【论文阅读】VulCNN受图像启发的可扩展漏洞检测系统
基本信息

摘要
由于深度学习(DL)可以自动从源代码中学习特征,因此已被广泛用于源代码漏洞检测。为了实现可扩展的漏洞扫描,一些先前的研究打算通过将源代码视为文本来直接处理源代码。为了实现准确的漏洞检测,其他方法考虑将程序语义提炼成图形表示,并使用它们来检测漏洞。在实践中,基于文本的技术是可扩展的,但由于缺乏程序语义而不准确。基于图的方法很准确,但不可扩展,因为图分析通常很耗时。在本文中,我们的目标是在扫描大规模源代码漏洞时实现可扩展性和准确性。受现有基于深度学习的图像分类的启发,该分类能够准确分析数百万张图像,我们更喜欢使用这些技术来实现我们的目的。具体来说,我们提出了一个新颖的想法,可以在保留程序细节的同时有效地将函数的源代码转换为图像。我们实现了 VulCNN,并在 13,687 个易受攻击的函数和 26,970 个非易受攻击的函数的数据集上对其进行了评估。实验结果表明,VulCNN的准确率高于8种最先进的漏洞检测器(即Checkmarx、FlawFinder、RATS、TokenCNN、VulDeePecker、SySeVR、VulDeeLocator和Devign)。至于可扩展性,VulCNN 比 VulDeePecker 和 SySeVR 快四倍,比 VulDeeLocator 快 15 倍,比 Devign 快六倍。此外,我们还对一个超过2500万行代码的案例进行了研究,结果表明VulCNN可以检测到大规模漏洞。通过扫描报告,我们终于发现了 73 个 NVD 中未报告的漏洞。
关键点
不同于该团队之前成果Vuldeelocator,将漏洞源代码转换为llvm-IR中间代码切片然后转化为向量,VulCNN是将漏洞源代码的数据流图DFG和控制流图CFG合并成为程序依赖图PDG,然后把 PDG 当作一个社交网络,利用度中心性 、katz 中心性和接近中心性分别构造向量,合并成为3∗100∗128的图像,然后改造利用CNN实现精准识别和分类。
下面的流程图应该一目了然:
当前研究进度
一般来说,源代码漏洞检测方法可以分为两大类,即基于代码相似性的方法和基于模式的方法。基于代码相似度的漏洞检测方法主要用于检测代码克隆产生的漏洞。当用于检测不是由代码克隆产生的漏洞时,会导致较高的误报率。传统的基于模式的漏洞检测方法依靠专家手动定义漏洞规则或特征来描述漏洞,这些方法不仅具有主观性,而且难以同时实现低误报率和低误报率。
近年来,由于深度学习 (DL) 的自动特征提取,被广泛用于检测源代码漏洞。这些基于 DL 的技术属于第二类方法 (即基于模式的方法)。它们不需要专家手动定义功能,并且可以自动生成漏洞模式。例如,一些先前的研究将源代码视为文本,并应用自然语言处理领域的技术来检测漏洞。这些基于文本的方法的检测性能并不理想,因为它们忽略了源代码的程序语义。为了解决这个问题,研究人员进行程序分析,将源代码的程序语义提炼成图形表示,并执行图形分析 (例如,图形神经网络) 来检测漏洞。这些基于图的技术在检测漏洞方面可以实现更高的效率,但是它们的可扩展性比基于文本的方法差得多。此外,几乎所有这些方法都只关注将函数标记为易受攻击或非易受攻击,而无法确定哪些代码行可能更容易受到攻击。在本文中,作者的目标是在检测大规模源代码中的漏洞时同时实现准确性和可扩展性。本文的关键思想源自基于 DL 的图像分类,它可以处理数百万张图像,同时保持高精度,并且分类结果可以通过可视化技术进行解释。
本文主要方法
为什么使用三个中心性进行分析?
作者开篇问了这样一个问题:如何找出函数中不同代码行对程序语义的贡献?
