DataWorks功能实践速览 05——循环与遍历
简介: DataWorks功能实践系列,帮助您解析业务实现过程中的痛点,提高业务功能使用效率!通过往期的介绍,您已经了解到在DataWorks上进行任务运行的最关键的几个知识点,其中上期参数透传中为您介绍了可以将上游节点参数透传到下游节点的特殊节点——赋值节点,结合赋值节点和其他节点,可实现循环或遍历读取处理数据的任务。本期为您介绍如何在DataWorks上实现循环与遍历任务。


往期回顾:
- DataWorks 功能实践速览01期——数据同步解决方案:为您介绍不同场景下可选的数据同步方案。
- DataWorks 功能实践速览02期——独享数据集成资源组:为您介绍进行数据同步时,可使用的资源组与网络连通方案、注意事项。
- DataWorks 功能实践速览03期——生产开发环境隔离:为您介绍DataWorks通过标准模式提供开发环境与生产环境隔离及不同环境的权限要求。
- DataWorks功能实践速览 04期——参数透传:为您介绍如何在DataWorks上实现参数透传,即把上游任务的参数透传到下游任务。
通过往期的介绍,您已经了解到在DataWorks上进行任务运行的最关键的几个知识点,其中上期参数透传中为您介绍了可以将上游节点参数透传到下游节点的特殊节点——赋值节点,结合赋值节点和其他节点,可实现循环或遍历读取处理数据的任务。本期为您介绍如何在DataWorks上实现循环与遍历任务。
功能推荐:循环节点与遍历节点
在进行数据开发任务编译的过程中,有时我们可能碰到需要进行循环或遍历的任务场景,DataWorks为您提供两类特殊节点以满足此类场景的使用需求。
|
对比项 |
循环节点(do-while节点) |
遍历节点(for-each节点) |
|
应用场景 |
根据对象集合的数量逐条读取并判断是否满足循环条件,如果满足则继续循环,如果不满足则退出循环,循环次数根据每次循环的判断结果而定,不固定。 |
根据对象集合的数量逐条读取(遍历),循环次数已知。 |
|
节点应用 |
您可以重新编排do-while节点内部的业务流程,将需要循环执行的逻辑写在节点内,再编辑end循环判断节点来控制是否退出循环。同时您也可以结合赋值节点来循环遍历赋值节点传递的结果集。 |
您可以通过for-each节点来循环遍历赋值节点传递的结果集。同时您也可以重新编排for-each节点内部的业务流程。 |
通常循环节点(do-while节点)与遍历节点(for-each节点)会与赋值节点联合使用,将上游节点的输出通过赋值节点传递给下游节点,在下游节点中对上游节点的输出结果进行循环或遍历。
同时,循环节点(do-while节点)与遍历节点(for-each节点)与其他简单节点不一致的地方在于,这类逻辑节点自身包含内部节点。以do-while节点为例,一个do-while节点创建完成后,通常会为您自动创建好3个内部节点,同时您也可以将内部节点重新进行内部业务流程和节点内容的编译。
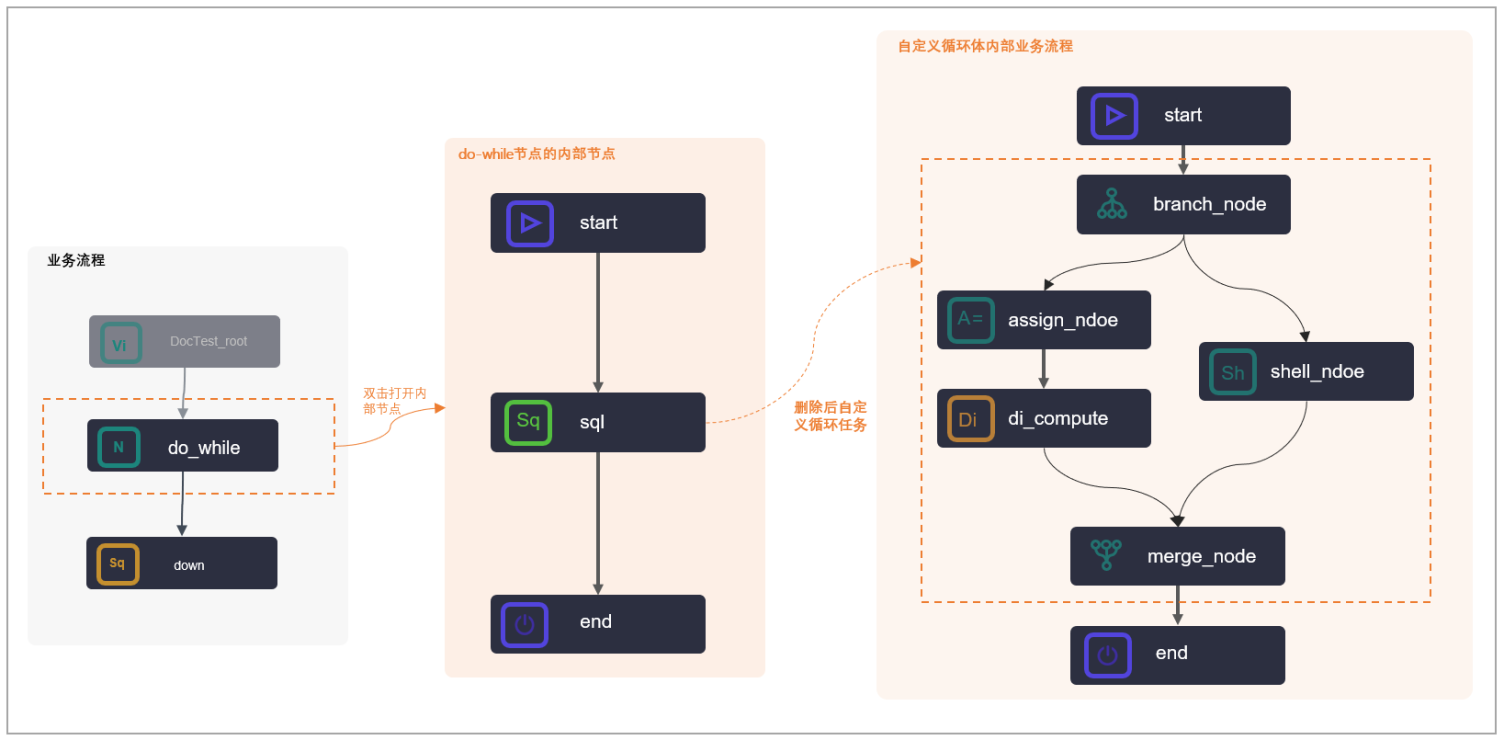
Part1:循环节点(do-while节点)
1.1 节点组成
DataWorks的do-while节点是包含内部节点的一种特殊节点,您在创建完成do-while节点时,同时也自动创建完成了三个内部节点:start节点(循环开始节点)、sql节点(循环任务节点)、end节点(循环结束判断节点),通过内部节点组织成内部节点流程,实现任务的循环运行。
如上图所示:
- start节点是内部节点的开始节点,不承载具体的任务代码。
- sql节点DataWorks默认为您创建好了一个SQL类型的内部任务运行节点,您也可以删除默认的sql节点后,自定义内部循环任务的运行节点。
- 您的循环任务是SQL类型的任务,则可以直接双击默认的sql节点,进入节点的代码开发页面开发循环任务代码。
- 您的循环任务比较复杂,您可以在内部节点流程中新建其他任务节点,并根据实际情况重新构建节点的运行流程。通常循环任务的业务流程会与赋值节点、分支节点、归并节点联合使用,典型应用场景说明请参见典型应用:与赋值节点联合使用。
说明 自定义循环任务节点时,您可以删除内部节点间的依赖关系,重新编排循环节点内部业务流程,但需要分别将start节点、end节点分别作为do-while节点内部业务流程的首末节点。
- end节点
- end节点是do-while节点的循环判断节点,来控制do-while节点循环次数,其本质上是一个赋值节点,输出true和false两种字符串,分别代表继续下一个循环和不再继续循环。
- end节点支持使用ODPS SQL、SHELL和Python(Python2)三种语言进行循环判断代码开发,同时do-while节点为您提供了便利的内置变量,便于您进行end代码开发。内置变量的介绍请参见内置变量和变量取值案例,不同语言开发的样例代码请参见案例1:end节点代码样例。
1.2 使用限制与注意事项
- 循环支持
- 仅DataWorks标准版及以上版本支持使用do-while节点。
- do-while节点最多支持循环128次,end节点控制循环次数时,如果超过了128次,则运行会报错。
- 内部节点
