性能提升1400+倍,快来看MySQL Volcano模型迭代器的谓词位置优化详解
摘要:性能提升1400+倍,快来看MySQL Volcano模型迭代器的谓词位置优化详解。
本文分享自华为云社区《华为云数据库内核专家为您揭秘MySQL Volcano模型迭代器性能提升千倍的秘密》,作者:GaussDB 数据库 。

20年以上数据库内核研发经验。原IBM DB2数据库内核专家,专长数据库内核性能优化、SQL查询优化、MPP分布式数据仓库技术等。现就职于华为加拿大研究所,全程参与了RDS for MySQL以及GaussDB(for MySQL)的研发工作,熟悉GaussDB(for MySQL) 全栈技术。负责NDP的总体架构设计和实现,并成功落地上线。拥有多项技术发明专利,并co-author了SIGMOD 2020 Taurus( GaussDB(for MySQL)) Paper,目前专注于下一代云数据库智能优化器的研究。
一、背景介绍
MySQL 8.0.18引入了一个新的SQL执行引擎,它遵循了Volcano模型。该模型的关键思想是将所有操作建模为“迭代器”。迭代器提供基本迭代组件:初始化、迭代和终止。所有迭代器都提供如以上相同的接口,因此迭代器可以任意组合堆叠在一起,形成执行计划。
MySQL 8.0.18还包括一个新的连接方法:哈希连接。哈希连接有探测端和构建端。哈希表是使用构建端的连接列作为哈希键值构建的;然后使用探测端的连接列来查找哈希表中的匹配行。
关于Volcano模型和哈希连接的细节不在本文的范围内。本文重点讨论一个问题,即哈希连接的谓词没有附加到合适的哈希连接迭代器,该问题可能会导致严重的性能下降。请注意:这不是一个功能问题,因为尽管有显著的性能下降,但最终的查询结果是正确的。
华为云数据库内核专家林舒向MySQL官方提交了此错误报告,以及对应的补丁,具体信息请参考这里:https://bugs.mysql.com/?id=104760。在本文中,我们将通过一个示例查询,来说明此问题,并比较应用补丁前后的性能差异。
本文中的查询在MySQL 8.0.26上测试,使用100MB的TPC-H数据库。为了说明问题,在查询语句中使用了索引提示(Index Hint)来促使SQL优化器选择哈希连接。
二、问题描述
该问题使用的查询及其执行计划如下:
问题查询:
explain format=tree
select avg(case ps_partkey when null then 1 else l_quantity end)
from lineitem left outer join
( partsupp ignore index (primary) join part ignore index (primary) on ps_partkey = p_partkey and p_name like '%snow%')
on ps_suppkey = l_suppkey and ps_partkey = l_partkey
执行计划:

-> Aggregate: avg((case partsupp.PS_PARTKEY when NULL then 1 else lineitem.L_QUANTITY end)) (cost=179829230844583.70 rows=899131908749360)
-> Left hash join (part.P_PARTKEY = lineitem.L_PARTKEY), (partsupp.PS_PARTKEY = lineitem.L_PARTKEY), (partsupp.PS_SUPPKEY = lineitem.L_SUPPKEY) (cost=89916039969647.67 rows=899131908749360)
-> Table scan on lineitem (cost=61043.00 rows=596410)
-> Hash
-> Filter: (part.P_NAME like '%snow%') (cost=2849092735.78 rows=1507573496)
-> Inner hash join (no condition) (cost=2849092735.78 rows=1507573496)
-> Table scan on partsupp (cost=0.23 rows=77726)
-> Hash
-> Table scan on part (cost=0.01 rows=19396)
注意以上查询计划的内哈希连接(Inner hash join)部分,partsupp和part之间的连接是“无条件”的,而谓词(part.P_NAME like“%snow%”)是在内哈希连接完成之后才被应用来过滤结果集的。观察原始查询语句,我们会注意到,partsupp和part之间存在一个连接谓词(ps_partkey = p_partkey),这个谓词去哪里了呢?它隐含在外层的左哈希连接(Left hash join)的连接谓词中,即 (part.P_PARTKEY = lineitem.L_PARTKEY)和(partupp.PS_PartKEY=lineitem.L_PartKEY)这两个谓词描述里。在内哈希连接中缺少谓词会导致性能问题,因为它使得有谓词的连接操作被替换为笛卡尔积,由于缺少连接条件进行过滤,结果集会被放大。此外,本地谓词(part.P_NAME like“%snow%”),可以在内哈希连接之前被应用,提前过滤掉无效的行。
三、原因分析
这个问题发生的场景是,一个语句使用了外连接,而这个外连接选用哈希连接来完成,并且这个外连接的一部分涉及到了多于一张表。当这些条件同时具备,就可能会引发此问题。
