【赵渝强老师】搭建Hadoop环境
说明:这里我们以本地模式和伪分布模式伪列,为大家介绍如何搭建Hadoop环境。有了这个基础,大家可以自行搭建Hadoop的全分布模式。
需要使用的安装介质:
- hadoop-2.7.3.tar.gz
- jdk-8u181-linux-x64.tar.gz
- rhel-server-7.4-x86_64-dvd.iso
一、安装前的准备工作
- 安装好Redhat Linux 7.4(安装包rhel-server-7.4-x86_64-dvd.iso),并在Linux上创建tools和training两个目录

- 关闭防火墙,执行下面的命令
systemctl stop firewalld.service
systemctl disable firewalld.service
- 配置主机名,使用vi编辑器编辑文件/etc/hosts,输入以下内容
bigdata111 192.168.157.111
- 配置免密码登录,在命令行中输入下面的命令
ssh-keygen -t rsa
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata111
二、安装JDK
- 通过FTP工具将jdk-8u181-linux-x64.tar.gz和hadoop-2.7.3.tar.gz上传到Linux的/root/tools目录
- 在xshell中,解压jdk-8u181-linux-x64.tar.gz,执行下面的命令
tar -zxvf jdk-8u181-linux-x64.tar.gz -C /root/training/
- 设置Java的环境变量,使用vi编辑器编辑~/.bash_profile文件。执行下面的命令
vi /root/.bash_profile
- 在vi编辑器中,输入以下内容
JAVA_HOME=/root/training/jdk1.8.0_181
export JAVA_HOME PATH=$JAVA_HOME/bin:$PATH
export PATH
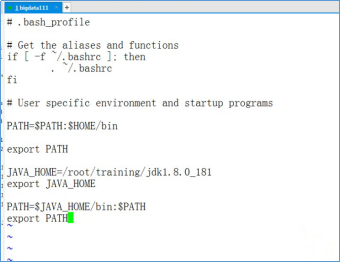
- 生效环境变量,执行下面的命令
source /root/.bash_profile

- 输入下图中,红框中的命令验证Java环境
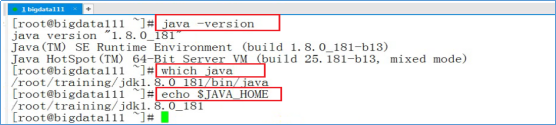
三、解压Hadoop,并设置环境变量
- 执行下面的命令,解压hadoop-2.7.3.tar.gz
tar -zxvf hadoop-2.7.3.tar.gz -C ~/training/
- 设置Hadoop的环境变量,编辑~/.bash_profile文件,并输入以下内容
HADOOP_HOME=/root/training/hadoop-2.7.3
export HADOOP_HOME PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
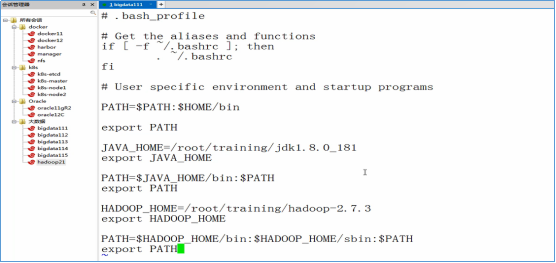
- 生效环境变量
source ~/.bash_profile
四、搭建Hadoop的本地模式
- 进入目录/root/training/hadoop-2.7.3/etc/hadoop
- 使用vi编辑器编辑文件:hadoop-env.sh
- 修改JAVA_HOME
export JAVA_HOME=/root/training/jdk1.8.0_181

- 测试Hadoop的本地模式,执行MapReduce程序。准备测试数据:vi ~/temp/data.txt
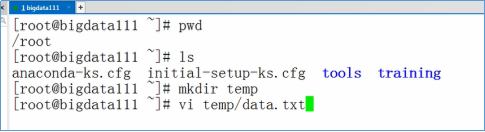
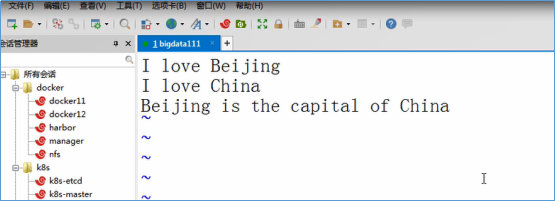
- 输入下面的数据,并保存退出
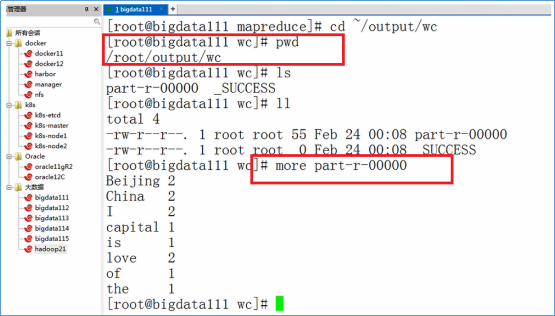
- 进入目录:/root/training/hadoop-2.7.3/share/hadoop/mapreduce