- 自定义循环任务节点时,您可以删除内部节点间的依赖关系,重新编排循环节点内部业务流程,但需要分别将start节点、end节点分别作为do-while节点内部业务流程的首末节点。
- 在do-while节点的内部节点使用分支节点进行逻辑判断或者结果遍历时,需要同时使用归并节点。
- do-while节点的内部节点end节点在代码开发时,不支持添加注释。
- 调测运行
- DataWorks为标准模式时,不支持在DataStudio界面直接测试运行do-while节点。如果您想测试验证do-while节点的运行结果,您需要将包含do-while节点的任务发布提交到运维中心,在运维中心页面运行do-while节点任务。如果您在do-while节点内使用了赋值节点传递的值,请在运维中心测试时,同时运行赋值节点和循环节点。
- 在运维中心查看do-while节点的执行日志时,您需要右键实例,单击查看内部节点来查看内部节点的执行日志。
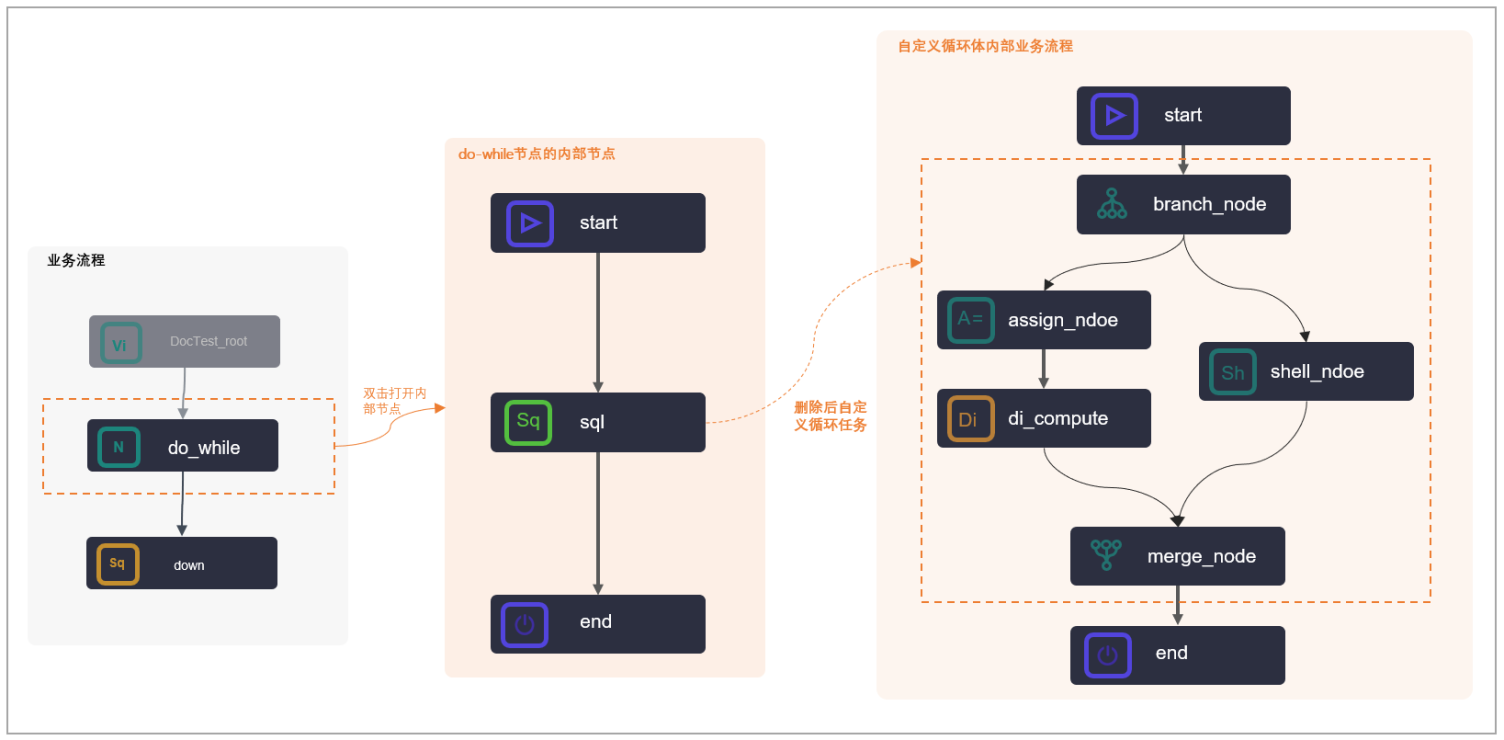
1.3 典型应用:与赋值节点联合使用
do-while节点常常与赋值节点联合使用,如下图所示。
与赋值节点联合使用时:
- 您需要将赋值节点的输出作为赋值节点的本节点输入,且与赋值节点做好上下游依赖关系的配置,其他配置注意事项请参见案例2:与赋值节点联合使用。
- 与赋值节点联合使用时,可以使用一些内置变量来获取当前已循环次数、赋值参数值等循环变量值,详情请参见内置变量。
1.4 内置变量
DataWorks的do-while节点,通过内部节点来实现循环运行任务,每次任务循环运行时,您可以通过一些内置的变量来获取当前已循环次数和偏移量。
|
内置变量 |
含义 |
取值 |
|
${dag.loopTimes} |
当前已循环次数 |
第一次循环为1、第二次为2、第三次为3…第n次为n。 |
|
${dag.offset} |
偏移量 |
第一次循环为0、第二次为1、第三次为2…第n次为n-1。 |
如果您联合使用了赋值节点,则还可以通过以下方式来获取赋值参数值和循环变量参数。
说明 以下以变量示例中,input是do-while节点中自定义的本节点输入参数名称,实际使用时,需替换为您真实的名称。
|
内置变量 |
含义 |
|
${dag.input} |
上游赋值节点传递的数据集。 |
|
${dag.input[${dag.offset}]} |
循环节点内部获取当前循环的数据行。 |
|
${dag.input.length} |
循环节点内部获取数据集长度。 |
1.5 变量取值案例
- 案例1
上游赋值节点为shell节点,最后一条输出结果为2021-03-28,2021-03-29,2021-03-30,2021-03-31,2021-04-01,此时,各变量的取值如下:
|
内置变量 |
第1次循环时取值 |
第2次循环时取值 |
|
${dag.input} |
2021-03-28,2021-03-29,2021-03-30,2021-03-31,2021-04-01 |
|
|
${dag.input[${dag.offset}]} |
2021-03-28 |
2021-03-29 |
|
${dag.input.length} |
5 |
|
|
${dag.loopTimes} |
1 |
2 |
|
${dag.offset} |
0 |
1 |
- 案例2
上游赋值节点为ODPS SQL节点,最后一条select语句查询出两条数据:
+----------------------------------------------+
| uid | region | age_range | zodiac |
+----------------------------------------------+
| 0016359810821 | 湖北省 | 30~40岁 | 巨蟹座 |
| 0016359814159 | 未知 | 30~40岁 | 巨蟹座 |
+----------------------------------------------+
此时,各变量的取值如下:
|
内置变量 |
第1次循环时取值 |
第2次循环时取值 |
|
${dag.input} |
|
|
|
${dag.input[${dag.offset}]} |
0016359810821,湖北省,30~40岁,巨蟹座 |
0016359814159,未知,30~40岁,巨蟹座 |
|
${dag.input.length} |
2 说明 二维数组的行数为数据集长度,当前赋值节点输出的二维数组行数为2。 |
|
|
${dag.input[0][1] 说明 二维数组的第一行第一列的取值。 |
0016359810821 |
|
|
${dag.loopTimes} |
1 |
2 |
|
${dag.offset} |
0 |
1 |
Part2:遍历节点(for-each节点)
2.1 节点组成
DataWorks的for-each节点是包含内部节点的一种特殊节点,您在创建完成for-each节点时,同时也自动创建完成了三个内部节点:start节点(循环开始节点)、sql节点(循环任务节点)、end节点(循环结束判断节点),通过内部节点组织成内部节点流程,实现对上游赋值接节点输出结果的循环遍历。
