论文笔记:《OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks DeepLearning 》
一、Abstract综述
训练出一个CNN可以同时实现分类,定位和检测..,三个任务共用同一个CNN网络,只是在pool5之后有所不同
二、分类
这里CNN的结构是对ALEXNET做了一些改进,具体的在论文中都说了,就不再赘述了。说几个关键的地方。
1.之前在多尺度的情况下,Krizhevsky用的是multi—view的方法,也就是对给定的图片分别取四个角,中间以及翻转的图块输入到CNN中,得到的结果取均值。这个方法的缺陷在于有些区域的组合会被忽略(比如 ground truth在中间偏右,但是此方法并没有检测这个框),只关注了一个scale导致结果的置信度不高,而且重叠区域的计算很耗时。所以这里采用的方法是multi—scale。
传统的检测/定位算法是固定输入图像不变,采用不同大小的滑窗来支持不同尺度的物体。这里因为采用的是全卷积网络,训练时固定输入大小,使用的时候可以multi-scale,这个待会再详细讲,只要清楚每次输入的时候,滑窗的大小就是训练时输入图像的大小,是不可以改变的。那么,CNN支持多尺度的办法就是,固定滑窗的大小,改变输入图像的大小。具体来说,对于一幅给定的待处理的图像,将图像分别resize到对应的尺度上,然后,在每一个尺度上执行上述的密集采样的算法,最后,将所有尺度上的结果结合起来,得到最终的结果。
这样做的好处就是:1.速度快,卷积处理的速度当然快 2.预测时不用对图像做尺度处理。
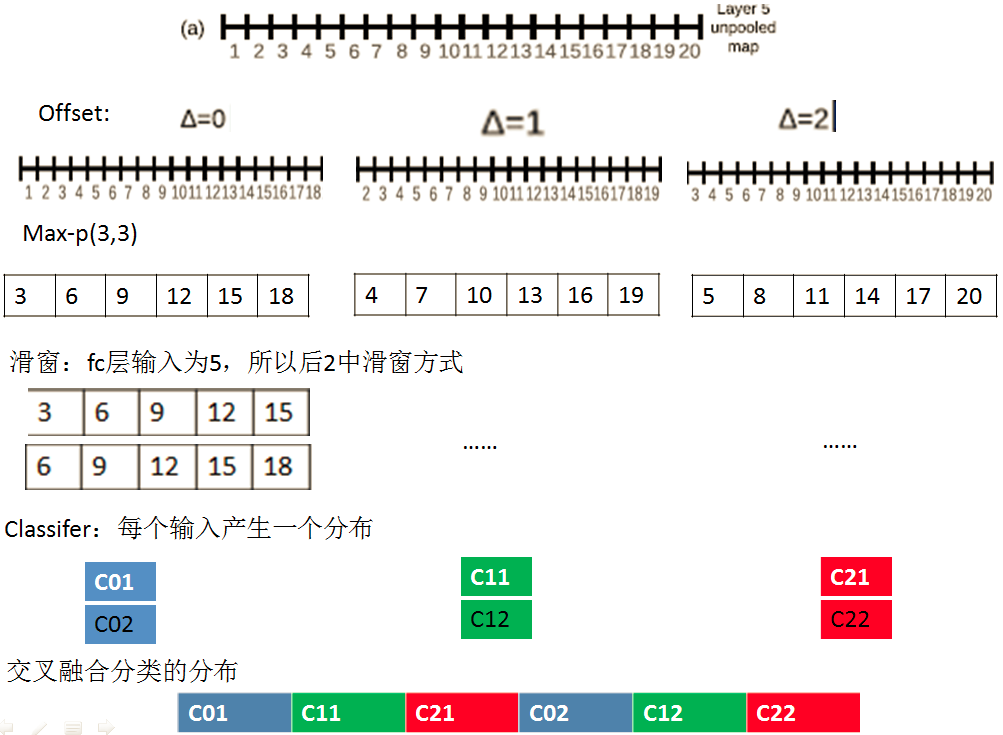
但是固定slide window也有坏处,就是步长固定了, 整个网络的子采样比例=2*3*2*3=36,即当应用网络计算时,输入图像的每个维度上,每36个像素才能产生一个输出。文章采用的解决方法是使用模型前5层卷积层来提取特征,layer 5在 pooling 之前给定 x,y 一个偏移,,即对每个 feature map 滑窗从(0,0), (0,1), (0,2), (1,0), (1,1)...处分别开始滑动,得到9种不同的feature map,那么下一层的 feature map 总数为9*前一层的 num_output。这样的话就会把sampling从36降到了12.
