ES进阶
https://www.elastic.co/guide/en/elasticsearch/reference/current/cat.html
1.监控接口
访问es的_cat接口,获取不同的属性
http://10.0.0.51:9200/_cat/health
http://10.0.0.51:9200/_cat/nodes
http://10.0.0.51:9200/_cat/master
http://10.0.0.51:9200/_cat/indices
http://10.0.0.51:9200/_cat/shards
http://10.0.0.51:9200/_cat/shards/t2
#http接口查看集群状态
# 判断是否健康
[root@es-node1 ~]#curl -s 127.0.0.1:9200/_cat/health|grep 'green' | wc -l
1
[root@es-node1 ~]#
# 统计es节点数量
[root@es-node1 ~]#curl -s 127.0.0.1:9200/_cat/nodes | wc -l
3
[root@es-node1 ~]#kibana控制台

kibana开启监控
添加监控
打开监控
查看es集群信息
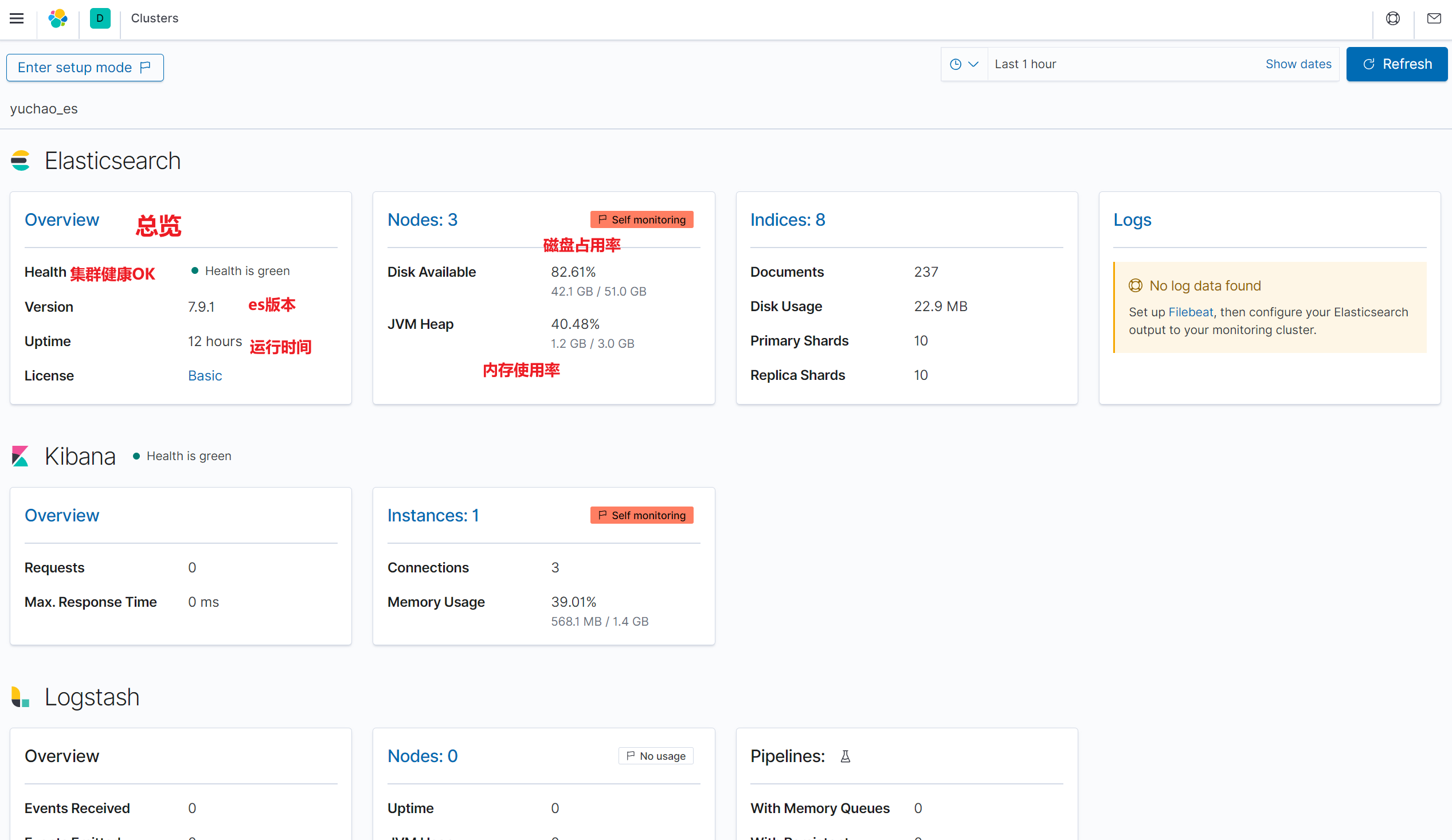
节点使用率状态
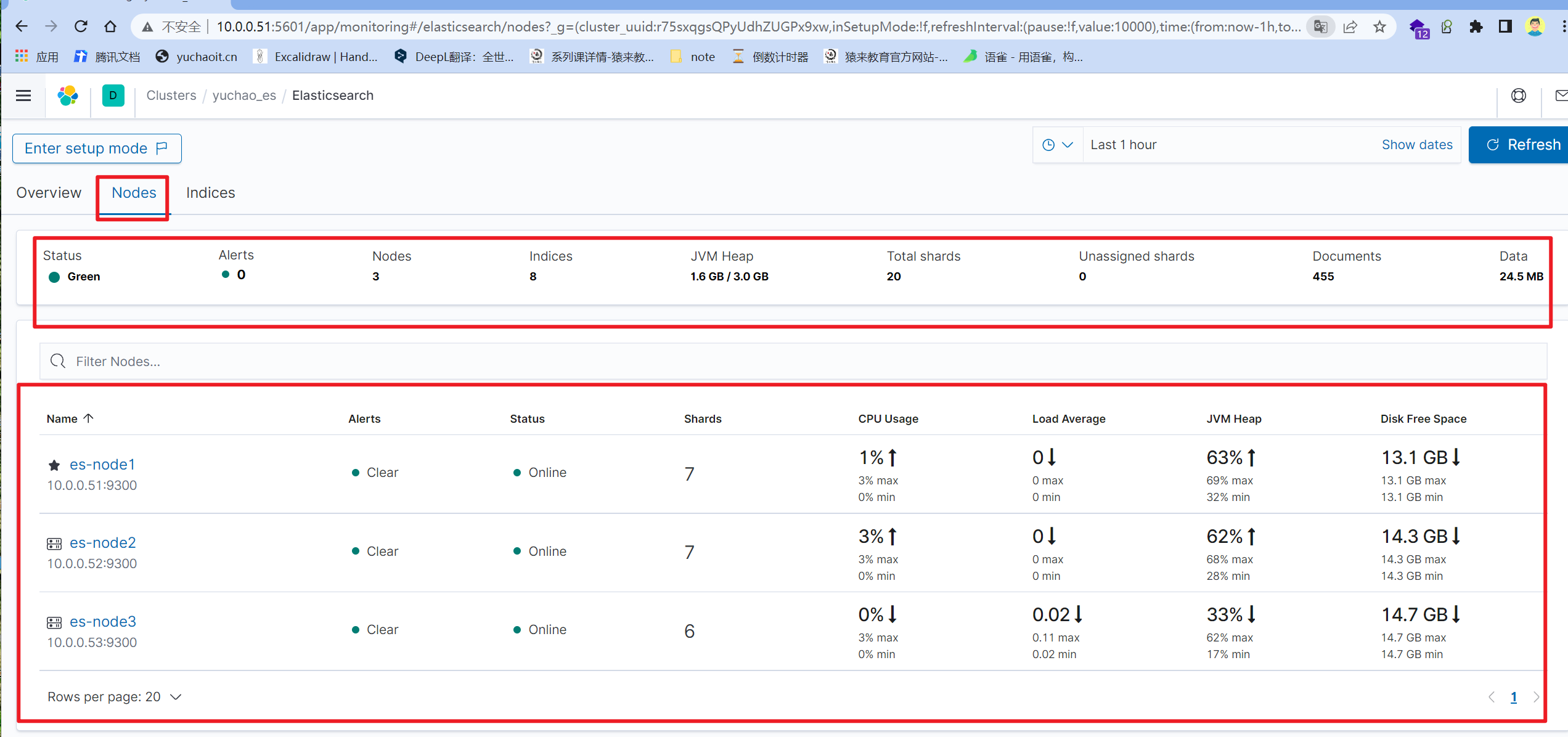
kibana生成的监控数据
kibana获取监控数据,写入es,然后kibana再读。
10s采集区间。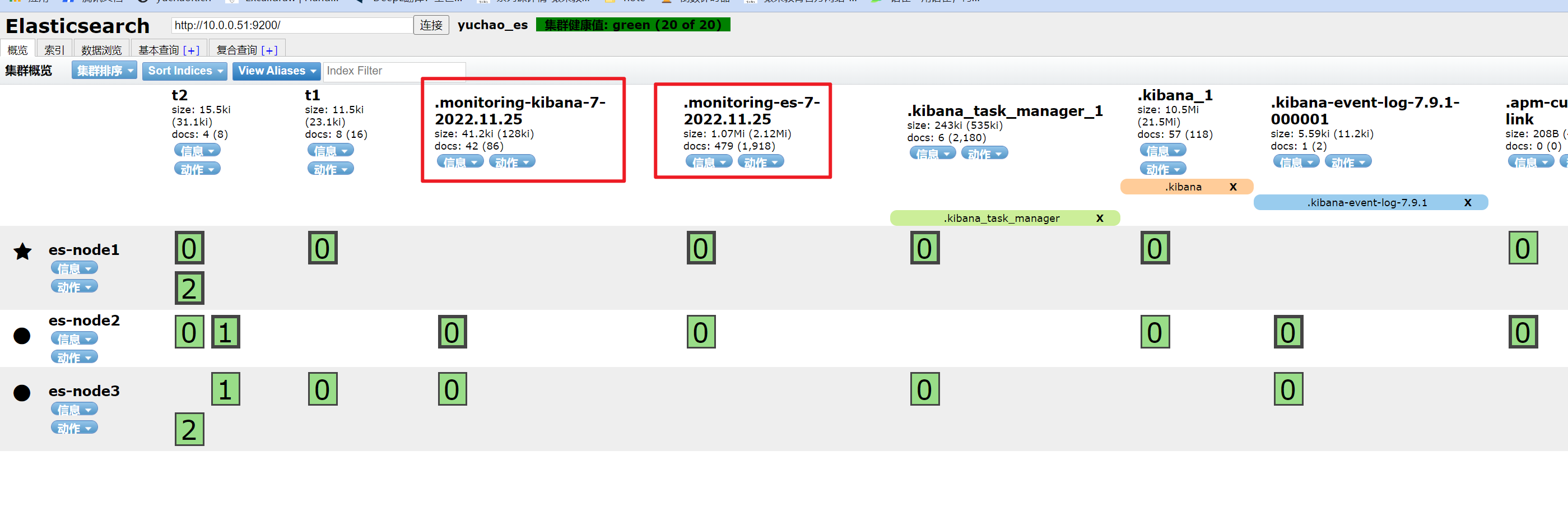
关闭kibana监控
# 查看集群状态,是否监控
GET /_cluster/settings
PUT /_cluster/settings
{