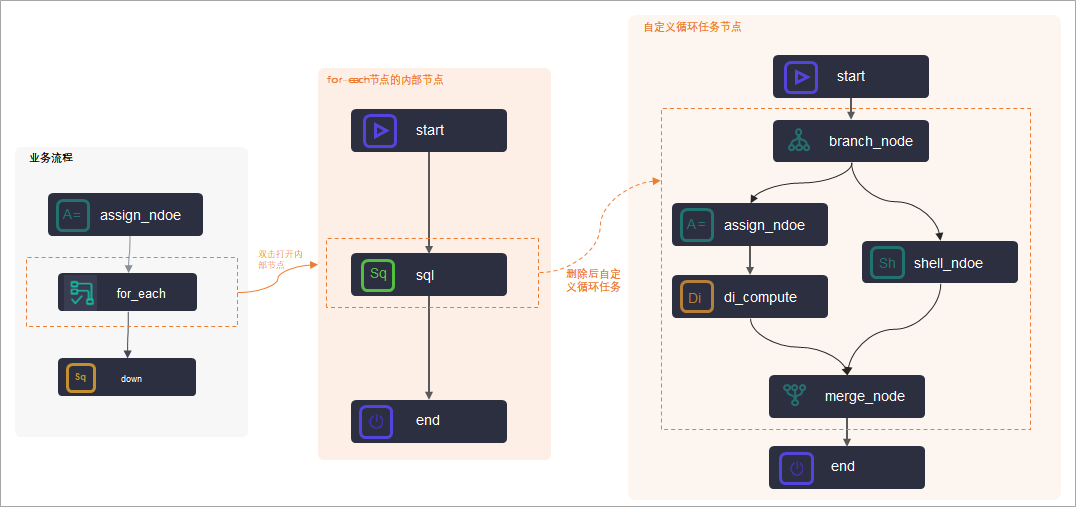
如上图所示:
- sql节点DataWorks默认为您创建好了一个SQL类型的内部任务运行节点,您也可以删除默认的sql节点后,自定义内部循环遍历任务的运行节点。
- 您的循环遍历任务是SQL类型的任务,则可以直接双击默认的sql节点,进入节点的代码开发页面开发任务代码。
- 您的循环遍历任务比较复杂,您可以在内部节点流程中新建其他任务节点,并根据实际情况重新构建节点的运行流程。
说明 自定义循环任务节点时,您可以删除内部节点间的依赖关系,重新编排循环节点内部业务流程,但需要分别将start节点、end节点分别作为for-each节点内部业务流程的首末节点。
- start节点与end节点是内部节点业务流程每次循环遍历的开始节点与结束节点,不承载具体的任务代码。
说明 for-each节点的end节点不控制循环遍历的次数,for-each节点的循环遍历次数由上游赋值节点实际输出控制。
2.2 使用限制与注意事项
- 上下游依赖
for-each遍历节点需要遍历赋值节点传递的值,所以赋值节点需作为for-each节点的上游节点,for-each节点需要依赖赋值节点。
- 循环支持
- 仅DataWorks标准版及以上版本支持使用for-each节点。
- for-each节点最多支持循环128次,如果超过了128次,则运行会报错。实际循环遍历次数由上游赋值节点实际输出控制。
- 一维数组类型的输出,循环遍历次数即为一维数组元素的个数。例如,赋值节点的赋值语言为SEHLL或Python(Python2)时,输出结果为一维数组:2021-03-28,2021-03-29,2021-03-30,2021-03-31,2021-04-01,则for-each节点会循环5次完成遍历。
- 二维数组类型的输出,循环遍历次数即为二维数组元素的行数。例如,赋值节点的赋值语言为OdpsSQL时,输出结果为二维数组:
+----------------------------------------------+
| uid | region | age_range | zodiac |
+----------------------------------------------+
| 0016359810821 | 湖北省 | 30~40岁 | 巨蟹座 |
| 0016359814159 | 未知 | 30~40岁 | 巨蟹座 |
+----------------------------------------------+
则for-each节点会循环2次完成遍历。
- 内部节点
- 您可以删除for-each节点的内部节点间的依赖关系,重新编排内部业务流程,但需要分别将start节点、end节点分别作为for-each节点内部业务流程的首末节点。
- 在for-each节点的内部节点使用分支节点进行逻辑判断或者结果遍历时,需要同时使用归并节点。
- 调测运行
- DataWorks为标准模式时,不支持在DataStudio界面直接测试运行for-each节点。如果您想测试验证for-each节点的运行结果,您需要将包含for-each节点的任务发布提交到运维中心,在运维中心页面运行for-each节点任务。
- 在运维中心查看for-each节点的执行日志时,您需要右键实例,单击查看内部节点来查看内部节点的执行日志。
2.3 典型应用
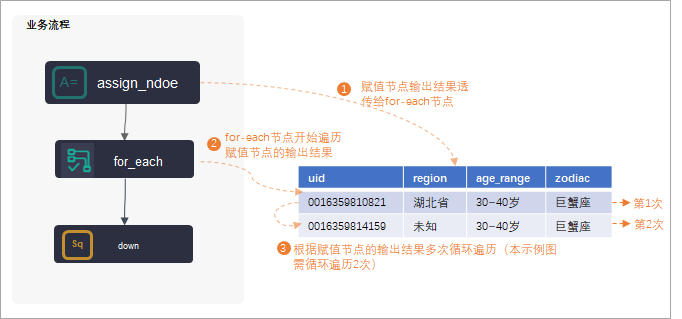
DataWorks的for-each节点主要用于有循环遍历的场景,且需要与赋值节点联合使用,将赋值节点作为for-each节点的上游节点,将赋值节点的输出结果赋值给for-each节点后,一次次循环来遍历赋值节点的输出结果。
2.4 内置变量
DataWorks的for-each节点每次循环遍历赋值节点的输出结果时,您可以通过一些内置的变量来获取当前已循环次数和偏移量。
|
内置变量 |
含义 |
与for循环对比 |
|
${dag.loopDataArray} |
获取赋值节点的数据集 |
相当于for循环中的代码结果: data=[] |
|
${dag.foreach.current} |
获取当前遍历值 |
以下面的for循环代码为例:
|
|
${dag.offset} |
当前偏移量 (每一次遍历相对于第一次的偏移量) |
|
|
${dag.loopTimes} |
获取当前遍历次数 |
- |
在您了解自己输出的表结构的情况下,您可以使用如下变量方式,获取其他变量取值。
|
其他变量 |
含义 |
|
${dag.foreach.current[n]} |
上游赋值节点的输出结果为二维数组时,每次遍历时获取当前数据行的某列的数据。 |
|
${dag.loopDataArray[i][j]} |
上游赋值节点的输出结果为二维数组时,获取数据集中具体i行j列的数据。 |
|
${dag.foreach.current[n]} |
上游赋值节点的输出结果为一维数组时,获取具体某列数据。 |
