Hive压缩和存储
1.压缩
(1)Hive支持的压缩编码
|
压缩格式 |
工具 |
算法 |
文件扩展名 |
是否可切分 |
对应的编码/解码器 |
|
DEFLATE |
无 |
DEFLATE |
.deflate |
否 |
org.apache.hadoop.io.compress.DefaultCodec |
|
Gzip |
gzip |
DEFLATE |
.gz |
否 |
org.apache.hadoop.io.compress.GzipCodec |
|
bzip2 |
bzip2 |
bzip2 |
.bz2 |
是 |
org.apache.hadoop.io.compress.BZip2Codec |
|
LZO |
lzop |
LZO |
.lzo |
是 |
com.hadoop.compression.lzo.LzopCodec |
|
Snappy |
无 |
Snappy |
.snappy |
否 |
org.apache.hadoop.io.compress.SnappyCodec |
压缩性能的对比
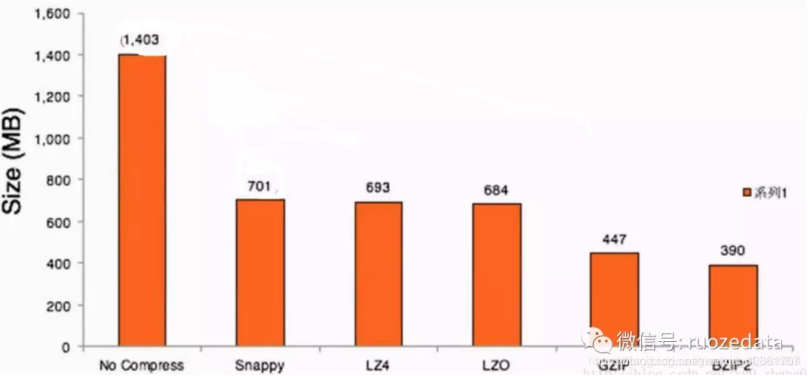
下面是一份源数据1.4G的文件,各类压缩格式的比率和时间对比
数据压缩后大小:
从上面对比可以看出:
在压缩数据比上:
Snappy、LZ4、LZO可以压缩到50%左右
GZIP、BZIP2可以压缩到30%左右
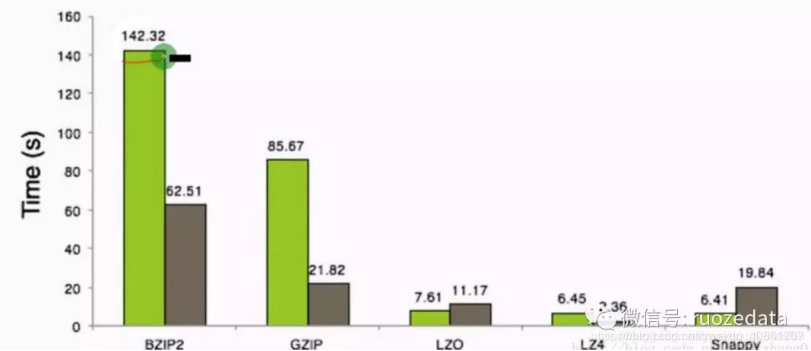
在压缩和解压时间上:
Snappy、LZ4、LZO 的压缩时间非常接近,范围6-8秒内;Snappy的解压时间是最高的,是压缩时间的3倍,其次是LZO,LZ4解压时间最低
GZIP、BZIP2 的压缩和解压时间都非常高。
总结一句话就是:压缩比率高的,压缩和解压时间花费就比较长。
那么该如何选择合适的压缩方式?
Snappy: 压缩速度快;支持hadoop native库
缺点:不支持split;压缩比低;hadoop本身不支持,需要安装;linux系统下没有对应的命令.