"persistent" : {
"xpack" : {
"monitoring" : {
"collection" : {
"enabled" : "false"
}
}
}
},
"transient" : { }
}
# 可以删除监控数据index2.ES中文分词器
创建测试数据
PUT /news2/_doc/1
{"content":"美国留给伊拉克的是个烂摊子吗"}
PUT /news2/_doc/2
{"content":"公安部:各地校车将享最高路权"}
PUT /news2/_doc/3
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}
PUT /news2/_doc/4
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}
关键字查询
POST /news/_search
{
"query":{"match":{"content":"中国"}},
"highlight":{
"pre_tags":["--","=="],
"post_tags":["--","=="],
"fields":{
"content":{}
}
}
}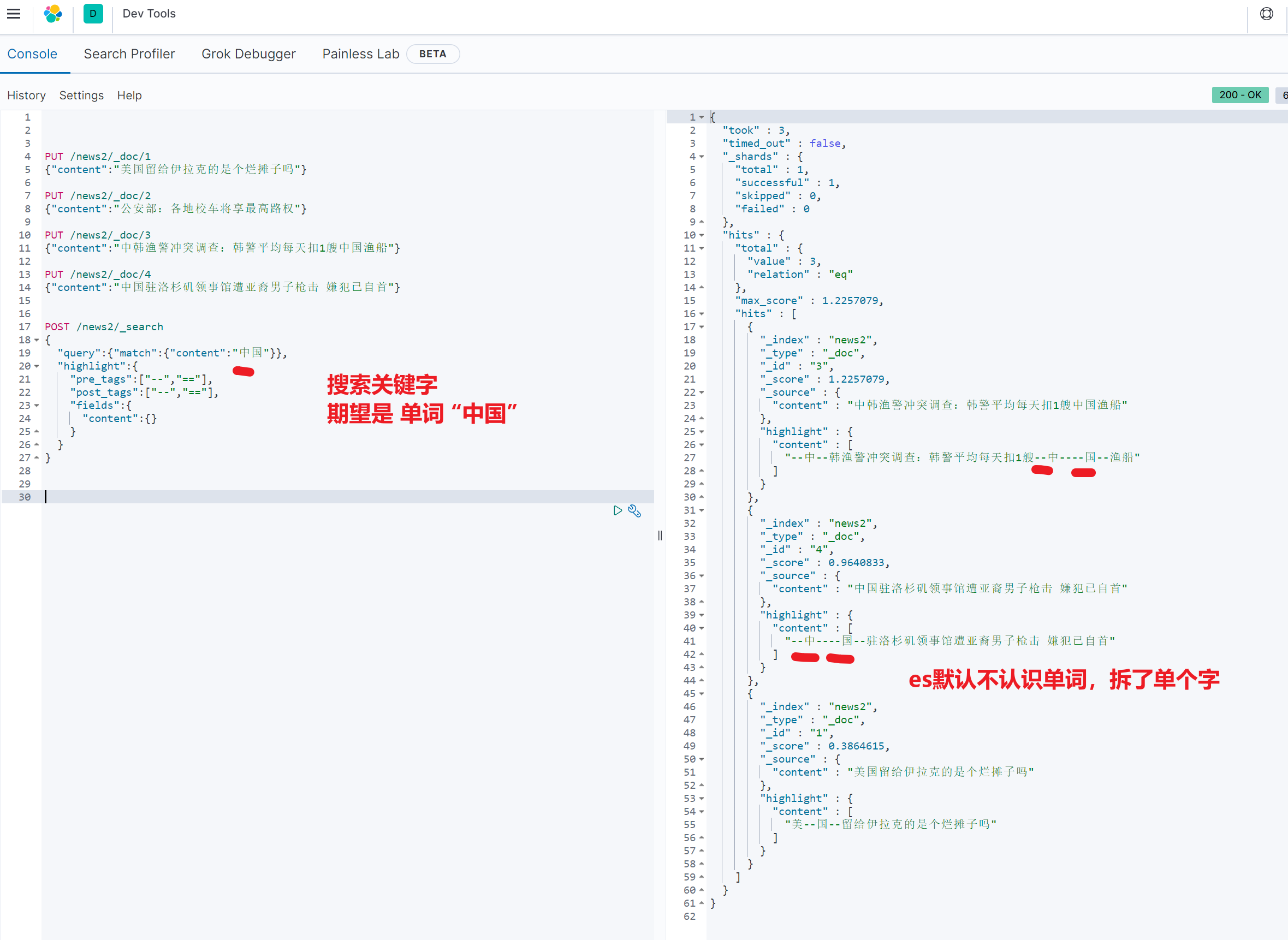
坑
你搜索的命名是词语,但是es认为是单个的字母。
修改es中文查询
1.这是第三方插件,需要给es所有节点部署,且重启
2.中文分词器版本,与es版本对应
3.下载地址
https://github.com/medcl/elasticsearch-analysis-ik安装中文分词器插件
# 在线安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.9.1/elasticsearch-analysis-ik-7.9.1.zip
# 离线安装,3个机器
[root@es-node3 ~]#/usr/share/elasticsearch/bin/elasticsearch-plugin install file:///root/elasticsearch-analysis-ik-7.9.1.zip
-> Installing file:///root/elasticsearch-analysis-ik-7.9.1.zip
-> Downloading file:///root/elasticsearch-analysis-ik-7.9.1.zip
[=================================================] 100%
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.net.SocketPermission * connect,resolve
See http://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
-> Installed analysis-ik
# 重启3个节点的es
systemctl restart elasticsearch.service测试中文分词器
1. 要创建支持中文的索引模板
PUT /news_cn/
2. 创建索引使用哪一款分词器
PUT /news_cn/_doc/_mapping?include_type_name=true
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
# 根据教程走即可
https://github.com/medcl/elasticsearch-analysis-ik
# 插入新数据解释
ik_max_word 和 ik_smart 什么区别?