2.5 内置变量取值案例
- 案例1
上游赋值节点为shell节点,最后一条输出结果为2021-03-28,2021-03-29,2021-03-30,2021-03-31,2021-04-01,此时,各变量的取值如下:
说明 由于输出结果为一维数组,数组元素个数为5(逗号分隔每个元素),因此for-each总遍历次数为5。
|
内置变量 |
第1次循环遍历的取值 |
第2次循环遍历的取值 |
|
${dag.loopDataArray} |
2021-03-28,2021-03-29,2021-03-30,2021-03-31,2021-04-01 |
|
|
${dag.foreach.current} |
2021-03-28 |
2021-03-29 |
|
${dag.offset} |
0 |
1 |
|
${dag.loopTimes} |
1 |
2 |
|
${dag.foreach.current[3]} |
2021-03-30 |
|
- 案例2
上游赋值节点为ODPS SQL节点,最后一条select语句查询出两条数据:
+----------------------------------------------+
| uid | region | age_range | zodiac |
+----------------------------------------------+
| 0016359810821 | 湖北省 | 30~40岁 | 巨蟹座 |
| 0016359814159 | 未知 | 30~40岁 | 巨蟹座 |
+----------------------------------------------+
此时,各变量的取值如下:
说明 由于输出结果为二维数组,数组行数为2,因此for-each总遍历次数为2。
|
内置变量 |
第1次循环遍历的取值 |
第2次循环遍历的取值 |
|
${dag.loopDataArray} |
|
|
|
${dag.foreach.current} |
0016359810821,湖北省,30~40岁,巨蟹座 |
0016359814159,未知,30~40岁,巨蟹座 |
|
${dag.offset} |
0 |
1 |
|
${dag.loopTimes} |
1 |
2 |
|
${dag.foreach.current[0]} |
0016359810821 |
0016359814159 |
|
${dag.loopDataArray[1][0]} |
0016359814159 |
|
本文为阿里云原创内容,未经允许不得转载。

往期回顾:
- DataWorks 功能实践速览01期——数据同步解决方案:为您介绍不同场景下可选的数据同步方案。
- DataWorks 功能实践速览02期——独享数据集成资源组:为您介绍进行数据同步时,可使用的资源组与网络连通方案、注意事项。
- DataWorks 功能实践速览03期——生产开发环境隔离:为您介绍DataWorks通过标准模式提供开发环境与生产环境隔离及不同环境的权限要求。
- DataWorks功能实践速览 04期——参数透传:为您介绍如何在DataWorks上实现参数透传,即把上游任务的参数透传到下游任务。
通过往期的介绍,您已经了解到在DataWorks上进行任务运行的最关键的几个知识点,其中上期参数透传中为您介绍了可以将上游节点参数透传到下游节点的特殊节点——赋值节点,结合赋值节点和其他节点,可实现循环或遍历读取处理数据的任务。本期为您介绍如何在DataWorks上实现循环与遍历任务。
功能推荐:循环节点与遍历节点
在进行数据开发任务编译的过程中,有时我们可能碰到需要进行循环或遍历的任务场景,DataWorks为您提供两类特殊节点以满足此类场景的使用需求。
|
对比项 |
循环节点(do-while节点) |
遍历节点(for-each节点) |
|
应用场景 |
根据对象集合的数量逐条读取并判断是否满足循环条件,如果满足则继续循环,如果不满足则退出循环,循环次数根据每次循环的判断结果而定,不固定。 |
根据对象集合的数量逐条读取(遍历),循环次数已知。 |
|
节点应用 |
您可以重新编排do-while节点内部的业务流程,将需要循环执行的逻辑写在节点内,再编辑end循环判断节点来控制是否退出循环。同时您也可以结合赋值节点来循环遍历赋值节点传递的结果集。 |
您可以通过for-each节点来循环遍历赋值节点传递的结果集。同时您也可以重新编排for-each节点内部的业务流程。 |
通常循环节点(do-while节点)与遍历节点(for-each节点)会与赋值节点联合使用,将上游节点的输出通过赋值节点传递给下游节点,在下游节点中对上游节点的输出结果进行循环或遍历。
同时,循环节点(do-while节点)与遍历节点(for-each节点)与其他简单节点不一致的地方在于,这类逻辑节点自身包含内部节点。以do-while节点为例,一个do-while节点创建完成后,通常会为您自动创建好3个内部节点,同时您也可以将内部节点重新进行内部业务流程和节点内容的编译。
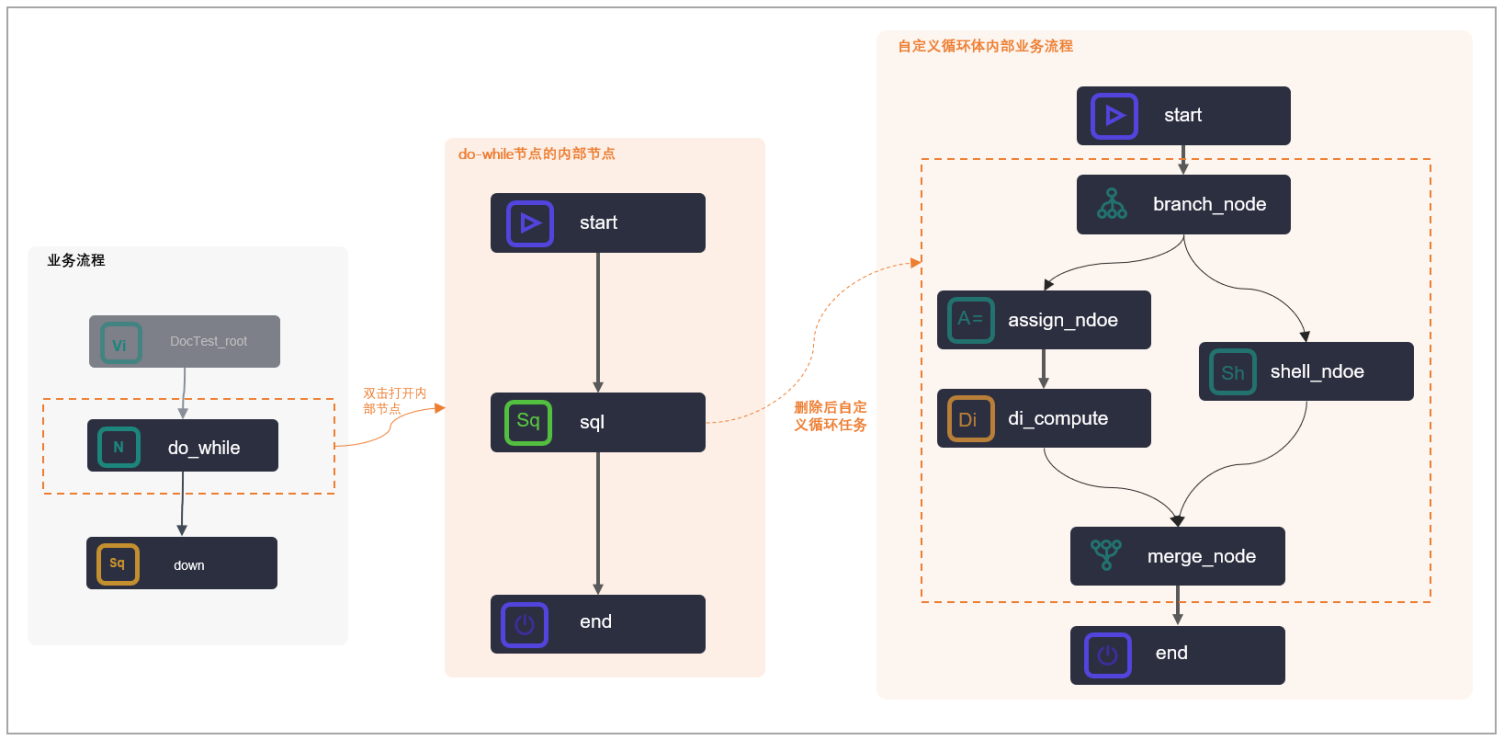