LZO: 压缩/解压速度也比较快,合理的压缩率;支持split,是hadoop中最流行的压缩格式;
支持hadoop native库;需要在linux系统下自行安装lzop命令,使用方便
缺点: 压缩率比gzip要低;
lzo虽然支持split,但需要对lzo文件建索引,否则hadoop也是会把lzo文件看成一个普通文件
GZIP: 压缩比较高;hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样;
有hadoop native库;大部分linux系统都自带gzip命令,使用方便
缺点: 不支持split
BZIP2 : 支持split;具有很高的压缩率,比gzip压缩率都高;
hadoop本身支持,但不支持native;在linux系统下自带bzip2命令,使用方便
缺点:压缩/解压速度慢;不支持native
(2)压缩参数配置
要在Hadoop中启用压缩,可以配置如下参数(mapred-site.xml文件中):
|
参数 |
默认值 |
阶段 |
建议 |
|
io.compression.codecs (在core-site.xml中配置) |
org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.Lz4Codec |
输入压缩 |
Hadoop使用文件扩展名判断是否支持某种编解码器 |
|
mapreduce.map.output.compress |
FALSE |
mapper输出 |
这个参数设为true启用压缩 |
|
mapreduce.map.output.compress.codec |
org.apache.hadoop.io.compress.DefaultCodec |
mapper输出 |
使用LZO、LZ4或snappy编解码器在此阶段压缩数据 |
|
mapreduce.output.fileoutputformat.compress |
FALSE |
reducer输出 |
这个参数设为true启用压缩 |
|
mapreduce.output.fileoutputformat.compress.codec |
org.apache.hadoop.io.compress. DefaultCodec |
reducer输出 |
使用标准工具或者编解码器,如gzip和bzip2 |
|
mapreduce.output.fileoutputformat.compress.type |
RECORD |
reducer输出 |
SequenceFile输出使用的压缩类型:NONE和BLOCK |
(3)MR过程中进行压缩
开启Map输出阶段压缩
开启map输出阶段压缩可以减少job中map和Reduce task间数据传输量。具体配置如下:
案例实操:
1.开启hive中间传输数据压缩功能
hive (default)>set hive.exec.compress.intermediate=true;
2.开启mapreduce中map输出压缩功能
hive (default)>set mapreduce.map.output.compress=true;
3.设置mapreduce中map输出数据的压缩方式
hive (default)>set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
4.执行查询语句
hive (default)> select count(ename) name from emp;
开启Reduce输出阶段压缩
当Hive将输出写入到表中时,输出内容同样可以进行压缩。属性hive.exec.compress.output控制着这个功能。
用户可能需要保持默认设置文件中的默认值false,这样默认的输出就是非压缩的纯文本文件了。
用户可以通过在查询语句或执行脚本中设置这个值为true,来开启输出结果压缩功能。
案例实操:
1.开启hive最终输出数据压缩功能
hive (default)>set hive.exec.compress.output=true;
2.开启mapreduce最终输出数据压缩