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”
拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
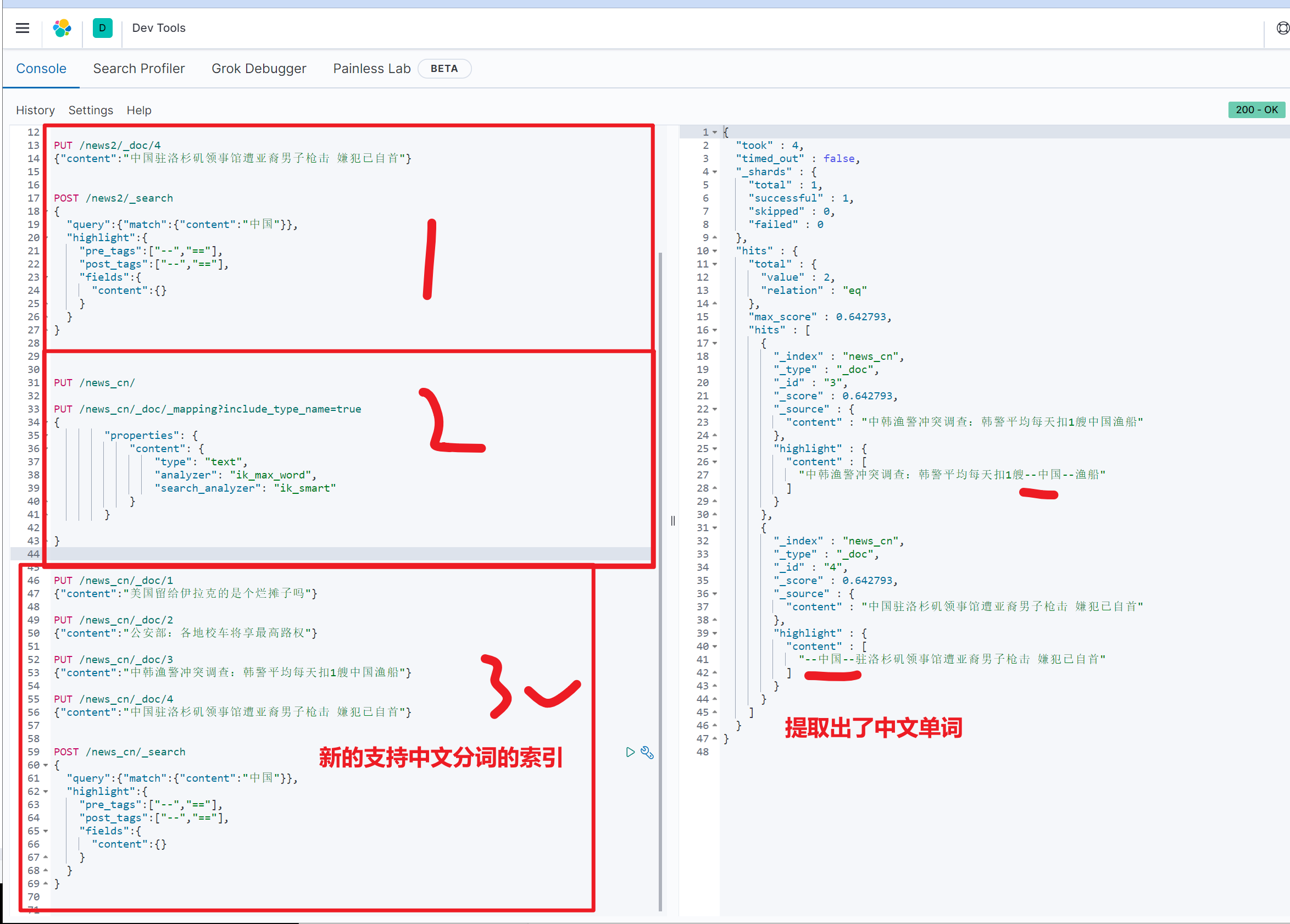
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。完整中文分词效果
POST /news/_search
{
"query":{"match":{"content":"中国"}},
"highlight":{
"pre_tags":["--","=="],
"post_tags":["--","=="],
"fields":{
"content":{}
}
}
}
创建自带中文词库
[root@es-node3 /etc/elasticsearch/analysis-ik]#wc -l main.dic
275908 main.dic更新中文词库
1. 安装nginx
[root@es-node1 ~]#yum install nginx -y
2.写好词典文件