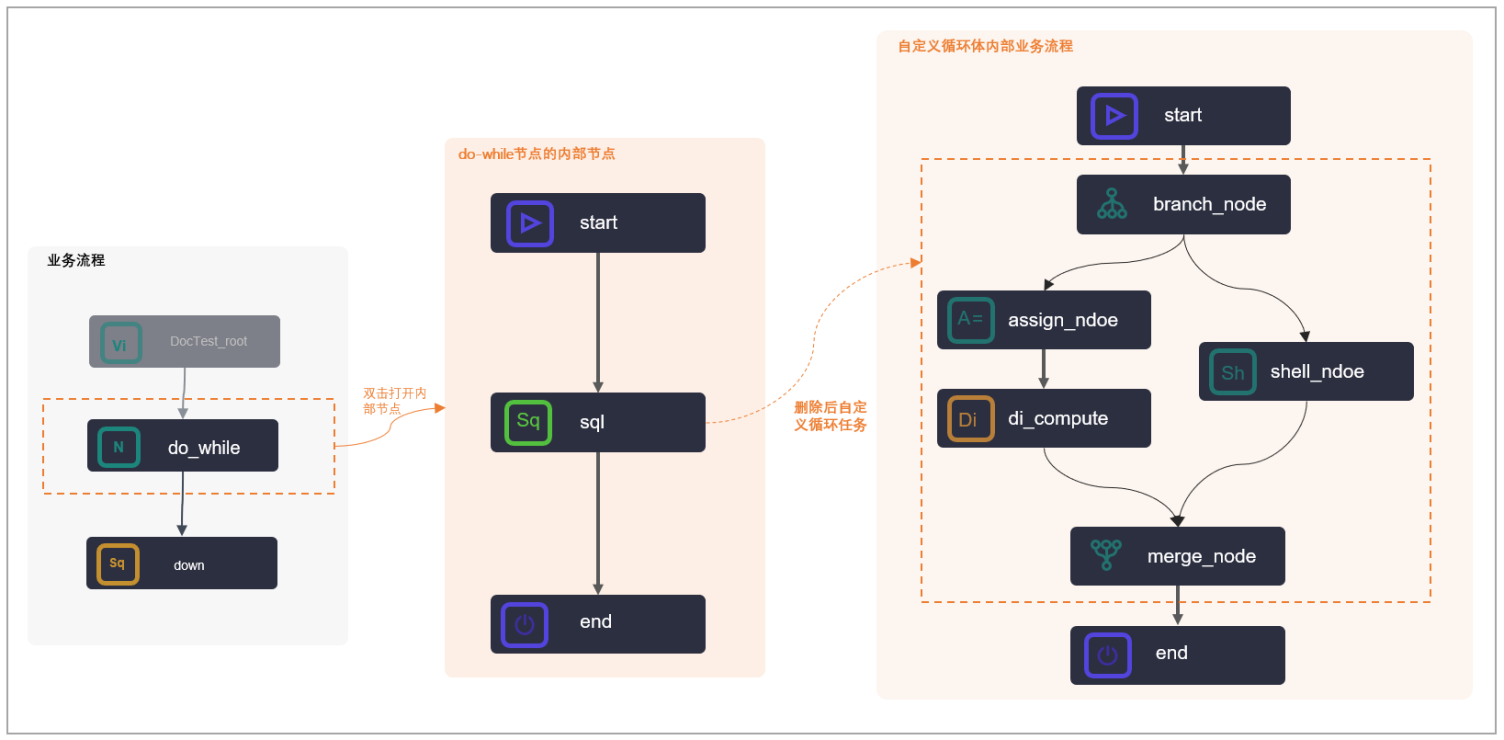
Part1:循环节点(do-while节点)
1.1 节点组成
DataWorks的do-while节点是包含内部节点的一种特殊节点,您在创建完成do-while节点时,同时也自动创建完成了三个内部节点:start节点(循环开始节点)、sql节点(循环任务节点)、end节点(循环结束判断节点),通过内部节点组织成内部节点流程,实现任务的循环运行。
如上图所示:
- start节点是内部节点的开始节点,不承载具体的任务代码。
- sql节点DataWorks默认为您创建好了一个SQL类型的内部任务运行节点,您也可以删除默认的sql节点后,自定义内部循环任务的运行节点。
- 您的循环任务是SQL类型的任务,则可以直接双击默认的sql节点,进入节点的代码开发页面开发循环任务代码。
- 您的循环任务比较复杂,您可以在内部节点流程中新建其他任务节点,并根据实际情况重新构建节点的运行流程。通常循环任务的业务流程会与赋值节点、分支节点、归并节点联合使用,典型应用场景说明请参见典型应用:与赋值节点联合使用。
说明 自定义循环任务节点时,您可以删除内部节点间的依赖关系,重新编排循环节点内部业务流程,但需要分别将start节点、end节点分别作为do-while节点内部业务流程的首末节点。
- end节点
- end节点是do-while节点的循环判断节点,来控制do-while节点循环次数,其本质上是一个赋值节点,输出true和false两种字符串,分别代表继续下一个循环和不再继续循环。
- end节点支持使用ODPS SQL、SHELL和Python(Python2)三种语言进行循环判断代码开发,同时do-while节点为您提供了便利的内置变量,便于您进行end代码开发。内置变量的介绍请参见内置变量和变量取值案例,不同语言开发的样例代码请参见案例1:end节点代码样例。
1.2 使用限制与注意事项
- 循环支持
- 仅DataWorks标准版及以上版本支持使用do-while节点。
- do-while节点最多支持循环128次,end节点控制循环次数时,如果超过了128次,则运行会报错。
- 内部节点
- 自定义循环任务节点时,您可以删除内部节点间的依赖关系,重新编排循环节点内部业务流程,但需要分别将start节点、end节点分别作为do-while节点内部业务流程的首末节点。
- 在do-while节点的内部节点使用分支节点进行逻辑判断或者结果遍历时,需要同时使用归并节点。
- do-while节点的内部节点end节点在代码开发时,不支持添加注释。
- 调测运行
- DataWorks为标准模式时,不支持在DataStudio界面直接测试运行do-while节点。如果您想测试验证do-while节点的运行结果,您需要将包含do-while节点的任务发布提交到运维中心,在运维中心页面运行do-while节点任务。如果您在do-while节点内使用了赋值节点传递的值,请在运维中心测试时,同时运行赋值节点和循环节点。
- 在运维中心查看do-while节点的执行日志时,您需要右键实例,单击查看内部节点来查看内部节点的执行日志。
1.3 典型应用:与赋值节点联合使用
do-while节点常常与赋值节点联合使用,如下图所示。
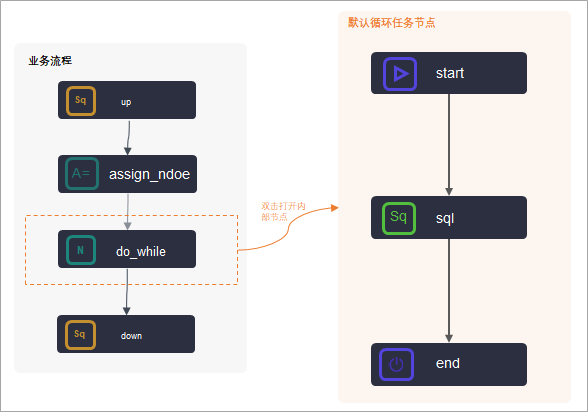
与赋值节点联合使用时:
- 您需要将赋值节点的输出作为赋值节点的本节点输入,且与赋值节点做好上下游依赖关系的配置,其他配置注意事项请参见案例2:与赋值节点联合使用。
- 与赋值节点联合使用时,可以使用一些内置变量来获取当前已循环次数、赋值参数值等循环变量值,详情请参见内置变量。
1.4 内置变量
DataWorks的do-while节点,通过内部节点来实现循环运行任务,每次任务循环运行时,您可以通过一些内置的变量来获取当前已循环次数和偏移量。
|
内置变量 |
含义 |
取值 |
|
${dag.loopTimes} |
当前已循环次数 |
第一次循环为1、第二次为2、第三次为3…第n次为n。 |
|
${dag.offset} |
偏移量 |
第一次循环为0、第二次为1、第三次为2…第n次为n-1。 |
如果您联合使用了赋值节点,则还可以通过以下方式来获取赋值参数值和循环变量参数。
说明以下以变量示例中,input是do-while节点中自定义的本节点输入参数名称,实际使用时,需替换为您真实的名称。
|
内置变量 |
含义 |
|
${dag.input} |
上游赋值节点传递的数据集。 |
|
${dag.input[${dag.offset}]} |
循环节点内部获取当前循环的数据行。 |
|
${dag.input.length} |
循环节点内部获取数据集长度。 |
1.5 变量取值案例
- 案例1
上游赋值节点为shell节点,最后一条输出结果为2021-03-28,2021-03-29,2021-03-30,2021-03-31,2021-04-01,此时,各变量的取值如下:
|
内置变量 |
第1次循环时取值 |
第2次循环时取值 |
|
${dag.input} |
2021-03-28,2021-03-29,2021-03-30,2021-03-31,2021-04-01 |
