Falcon Mamba: 首个高效的无注意力机制 7B 模型
Falcon Mamba 是由阿布扎比的 Technology Innovation Institute (TII) 开发并基于 TII Falcon Mamba 7B License 1.0 的开放获取模型。该模型是开放获取的,所以任何人都可以在 Hugging Face 生态系统中 这里 使用它进行研究或应用。
在这篇博客中,我们将深入模型的设计决策、探究模型与其他现有的 SoTA 模型相比的竞争力,以及如何在 Hugging Face 生态系统中使用它。
第一款通用的大规模纯 Mamba 模型
目前,所有顶级大型语言模型都使用基于注意力机制的 Transformer 架构。然而,由于计算和内存成本随序列长度增加而增加,注意力机制在处理大序列时存在根本性的局限性。状态空间语言模型 (SSLMs) 等各种替代架构尝试解决序列扩展的限制,但在性能上仍不及最先进的 Transformer 架构模型。
通过 Falcon Mamba,我们证明了序列扩展的限制确实可以在不损失性能的情况下克服。Falcon Mamba 基于原始的 Mamba 架构,该架构在 Mamba: Linear-Time Sequence Modeling with Selective State Spaces 中提出,并增加了额外的 RMS 标准化层以确保大规模稳定训练。这种架构选择确保 Falcon Mamba:
- 能够处理任意长度的序列,而不增加内存存储,特别是适用于单个 A10 24GB GPU。
- 生成新令牌的时间是恒定的,不论上下文的大小。
模型训练
Falcon Mamba 训练所用的数据量约为 5500GT,主要包括经过精选的网络数据,并补充了来自公开源的高质量技术和代码数据。我们在大部分训练过程中使用恒定的学习率,随后进行了一个相对较短的学习率衰减阶段。在最后这个阶段,我们还添加了一小部分高质量的策划数据,以进一步提高模型性能。
模型评估
我们使用 lm-evaluation-harness 包在新排行榜版本的所有基准上评估我们的模型,然后使用 Hugging Face 分数规范化方法规范化评估结果。model name``IFEval``BBH``MATH LvL5``GPQA``MUSR``MMLU-PRO``Average
model name |
IFEval |
BBH |
MATH LvL5 |
GPQA |
MUSR |
MMLU-PRO |
Average |
|---|---|---|---|---|---|---|---|
| Pure SSM models | |||||||
Falcon Mamba-7B |
33.36 | 19.88 | 3.63 | 8.05 | 10.86 | 14.47 | 15.04 |
TRI-ML/mamba-7b-rw* |
22.46 | 6.71 | 0.45 | 1.12 | 5.51 | 1.69 | 6.25 |
| Hybrid SSM-attention models | |||||||
recurrentgemma-9b |
30.76 | 14.80 | 4.83 | 4.70 | 6.60 | 17.88 | 13.20 |
Zyphra/Zamba-7B-v1* |
24.06 | 21.12 | 3.32 | 3.03 | 7.74 | 16.02 | 12.55 |
| Transformer models | |||||||
Falcon2-11B |
32.61 | 21.94 | 2.34 | 2.80 | 7.53 | 15.44 | 13.78 |
Meta-Llama-3-8B |
14.55 | 24.50 | 3.25 | 7.38 | 6.24 | 24.55 | 13.41 |
Meta-Llama-3.1-8B |
12.70 | 25.29 | 4.61 | 6.15 | 8.98 | 24.95 | 13.78 |
Mistral-7B-v0.1 |
23.86 | 22.02 | 2.49 | 5.59 | 10.68 | 22.36 | 14.50 |
Mistral-Nemo-Base-2407 (12B) |
16.83 | 29.37 | 4.98 | 5.82 | 6.52 | 27.46 | 15.08 |
gemma-7B |
26.59 | 21.12 | 6.42 | 4.92 | 10.98 | 21.64 | 15.28 |
此外,我们使用 lighteval 工具在 LLM 排行榜第一版的基准测试上对模型进行了评估。model name``ARC``HellaSwag``MMLU``Winogrande``TruthfulQA``GSM8K``Average
model name |
ARC |
HellaSwag |
MMLU |
Winogrande |
TruthfulQA |
GSM8K |
Average |
|---|---|---|---|---|---|---|---|
| Pure SSM models | |||||||
Falcon Mamba-7B* |
62.03 | 80.82 | 62.11 | 73.64 | 53.42 | 52.54 | 64.09 |