cat >> /usr/share/nginx/html/my_word.txt <<'EOF'
北京
上海
江苏
淮安
山东
于超
周杰伦
EOF
3.启动访问nginx的词典
[root@es-node1 ~]#nginx
[root@es-node1 ~]#
[root@es-node1 ~]#curl 10.0.0.51/my_word.txt
北京
上海
江苏
淮安
山东
于超
周杰伦
[root@es-node1 ~]#
4.修改es中文分词器插件
[root@es-node1 ~]#
cat >/etc/elasticsearch/analysis-ik/IKAnalyzer.cfg.xml <<'EOF'
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://10.0.0.51/my_word.txt</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
EOF
5.同步3个机器的配置文件
cd /etc/elasticsearch/analysis-ik/
scp IKAnalyzer.cfg.xml root@10.0.0.52:/etc/elasticsearch/analysis-ik/
scp IKAnalyzer.cfg.xml root@10.0.0.53:/etc/elasticsearch/analysis-ik/
6.重启所有节点的es,检查日志
systemctl restart elasticsearch.service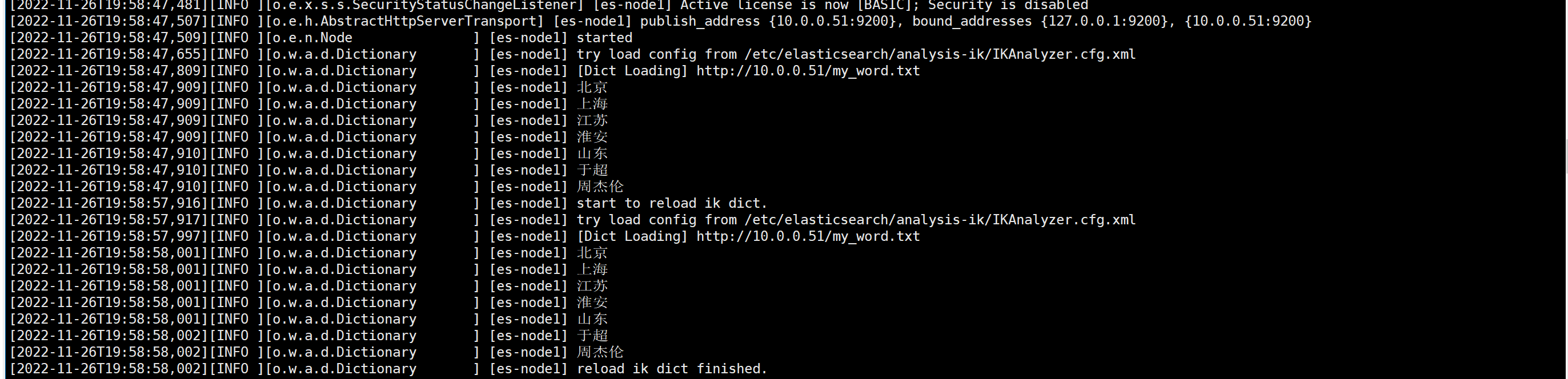
试试是否识别自定义中文词典
# 默认词库里是没有的
[root@es-node3 /etc/elasticsearch/analysis-ik]#grep '于超' main.dic
# 注意修改索引,采用中文分词插件
# 注意步骤,先创建index,修改属性
PUT /names/
PUT /names/_doc/_mapping?include_type_name=true
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
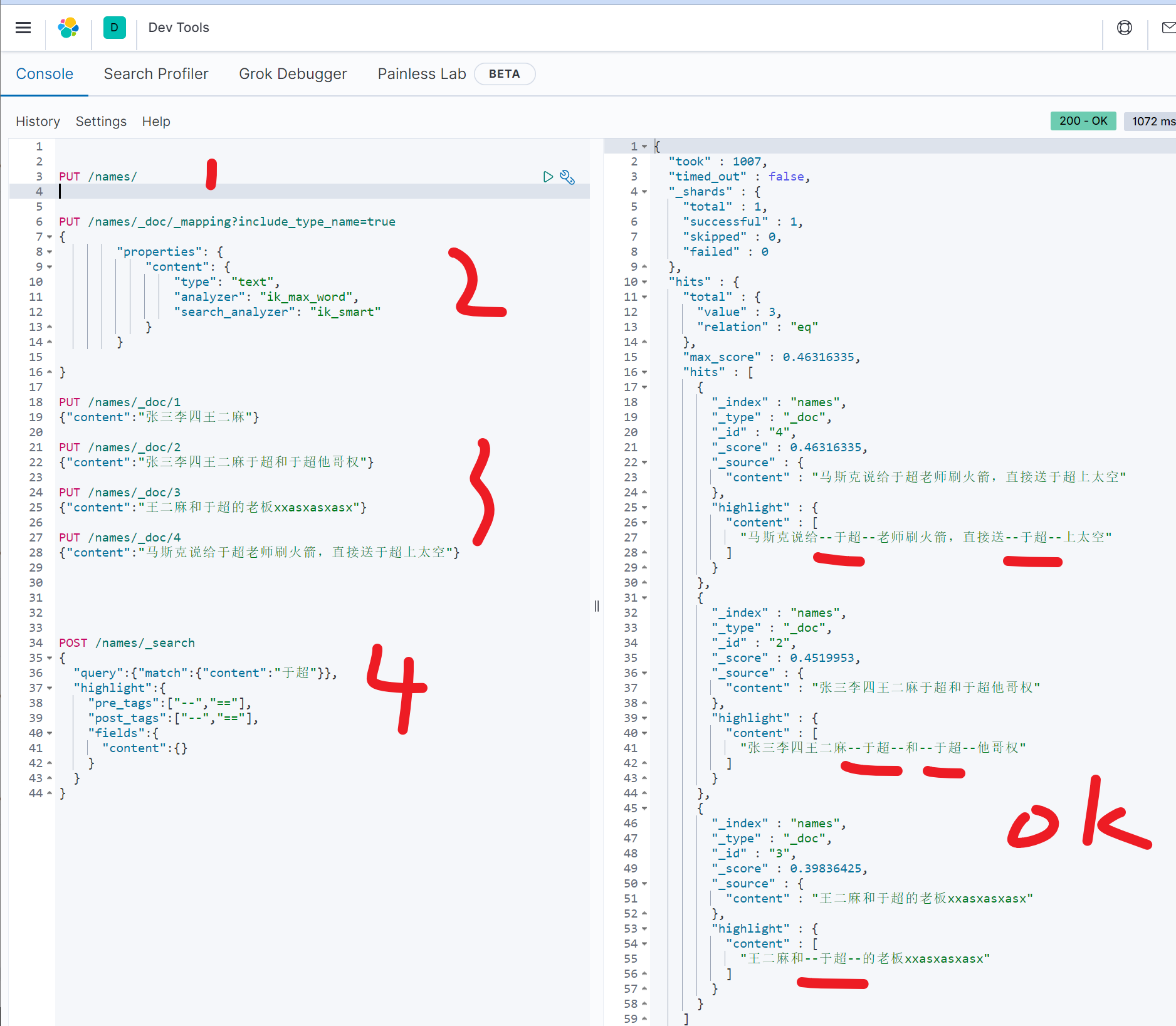
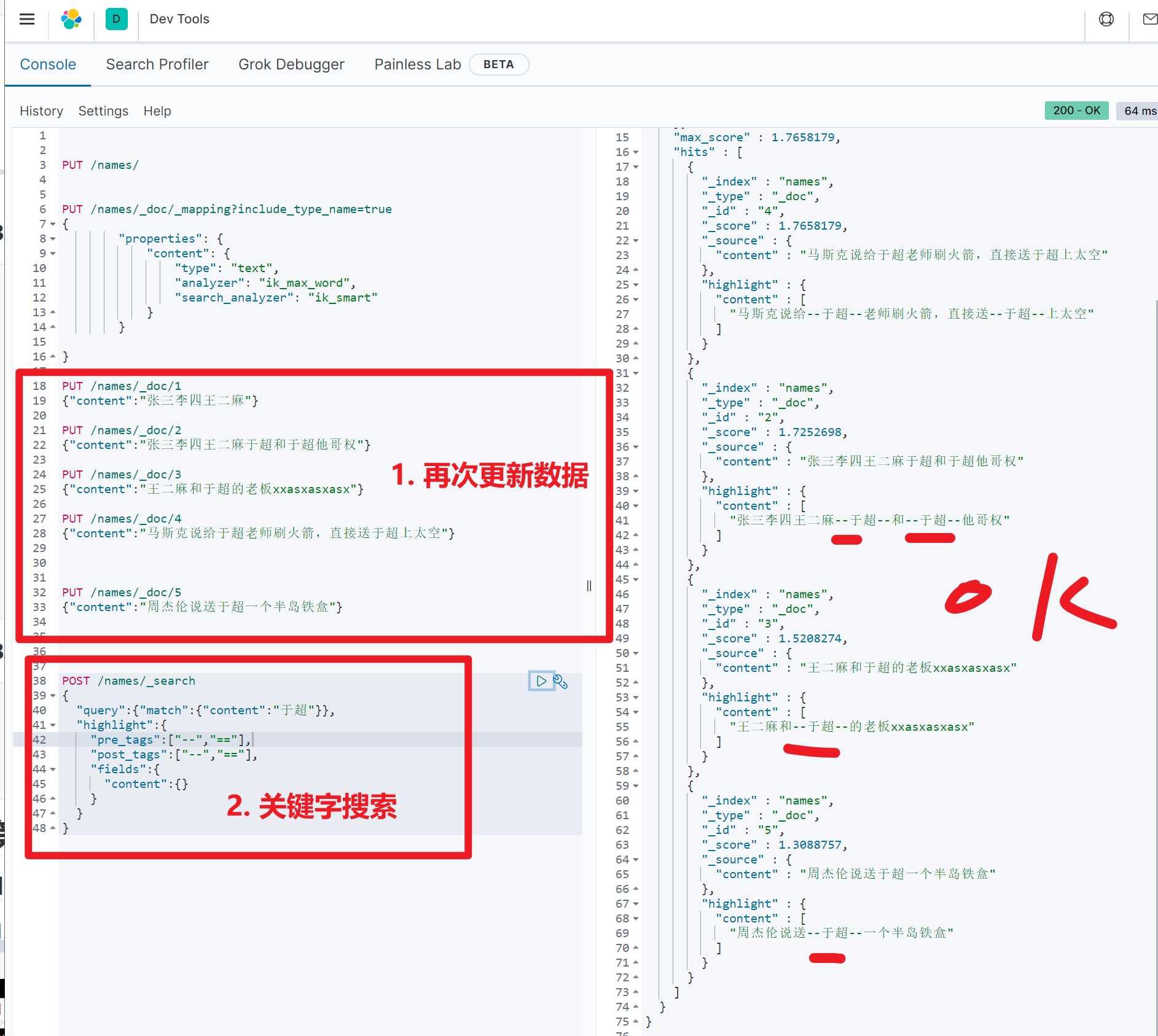
# 再写入数据
PUT /names/_doc/1