|
|
${dag.input[${dag.offset}]} |
2021-03-28 |
2021-03-29 |
|
${dag.input.length} |
5 |
|
|
${dag.loopTimes} |
1 |
2 |
|
${dag.offset} |
0 |
1 |
- 案例2
上游赋值节点为ODPS SQL节点,最后一条select语句查询出两条数据:
+----------------------------------------------+
| uid | region | age_range | zodiac |
+----------------------------------------------+
| 0016359810821 | 湖北省 | 30~40岁 | 巨蟹座 |
| 0016359814159 | 未知 | 30~40岁 | 巨蟹座 |
+----------------------------------------------+
此时,各变量的取值如下:
|
内置变量 |
第1次循环时取值 |
第2次循环时取值 |
|
${dag.input} |
|
|
|
${dag.input[${dag.offset}]} |
0016359810821,湖北省,30~40岁,巨蟹座 |
0016359814159,未知,30~40岁,巨蟹座 |
|
${dag.input.length} |
2 说明 二维数组的行数为数据集长度,当前赋值节点输出的二维数组行数为2。 |
|
|
${dag.input[0][1] 说明 二维数组的第一行第一列的取值。 |
0016359810821 |
|
|
${dag.loopTimes} |
1 |
2 |
|
${dag.offset} |
0 |
1 |
Part2:遍历节点(for-each节点)
2.1 节点组成
DataWorks的for-each节点是包含内部节点的一种特殊节点,您在创建完成for-each节点时,同时也自动创建完成了三个内部节点:start节点(循环开始节点)、sql节点(循环任务节点)、end节点(循环结束判断节点),通过内部节点组织成内部节点流程,实现对上游赋值接节点输出结果的循环遍历。
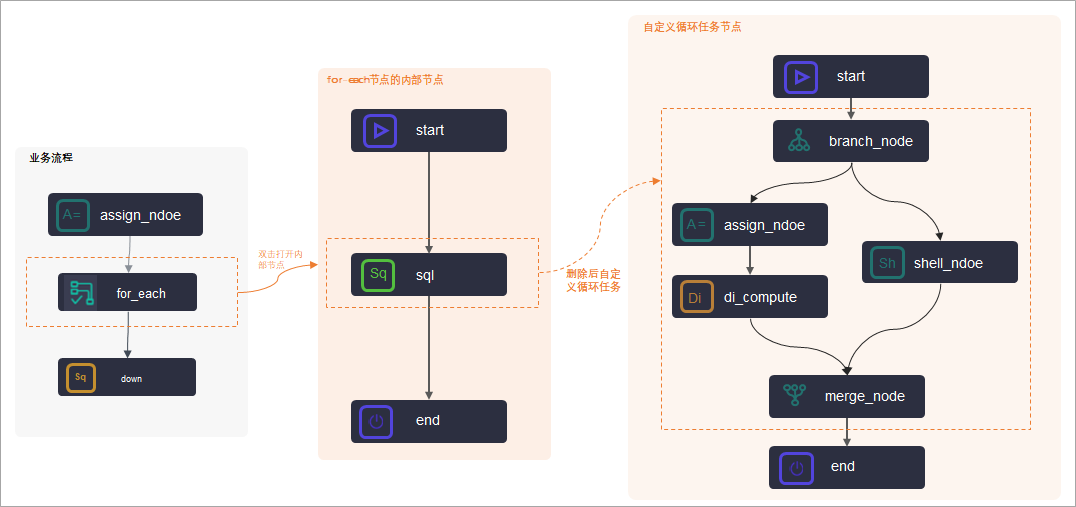
如上图所示:
- sql节点DataWorks默认为您创建好了一个SQL类型的内部任务运行节点,您也可以删除默认的sql节点后,自定义内部循环遍历任务的运行节点。
- 您的循环遍历任务是SQL类型的任务,则可以直接双击默认的sql节点,进入节点的代码开发页面开发任务代码。
- 您的循环遍历任务比较复杂,您可以在内部节点流程中新建其他任务节点,并根据实际情况重新构建节点的运行流程。
说明 自定义循环任务节点时,您可以删除内部节点间的依赖关系,重新编排循环节点内部业务流程,但需要分别将start节点、end节点分别作为for-each节点内部业务流程的首末节点。
- start节点与end节点是内部节点业务流程每次循环遍历的开始节点与结束节点,不承载具体的任务代码。
说明 for-each节点的end节点不控制循环遍历的次数,for-each节点的循环遍历次数由上游赋值节点实际输出控制。
2.2 使用限制与注意事项
- 上下游依赖
for-each遍历节点需要遍历赋值节点传递的值,所以赋值节点需作为for-each节点的上游节点,for-each节点需要依赖赋值节点。
- 循环支持
- 仅DataWorks标准版及以上版本支持使用for-each节点。
- for-each节点最多支持循环128次,如果超过了128次,则运行会报错。实际循环遍历次数由上游赋值节点实际输出控制。
- 一维数组类型的输出,循环遍历次数即为一维数组元素的个数。例如,赋值节点的赋值语言为SEHLL或Python(Python2)时,输出结果为一维数组:2021-03-28,2021-03-29,2021-03-30,2021-03-31,2021-04-01,则for-each节点会循环5次完成遍历。
- 二维数组类型的输出,循环遍历次数即为二维数组元素的行数。例如,赋值节点的赋值语言为OdpsSQL时,输出结果为二维数组:
+----------------------------------------------+
| uid | region | age_range | zodiac |
+----------------------------------------------+
| 0016359810821 | 湖北省 | 30~40岁 | 巨蟹座 |
| 0016359814159 | 未知 | 30~40岁 | 巨蟹座 |
+----------------------------------------------+
则for-each节点会循环2次完成遍历。
- 内部节点
- 您可以删除for-each节点的内部节点间的依赖关系,重新编排内部业务流程,但需要分别将start节点、end节点分别作为for-each节点内部业务流程的首末节点。