如果我们直接将这些代码视为文本来处理它们,则所有代码行的度数为一,这可能会降低漏洞检测的准确性。一句话,一个图可以用它的邻接矩阵来表示,矩阵可以用所有节点的度来描述。因此,计算函数中的代码度数可能是保留图形细节的绝佳候选者。
在社交网络分析中,中心性分析已被提出来衡量网络中节点的重要性。
不同的中心性可以从不同的方面维护图的属性。
图像通常具有三个通道 (即红色、绿色和蓝色),它们共同作用以产生完整的图像。中心性分析的输出是一张图像,同时从三个方面保留了图的细节。
后文讨论中这样说道
中心性度量与图像通道颜色之间的关系。构建图像的目的是便于使用基于图像的模型(即CNN)进行漏洞检测,同时保留程序细节。因此,我们的功能图像有三个层次(与常规图像的格式相同),但常规图像中的三种颜色与功能图像中的三种中心性度量之间没有严格的对应关系。
方法流程
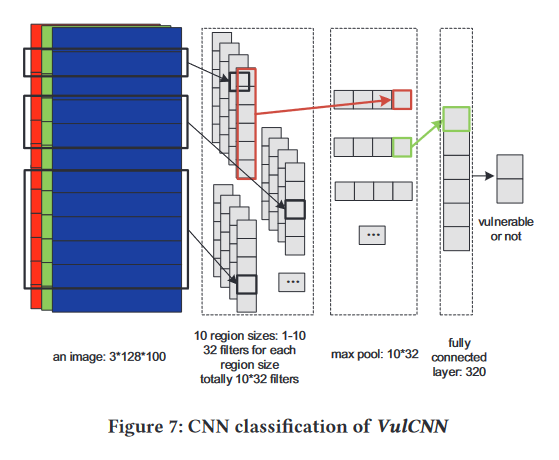
如图所示,VulCNN 主要由四个阶段组成:图提取 Graph Extraction 、句子嵌入 Sentence Embedding、图像生成 Image Generation 和分类 Classification。
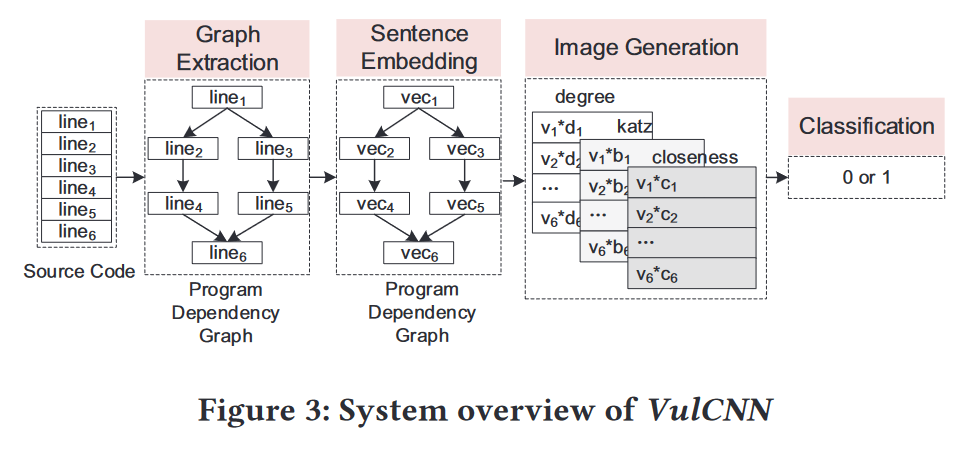
1. Graph Extraction:给定一个函数的源代码,首先对其进行归一化,然后进行静态分析,提取函数的程序依赖图 (PDG)。
2. Sentence Embedding:PDG 中的每个节点对应函数中的一行代码,作者将一行代码视为一个句子,并将它们嵌入到一个向量中。
由于文件级漏洞检测的粒度较粗,故本文检测函数级别的漏洞。首先对源代码进行抽象和规范化,然后再提取函数的图形表示。
本文使用了三个级别的规范化,这使得 VulCNN 能够适应常见的代码修改,同时保留程序语义。
第 1 步:删除源代码中的注释,因为它们与程序语义无关。
第 2 步:以一对一的方式将用户定义的变量映射到符号名称(例如,VAR1)。
第 3 步:以一对一的方式将用户定义的函数映射到符号名称(例如,FUN1)。
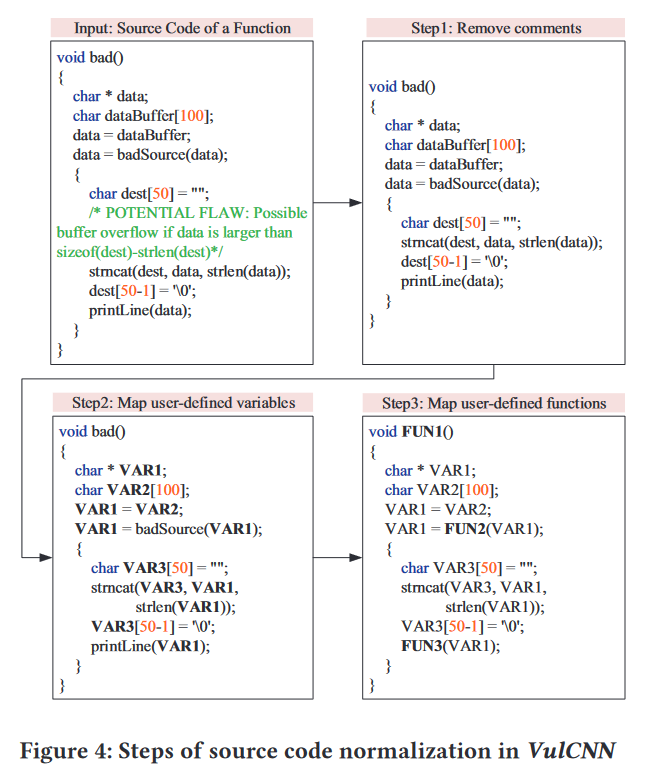