TRI-ML/mamba-7b-rw* |
51.25 | 80.85 | 33.41 | 71.11 | 32.08 | 4.70 | 45.52 |
| Hybrid SSM-attention models | |||||||
recurrentgemma-9b** |
52.00 | 80.40 | 60.50 | 73.60 | 38.60 | 42.60 | 57.95 |
Zyphra/Zamba-7B-v1* |
56.14 | 82.23 | 58.11 | 79.87 | 52.88 | 30.78 | 60.00 |
| Transformer models | |||||||
Falcon2-11B |
59.73 | 82.91 | 58.37 | 78.30 | 52.56 | 53.83 | 64.28 |
Meta-Llama-3-8B |
60.24 | 82.23 | 66.70 | 78.45 | 42.93 | 45.19 | 62.62 |
Meta-Llama-3.1-8B |
58.53 | 82.13 | 66.43 | 74.35 | 44.29 | 47.92 | 62.28 |
Mistral-7B-v0.1 |
59.98 | 83.31 | 64.16 | 78.37 | 42.15 | 37.83 | 60.97 |
gemma-7B |
61.09 | 82.20 | 64.56 | 79.01 | 44.79 | 50.87 | 63.75 |
对于用 星号 标记的模型,我们内部评估了任务; 而对于标有两个 星号 的模型,结果来自论文或模型卡片。
处理大规模序列
基于 SSM (状态空间模型) 在处理大规模序列方面理论上的效率,我们使用 optimum-benchmark 库比较了 Falcon Mamba 与流行的 Transformer 模型在内存使用和生成吞吐量上的差异。为了公平比较,我们调整了所有 Transformer 模型的词汇大小以匹配 Falcon Mamba,因为这对模型的内存需求有很大影响。
在介绍结果之前,首先讨论提示 (prefill) 和生成 (decode) 部分序列的区别。我们将看到,对于状态空间模型而言,prefill 的细节比 Transformer 模型更为重要。当 Transformer 生成下一个令牌时,它需要关注上下文中所有之前令牌的键和值。这意味着内存需求和生成时间都随上下文长度线性增长。状态空间模型仅关注并存储其循环状态,因此不需要额外的内存或时间来生成大序列。虽然这解释了 SSM 在解码阶段相对于 Transformer 的优势,但 prefill 阶段需要额外努力以充分利用 SSM 架构。
prefill 的标准方法是并行处理整个提示,以充分利用 GPU。这种方法在 optimum-benchmark 库中被使用,并被我们称为并行 prefill。并行 prefill 需要在内存中存储提示中每个令牌的隐藏状态。对于 Transformer,这额外的内存主要由存储的 KV 缓存所占据。对于 SSM 模型,不需要缓存,存储隐藏状态的内存成为与提示长度成比例的唯一组成部分。结果,内存需求将随提示长度扩展,SSM 模型将失去处理任意长序列的能力,与 Transformer 类似。
另一种 prefill 方法是逐令牌处理提示,我们将其称为 顺序 prefill 。类似于序列并行性,它也可以在更大的提示块上执行,而不是单个令牌,以更好地利用 GPU。虽然对于 Transformer 来说,顺序 prefill 几乎没有意义,但它让 SSM 模型重新获得了处理任意长提示的可能性。
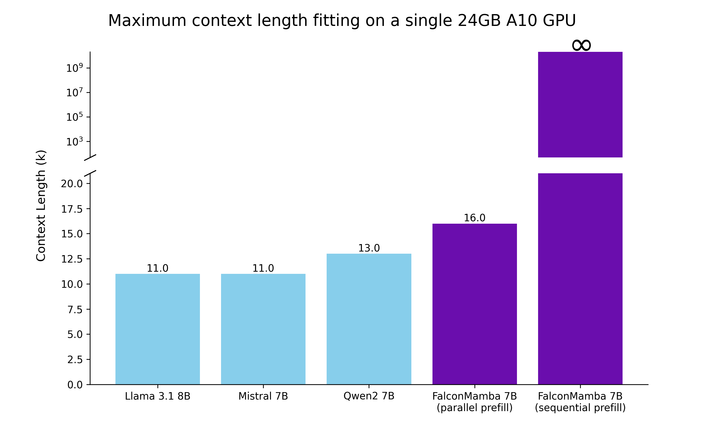
基于这些考虑,我们首先测试了单个 24GB A10 GPU 可以支持的最大序列长度,具体结果请见下方的图表。批处理大小固定为 1,我们使用 float32 精度。即使对于并行 prefill,Falcon Mamba 也能适应比 Transformer 更大的序列,而在顺序 prefill 中,它释放了全部潜力,可以处理任意长的提示。
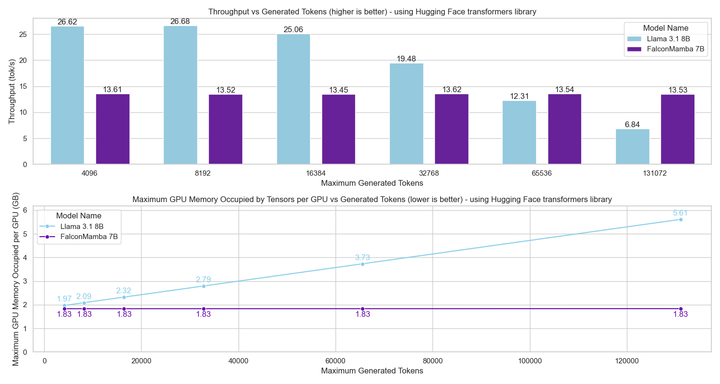
接下来,我们在提示长度为 1 且生成高达 130k 令牌的设置中测量生成吞吐量,使用批量大小 1 和 H100 GPU。结果报告在下方的图表中。我们观察到,我们的 Falcon Mamba 在恒定的吞吐量下生成所有令牌,且 CUDA 峰值内存没有增加。对于 Transformer 模型,峰值内存随生成令牌数的增加而增长,生成速度也随之减慢。
接下来,我们在使用单个 H100 GPU 和批量大小为 1 的设置中,测量了提示长度为 1 且生成高达 130,000 个令牌的生成吞吐量。结果显示在下方的图表中。我们观察到,我们的 Falcon Mamba 能够以恒定的吞吐量生成所有令牌,并且 CUDA 峰值内存没有任何增加。对于 Transformer 模型,随着生成令牌数量的增加,峰值内存增长,生成速度减慢。
在 Hugging Face transformers 中如何使用 Falcon Mamba?