- 执行WordCount任务
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /root/temp /root/output/wc
- 根据下图的命令,查看输出结果
五、搭建Hadoop的伪分布模式
- 首先,搭建好Hadoop的本地模式
- 创建目录:/root/training/hadoop-2.7.3/tmp
mkdir /root/training/hadoop-2.7.3/tmp
- 进入目录:/root/training/hadoop-2.7.3/etc/hadoop
cd /root/training/hadoop-2.7.3/etc/hadoop
- 修改hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
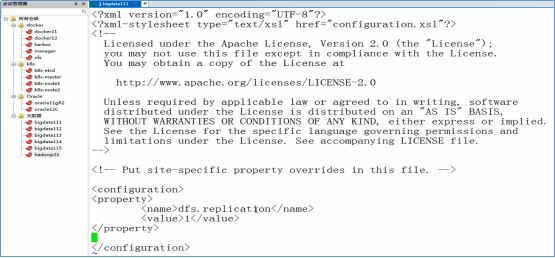
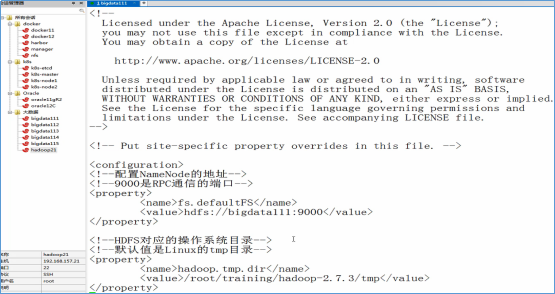
- 修改core-site.xml
<!--配置NameNode的地址-->
<!--9000是RPC通信的端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata111:9000</value>
</property> <!--HDFS对应的操作系统目录-->
<!--默认值是Linux的tmp目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-2.7.3/tmp</value>
</property>
- 修改mapred-site.xml(注意:这个文件默认没有)
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

- 修改yarn-site.xml
<!--配置ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata111</value>
</property> <!--MapReduce运行的方式是洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>

- 格式化NameNode
hdfs namenode -format

- 启动Hadoop
start-all.sh

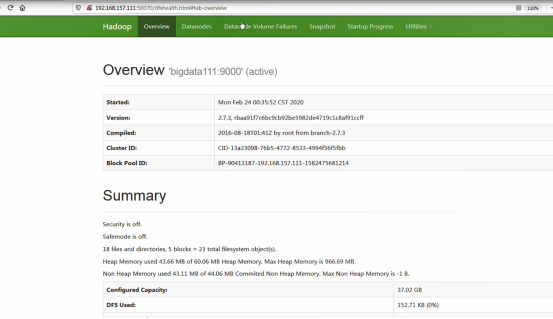
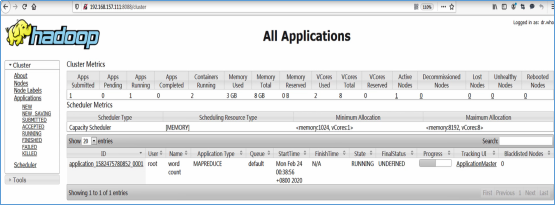
- 访问Web Console
http://192.168.157.111:50070
http://192.168.157.111:8088

