scrapy爬取用户信息 ---崔志才
这个实例还是值得多次看的
其流程图如下,还是有一点绕的。
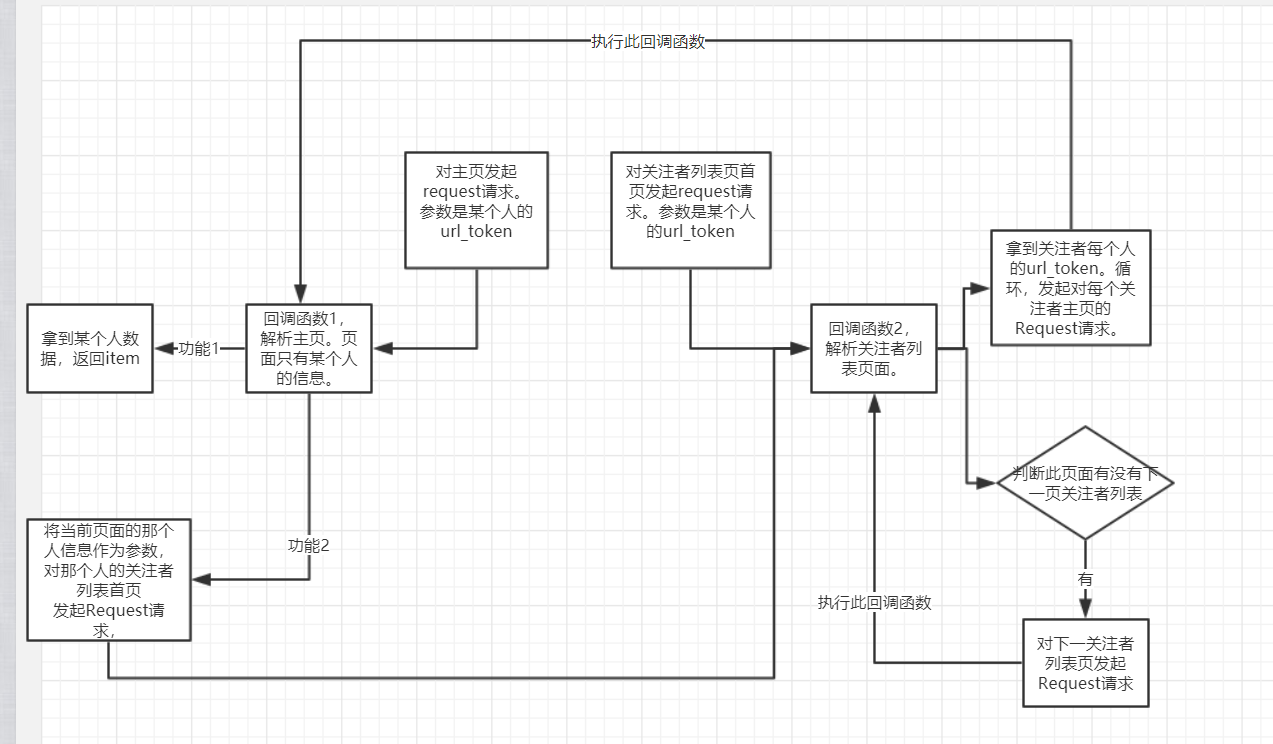
总结:
1 Requst(rul=' xxx ',callback= ' '),仅仅发起 某个网页 的访问请求,没啥了。剩下的交给回调函数
2 parse_()。对 某个页面 经过下载后的 数据 进行处理,包括逻辑判断,有可能比较复杂,提取想要的数据等等。最终,返回item,或 Request对象,也可以两者都返回。 有的回调函数返回一个request对象,这个request对象调用本身这个回调函数。如:判断是否有下一页的情况就可以写成递归函数。猜想:这种情况下,肯定有条件判断,来终止递归的执行。
3 回调函数可以有很多个。回调函数也是函数,实现不同的功能,对不同的response执行不同的逻辑,所以肯定是有多个回调函数的。
4 同时,回调函数既然是函数,函数之间可以互相调用,回调函数之间同样也可以互相调用。
5 乍一看,回调函数可以回返回很多Request对象,不要慌,不要紧张,随他去,所有的request对象都叫个调度器管理。每个request都只是对某个页面的请求而已。request对象固然多,一个一个来,慢慢来。顺序是由调度器决定,一个request到了,经过下载器,然后在执行回调函数。这就是一个request的流程。走完后,它的功能已经实现了。
不要管回调函数返回的是啥,可能是item,也可能是request对象。这个时候这里的request对象是一个完全新的request对象,它有他自己的流程。它在调度器里等,直到调度器安排说,到你了,出来吧。
6 即便是用scrapy框架写,也最好思路明确。耦合性要低。别想着一个start_requests,一个paser就能搞定。
上代码
pipeline.py
文档中有现成的代码
稍微修改了下,理由upsert方法,实现对数据的去重。item本身就是一个字典。所以 {'$set':item},是没有问题的。
import pymongo
class MongoPipeline(object):
collection_name = 'userinfo'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
# print(item)
if item['url_token']:
self.db[self.collection_name].update({'url_token':item['url_token']},{'$set':item},True)
return item
zhihu.py
from scrapy import Spider,Request
from zhihu.items import *
import json
class ZhihuUserinfoSpider(Spider): name = 'zhihu'
allowed_domains = ['www.zhihu.com']
# start_urls = ['http://www.zhihu.com/']
start_user = 'https://www.zhihu.com/api/v4/members/{}?include=allow_message%2Cis_followed%2Cis_following%2Cis_org%2Cis_blocking%2Cemployments%2Canswer_count%2Cfollower_count%2Carticles_count%2Cgender%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics'
start_followee = 'https://www.zhihu.com/api/v4/members/{}/followees?offset={}&limit={}' # 随便填一个注册过的名字url_token,都是可以的。都会都json数据返回。
def start_requests(self):
'''
对某个用户页面,对某个用户其关注者的页面发起请求。Request,只管发起请求,可以这样简单理解。
:return:
'''
yield Request(url=self.start_user.format('valarmorghulis'),callback=self.parse_user)