这种去除自定义变量函数名的方法在该团队的方法中很常见,例如Vuldeelocator。
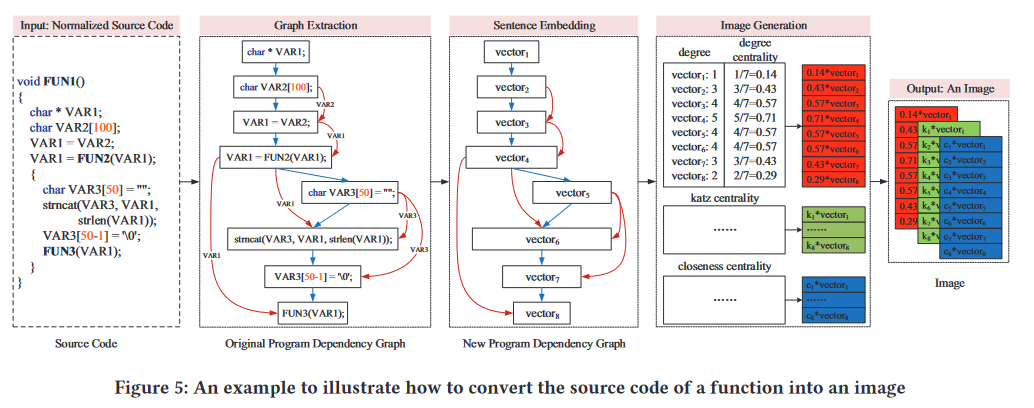
在对源代码进行抽象之后,本文利用 C/C++ 的开源代码分析平台 Joern 来提取函数的程序依赖图 (PDG)。 PDG 中的每个节点对应于函数中的一行代码。本文将一行代码视为一个句子,并应用句子嵌入将其转换为固定长度的向量。具体来说,本文利用 sent2vec 来完成句子嵌入。它采用简单但有效的无监督目标来训练句子的分布式表示。使用 sent2vec 模型,可以将一行代码转换为其相应的向量表示,在论文中其维度为 128。为了更好地说明本文提出的方法中涉及的详细步骤,作者在图 5 中提供了一个示例。图 5 中的红线和蓝线分别表示函数中不同代码行之间的数据流和控制流。
3. Image Generation:在句子嵌入之后,应用中心性分析来获得所有代码行的重要性并且将它们与向量一一相乘。此阶段的输出是图像。
在图提取和句子嵌入之后,可以得到一个新的 PDG,其中每个节点都是一个向量表示。接下来,本文将 PDG 视为一个社交网络,并应用社交网络中心性分析来获得所有代码行的重要性。
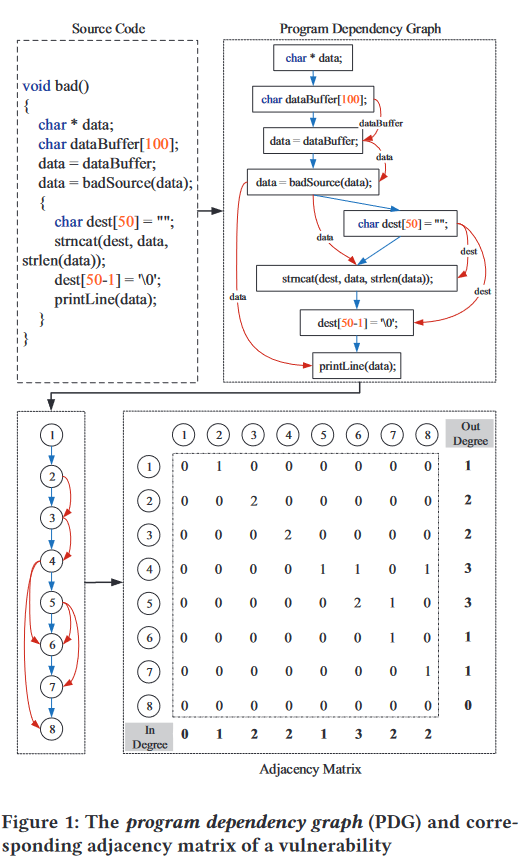
(这里生成邻接矩阵计算度的时候,将数据流和控制流作为同一种,不知道是否会对代码语义的理解造成影响?有待探究。)
因为图像通常具有三个通道(即红色、绿色和蓝色),它们共同作用以产生完整的图像。故本文选择三个不同的中心性(即Degree centrality、Katz centrality 和 Closeness centrality)来对应三个通道。这三个中心可以从三个不同的方面计算一个函数中所有代码行的重要性。这样,就可以全面考虑不同代码行对函数程序语义的贡献。算法 1 展示了 VulCNN 如何将函数转换为图像的整个过程。如图 5 和算法 1 所示,首先对新 PDG 中的所有节点进行度中心性分析,以收集所有节点(即向量)的度中心性。然后将所有向量乘以相应的度中心性后根据代码行数一一排列。作者将这些排列好的新向量称为"度数通道"。同理,对新的 PDG 应用Katz centrality 和 Closeness centrality 后,就可以得到另外两个通道,分别是 “katz channel” 和 “closeness channel”。最后,这三个通道用于生成图像。
