直接去开启发 ...
- ASP.NET中获取Repeater模板列中LinkButton按钮事件中获取ID等
前台页面中: <asp:Repeater ID="repComment" runat="server"> <ItemTe ...
- CentOS 简单设置samba服务
1.安装 yum -y install samba 2.设置配置文件 1) 备份Samba的配置文件:cp /etc/samba/smb.conf /etc/samba/smb.conf.bak ...
- Linux 环境变量 设置 etc profile
一.Linux的变量种类 按变量的生存周期来划分,Linux变量可分为两类: 1.永久的:需要修改配置文件,变量永久生效. 2.临时的:使用export命令声明即可,变量在关闭shell时失效. 二. ...
- BeautifulSoup Some characters could not be decoded, and were replaced with REPLACEMENT CHARACTER.
BeautifulSoup很赞的东西 最近出现一个问题:Python 3.3 soup=BeautifulSoup(urllib.request.urlopen(url_path),"htm ...
- iOS中push视图的时候,屏幕中间会出现一条灰色的粗线的解决方案
因为执行动画需要时间,所以在动画未完成又执行另一个切换动画,容易产生异常.所以在一个方法连续push不同的VC是没有问题的,但是不小心push同一个VC,并且animated为YES,可能多次跳转了 ...