在哈希连接中,其构建端是无法访问探测端上的任何列,反之亦然。一个引用了双端的谓词只能放置在哈希连接迭代器上。当MySQL优化器为表分配谓词时,它假定谓词可以引用表前面出现的所有表,然而这显然不适用于哈希连接。因此,当优化器的计划转换为迭代器计划时,优化器到迭代器的转换代码需要做出额外的补救,现在MySQL的转换代码中缺少相关的处理,导致了本文的问题。
四、如何修复
针对这个问题的修复主要专注在优化器结构到迭代器转换代码中的主函数:ConnectJoins()。基本的思路是让该函数知道哪些表在当前不是可用的,因为这些表位于哈希连接的另一边。当函数将谓词放置在迭代器上时,尚未应用的谓词将沿着迭代器向上推,并在所需的表可用后立即被应用。
以下是在MySQL 8.0.26之上应用修复后的执行计划。partupp和part之间的内哈希连接现在有一个连接谓词:partupp.PS_PARTKEY=part.P_KEY。另外 ,本地谓词(part.P_NAME like“%snow%”)现在出现在内部连接下面,也就是先于内哈希连接而被应用。

-> Aggregate: avg((case partsupp.PS_PARTKEY when NULL then 1 else lineitem.L_QUANTITY end)) (cost=179829230844583.70 rows=899131908749360)
-> Left hash join (part.P_PARTKEY = lineitem.L_PARTKEY), (partsupp.PS_SUPPKEY = lineitem.L_SUPPKEY) (cost=89916039969647.67 rows=899131908749360)
-> Table scan on lineitem (cost=61043.00 rows=596410)
-> Hash
-> Inner hash join (partsupp.PS_PARTKEY = part.P_PARTKEY) (cost=2849092735.78 rows=1507573496)
-> Table scan on partsupp (cost=0.23 rows=77726)
-> Hash
-> Filter: (part.P_NAME like '%snow%') (cost=0.01 rows=19396)
-> Table scan on part (cost=0.01 rows=19396)
下面是应用补丁前后的查询时间比较:打补丁前,查询耗时需要11分37秒
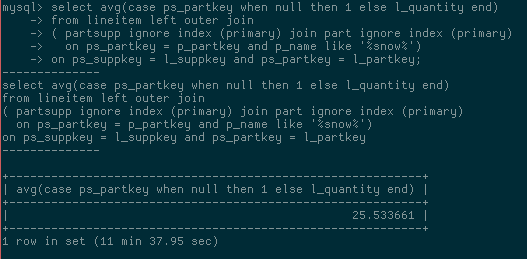
打补丁后,查询耗时仅需0.49秒
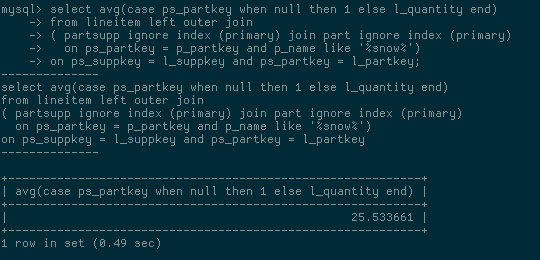
11分37秒 vs 0.49秒,修改前后的性能差距有1400多倍,区别是巨大的。希望这个问题可以在下一个MySQL版本中得到解决。
我们知道,MySQL社区的发展离不开每个数据库领域从业人员的努力,华为云GaussDB也一直重视开源社区的发展,积极对社区版本进行优化和改进,为社区做贡献。本次MySQL Volcano模型迭代器的谓词位置优化,助力MySQL查询性能提升千倍,正是华为云GaussDB 对社区发展的积极反馈。
另外,告诉大家一个好消息,华为云数据库专场活动正在进行,云数据库MySQL包年19.9元起,助力企业无忧上云,更多活动详情戳:https://activity.huaweicloud.com/dbs_Promotion/index.html
参考资料:
[1] G. Graefe, "Volcano— An Extensible and Parallel Query Evaluation System," IEEE Transactions on Knowledge and Data Engineering, pp. 120-135, 1994.
[2] "WL#11785: Volcano iterator design," [Online]. Available: https://dev.mysql.com/worklog/task/?id=11785.
[3] "WL#12074: Volcano iterator executor base," [Online]. Available: https://dev.mysql.com/worklog/task/?id=12074.
[4] "WL#12470: Volcano iterator semijoin," [Online]. Available: https://dev.mysql.com/worklog/task/?id=12470.
[5] "Hash Join Optimization," [Online]. Available: https://dev.mysql.com/doc/refman/8.0/en/hash-joins.html.
[6] "WL#2241: Hash join," [Online]. Available: https://dev.mysql.com/worklog/task/?id=2241.
"TPC-H Homepage," [Online]. Available: http://www.tpc.org/tpch/.
性能提升1400+倍,快来看MySQL Volcano模型迭代器的谓词位置优化详解的更多相关文章
- Web 应用性能提升 10 倍的 10 个建议
转载自http://blog.jobbole.com/94962/ 提升 Web 应用的性能变得越来越重要.线上经济活动的份额持续增长,当前发达世界中 5 % 的经济发生在互联网上(查看下面资源的统计 ...
- 重构、插件化、性能提升 20 倍,Apache DolphinScheduler 2.0 alpha 发布亮点太多!
