STM32F1和STM32F4系列DMA的不同之处——对STM32的DMA的工作机制的一些理解
喜欢用STM32的DMA功能。一方面STM32的DMA和MPU的DMA一样,可以提高数据传输效率。另一方面,作为一种MCU上的DMA,它可以提高针对外设(peripheral)的数据传输的实时性,改变了传统MCU只能用定时中断实现实时控制的方法。
比较STM32F4和STM32F1系列的DMA控制器,可以发现区别主要有三:1)增加了DMA流(Stream)的概念;2)限制了两个DMA控制器的数据流向;3)为每个数据流添加了可配置的FIFO缓冲区。
本文逐一比较了以上三种硬件上的改变带来的功能方面的升级和不同。另外,还大胆猜测了STM32的芯片设计者对DMA的工作机制和场景的构想。以下原创内容欢迎网友转载,但请注明出处: https://www.cnblogs.com/helesheng
1. 增加DMA流(Stream)的概念
1.1 不同之处
我认为STM32F4的DMA控制器的流(Stream)虽然是新增的,但可以理解为只是对原有通道(Channel)概念的细化和扩展,新增的只是“概念”而非实体。请大家对比两个系列数据手册中的DMA1传输请求表。

图1 STMF1系列DMA1控制器的外设传输请求表
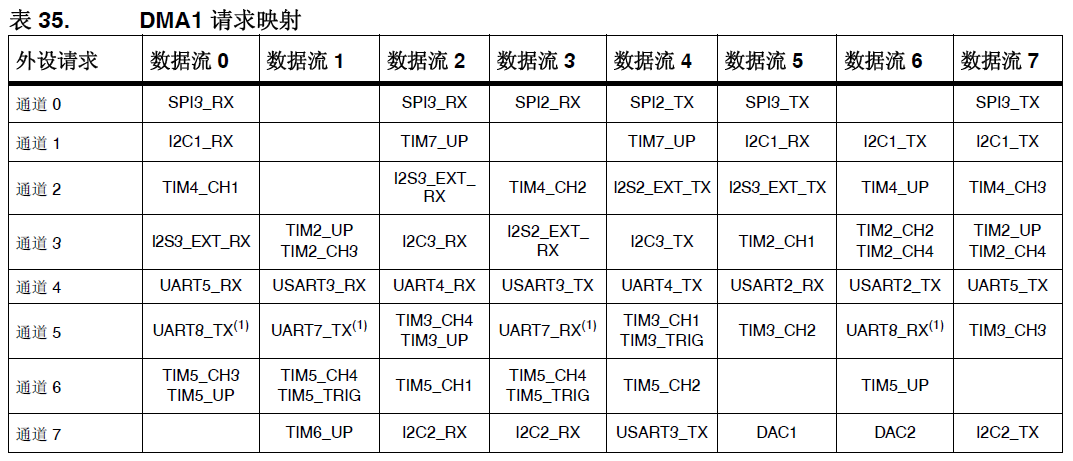
图2 STMF4系列DMA1控制器的外设传输请求表
可以发现,两个系列DMA1可以响应的外设的传输请求,都是可以表示为二维的矩形表格。由于外设种类和路数也相差不大,可以想象STM32F1和STM32F4两类控制器的DMA1和DMA2所能管理的外设传输请求种类和总数数也相差不大。不同点在于:STM32F4将原来STM32F1中以列方式存在的“通道x”传输请求转换成了行的方式,替代了STM32F1表格中每行所对应的某种具体外设;STM32F4的表格中同时还将现在的每一列取了一个新的名字流(stream)。由于两个表格中没有增加“实体”,所以我才认为新增的只是流这个“概念”本身。
但“流”这个概念的增加,却使得STM32F4程序员可以通过软件指定流和通道的具体编号,定位表格中的某一个确切的传输请求。而不像STM32F1只能指定某一通道,而无法进一步在图1表格中定位传输请求来一列中的那个具体外设。也就是说在STM32F1中,每当发生外设引发的DMA传输请求时,程序员只能确定该传输请求来自图1表格中某一列中的任何一个外设,而无法像在STM32F4中一样定位到表格中的任意具体位置的外设。这意味着,STM32F1的程序员无法同时使用表格一列中的两种以上外设传输请求,而STM32F4却可以。