简而言之,图像生成阶段的输入是一个新的 PDG,其中每个节点是一个嵌入向量,输出是具有所有代码行重要性的图像。
4. Classification:给定生成的图像,首先训练一个 CNN 模型,然后用它来检测漏洞。
在图像生成阶段之后,将函数的源代码转换为图像。给定一张图像,本文通过训练 CNN 模型来检测漏洞。由于 CNN 以相同大小的图像作为输入,而不同功能的代码行数不同,故需要进行调整。为了找到更合适的阈值来生成固定大小的图像,作者选择第 4 节中的实验数据集(即 40,657 个函数)作为测试对象,并记录所有这些函数的代码行数。结果显示超过 99% 的函数的代码行数少于 200 行。故本文输入的图像大小为 3∗100∗128,其中 3 对应三个通道,100 对应于代码行的阈值,以及 128 表示句子向量的维度。
实验
实验之前,作者提了三个问题。
RQ1:VulCNN在检测源码漏洞时的检测性能如何?
RQ2:VulCNN在检测源码漏洞时的运行时开销是多少?
RQ3:VulCNN能否实现大规模漏洞扫描?
数据集是SARD,c/c++源码数据集。12,303个Vul源代码文件和21,057个No-Vul源代码文件。
代码语句长度的选择
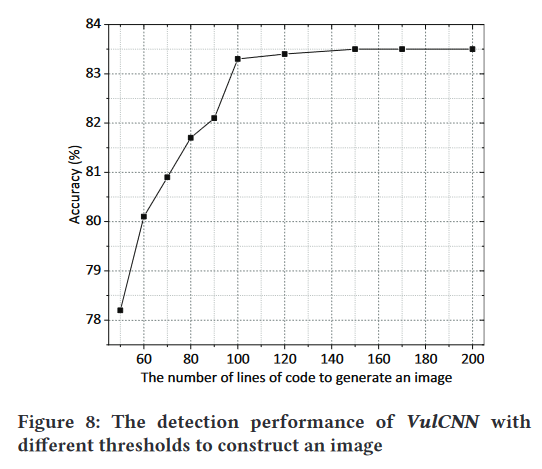
我们看到阈值与检测精度呈正相关,阈值越大,准确率越高。但是,当阈值达到 100 行时,精度的增长变得很小。一方面,由于 100 行代码的 VulCNN 检测精度几乎是最高的。另一方面,阈值越大,图像越大,所需的内存也就越多。因此,我们选择 100 行代码作为生成输入图像的最终阈值。
利用Gradientweighted Class Activation Mapping++ (Grad-CAM++)做可解释
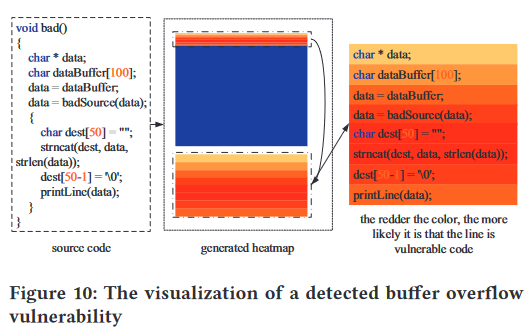
当 'data' 大于 'sizeof(dest) - strlen(dest)' 时,可触发此漏洞。在这种情况下,终端 null 将写入缓冲区之外。通过图 10,我们看到代码 'strncat(dest, data, strlen(data));' 的颜色是最红的,这意味着这行代码更有可能是易受攻击的代码。这一结果符合预期。