hive (default)>set mapreduce.output.fileoutputformat.compress=true;
3.设置mapreduce最终数据输出压缩方式
hive (default)> set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
4.设置mapreduce最终数据输出压缩为块压缩
hive (default)> set mapreduce.output.fileoutputformat.compress.type=BLOCK;
5.测试一下输出结果是否是压缩文件
hive (default)> insert overwrite local directory '/opt/module/datas/distribute-result' select * from emp distribute by deptno sort by empno desc;
2.存储
文件存储格式:
Hive支持的存储数据的格式主要有:TEXTFILE 、SEQUENCEFILE、ORC、PARQUET。
列式存储和行式存储
行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的;
ORC和PARQUET是基于列式存储的。
(1)TextFile格式
默认格式,存储方式为行存储,数据不做压缩,磁盘开销大,数据解析开销大。
可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,压缩后的文件不支持split,Hive不会对数据进行切分,从而无法对数据进行并行操作。
并且在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比SequenceFile高几十倍。
优点:查看编辑简单
(2)SequenceFile格式
SequenceFile是Hadoop API提供的一种二进制文件支持,它将数据以<key,value>的形式序列化到文件中。
这种二进制文件内部使用Hadoop 的标准的Writable 接口实现序列化和反序列化。Hive 中的SequenceFile 继承自Hadoop API 的SequenceFile,不过它的key为空,使用value 存放实际的值, 这样是为了避免MR 在运行map 阶段的排序过程。
存储方式为行存储,其具有使用方便、可分割、可压缩的特点。
SequenceFile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,一般建议使用BLOCK压缩。
优势是文件和hadoop api中的MapFile是相互兼容的
缺点:本地查看不方便
(3)RC格式
存储方式:数据按行分块,每块按列存储。结合了行存储和列存储的优点:
首先,RCFile 保证同一行的数据位于同一节点,因此元组重构的开销很低;
其次,像列存储一样,RCFile 能够利用列维度的数据压缩,并且能跳过不必要的列读取;
RCFile的一个行组包括三个部分:
第一部分是行组头部的【同步标识】,主要用于分隔 hdfs 块中的两个连续行组
第二部分是行组的【元数据头部】,用于存储行组单元的信息,包括行组中的记录数、每个列的字节数、列中每个域的字节数
第三部分是【表格数据段】,即实际的列存储数据。在该部分中,同一列的所有域顺序存储。
从图可以看出,首先存储了列 A 的所有域,然后存储列 B 的所有域等。
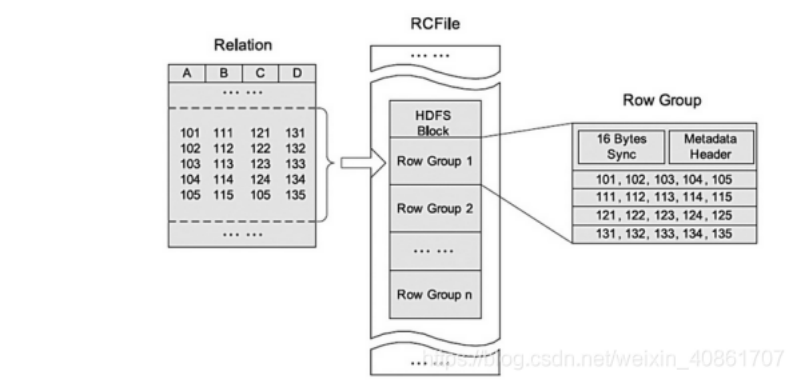
数据追加:RCFile 不支持任意方式的数据写操作,仅提供一种追加接口,这是因为底层的 HDFS当前仅仅支持数据追加写文件尾部。
行组大小:行组变大有助于提高数据压缩的效率,但是可能会损害数据的读取性能,因为这样增加了 Lazy 解压性能的消耗。而且行组变大会占用更多的内存,这会影响并发执行的其他MR作业。 考虑到存储空间和查询效率两个方面,Facebook 选择 4MB 作为默认的行组大小,当然也允许用户自行选择参数进行配置。
(4)ORC格式
Orc (Optimized Row Columnar)是Hive 0.11版里引入的新的存储格式。