{"content":"张三李四王二麻"}
PUT /names/_doc/2
{"content":"张三李四王二麻于超和于超他哥权"}
PUT /names/_doc/3
{"content":"王二麻和于超的老板xxasxasxasx"}
PUT /names/_doc/4
{"content":"马斯克说给于超老师刷火箭,直接送于超上太空"}图示,提取了中文于超
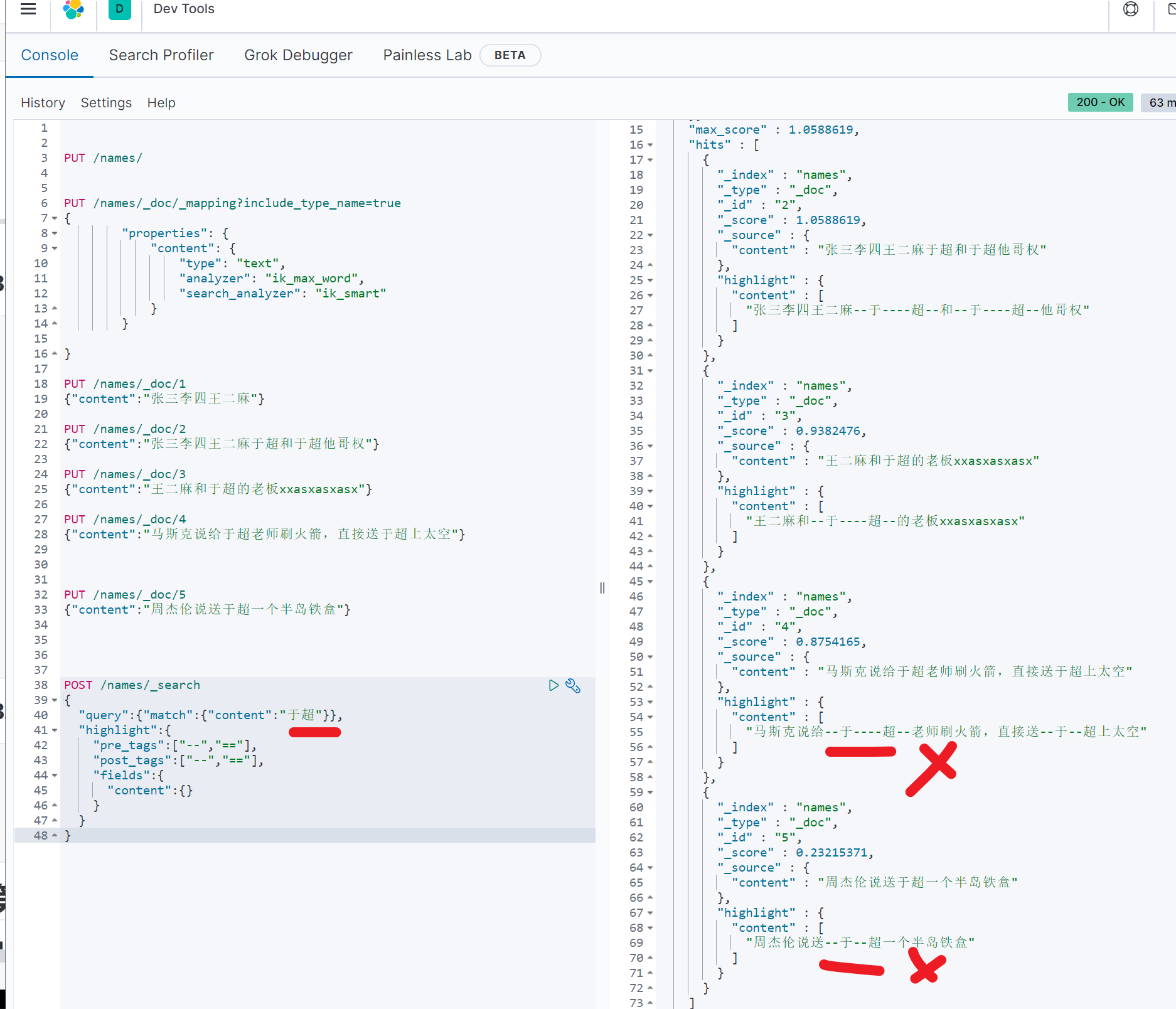
去掉词库的中文单词
es中文插件以支持nginx的热更新
去掉单词,于超
此时已经不认识了单词“于超”
再次添加nginx词典,热更新
1. 60s 更新时间
2. 注意,数据要更新index(公司里后端开发,会主动更新,新产品的关键词,更新词典,然后再录入数据)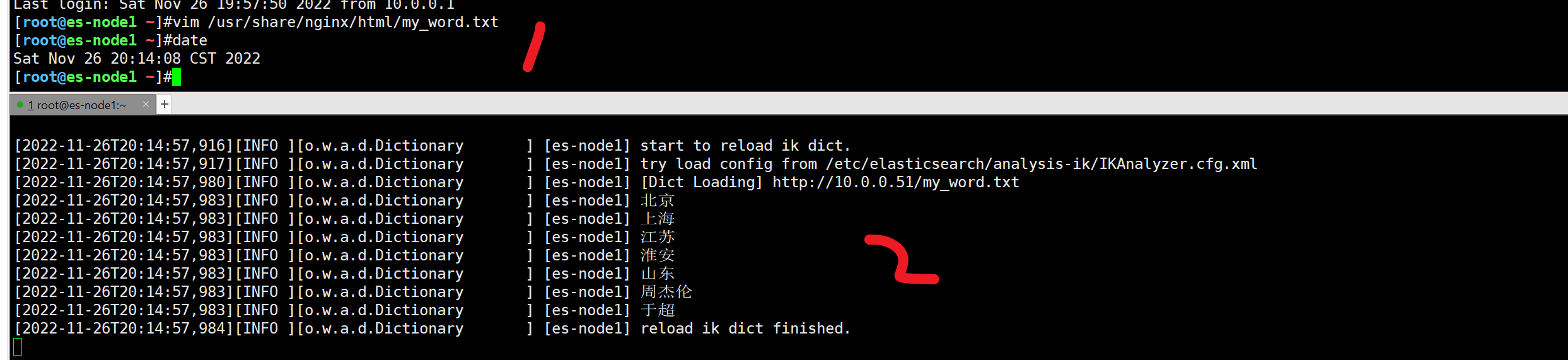
ES进阶的更多相关文章
- ES进阶--04
第30节彻底掌握IK中文分词_上机动手实战IK中文分词器的安装和使用 之前大家会发现,我们全部是用英文在玩儿...好玩儿不好玩儿...不好玩儿 中国人,其实我们用来进行搜索的,绝大多数,都是中文应用, ...