对比思考
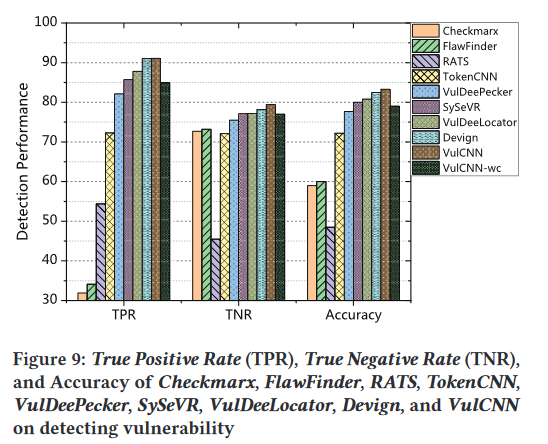
VulDeePecker 只对程序进行切片数据流分析,而 SySeVR 同时考虑控制流和数据流来获取程序切片。显然,SySeVR 比 VulDeePecker 性能更好,因为它包含更多的程序语义。但是,它们不考虑不同代码行对程序语义的不同贡献,而是将切片中的所有代码行视为文本,并直接应用 BRNN 来训练漏洞检测器。这就是为什么他们检测到的漏洞比 VulCNN.AsforVulDeeLocator 少的原因,它首先将程序编译为 LLVM 位码文件,然后提取中间表示 (IR) 切片以保留程序语义。最后,这些 IR 切片用于通过训练 BRNN 模型来检测漏洞。由于 IR 包含的程序详细信息多于源代码,因此 VulDeeLocator 可以比 VulDeePecker 和 SySeVR 区分更多的漏洞。然而,与 VulDeePecker 和 SySeVR 类似,VulDeeLocator 也将切片视为文本,导致性能低于 VulCNN.AsforDevign,它首先应用复杂的程序分析来提取包含综合程序语义的图表示,然后使用通用的图神经网络来检测漏洞。Devign 的检测性能与 VulCNN 几乎相同。但是,由于生成的图的复杂性,无法扩展到大规模漏洞扫描。但 VulCNN 可以,因为它使用中心性分析将耗时的图形分析转换为高效的图像扫描。为了验证中心性分析的使用是否有助于 VulCNN 检测漏洞,我们构建了另一个实验。更具体地说,在句子嵌入之后,我们直接将句子向量输入到 CNN 模型中以训练分类器,而无需乘以中心性。我们将该方法称为 VulCNN-wc(即没有中心性的 VulCNN),并将实验结果显示在图 9 中。通过图中可以看出,VulCNN优于VulCNN-wc,这表明考虑一个函数中不同代码行的中心性可以提高漏洞检测的检测精度。
运行时间开销
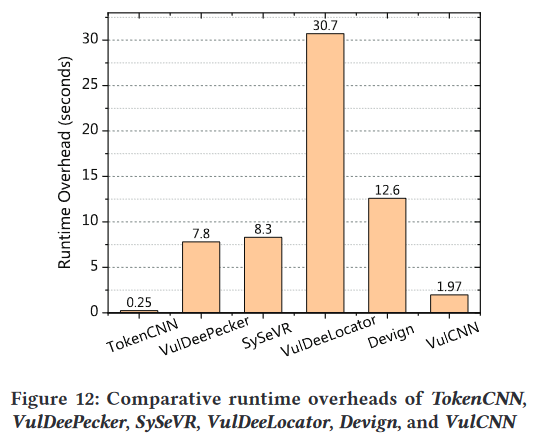