1.2 对STM32外设DMA工作机制理解的深化
1)对比的两种DMA 外设请求组织的形式,给我个人最大的启示在于进一步深刻的意识到:图1、图2表格中的外设只是DMA的传输“请求”(require),而非传输数据源(source)或目标(destination)。DMA外设数据的传输是由表格指定的外设动作“引发”,但传输数据源或目标可以和产生传输请求的外设完全无关。
例如,需要用STM32F4的DMA控制SPI1持续地间隔1ms发送数据,就需要选择能够定时1ms的某个定时器(此处不妨选择TMR3)作为DMA的外设传输请求,查看图2得到对应的通道和流为DMA1_STREAM2_CH5。但在对DMA1_STREAM2_CH5的传输参数进行配置的时候,却需要指定以SPI1的数据寄存器地址作为传输目标,待发送数据存储区地址号作为传输数据源。
这种“传输请求”和“传输源和目标”分离的DMA工作机制其实在STM32F1中就一直存在,但手册中图1表格每行开始的“外设”一列很容易让人产生“传输源”和“传输源/目标”只能是一种外设的误解。
2)传输模式中可以选择“外设到内存/内存到外设”或“存储器到存储器”两种类型的区别,仅仅在于DMA控制器启动一次数据传输,是需要等到下一次外设的传输(require)请求到来(“外设到内存/内存到外设”模式);还是可以在一次传输完成之后不用等待指定外设的传输请求,直接启动DMA传输(“存储器到存储器”模式)。
例如,当用FSMC接口扩展了一个高速并行接口DAC,需要定时地向FSMC并行接口写入数据,以产生指定波形。该应用需要定时用DMA向FSMC扩展DAC的地址传输数据。虽然DMA数据源和目标都是存储器地址(内存和FSMC),但配置DMA时还必须选择“内存到外设”或“外设到内存模式”。应为如果配置为“存储器到存储器”模式,则会导致DMA用自己最快的速度完成数据的传输,而不会等到定时器到采样间隔后再输出数据。
根据我自己对上述DMA工作机制的加深理解,我“解锁”了GPIO高速同步数据传输的“新技能”,将在下一篇博文中展示用DMA 和STM32F4的高速GPIO(AHB总线)实现对独立10MSPS ADC的控制方法和代码,欢迎大家捧场!
2. 分别限制了两个DMA控制器的数据流向
2.1 不同之处
STM32F1系列除了在图1的表格中指定了每个通道的DMA请求外设之外,并没有限制两个DMA控制器的数据源和目标源种类。但STM32F4却通过下图指定了两个DMA控制器的数据源和目标源的种类。
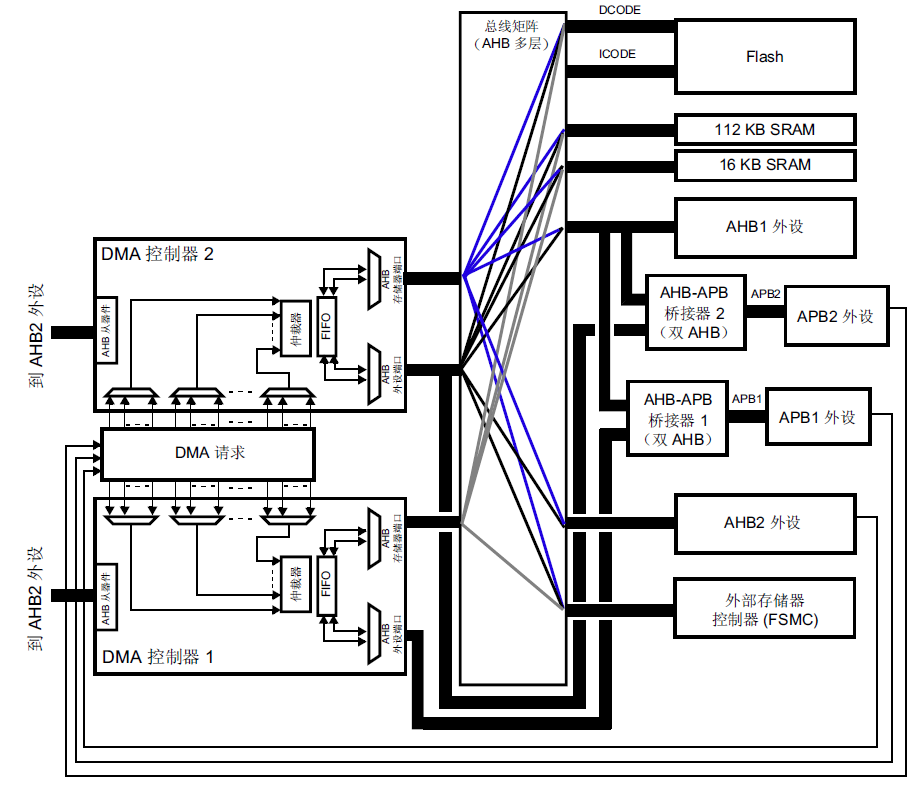
图3 STM32F4系列两个DMA控制器端口(源和目标)连接的外设/存储器种类