yield Request(url=self.start_followee.format('valarmorghulis',,),callback=self.parse_followees,)
def parse_user(self,response):
'''
解析 页面--->某个用户信息进行解析。只管对拿到的response数据进行解析。哪个Request的回调函数是它,它就解析这个Request生成的数据。
:param response:
:return:
'''
result = json.loads(response.text)
item = UserInfoItem() for field in item.fields:
if field in result.keys():
item[field] = result.get(field)
yield item
url_token = result.get('url_token')
yield Request(url=self.start_followee.format(url_token,,),callback=self.parse_followees)
def parse_followees(self,response):
'''
有时候回调函数就是自己,这个就是个很好的例子。
解析某一页的数据,拿到用户的url_token,对每个url_token发起请求,调用self.parse_user。并判断是否有下一页。
如果有,发起访问请求,拿到这一页数据,解析这一页数据。。。递归调用自己
:param response:
:return:
'''
result = json.loads(response.text)
if result.get('data'):
for data in result.get('data'):
url_token = data.get('url_token')
yield Request(url=self.start_user.format(url_token),callback=self.parse_user)
if result.get('paging') and result.get('paging').get('is_end') == False:
next = result.get('paging').get('next')
yield Request(url=next,callback=self.parse_followees)
settings.py
user_agent肯定是要有的。
authorization 这应该就是反扒措施。服务器要求必须有的一个字段。如果没有,会报401错误。自己试了好久,没试出来。自己试了cookie,以及其它的一些key。长点心吧。
来源是百度的解释:
您的Web服务器认为,客户端(例如您的浏览器或我们的 CheckUpDown 机器人)发送的 HTTP 数据流是正确的,但进入网址 (URL) 资源 , 需要用户身份验证 , 而相关信息 1 )尚未被提供, 或 2 )已提供但没有通过授权测试。这就是通常所知的“ HTTP 基本验证 ”。 需客户端提供的验证请求在 HTTP 协议中被定义为 WWW – 验证标头字段 (WWW-Authenticate header field) 。
DEFAULT_REQUEST_HEADERS = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
'authorization': 'Bearer 2|1:0|10:1523006417|4:z_c0|92:Mi4xU2lGZ0FBQUFBQUFBOE8taEQ2Um1EU1lBQUFCZ0FsVk4wWW0wV3dDcFItSkVsME8ycEs2SHRWaG9xdWJvY3VBdzRR|f54e22b627da25b200b9467fef2702fa0f57be6961389f62f4f0d39520f8fe1b',
}
scrapy爬取用户信息 ---崔志才的更多相关文章
- 支付宝小程序serverless---获取用户信息(头像)并保存到云数据库
支付宝小程序serverless---获取用户信息(头像)并保存到云数据库 博客说明 文章所涉及的资料来自互联网整理和个人总结,意在于个人学习和经验汇总,如有什么地方侵权,请联系本人删除,谢谢! 我又 ...