AsforTokenCNN,因为它只应用简单的词法分析来获取源代码令牌,并使用CNN模型来检测漏洞,所以它是最快的。
综上所述,虽然 VulCNN 的可扩展性不如 TokenCNN,但它比 VulDeePecker 和 SySeVR 快约 4 倍,比 VulDeeLocator 快约 15 倍,比 Devign 快约 6 倍。
开源项目实战
首先使用收集到的标记的 40,657 个函数训练 CNN 模型,包括 13,687 个易受攻击的函数和 26,970 个非易受攻击的函数。然后,从表2中超过2500万行代码中生成的600,233张图像被输入到经过训练的CNN模型中。在收集了 VulCNN 报告的所有警告后,我们再进行人工分析,将它们与我们收集的真实漏洞一一进行比较。如果发现两者属于同一模式,则判断为真正的漏洞。
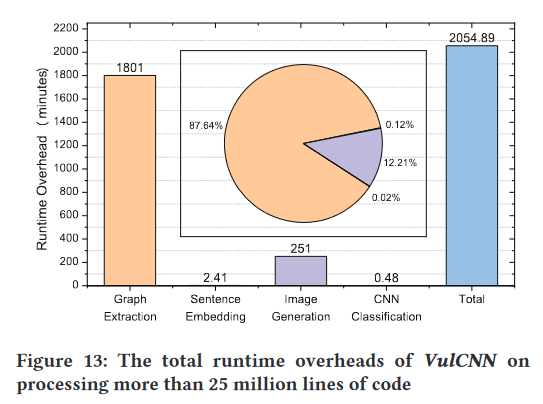
总时间消耗
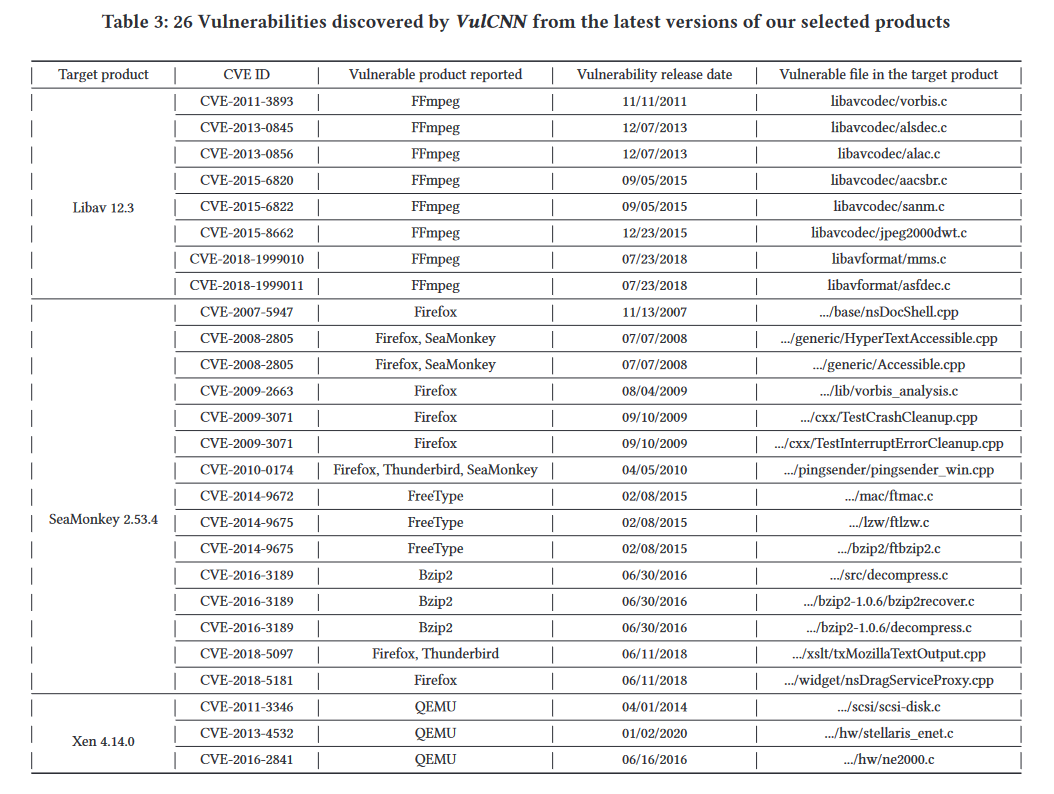
找到的已知漏洞
对比对象
- 基于令牌的工具(即 TokenCNN)
- 基于切片的工具(即 VulDeePecker)
- 基于位码的工具(即 VulDeeLocator)
- 基于图的工具(即 Devign)
- 三种传统的基于规则的工具(即 Checkmarx、FlawFinder 和 RATS)。
结果
本文实现了 VulCNN 并在 40657 个函数的数据集上对其进行评估,其中包括 13687 个易受攻击的函数和 26970 个非易受攻击的函数。评估结果表明,VulCNN 可以比 8 个比较漏洞检测器(即 Checkmarx、FlawFinder、RATS、TokenCNN、VulDeePecker、SySeVR、VulDeeLocator 和 Devign。此外,VulCNN 比最先进的基于图的漏洞检测工具 Devign 快六倍以上。为了验证 VulCNN 在大规模漏洞扫描方面的能力,本文对超过 2500 万行代码进行了案例研究。通过扫描报告,最终发现了 73 个未在 NVD 中报告的漏洞。其中,17个已被厂商在对应产品的最新版本中“默默”修补,4个漏洞已被删除,其余52个仍存在于产品中。作者已将这些漏洞报告给他们的供应商,并希望它们能够尽快得到修补。
未来工作