我自己初次看到这张图并没有什么太深的感触,但随着对STM32F4的DMA使用经验的增加,会发现这张图对于DMA1和DMA2两个控制器的选择,有着重要的影响。
例如,要想实现片上SRAM存储器到片上SRAM存储器的数据搬运,你会发现STM32F4只能使用DMA2控制器——因为DMA1靠下的端口被固定连接到APB1的数据端口上,无法实现SRAM到SRAM的数据传输。
又如,要实现上文提到的片上SRAM和GPIO之间的高速数据同步传输,由于STM32F4的GPIO被连接到AHB1上,而连接到AHB1的数据端口只被连接到了DMA2的两个端口,所以也只能选用DMA2控制器来实现SRAM和GPIO之间的高速数据同步传输。
2.2 怎样选择STM32F4中的DMA控制器、流和通道
在实际使用STM32F4中的DMA时,需要根据具体应用的要求的传输源和目标的硬件类型和种类,查询图3来确定DMA1或DMA2,举例说明:
要将Flash中的100字节数据通过USART2(串口2)发送出去。由于USART属于慢速设备,发送速率远低于Flash存储器的读取速度。用DMA匹配二者“产生”和“消费”数据的速度,实现速度匹配的方法一般有两种:
连续发送法:USART2并在其每发送完一个字节后,由USART2发送完成事件触发下一次DMA数据传输。此时只能选择“存储器到外设”的工作模式,而DMA传输请求为“USART2发送完成”,在图2表格中找到USART2_TX在DMA1控制器数据流6通道4。反过来在图3中核查一下DMA1是否有能力实现所需的数据传输:USART2属于APB1总线上的外设(参加下图4中的STM32F40x内部总线结构),可以使用图3中DMA1靠下的端口,而DMA1另一靠上的端口的灰色连线可以连接到Flash的DCODE总线。因此使用DMA1_STREAM6_CH4可以实现这种要求的数据传输。

图4 STM32F40x内部结构框图
定时发送法:每间隔一段时间t(长于USART2发送一个字节的时间,如10ms)USART2向外发送一个字节,发送完成后USART2空闲,一直等到下一个t开始在向外发送下一个字节。也就是DMA向USART2的发送数据寄存器传输数据的动作由其他定时器TMR来触发。此时可以选择“存储器到外设”或“外设到存储器”模式,但不能选择“存储器到存储器”模式。DMA传输请求可以是任意TMR的计数器更新事件。当然在启动DMA之前,还需要将TMR3的时基配置为10ms溢出一次。最后,在图1或下图5所示的STM32F4的DMA2外设传输请求表中选择任意空闲的TMR更新事件。不失一般性,我选择图1中DMA1_STREAM2_CH5中的TMR3更新作为DMA传输请求。最后,同样需要在图3中核查一下DMA1是否有能力实现所需的数据传输,器过程和上一种同步方法相同,这里不再赘述。