Falcon Mamba 架构将在下一个版本的 Hugging Face transformers 库 (>4.45.0) 中提供。要使用该模型,请确保安装了最新版本的 Hugging Face transformers 或从源代码安装库。
Falcon Mamba 与 Hugging Face 提供的大多数 API 兼容,您可能已经熟悉了,如 AutoModelForCausalLM 或 pipeline :
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "tiiuae/falcon-mamba-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto", device_map="auto")
inputs = tokenizer("Hello world, today", return_tensors="pt").to(0)
output = model.generate(**inputs, max_new_tokens=100, do_sample=True)
print(tokenizer.decode(Output[0], skip_special_tokens=True))
由于模型较大,它还支持诸如 bitsandbytes 量化的特性,以便在较小的 GPU 内存限制下运行模型,例如:
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_id = "tiiuae/falcon-mamba-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config)
inputs = tokenizer("Hello world, today", return_tensors="pt").to(0)
output = model.generate(**inputs, max_new_tokens=100, do_sample=True)
print(tokenizer.decode(output[0], skip_special_tokens=True))
我们很高兴继续介绍 Falcon Mamba 的指令调优版本,该版本已通过额外的 50 亿令牌的监督微调 (SFT) 数据进行了微调。这种扩展训练增强了模型执行指令任务的精确性和有效性。您可以通过我们的演示体验指令模型的功能,演示可在 此处 找到。对于聊天模板,我们使用以下格式:
<|im_start|>user
prompt<|im_end|>
<|im_start|>assistant
您也可以选择使用 基础模型 及其 指令模型 的 4 位转换版本。确保您有权访问与 bitsandbytes 库兼容的 GPU 来运行量化模型。
您还可以使用 torch.compile 实现更快的推理; 只需在加载模型后调用 model = torch.compile(model) 。
致谢
我们感谢 Hugging Face 团队在整合过程中提供的无缝支持,特别鸣谢以下人员:
- Alina Lozovskaya 和 Clementine Fourrier 帮助我们在排行榜上评估模型
- Arthur Zucker 负责 transformers 的整合
- Vaibhav Srivastav, hysts 和 Omar Sanseviero 在 Hub 相关问题上提供的支持
作者还要感谢 Tri Dao 和 Albert Gu 将 Mamba 架构实现并开源给社区。
英文原文: https://hf.co/blog/falconmamba
原文作者: Jingwei Zuo, Maksim Velikanov, Rhaiem, Ilyas Chahed, Younes Belkada, Guillaume Kunsch
译者: Evinci
Falcon Mamba: 首个高效的无注意力机制 7B 模型的更多相关文章
- TensorFlow从1到2(十)带注意力机制的神经网络机器翻译
基本概念 机器翻译和语音识别是最早开展的两项人工智能研究.今天也取得了最显著的商业成果. 早先的机器翻译实际脱胎于电子词典,能力更擅长于词或者短语的翻译.那时候的翻译通常会将一句话打断为一系列的片段, ...
- 深度学习之注意力机制(Attention Mechanism)和Seq2Seq
这篇文章整理有关注意力机制(Attention Mechanism )的知识,主要涉及以下几点内容: 1.注意力机制是为了解决什么问题而提出来的? 2.软性注意力机制的数学原理: 3.软性注意力机制. ...