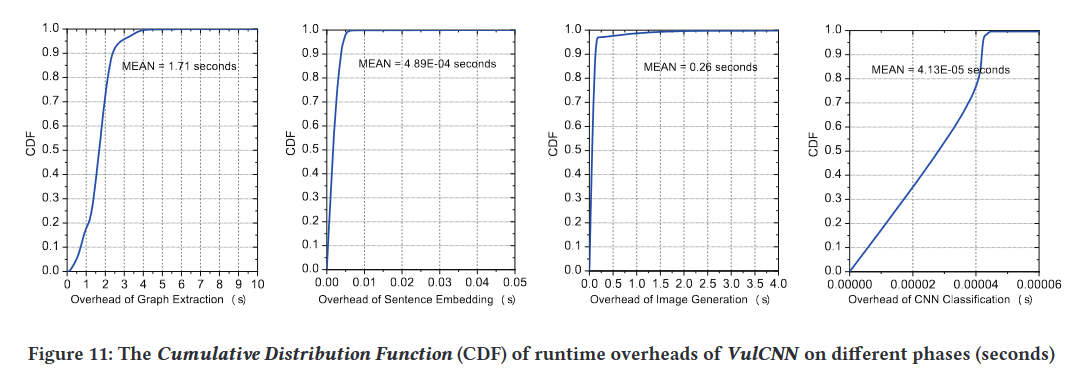
从图 13 的结果中可以看出,VulCNN 最耗时的阶段是提取函数的 PDG,这个阶段占据了总处理运行时间的 87% 以上。在未来的工作中,我们计划设计一种新的静态分析工具或尝试其他静态分析工具(例如Frama-C),以实现更高效的PDG生成。在 VulCNN 中,我们选择度中心性、katz 中心性和接近中心性来开始我们的图像转换。在实践中,也可以采用其他不同的中心性来保留图形细节。我们计划使用不同中心的不同组合来找到合适的组合,以实现 VulCNN 中更有效的图像转换。此外,由于大多数漏洞检测系统都是闭源的,我们只将 VulCNN 与八种工具(即 Checkmarx、FlawFinder、RATS、TokenCNN、VulDeePecker、SySeVR、VulDeeLocator 和 Devign)进行比较。我们将在今后的工作中对更多系统进行详细的对比分析。尽管 VulCNN 可以保持比比较工具更好的有效性,但其 TNR 并不理想。换句话说,我们检测到的一些漏洞可能是误报。在我们未来的工作中,我们计划利用定向模糊测试来缓解这种情况。
- END -
::: block-2
一个只记录最真实学习网络安全历程的小木屋,最新文章会在公众号更新,欢迎各位师傅关注!
公众号名称:网安小木屋

博客园主页:
博客园-我记得https://www.cnblogs.com/Zyecho/
:::
【论文阅读】VulCNN受图像启发的可扩展漏洞检测系统的更多相关文章
- 【笔记】论文阅读:《Gorilla: 一个快速, 可扩展的, 内存式时序数据库》
英文:Gorilla: A fast, scalable, in-memory time series database 中文:Gorilla: 一个快速, 可扩展的, 内存式时序数据库
- 论文阅读 | FoveaBox: Beyond Anchor-based Object Detector
论文阅读——FoveaBox: Beyond Anchor-based Object Detector 概述 这是一篇ArXiv 2019的文章,作者提出了一种新的anchor-free的目标检测框架 ...