图5 STMF4系列DMA2控制器的外设传输请求表
3. 每个数据流(STREAM)增添了先进先出的缓冲FIFO
3.1 DMA FIFO的作用
STM32F4为每个DMA数据流添加了独立的四级,每级32位的先进先出缓冲区FIFO。可以看到有网文介绍DMA FIFO能够提升DMA数据传输的带宽,防止外设数据由于总线繁忙造成丢失——理由是外设数据的传输需求,只受DMA传输请求控制,传输请求到来时,由于系统总线繁忙,理论上有可能造成外设数据的丢失。但我个人认为,STM32F4属于微控制器MCU,一般常见应用不会涉及高带宽的纯数据传输;而外设的DMA数据传输带宽都不会太大,因此需要用FIFO提升DMA带宽和可靠性的情况很少。在搜索引擎和大模型中搜索基本很少看到DMA FIFO的应用实例,就是这一结论的旁证。
我个人认为STM32F4的DMA FIFO的作用主要在于实现DMA源和目标数据宽度不等情况下的转换和传输,以及DMA的突发传输(burst transfers)。而这两个功能都是STM32F1系列DMA不具备的。
3.2 实现数据宽度不同的源与目标间的缓冲和转换
DMA的源和目的是不同的外设和存储器,当二者的数据宽度不同时,对于DMA控制器而言就会出现数据“生产”和“消费”速度不等的问题。为使二者相等,数据宽度较小的一侧所需的传输次数就必须多于数据较宽的一侧。DMA控制器就需要暂时缓冲数据宽度较窄一侧前几次传输来的数据,DMA FIFO就可以用于实现对这些数据的缓冲。
下图6所示的就是两侧数据宽度不同时,FIFO中存放数据的顺序。
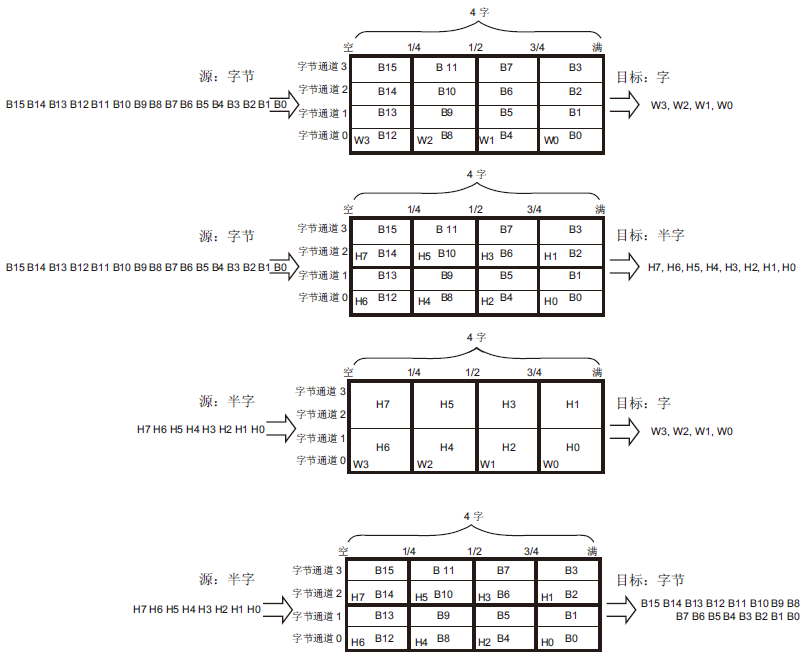
图6 数据宽度不同时,DMA FIFO中存放数据的结构
注意:左侧数据写入的顺序是B0 -> B1 -> B2 -> B3 -> B4 -> B5 -> B6…… H0 -> H1 -> H2 -> H3 …… ;
而右侧读出数据的顺序是W0 -> W1 -> W2 -> W3…… H0 -> H1 -> H2 -> H3 …… 。
可以看到数据在矩形的FIFO中存储后,以列的形式从右侧读出,而两侧的数据传输次数都不相等。
当然FIFO还可以被设置为1-4的不同深度,从而使用图5矩形中的1-4列存储器。
3.3 实现DMA数据突发传输