- 在for-each节点的内部节点使用分支节点进行逻辑判断或者结果遍历时,需要同时使用归并节点。
- 调测运行
- DataWorks为标准模式时,不支持在DataStudio界面直接测试运行for-each节点。如果您想测试验证for-each节点的运行结果,您需要将包含for-each节点的任务发布提交到运维中心,在运维中心页面运行for-each节点任务。
- 在运维中心查看for-each节点的执行日志时,您需要右键实例,单击查看内部节点来查看内部节点的执行日志。
2.3 典型应用
DataWorks的for-each节点主要用于有循环遍历的场景,且需要与赋值节点联合使用,将赋值节点作为for-each节点的上游节点,将赋值节点的输出结果赋值给for-each节点后,一次次循环来遍历赋值节点的输出结果。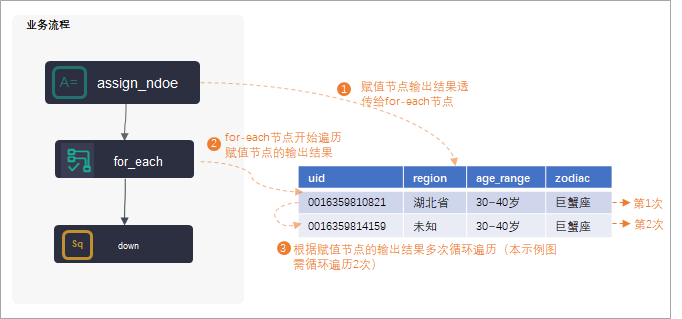
2.4 内置变量
DataWorks的for-each节点每次循环遍历赋值节点的输出结果时,您可以通过一些内置的变量来获取当前已循环次数和偏移量。
|
内置变量 |
含义 |
与for循环对比 |
|
${dag.loopDataArray} |
获取赋值节点的数据集 |
相当于for循环中的代码结果: data=[] |
|
${dag.foreach.current} |
获取当前遍历值 |
以下面的for循环代码为例:
|
|
${dag.offset} |
当前偏移量 (每一次遍历相对于第一次的偏移量) |
|
|
${dag.loopTimes} |
获取当前遍历次数 |
- |
在您了解自己输出的表结构的情况下,您可以使用如下变量方式,获取其他变量取值。
|
其他变量 |
含义 |
|
${dag.foreach.current[n]} |
上游赋值节点的输出结果为二维数组时,每次遍历时获取当前数据行的某列的数据。 |
|
${dag.loopDataArray[i][j]} |
上游赋值节点的输出结果为二维数组时,获取数据集中具体i行j列的数据。 |
|
${dag.foreach.current[n]} |
上游赋值节点的输出结果为一维数组时,获取具体某列数据。 |
2.5 内置变量取值案例
- 案例1
上游赋值节点为shell节点,最后一条输出结果为2021-03-28,2021-03-29,2021-03-30,2021-03-31,2021-04-01,此时,各变量的取值如下:
说明 由于输出结果为一维数组,数组元素个数为5(逗号分隔每个元素),因此for-each总遍历次数为5。
|
内置变量 |
第1次循环遍历的取值 |
第2次循环遍历的取值 |
|
${dag.loopDataArray} |
2021-03-28,2021-03-29,2021-03-30,2021-03-31,2021-04-01 |
|
|
${dag.foreach.current} |
2021-03-28 |
2021-03-29 |
|
${dag.offset} |
0 |
1 |
|
${dag.loopTimes} |
1 |
2 |
|
${dag.foreach.current[3]} |
2021-03-30 |
|
- 案例2
上游赋值节点为ODPS SQL节点,最后一条select语句查询出两条数据:
+----------------------------------------------+
| uid | region | age_range | zodiac |
+----------------------------------------------+
| 0016359810821 | 湖北省 | 30~40岁 | 巨蟹座 |
| 0016359814159 | 未知 | 30~40岁 | 巨蟹座 |
+----------------------------------------------+
此时,各变量的取值如下:
说明 由于输出结果为二维数组,数组行数为2,因此for-each总遍历次数为2。
|
内置变量 |
第1次循环遍历的取值 |
第2次循环遍历的取值 |
|
${dag.loopDataArray} |
|
|
|
${dag.foreach.current} |
0016359810821,湖北省,30~40岁,巨蟹座 |
0016359814159,未知,30~40岁,巨蟹座 |
|
${dag.offset} |
0 |
1 |
|
${dag.loopTimes} |
1 |
2 |
|
${dag.foreach.current[0]} |
0016359810821 |
0016359814159 |
|
${dag.loopDataArray[1][0]} |
0016359814159 |
|
DataWorks功能实践速览 05——循环与遍历的更多相关文章
- .NET平台开源项目速览(13)机器学习组件Accord.NET框架功能介绍
Accord.NET Framework是在AForge.NET项目的基础上封装和进一步开发而来.因为AForge.NET更注重与一些底层和广度,而Accord.NET Framework更注重与机器 ...