- 论文阅读:Face Recognition: From Traditional to Deep Learning Methods 《人脸识别综述:从传统方法到深度学习》
论文阅读:Face Recognition: From Traditional to Deep Learning Methods <人脸识别综述:从传统方法到深度学习> 一.引 ...
- 论文阅读:《Bag of Tricks for Efficient Text Classification》
论文阅读:<Bag of Tricks for Efficient Text Classification> 2018-04-25 11:22:29 卓寿杰_SoulJoy 阅读数 954 ...
- YOLO 论文阅读
YOLO(You Only Look Once)是一个流行的目标检测方法,和Faster RCNN等state of the art方法比起来,主打检测速度快.截止到目前为止(2017年2月初),YO ...
- 深度学*点云语义分割:CVPR2019论文阅读
深度学*点云语义分割:CVPR2019论文阅读 Point Cloud Oversegmentation with Graph-Structured Deep Metric Learning 摘要 本 ...
- 论文阅读笔记二十二:End-to-End Instance Segmentation with Recurrent Attention(CVPR2017)
论文源址:https://arxiv.org/abs/1605.09410 tensorflow 代码:https://github.com/renmengye/rec-attend-public 摘 ...
- 论文阅读笔记十七:RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation(CVPR2017)
论文源址:https://arxiv.org/abs/1611.06612 tensorflow代码:https://github.com/eragonruan/refinenet-image-seg ...
- 论文阅读 | FCOS: Fully Convolutional One-Stage Object Detection
论文阅读——FCOS: Fully Convolutional One-Stage Object Detection 概述 目前anchor-free大热,从DenseBoxes到CornerNet. ...
- SSD: Single Shot MultiBox Detector论文阅读摘要
论文链接: https://arxiv.org/pdf/1512.02325.pdf 代码下载: https://github.com/weiliu89/caffe/tree/ssd Abstract ...
随机推荐
- Python - 字典1
字典用于存储键值对形式的数据.字典是一个有序.可更改的集合,不允许重复.从 Python 3.7 版本开始,字典是有序的.在 Python 3.6 及更早版本中,字典是无序的.字典用花括号编写,具有键 ...
- Python 列表操作指南2
将元组的元素添加到列表中: thislist = ["apple", "banana", "cherry"] thistuple = (&q ...
- identity4 系列————用户数据持久化篇[六]
前言 前面的例子已经将各种情形下的例子已经介绍了一遍,那么后面就是用户数据持久化该如何处理了. 正文 例子位置: https://github.com/IdentityServer/IdentityS ...
- js 连接数据库 提示:ActiveXObject is not defined
ActiveXObject is not defined 最近比较闲,上班瞎捣鼓一下,没想到报错了,提示ActiveXObject is not defined 大概是在js连接数据库时new对象使用 ...
- watch对比computed
总结: computed和watch之间的区别: 1.computed能完成的功能,Watch都可以实现 2.watch能完成的功能,comp ...
- 技术解读:现代化工具链在大规模 C++ 项目中的运用 | 龙蜥技术
简介: 本文详细介绍我们在实际工作中的大型 C++ 项目中现代化工具链的实践以及结果. 编者按:C++ 语言与编译器一直都在持续演进,出现了许多令人振奋的新特性,同时还有许多新特性在孵化阶.除此之外, ...
- 重磅官宣:Nacos2.0发布,性能提升10倍
简介: Nacos2.0 作为一个跨代版本,彻底解决了 Nacos1.X 的性能问题,将性能提升了 10 倍. 作者:席翁 继 Nacos 1.0 发布以来,Nacos 迅速被成千上万家企业采用,并 ...
- Fluid给数据弹性一双隐形的翅膀 (1) -- 自定义弹性伸缩
简介: 弹性伸缩作为Kubernetes的核心能力之一,但它一直是围绕这无状态的应用负载展开.而Fluid提供了分布式缓存的弹性伸缩能力,可以灵活扩充和收缩数据缓存. 它基于Runtime提供了缓存空 ...
- 多任务多目标CTR预估技术
简介: 多目标(Multi Objective Learning)是MTL中的一种.在业务场景中,经常面临既要又要的多目标问题.而多个目标常常会有冲突.如何使多个目标同时得到提升,是多任务多目标在真 ...
- [Go] assignment count mismatch 1 = 2
Golang 中这个错误的的意思是赋值变量的数目不匹配. 举例: result := json.Marshal(List) 由于没有给返回值中的 error 正确赋值,就会报 assignment ...