点击上方 蓝字关注我们 社区的小伙伴们,好消息!经过 100 多位社区贡献者近 10 个月的共同努力,我们很高兴地宣布 Apache DolphinScheduler 2.0 alpha 发布.这是 ...
- SqlServer数据库性能优化详解
数据库性能优化详解 性能调节的目的是通过将网络流通.磁盘 I/O 和 CPU 时间减到最小,使每个查询的响应时间最短并最大限度地提高整个数据库服务器的吞吐量.为达到此目的,需要了解应用程序的需求和数据 ...
- MySQL数据库优化详解(收藏)
MySQL数据库优化详解 mysql表复制 复制表结构+复制表数据mysql> create table t3 like t1;mysql> insert into t3 select * ...
- MySQL 5.7主从复制从零开始设置及全面详解——实现多线程并行同步,解决主从复制延迟问题!
MySQL 5.7主从复制从零开始设置及全面详解——实现多线程并行同步,解决主从复制延迟问题!2017年06月15日 19:59:44 蓝色-鸢尾 阅读数:2062版权声明:本文为博主原创文章,如需转 ...
- centos7.2环境nginx+mysql+php-fpm+svn配置walle自动化部署系统详解
centos7.2环境nginx+mysql+php-fpm+svn配置walle自动化部署系统详解 操作系统:centos 7.2 x86_64 安装walle系统服务端 1.以下安装,均在宿主机( ...
- MySQL之SQL优化详解(二)
目录 MySQL之SQL优化详解(二) 1. SQL的执行顺序 1.1 手写顺序 1.2 机读顺序 2. 七种join 3. 索引 3.1 索引初探 3.2 索引分类 3.3 建与不建 4. 性能分析 ...
- [推荐]T- SQL性能优化详解
[推荐]T- SQL性能优化详解 博客园上一篇好文,T-sql性能优化的 http://www.cnblogs.com/Shaina/archive/2012/04/22/2464576.html
- 性能提升 40 倍!我们用 Rust 重写了自己的项目
前言 Rust 已经悄然成为了最受欢迎的编程语言之一.作为一门新兴底层系统语言,Rust 拥有着内存安全性机制.接近于 C/C++ 语言的性能优势.出色的开发者社区和体验出色的文档.工具链和IDE 等 ...
- 优化临时表使用,SQL语句性能提升100倍
[问题现象] 线上mysql数据库爆出一个慢查询,DBA观察发现,查询时服务器IO飙升,IO占用率达到100%, 执行时间长达7s左右.SQL语句如下:SELECT DISTINCT g.*, cp. ...
随机推荐
- Thread类 常用方法
3.6 start 与 run 调用 run public static void main(String[] args) { Thread t1 = new Thread("t1" ...
- 基于亚博k210+arduino 智能垃圾桶(23工训赛)
#2023 10 15 派大星改 # object classifier boot.py # generated by maixhub.com from fpioa_manager import * ...
- [Python急救站课程]叠加等边三角形的绘制
叠加等边三角形的绘制 from turtle import * penup() fd(-100) pendown() pensize(10) seth(60) fd(200) seth(-60) fd ...
- 用原型实现Class的各项语法
本人之前对Class一直不够重视.平时对原型的使用,也仅限于在构造函数的prototype上挂属性.原型尚且用不着,更何况你Class只是原型的一颗语法糖? 直到公司开始了一个webgis项目,使用o ...
- Java JDBC连接数据库的CURD操作(JDK1.8 + MySQL8.0.33 + mysql-connector-java-8.0.27-bin驱动)
JDBC概述 JDBC(Java Database Connectivity)是一个独立于特定数据库管理系统.通用的SQL数据库存取和操作的公共接口(一组API),定义了用来访问数据库的标准Java类 ...
- CentOS 7替换默认软件源
安装CentOS 7后,默认源在国外,可以替换为国内的源以提升访问速度 参考https://mirrors.ustc.edu.cn/help/centos.html sudo vi /etc/yum. ...
- Django学习(二) 之 模板的使用
写在前面 昨晚应该是睡的最好一天吧,最近一个月睡眠好差,睡不着不说,而且半夜总醒,搞的第二天就会超没精神. 昨天下午去姐姐家,小外甥直接进屋就问我说: 老舅,你都很长时间没来啦,**(前女友)怎么哪去 ...
- 聊一聊 .NET高级调试 中必知的符号表
一:背景 1. 讲故事 在高级调试的旅行中,发现有不少人对符号表不是很清楚,其实简而言之符号表中记录着一些程序的生物特征,比如哪个地址是函数(签名信息),哪个地址是全局变量,静态变量,行号是多少,数据 ...
- Selenium的基本api
1.打开浏览器的驱动,以chrome为例 from selenium import webdriver #chrome驱动 driver = webdriver.Chrome(executable_p ...
- k8s安装网络插件calico出现error validating "calico.yaml": error validating data: invalid object to validate; if you choose to ignore these errors, turn validation off with --validate=false
解决办法:使用下面版本的calico curl https://docs.projectcalico.org/v3.20/manifests/calico.yaml -O