2.offset max-pooling
上面的方法是可以单独拉出来说一说的,以下图为例,这是一维的,classfilier的输入要求是1*5,我们先用offset max_pooling得到三个1*6的feature map(注意这里是non-overlapping regions的),然后对每个用1*5的滑动窗口计算,也就是放到分类器里面,会得到2*3=6个输出,然后融合以后就可以得到分类器的1*6的输出。
2.全卷积网络的好处
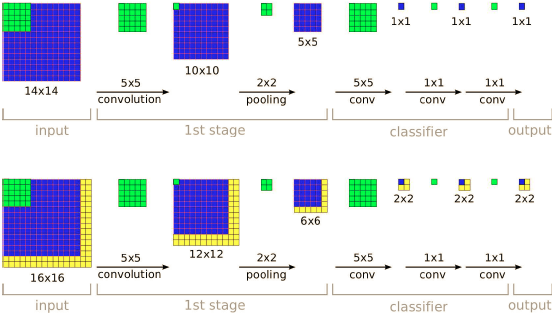
如上图所示,可以看到后面的全连接层被转换为卷积层了,本来训练的时候只有14*14的输入,最后得到1*1的输出,在predict的时候,如果输入时16*16,最后得到的结果是2*2的output,这个相当于四个滑动窗口在16*16的input上滑动的输出结果,但计算明显减轻了很多。
3.上面这样做还有一个问题,就是不同的scale输出的feature map大小不同,而最后的classifier要求固定的input,所以这里需要calssifier在feature map上做滑动窗口,这样最后就有了multi-scale的预测:最对某一个类别,分别对不同scale矩阵取最大值,然后取该类别中不同矩阵最大值的均值,最后输出所有类别的top-1 or top-5
三、定位
定位问题的模型也是一个CNN,1-5层作为特征提取层和分类问题完全一样,后面接两个全连接层,组成regressor network ,也就是用回归的方法来训练得到bounding box的四个角点的坐标,使用预测边界和真实边界之间的L2范数作为代价函数,来训练回归网络。对于每个class都要单独训练一个定位层,这样,假设类别数有1000,则这个 regressor network 输出1000个 bounding box ,每一个 bounding box对应一类。
1.算法流程
(1)初始化模型后,进来一张图片,利用滑动窗口技术提取出来多个patch。
(2)对于每个patch,用分类模型确定好类别,然后使用对用的定位模型来确定物体的位置。
(3)根据分类的分数可以选出k个候选的patch
(4)对patch进行合并
2.合并多框
因为论文里面使用的方法是重合率超过百分50就可以留下,所以会有很多的bounding box,所以最后需要做一个合并多框的方法,这里采用的是贪心策略
a)在6个缩放比例上运行分类网络,在每个比例上选取top-k个类别,就是给每个图片进行类别标定Cs
b)在每个比例上运行预测boundingbox网络,产生每个类别对应的bounding box集合Bs
c)各个比例的Bs到放到一个大集合B
d)融合bounding box。具体过程应该是选取两个bounding box b1,b2;计算b1和b2的匹配分式,如果匹配分数大于一个阈值,就结束,如果小于阈值就在B中删除b1,b2,然后把b1和b2的融合放入B中,在进行循环计算。
最终的结果通过融合具有最高置信度的bounding box给出。
3.为什么训练定位的时候要用multi-scale的输入
是为了在predic的时候可以做到across—scale的预测,多尺度的训练会让后面的合并的可信度更高,当然这也有问题,就是只能在处理训练的时候这几个尺度上的图片有好的效果,其他的时候不行。
三、检测
同时跑上面两个,得到的结果就是的了...
四、总结
最大的亮点在于在pool层用小的滑动窗口代替input的大的滑动窗口吧,大大提高了计算效率,而且这样可以fix住feature提取的那部分,所以检测和定位就可以共用了,所以整个CNN的效率和精度都有了很大的提高.暂时了解的只有这么多了,以后有新的理解还要再来修改。
论文笔记:《OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks DeepLearning 》的更多相关文章
- 《Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition》论文笔记
论文题目:<Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition> 论文作者:Qibin ...