所谓“突发传输”是指,一个DMA请求引发多次数据传输。当源和目标的数据宽度相等,源和目标的突发传输次数也相同时,DMA传输中数据“生产”和“消费”速度也相同,理论上就不需要FIFO来参与DMA的数据缓冲和传输。但源和目标的数据宽度,或突发传输次数只要有不同,就有可能造成数据“生产”和“消费”速度不相等,此时就必须有FIFO缓冲数据。STM32F4系列要求:只有当DMA FIFO开启时,才允许数据突发传输。当然,两侧数据的宽度和两侧突发传输的次数的关系,必须满足数据“生产”和“消费”速度相等的基本要求。
STM32F1和STM32F4系列DMA的不同之处——对STM32的DMA的工作机制的一些理解的更多相关文章
- STM32F1和STM32F4 区别
STM32F4相对于STM32F1的改进不只一点点,为了便于初学者了解,我们比对相关资料将改进点进行了汇总. STM32F1和STM32F4 区别 (安富莱整理)u F1采用Crotex M3内 ...
- STM32F4系列单片机上使用CUBE配置MBEDTLS实现pem格式公钥导入
|版权声明:本文为博主原创文章,未经博主允许不得转载. 最近尝试在STM32F4下用MBEDTLS实现了公钥导入(我使用的是ECC加密),整个过程使用起来比较简单. 首先,STM32F4系列CUBE里 ...
- STM32之DMA+ADC
借用小甲鱼的经典:各位互联网的广大网友们.大家早上中午晚上好..(打下小广告,因为小甲鱼的视频真的很不错).每次看小甲鱼的视频自学都是比较轻松愉快的..我在想,如果小甲鱼出STM32的视频,我会一集不 ...
- STM32之DMA
一.DMA简介 1.DMA简介 DMA(Direct Memory Access:直接内存存取)是一种可以大大减轻CPU工作量的数据转移方式. CPU有转移数据.计算.控制程序转移等很多功能,但其实转 ...
- hibernate学习系列-----(2)hibernate核心接口和工作机制
在上一篇文章hibernate学习系列-----(1)开发环境搭建中,大致总结了hibernate的开发环境的搭建步骤,今天,我们继续了解有关hibernate的知识,先说说这篇文章的主要内容吧: C ...
- 【STM32系列汇总】小白博主的STM32实战快速进阶之路(持续更新)
我把之前在学习和工作中使用STM32进行嵌入式开发的经验和教程等相关整理到这里,方便查阅学习,如果能帮助到您,请帮忙点个赞: 本文的宗旨 STM32 只是一个硬件平台,同样地他可以换成MSP430,N ...
- STM32使用DMA发送串口数据
1.概述 上一篇文章<STM32使用DMA接收串口数据>讲解了如何使用DMA接收数据,使用DMA外设和串口外设,使用的中断是串口空闲中断.本篇文章主要讲解使用DMA发送数据,不会讲解基础的 ...