- ES进阶--02
第11节深度探秘搜索技术_案例实战基于dis_max实现best fields策略进行多字段搜索 课程大纲 1.为帖子数据增加content字段 POST /forum/article/_bulk{ ...
- ES进阶--01
第2节结构化搜索_在案例中实战使用term filter来搜索数据 课程大纲 1.根据用户ID.是否隐藏.帖子ID.发帖日期来搜索帖子 (1)插入一些测试帖子数据 POST /forum/articl ...
- 白日梦的ES笔记三:万字长文 Elasticsearch基础概念统一扫盲
目录 一.导读 二.彩蛋福利:账号借用 三.ES的Index.Shard及扩容机制 四.ES支持的核心数据类型 4.1.数字类型 4.2.日期类型 4.3.boolean类型 4.4.二进制类型 4. ...
- ElasticSearch[v6.2] 在实际项目中的应用
摘要:本文所讲述的内容,为ElasticSearch(以下简称ES)全文搜索引擎在实际大数据项目的应用:ES的底层是开源库 Lucene.但是,你没法直接用 Lucene,必须自己写代码去调用它的接口 ...
- [.net 面向对象程序设计进阶] (2) 正则表达式 (一) 快速入门
[.net 面向对象程序设计进阶] (2) 正则表达式 (一) 快速入门 1. 什么是正则表达式? 1.1 正则表达式概念 正则表达式,又称正则表示法,英文名:Regular Expression(简 ...
- [.net 面向对象程序设计进阶] (3) 正则表达式 (二) 高级应用
[.net 面向对象程序设计进阶] (2) 正则表达式 (二) 高级应用 上一节我们说到了C#使用正则表达式的几种方法(Replace,Match,Matches,IsMatch,Split等),还 ...
- gulp进阶构建项目由浅入深
gulp进阶构建项目由浅入深 阅读目录 gulp基本安装和使用 gulp API介绍 Gulp.src(globs[,options]) gulp.dest(path[,options]) gulp. ...
- Python之路,Day16 - Django 进阶
Python之路,Day16 - Django 进阶 本节内容 自定义template tags 中间件 CRSF 权限管理 分页 Django分页 https://docs.djangoproj ...
- 我的Android进阶之旅------>经典的大牛博客推荐(排名不分先后)!!
本文来自:http://blog.csdn.net/ouyang_peng/article/details/11358405 今天看到一篇文章,收藏了很多大牛的博客,在这里分享一下 谦虚的天下 柳志超 ...
随机推荐
- HarmonyOS NEXT应用开发—城市选择案例
介绍 本示例介绍城市选择场景的使用:通过AlphabetIndexer实现首字母快速定位城市的索引条导航. 效果图预览 使用说明 分两个功能 在搜索框中可以根据城市拼音模糊搜索出相近的城市,例如输入& ...
- 巧用API网关构建大型应用体系架构
简介: 近期阿里云重磅发布了BizWorks一体化的云原生应用的开发和运营平台,内置阿里巴巴业务中台构建的最佳技术实践.它已经将API网关作为关键组件融入其中,并且基于API网关为用户提供能力开放平台 ...
- PolarDB for PostgreSQL 内核解读 :HTAP架构介绍
简介:在 PolarDB 存储计算分离的架构基础上我们研发了基于共享存储的MPP架构步具备了 HTAP 的能力,对一套 TP的数据支持两套执行引擎:单机执行引擎用于处理高并发的 OLTP:MPP跨机分 ...
- KubeMeet|聊聊新锐开源项目与云原生新的价值聚焦点
简介: 10 月 16 日上海,OAM/KubeVela.OpenKruise.OCM 三大开源项目的社区负责人.核心贡献者和企业用户将齐聚 KubeMeet,和现场 100 名开发者聊聊新的技术环 ...
- 长文解析:作为容器底层技术的半壁江山, cgroup如何突破并发创建瓶颈?
简介: io_uring 作为一种新型高性能异步编程框架,代表着 Linux 内核未来的方向,当前仍处于快速发展中.阿里云联合 InfoQ 发起<io_uring 介绍及应用实践>的技术 ...
- Ubuntu WSL 下编译并使用OpenJDK12
一,安装Ubuntu WSL 1.Windows中设置WSL并安装Ubuntu wsl "控制面板"-->"程序"-->"启用或关闭Win ...
- S3-FIFO
S3-FIFO 本文作为下一篇缓存文章的预备知识. 背景 基于LRU和FIFO的驱逐 FIFO和LRU都是经典的缓存驱逐算法,在过去几十年中也出现了很多追求更高效率的驱逐算法,如ARC, 2Q, LI ...
- 11.IO 流
1.IO 流引入 概述:以应用程序为参照物,读取数据为输入流(Input),写数据为输出流(Output),大量输入输出数据简称 IO 流 原理: 2.IO 流的分类 读写的文件分类 二进制文件:打开 ...
- 04 elasticsearch学习笔记-Rest风格说明
目录 Rest风格说明 关于文档的基本操作 添加数据PUT 查询 修改文档 删除索引或者文档 Rest风格说明 Rest风格说明 method url地址 描述 PUT localhost:9200/ ...
- WEB服务与NGINX(9)-NGINX作为下载服务器的相关配置
目录 1. NGINX的目录索引功能 2. NGINX的限速功能 2.1 限制下载速度 2.2 限制单位时间内产生的http请求数 2.3 限制客户端同一时刻的并发连接数 1. NGINX的目录索引功 ...