- [place recognition]NetVLAD: CNN architecture for weakly supervised place recognition 论文翻译及解析(转)
https://blog.csdn.net/qq_32417287/article/details/80102466 abstract introduction method overview Dee ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
- 论文笔记——Rethinking the Inception Architecture for Computer Vision
1. 论文思想 factorized convolutions and aggressive regularization. 本文给出了一些网络设计的技巧. 2. 结果 用5G的计算量和25M的参数. ...
- 论文笔记:Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells 2019-04- ...
- 论文笔记:ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware 2019-03-19 16:13:18 Pape ...
- 论文笔记:DARTS: Differentiable Architecture Search
DARTS: Differentiable Architecture Search 2019-03-19 10:04:26accepted by ICLR 2019 Paper:https://arx ...
- 论文笔记:Progressive Neural Architecture Search
Progressive Neural Architecture Search 2019-03-18 20:28:13 Paper:http://openaccess.thecvf.com/conten ...
- 论文笔记:Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation2019-03-18 14:4 ...
- 论文笔记系列-DARTS: Differentiable Architecture Search
Summary 我的理解就是原本节点和节点之间操作是离散的,因为就是从若干个操作中选择某一个,而作者试图使用softmax和relaxation(松弛化)将操作连续化,所以模型结构搜索的任务就转变成了 ...
随机推荐
- CentOS启动时自动加载内核模块
要想在CentOS中自动加载内核模块,需要在/etc/sysconfig/modules/目录中增加一个脚本,在此脚本中加载所需的模块. 下面是我所用的一个名为8021q.modules的脚本,用来在 ...
- SQLServer事务的原理
1.事务的概念 是数据库管理系统执行过程中的一个逻辑单元,由一个有限的数据库操作序列组成: 由事务开始(begin transaction)和事务结束(end transaction)之间执行的全体操 ...
- oracle安装报错[INS-30131]执行安装程序验证所需的初始设置失败(无法访问临时位置)解决方法!
最近在电脑上安装oracle12c,安装时,在执行检查环境步骤时候报错: [INS-30131]执行安装程序验证所需的初始设置失败(无法访问临时位置) 最后在网上搜索解决方法,特记录下,以防以后再用到 ...
- Drupal7新装一个主题时页面白屏,如何设置一个默认主题?
问题: 请问我不小心退出登陆了 但这个主题没有登录口 而且之前不知道为什么我其他界面都不能显示内容所以 ?q=user 也不行,怎么办呢?看网上说更换默认主题 去variable表里把默认主题换了,我 ...
- java算法面试题:有一个字符串,其中包含中文字符、英文字符和数字字符,请统计和打印出各个字符的个数 按值的降序排序,如果值相同则按键值的字母顺序
package com.swift; import java.util.HashMap; import java.util.Map; import java.util.Map.Entry; publi ...
- grep过滤目录或文件方法
在使用grep在指定目录下查找包含指定字符串的文件是,我们想过滤(即不递归查询指定目录)时!可以使用 –exclude-dir 参数 单个目录实例 搜索.目录但不搜索在.目录下的.svg目录中包含&q ...
- docker部署Ceph分布式存储集群
1.环境准备 3台virtualbox虚拟机,用来安装ceph集群,已用docker-machine安装上了docker,每台虚拟机虚拟创建一个5G的硬盘,用于存储osd数据,例如:/dev/sdb ...
- Linux下面自动清理超过指定大小的文件
Linux下面自动清理超过指定大小的文件 思路:1)查找test目录下的所有的文件2)判断是否大于100M3)大于100M则清空 以byte为单位显示文件大小,然后和100M大小做对比. 100M换算 ...
- Ecshop之ajax修改表里的状态(函数化处理)
目录 功能: 效果: 思路: 页面里 控制器里 功能: `点击图片,修改表里的状态值` 效果: 思路: 页面里在img里点绑定onclick件事,调用js函数listTable.toggle oncl ...
- 解决cmd目录下pip命令不存在的问题
解决cmd目录下pip命令不存在的问题 注:pip.exe程序在Python安装目录下的scripts中1.在cmd命令中输入: 先输入:python -m ensurepip 再输入:python ...