如图所示可以看到每个Orc文件由1个或多个stripe组成,每个stripe一般为HDFS的块大小,每一个stripe包含多条记录,这些记录按照列进行独立存储,对应到Parquet中的row group的概念。每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer:
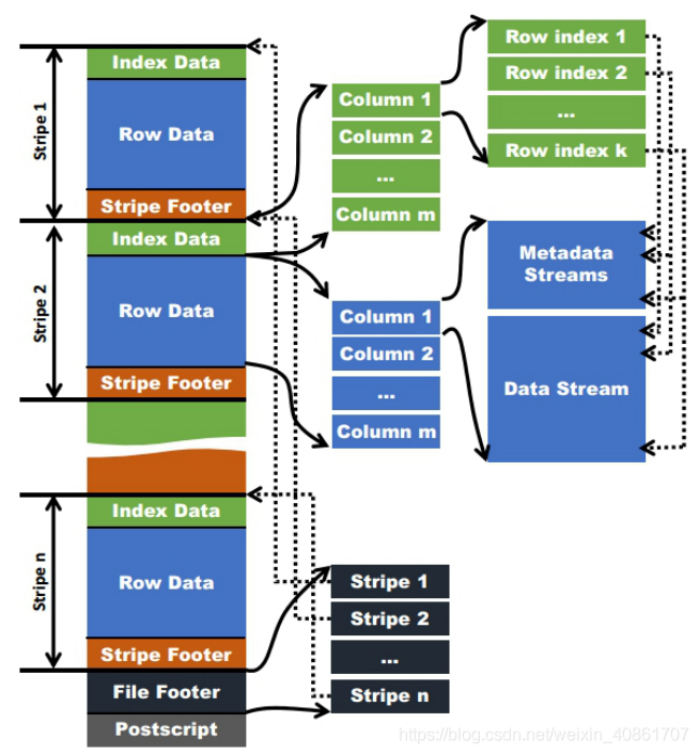
1)Index Data: 一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引应该只是记录某行的各字段在Row Data中的offset。
2)Row Data: 存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。
3)Stripe Footer: 存的是各个Stream的类型,长度等信息。
每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
(5)Parquet格式
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
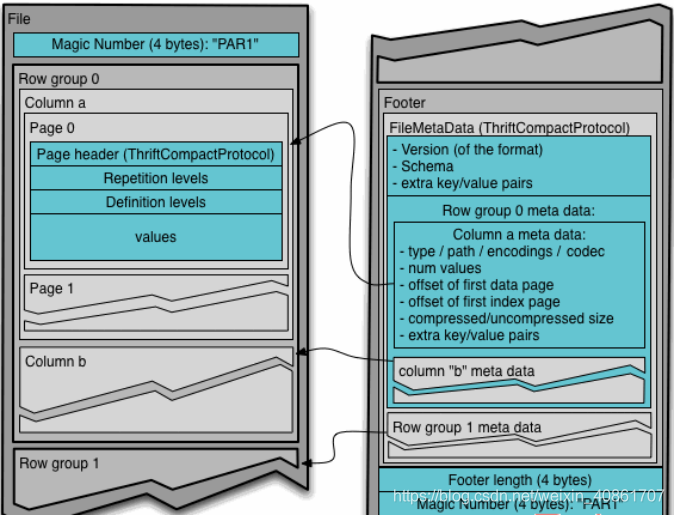
行组(Row Group): 每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,类似于orc的stripe的概念。
列块(Column Chunk): 在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
页(Page): 每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。
上图展示了一个Parquet文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件.
Footer length记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的Schema信息。
除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。
数据页用于存储当前行组中该列的值.
字典页存储该列值的编码字典,每一个列块中最多包含一个字典页.
索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页。
存储文件的压缩比总结:
ORC > Parquet > textFile
ORC存储文件默认采用ZLIB压缩,ZLIB采用的是deflate压缩算法。比snappy压缩的小。
在实际的项目开发当中,hive表的数据存储格式一般选择:orc或parquet。压缩方式一般选择snappy,lzo。
Hive压缩和存储的更多相关文章
- Hive压缩和存储(十二)
压缩和存储 1. Hadoop压缩配置 1) MR支持的压缩编码 压缩格式 工具 算法 文件扩展名 是否可切分 DEFAULT 无 DEFAULT .deflate 否 Gzip gzip DEFAU ...
- hive 压缩全解读(hive表存储格式以及外部表直接加载压缩格式数据);HADOOP存储数据压缩方案对比(LZO,gz,ORC)
数据做压缩和解压缩会增加CPU的开销,但可以最大程度的减少文件所需的磁盘空间和网络I/O的开销,所以最好对那些I/O密集型的作业使用数据压缩,cpu密集型,使用压缩反而会降低性能. 而hive中间结果 ...
- 大数据技术之_08_Hive学习_04_压缩和存储(Hive高级)+ 企业级调优(Hive优化)
第8章 压缩和存储(Hive高级)8.1 Hadoop源码编译支持Snappy压缩8.1.1 资源准备8.1.2 jar包安装8.1.3 编译源码8.2 Hadoop压缩配置8.2.1 MR支持的压缩 ...
- Hive中的HiveServer2、Beeline及数据的压缩和存储
1.使用HiveServer2及Beeline HiveServer2的作用:将hive变成一种server服务对外开放,多个客户端可以连接. 启动namenode.datanode.resource ...