- 互联网巨头们的 SRE 运维实践「GitHub 热点速览 v.21.27」
作者:HelloGitHub-小鱼干 本周大热点无疑是前几天 GitHub 发布的 Copilot,帮你补全代码,给你的注释提出建议,预测你即将使用的代码组件-如此神奇的 AI 技术,恰巧本周微软也开 ...
- .NET平台开源项目速览-最快的对象映射组件Tiny Mapper之项目实践
心情小札:近期换了工作,苦逼于22:00后下班,房间一篇狼藉~ 小翠鄙视到:"你就适合生活在垃圾堆中!!!" 晚上浏览博客园 看到一篇非常实用的博客:.NET平台开源项目速览(14 ...
- .NET平台开源项目速览(1)SharpConfig配置文件读写组件
在.NET平台日常开发中,读取配置文件是一个很常见的需求.以前都是使用System.Configuration.ConfigurationSettings来操作,这个说实话,搞起来比较费劲.不知道大家 ...
- .NET平台开源项目速览(11)KwCombinatorics排列组合使用案例(1)
今年上半年,我在KwCombinatorics系列文章中,重点介绍了KwCombinatorics组件的使用情况,其实这个组件我5年前就开始用了,非常方便,麻雀虽小五脏俱全.所以一直非常喜欢,才写了几 ...
- .NET平台开源项目速览(8)Expression Evaluator表达式计算组件使用
在文章:这些.NET开源项目你知道吗?让.NET开源来得更加猛烈些吧!(第二辑)中,给大家初步介绍了一下Expression Evaluator验证组件.那里只是概述了一下,并没有对其使用和强大功能做 ...
- 快看Sample代码,速学Swift语言(1)-语法速览
Swift是苹果推出的一个比较新的语言,它除了借鉴语言如C#.Java等内容外,好像还采用了很多JavaScript脚本里面的一些脚本语法,用起来感觉非常棒,作为一个使用C#多年的技术控,对这种比较超 ...
- 自制车速记录仪「GitHub 热点速览 v.21.31」
作者:HelloGitHub-小鱼干 如果你有一辆普通的自行车,那么就可以使用下 X-TRACK 这个项目制作一个自己的测速器,记录你的行驶轨迹还有车速,体验一把硬件发烧友的乐趣.如果你有一个非 ma ...
- GitHub 公布 2021 Top 10 博文「GitHub 热点速览」
作者:HelloGitHub-小鱼干 2021 年在这周彻底同我们告别了,在本周的「News 快读」模块你可以看到过去一年 GitHub 的热门文章,其中有我们熟悉的可能让很多程序员"失业& ...
- 读 Linux 像读小说「GitHub 热点速览 v.22.03」
本周特推选取了一个画风有点意思的 Linux 代码带读项目 flash-linux0.11-talk,希望有趣的文风能带你读完 Linux 代码.当然画风可以增加阅读体验,彩色标记也是一种学习方法-- ...
随机推荐
- 【leetcode 1425. 带限制的子序列和】【矩阵幂快速运算】
class Solution { public int countVowelPermutation(int n) { long[][] matrix = new long[][]{ {0, 1, 1, ...
- 5G+云渲染:如何快速推进XR和元宇宙实现?
XR(扩展现实)领域正在以惊人的速度增长.目前,到 2024 年,一些专家表示这个行业的价值将达到 3000 亿美元. 这个行业发展如此迅速的部分原因是 XR 将在商业环境中的带来巨大利益.近年来,很 ...
- eviacam在Arch/Manjaro Linux下的安装
安装base-devel 安装编译工具,默认的依赖里没有编译工具 sudo yay -S base-devel 如果安装编译工具,会报类似下面的错误: 安装eviacam yay -S eviacam ...
- 记录--两行CSS让页面提升了近7倍渲染性能
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前言 对于前端人员来讲,最令人头疼的应该就是页面性能了,当用户在访问一个页面时,总是希望它能够快速呈现在眼前并且是可交互状态.如果页面加载 ...
- FreeMarker介绍及基本数据类型和用法
FreeMarker介绍及基本数据类型和用法 FreeMarker 中文官方参考手册 FreeMarker 英文官方参考手册 一.FreeMarker介绍 FreeMarker 是一款 模板引擎: 即 ...
- MySQL函数GROUP_CONCAT()函数简介
一.数据需求按id分组然后把name用英文逗号分隔开 id name countryid age 1 曹操 1 56 2 刘备 2 47 3 孙权 3 38 4 司马懿 1 61 5 诸葛亮 2 42 ...
- AMD、request.js,生词太多,傻傻搞不清
前言 之前在公司用JS写前端页面,本来自己是一个写后端的,但是奈何人少,只能自己也去写了.但是自己对前端基本不懂,基本就是照着前人写的照着抄,反正大体意思是明白的,但是出现问题了,基本上也是吭哧吭哧好 ...
- #NTT,原根#洛谷 3321 JZOJ 4051 [SDOI2015]序列统计
题目 分析 首先朴素dp方程 设\(dp[i][j]\)表示\(i\)个数的数列乘积为\(j\)的方案 那么\(dp[i][j*a[k]\bmod m]=itself+dp[i-1][j]\) 这可以 ...
- Java 枚举(Enums)解析:提高代码可读性与易维护性
接口 在 Java 中,实现抽象的另一种方式是使用接口. 接口定义 接口是一个完全抽象的类,用于将具有空方法体的相关方法分组: // 接口 interface Animal { public void ...
- 开发指导—利用CSS动画实现HarmonyOS动效(二)
注:本文内容分享转载自HarmonyOS Developer官网文档 点击查看<开发指导-利用CSS动画实现HarmonyOS动效(一)> 3. background-position ...