- Seq2Seq模型与注意力机制
Seq2Seq模型 基本原理 核心思想:将一个作为输入的序列映射为一个作为输出的序列 编码输入 解码输出 解码第一步,解码器进入编码器的最终状态,生成第一个输出 以后解码器读入上一步的输出,生成当前步 ...
- JDK1.8 LongAdder 空间换时间: 比AtomicLong还高效的无锁实现
我们知道,AtomicLong的实现方式是内部有个value 变量,当多线程并发自增,自减时,均通过CAS 指令从机器指令级别操作保证并发的原子性. // setup to use Unsafe.co ...
- CAP:多重注意力机制,有趣的细粒度分类方案 | AAAI 2021
论文提出细粒度分类解决方案CAP,通过上下文感知的注意力机制来帮助模型发现细微的特征变化.除了像素级别的注意力机制,还有区域级别的注意力机制以及局部特征编码方法,与以往的视觉方案很不同,值得一看 来源 ...
- 自然语言处理中的自注意力机制(Self-attention Mechanism)
自然语言处理中的自注意力机制(Self-attention Mechanism) 近年来,注意力(Attention)机制被广泛应用到基于深度学习的自然语言处理(NLP)各个任务中,之前我对早期注意力 ...
- DeepLearning.ai学习笔记(五)序列模型 -- week2 序列模型和注意力机制
一.基础模型 假设要翻译下面这句话: "简将要在9月访问中国" 正确的翻译结果应该是: "Jane is visiting China in September" ...
- 自注意力机制(Self-attention Mechanism)——自然语言处理(NLP)
近年来,注意力(Attention)机制被广泛应用到基于深度学习的自然语言处理(NLP)各个任务中.随着注意力机制的深入研究,各式各样的attention被研究者们提出.在2017年6月google机 ...
- 推荐系统中的注意力机制——阿里深度兴趣网络(DIN)
参考: https://zhuanlan.zhihu.com/p/51623339 https://arxiv.org/abs/1706.06978 注意力机制顾名思义,就是模型在预测的时候,对用户不 ...
- Non-local Neural Networks 原理详解及自注意力机制思考
Paper:https://arxiv.org/abs/1711.07971v1 Author:Xiaolong Wang, Ross Girshick, Abhinav Gupta, Kaiming ...
随机推荐
- LitCTF 2023 部分wp
LitCTF 2023 PWN 只需要nc一下~ 根目录下的是假flag,真的在环境变量里 口算题卡 简单的计算题 import pwn io = pwn.remote("node5.ann ...
- 薅 AWS 羊毛的船新方式,以 ChatBot 为例
还在担心一年免费服务器到期后该怎么办?(Solo社区 投稿) 网上绝大多数薅 AWS 羊毛的教程都是在教大家如何申请创建一年免费的 VPS,太 OUT 了!就问一个问题,一年到期了那咋办? 其实,除了 ...
- 3分钟带你搞定Spring Boot中Schedule
一.背景介绍 在实际的业务开发过程中,我们经常会需要定时任务来帮助我们完成一些工作,例如每天早上 6 点生成销售报表.每晚 23 点清理脏数据等等. 如果你当前使用的是 SpringBoot 来开发项 ...
- Python 基于pymongo操作Mongodb学习总结
实践环境 Python 3.6.4 pymongo 4.1.1 pymongo-3.12.3-cp36-cp36m-win_amd64.whl 下载地址:https://pypi.org/simple ...
- LM Studio + open-webui 快速本地部署大语言模型
目录 一.前言 二.环境准备 三.安装设置 四.下载模型并运行 五.配置 open-webui 写在结尾 一.前言 自 OpenAi 发布 ChatGPT 对话性大语言模型,AI 这两年发展迎来爆发, ...
- 2023/4/21 SCRUM个人博客
1.我昨天的任务 学习信号和槽的定义并完善UI界面的基础知识 2.遇到了什么困难 难以理解design的设计理念 3.我今天的任务 学习如何使用QTdesign,并完善UI
- golang对遍历目录操作的优化
一转眼go1.23都快发布了,时间过得真快. 不过今天我们把时间倒流回三年半之前,来关注一个在go1.16引入的关于处理目录时的优化. 对于go1.16的新变化,大家印象最深的可能是io包的大规模重构 ...
- Jmeter函数助手24-longSum
longSum函数可用于计算两个或多个长值的和.intSum函数参数值的范围在-2147483648到2147483647之间,而longSum函数的参数值范围比intSum的大. First lon ...
- 【Dos-BatchPrograming】03
--1.AT 计划任务 Microsoft Windows [版本 10.0.19041.746] (c) 2020 Microsoft Corporation. 保留所有权利. C:\Users\A ...
- 【Docker】08 部署挂载本地目录的MySQL
拉取MySQL镜像: docker pull mysql:8.0.21 执行挂载运行MySQL容器的命令: docker run -dit \ --name mysql-test \ -p 3306: ...