- 一文彻底搞懂Hive的数据存储与压缩
目录 行存储与列存储 行存储的特点 列存储的特点 常见的数据格式 TextFile SequenceFile RCfile ORCfile 格式 数据访问 Parquet 测试 准备测试数据 存储空间 ...
- Hive(十一)【压缩、存储】
目录 一.Hadoop的压缩配置 1.MR支持的压缩编码 2.压缩参数配置 3.开启Mapper输出阶段压缩 4.开启Reduceer输出阶段 二.文件存储 1.列式存储和行式存储 2.TextFil ...
- Hive详解(05) - 压缩和存储
Hive详解(05) - 压缩和存储 Hadoop压缩配置 MR支持的压缩编码 压缩格式 算法 文件扩展名 是否可切分 DEFLATE DEFLATE .deflate 否 Gzip DEFLATE ...
- Hive 表操作(HIVE的数据存储、数据库、表、分区、分桶)
1.Hive的数据存储 Hive的数据存储基于Hadoop HDFS Hive没有专门的数据存储格式 存储结构主要包括:数据库.文件.表.试图 Hive默认可以直接加载文本文件(TextFile),还 ...
- 基于Cloudera Manager5配置HIVE压缩
[Author]: kwu 基于Cloudera Manager5配置HIVE压缩,配置HIVE的压缩.实际就是配置MapReduce的压缩,包含执行结果及中间结果的压缩. 1.基于HIVE命令行的配 ...
- hadoop笔记之Hive的数据存储(视图)
Hive的数据存储(视图) Hive的数据存储(视图) 视图(view) 视图是一种虚表,是一个逻辑概念:可以跨越多张表 既然视图是一种虚表,那么也就是说用操作表的方式也可以操作视图 但是视图是建立在 ...
随机推荐
- Latex常用数学符号输入方法
引用CSDN博文 https://blog.csdn.net/qq_25368751/article/details/87888974
- [kubernetes]服务健康检查
前言 进程在运行,但是不代表应用是正常的,对此pod提供的探针可用来检测容器内的应用是否正常.k8s对pod的健康状态可以通过三类探针来检查:LivenessProbe.ReadinessProbe和 ...
- 如何让pc端网站在手机上可以等比缩放的整个显示
将 头部标签的 <meta name="viewport" content="width=device-width, initial-scale=1.0&qu ...
- MySQL高可用搭建方案之(MHA)
有的时候博客内容会有变动,首发博客是最新的,其他博客地址可能会未同步,认准https://blog.zysicyj.top 首发博客地址 原文地址 MHA架构介绍 MHA是Master High Av ...
- [转帖]聊聊字符串数据长度和nls_length_semantics参数
字符串是我们设计数据库经常用到的类型,从传统的ASCII格式到UTF-8格式,不同应用需求对应不同的字符类型和长度配置.针对Oracle而言,最常用的类型无外乎char和varchar2两个基本类型. ...
- [转帖]谁动了我的 CPU 频率 —— CPU 性能之迷 Part 2
https://blog.mygraphql.com/zh/notes/low-tec/kernel/cpu-frequency/ 目录: 为何有本文 什么是动态 CPU 频率 什么是 p-state ...
- [转帖]十步解析awr报告
http://www.zhaibibei.cn/awr/1.1/ 从这期开始讲解awr报告的部分,首先讲解awr整体的部分 后续会针对不同的点进行讲解 1. 数据库细节 这部分可以看到 数据库的版本 ...
- [转帖]Jmeter正则提取器常用的几种方式
https://www.cnblogs.com/a00ium/p/10483741.html 使用jmeter的同学都知道,jmeter提供了各种各样的提取器,如jsonpath.Beanshell. ...
- [转帖]关于redis,你需要了解的几点!
github:https://github.com/windwant 博客园 首页 新随笔 联系 订阅 管理 随笔 - 227 文章 - 4 评论 - 36 阅读 - 73万 一.关于 re ...
- jcmd的简单总结
jcmd的简单总结 背景 自从2019年公司转向java技术路线. 一直断断续续的在学习java相关的技术内容. 但是总感觉学的不是很深入. 这周比较累.也不想在学新东西了. 所以想着再总结一下jcm ...