- STM32使用DMA接收不定长数据
开启串口,是能串口全局中断 配置DMA并勾选Memory选项 继续配置工程并且生成代码 添加一些串口通讯使用的全局变量 #define BUFFER_SIZE 128 uint8_t Tx_Buf[5 ...
- STM32F1库函数初始化系列:串口DMA空闲接收_DMA发送
1 void USART3_Configuration(void) //串口3配置---S 2 { 3 DMA_InitTypeDef DMA_InitStructure; 4 USART_InitT ...
- STM32F1库函数初始化系列:DMA—ADC采集
1 void ADC_Configure(void) 2 { 3 ADC_InitTypeDef ADC_InitStructure; 4 GPIO_InitTypeDef GPIO_InitStru ...
随机推荐
- AXI4自定义FPGA外设理论基础
AXI4自定义FPGA外设理论基础 1.理论目的 在前面的基于AXI4的自定义GPIO的实验中,大概地了解了AXI4的工作模式,即以寄存器为缓冲,实现操作和传输.那个实验只是将自定义的FPGA连接到现 ...
- kingbaseES 优化之数据库瓶颈排查
针对数据库的性能瓶颈排查方法分为两个层次1.实例级别性能问题排查 2.语句级别性能问题排查 实例级别 实例级别性能问题排查用来分析数据库实例整体是否存在性能瓶颈,然后根据排除出的疑似问题进行实例级别参 ...
- KingbaseES 控制文件损坏的恢复
sys_ control文件损坏: 需要手工指定一些参数完成sys_resetwal相关操作 当前数据库信息 test=# \d 关联列表 架构模式 | 名称 | 类型 | 拥有者 --------- ...
- 取消掉远程桌面mstsc顶部(侧面)连接栏
在进行mstsc远程桌面连接电脑或者虚拟机的时候,总是会出现一个连接栏.虽然点左边的图钉可以自动隐藏,但是每次鼠标滑到上面的时候,还是会冒出来,这个就有点闹心了. 查了下相关资料,解决了,特写下相关教 ...
- #线性dp,排列组合#洛谷 2476 [SCOI2008]着色方案
题目 分析(弱化版) 最暴力的想法就是直接维护每种颜色的个数dp, 弱化版有一个很突出的地方就是 \(c_i\leq 5\), 也就是说可以将相同个数的颜色合并按照个数dp, 设 \(dp[c1][c ...
- #点分树 or LCT#洛谷 4115 Qtree4
两次LCT的Access操作就可以求LCA啦 题目 给出一棵树,支持单点反色和查询全局最远白点 分析(点分树) 点分树的做法就是考虑点分树上的父亲把子树分成若干个部分, 那么所谓的白点直径可以把子树的 ...
- #莫比乌斯反演,整除分块,欧拉定理#U137539 虚伪的最小公倍数
题目 \[\large\prod_{i_1=1}^n\prod_{i_2=1}^n\dots\prod_{i_k=1}^n\frac{i_1*i_2*\dots*i_k}{gcd(i_1,i_2,\d ...
- HTTP协议安全头部的笔记
本文于2016年3月完成,发布在个人博客网站上. 考虑个人博客因某种原因无法修复,于是在博客园安家,之前发布的文章逐步搬迁过来. 近日项目组对当前开发.维护的Web系统做了AppScan扫描,扫描的结 ...
- C# 属性概述
属性概述 属性允许类公开获取和设置值的公共方法,而隐藏实现或验证代码. get 属性访问器用于返回属性值,而 set 属性访问器用于分配新值. 这些访问器可以具有不同的访问级别. 有关详细信息,请参阅 ...
- 掌上新闻随心播控,HarmonyOS SDK助力新浪新闻打造精致易用的资讯服务新体验
原生智能是HarmonyOS NEXT的核心亮点之一,依托HarmonyOS SDK丰富全面的开放能力,开发者只需通过几行代码,即可快速实现AI功能.新浪新闻作为鸿蒙原生应用开发的先行者之一,从有声资 ...