【赵渝强老师】搭建Hadoop环境的更多相关文章
- 【一】、搭建Hadoop环境----本地、伪分布式
## 前期准备 1.搭建Hadoop环境需要Java的开发环境,所以需要先在LInux上安装java 2.将 jdk1.7.tar.gz 和hadoop 通过工具上传到Linux服务器上 3. ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) (转载)
Hadoop在处理海量数据分析方面具有独天优势.今天花了在自己的Linux上搭建了伪分布模式,期间经历很多曲折,现在将经验总结如下. 首先,了解Hadoop的三种安装模式: 1. 单机模式. 单机模式 ...
- (转)超详细单机版搭建hadoop环境图文解析
超详细单机版搭建hadoop环境图文解析 安装过程: 一.安装Linux操作系统 二.在Ubuntu下创建hadoop用户组和用户 三.在Ubuntu下安装 ...
- 基于CentOS与VmwareStation10搭建hadoop环境
基于CentOS与VmwareStation10搭建hadoop环境 目 录 1. 概述.... 1 1.1. 软件准备.... 1 1.2. 硬件准备.... 1 2. 安装与配置虚拟机.. ...
- 基于《Hadoop权威指南 第三版》在Windows搭建Hadoop环境及运行第一个例子
在Windows环境上搭建Hadoop环境需要安装jdk1.7或以上版本.有了jdk之后,就可以进行Hadoop的搭建. 首先下载所需要的包: 1. Hadoop包: hadoop-2.5.2.tar ...
- Docker搭建Hadoop环境
文章目录 Docker搭建Hadoop环境 Docker的安装与使用 拉取镜像 克隆配置脚本 创建网桥 执行脚本 Docker命令补充 更换镜像源 安装vim 启动Hadoop 测试Word Coun ...
- Linux 下搭建 Hadoop 环境
Linux 下搭建 Hadoop 环境 作者:Grey 原文地址: 博客园:Linux 下搭建 Hadoop 环境 CSDN:Linux 下搭建 Hadoop 环境 环境要求 操作系统:CentOS ...
- 虚拟机搭建hadoop环境
这里简单用三台虚拟机,搭建了一个两个数据节点的hadoop机群,仅供新人学习.零零碎碎,花了大概一天时间,总算完成了. 环境 Linux版本:CentOS 6.5 VMware虚拟机 jdk1.6.0 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
首先要了解一下Hadoop的运行模式: 单机模式(standalone) 单机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选 ...
- 使用docker搭建hadoop环境,并配置伪分布式模式
docker 1.下载docker镜像 docker pull registry.cn-hangzhou.aliyuncs.com/kaibb/hadoop:latest 注:此镜像为阿里云个人上传镜 ...
随机推荐
- php环境-2024年3月19日
laravel 6[laravel的orm比其他框架的好用,可以写很少的代码就能完成] php 7.4 mysql 5.7 centos7 redis jwt 队列(laravel的redis队列,或 ...
- 机器学习:详解是否要使用端到端的深度学习?(Whether to use end-to-end learning?)
详解是否要使用端到端的深度学习? 假设正在搭建一个机器学习系统,要决定是否使用端对端方法,来看看端到端深度学习的一些优缺点,这样就可以根据一些准则,判断的应用程序是否有希望使用端到端方法. 这里是应用 ...
- 安卓开发(java.lang.NullPointerException: Attempt to invoke virtual method ‘void android.view.View...)空指针异常
无论是初学者还是做开发很久的人都会遇到这个问题,那就是空指针异常: 遇到这种情况我们首先不要惊慌,一般这个问题都不是很大的问题,只需要我们 静下心来慢慢的查找,下面分成几步来带你查找问题: 1:首先是 ...
- 【Spring】02 过程分析
回顾JavaWeb三层架构设计: UserDao接口 public interface UserDao { void getUser(); } 实现类 public class UserDaoImpl ...
- 【Scala】05 对象特性Part2
特质重复继承关系 父类特质 A 子类特质B 继承 A 子类特质C 继承A 类D 继承了 B 又实现了 C class D extends B with C 继承顺序是 D 继承 C 继承 B 继承 A ...
- 【转载】人工智能CAE仿真分析技术
原文: https://cloud.tencent.com/developer/news/628731 AI与CAE相结合 CAE的本质是对复杂工程问题通过合理简化建立数学模型,并根据输入求得输出.深 ...
- tmux开启鼠标模式
在tmux的配置文件中进行配置: vim ~/.tmux.conf set -g mouse on
- 韩国网费比其他国家贵10倍?—— 因网费太高,直播平台 Twitch 宣布2024年2月退出韩国市场
看新闻,说直播平台 Twitch因为韩国的网费太贵宣布退出韩国,这个新闻给我看纳闷了,从来么有听说过哪个视频或直播公司因为网费贵而关停,这个估计是这种原因关停的第一家吧,于是比较好奇. 相关: htt ...
- 神经网络初始化:xavier,kaiming、ortho正交初始化在CNN网络中的使用
xavier.ortho是神经网络中常用的权重初始化方法,在全连接中这两种权重初始化的方法比较好理解,但是在CNN的卷积网络中的具体实现却不好理解了. 在CNN网络中xavier的初始化可以参看: [ ...
- 高效调度新篇章:详解DolphinScheduler 3.2.0生产级集群搭建
转载自tuoluzhe8521 导读:通过简化复杂的任务依赖关系, DolphinScheduler为数据工程师提供了强大的工作流程管理和调度能力.在3.2.0版本中,DolphinScheduler ...