- 进阶——scrapy登录豆瓣解决cookie传递问题并爬取用户参加过的同城活动©seven_clear
最近在用scrapy重写以前的爬虫,由于豆瓣的某些信息要登录后才有权限查看,故要实现登录功能.豆瓣登录偶尔需要输入验证码,这个在以前写的爬虫里解决了验证码的问题,所以只要搞清楚scrapy怎么提交表单 ...
- 45.更新一下scrapy爬取工商信息爬虫代码
这里是完整的工商信息采集代码,不过此程序需要配合代理ip软件使用.问题:1.网站对ip之前没做限制,但是采集了一段时间就被检测到设置了反爬,每个ip只能访问十多次左右就被限制访问.2.网站对请求头的检 ...
- Android(Java) 模拟登录知乎并抓取用户信息
前不久.看到一篇文章我用爬虫一天时间"偷了"知乎一百万用户.仅仅为证明PHP是世界上最好的语言,该文章中使用的登录方式是直接复制cookie到代码中,这里呢,我不以爬信息为目的.仅 ...
- qq互联(connect.qq.com)取用户信息的方法
<?php //应用的APPID$app_id = "YOUR_APP_ID";//应用的APPKEY$app_secret = "YOUR_APP_KEY&quo ...
- 利用 Scrapy 爬取知乎用户信息
思路:通过获取知乎某个大V的关注列表和被关注列表,查看该大V和其关注用户和被关注用户的详细信息,然后通过层层递归调用,实现获取关注用户和被关注用户的关注列表和被关注列表,最终实现获取大量用户信息. 一 ...
- 利用Scrapy爬取所有知乎用户详细信息并存至MongoDB
欢迎大家关注腾讯云技术社区-博客园官方主页,我们将持续在博客园为大家推荐技术精品文章哦~ 作者 :崔庆才 本节分享一下爬取知乎用户所有用户信息的 Scrapy 爬虫实战. 本节目标 本节要实现的内容有 ...
- 使用python scrapy爬取知乎提问信息
前文介绍了python的scrapy爬虫框架和登录知乎的方法. 这里介绍如何爬取知乎的问题信息,并保存到mysql数据库中. 首先,看一下我要爬取哪些内容: 如下图所示,我要爬取一个问题的6个信息: ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
随机推荐
- JavaScript onkeydown事件入门实例(键盘某个按键被按下)
JavaScript onkeydown 事件 用户按下一个键盘按键时会触发 onkeydown 事件.与 onkeypress事件不同的是,onkeydown 事件是响应任意键按下的处理(包括功能键 ...
- javaweb基础(24)_jsp一般的标签开发
一.标签技术的API 1.1.标签技术的API类继承关系 二.标签API简单介绍 2.1.JspTag接口 JspTag接口是所有自定义标签的父接口,它是JSP2.0中新定义的一个标记接口,没有任何属 ...
- Nginx正向代理代理http和https服务
Nginx正向代理代理http和https服务 1. 背景需求 通过Nginx正向代理,去访问外网.可实现局域网不能访问外网的能力,以及防止在上网行为上,留下访问痕迹. 2. 安装配置 2.1安装 w ...
- ubuntu下RedisDesktopManager的安装,redis可视化工具
官方网站:https://redisdesktop.com/download 一句命令行解决: sudo snap install redis-desktop-manager 或者直接通过软件管理中心 ...
- Docker系列一:Docker的介绍和安装
Docker介绍 Docker是指容器化技术,用于支持创建和实验Linux Container.借助Docker,你可以将容器当做重量轻.模块化的虚拟机来使用,同时,你还将获得高度的灵活性,从而实现对 ...
- linux关于进程、内存和cpu情况
1.load average: 2.03, 1.76, 1.80 1分钟.5分钟.15分钟平均负载 2.%Cpu(s):100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa ...
- React和Vue组件间数据传递demo
一.React (一)父组件向子组件传数据 简单的向下传递参数 /* Parent */ class App extends Component { render() { return ( <d ...
- eclipse使用技巧的网站收集——转载(一)
Eclipse工具使用技巧总结(转载) 首先推荐一篇非常好的How to use eclipse文章 ,讲的是eclipse使用的方方面面,非常实用,推荐给大家! 一.常用快捷键:Ctrl+F11 运 ...
- nmap命令扫描存活主机
1.ping扫描:扫描192.168.0.0/24网段上有哪些主机是存活的: [root@laolinux ~]# nmap -sP 192.168.0.0/24 Starting Nmap 4. ...
- UVa 579 Clock Hands
水题.. 求任意时刻时针和分针的夹角,其结果在0°到180°之间. 这里又一次用到了sscanf()函数,确实很方便. 思路:我们分别求出时针和分针转过的角度,然后大的减小的,如果结果ans大于180 ...