Python爬虫实战之提高CSDN访问量
python爬虫之建立代理池(一)_CodingInCV的博客-CSDN博客
python爬虫之建立代理池(二)_CodingInCV的博客-CSDN博客
前面2篇分别介绍了从2个免费代理网站爬取免费代理来构建我们自己的代理池。这一篇我们从实战的角度来将我们的代理池用起来,通过代理的方式访问我们的CSDN博客(CSDN会认为是一次访问,访问量+1),从而实现访问量的增长,仅供学习爬虫使用···
获取博客文章列表和链接
获取博客列表的链接是https://blog.csdn.net/xxx/article/list/, 通过在后面添加页数,获取不同页的博客列表。
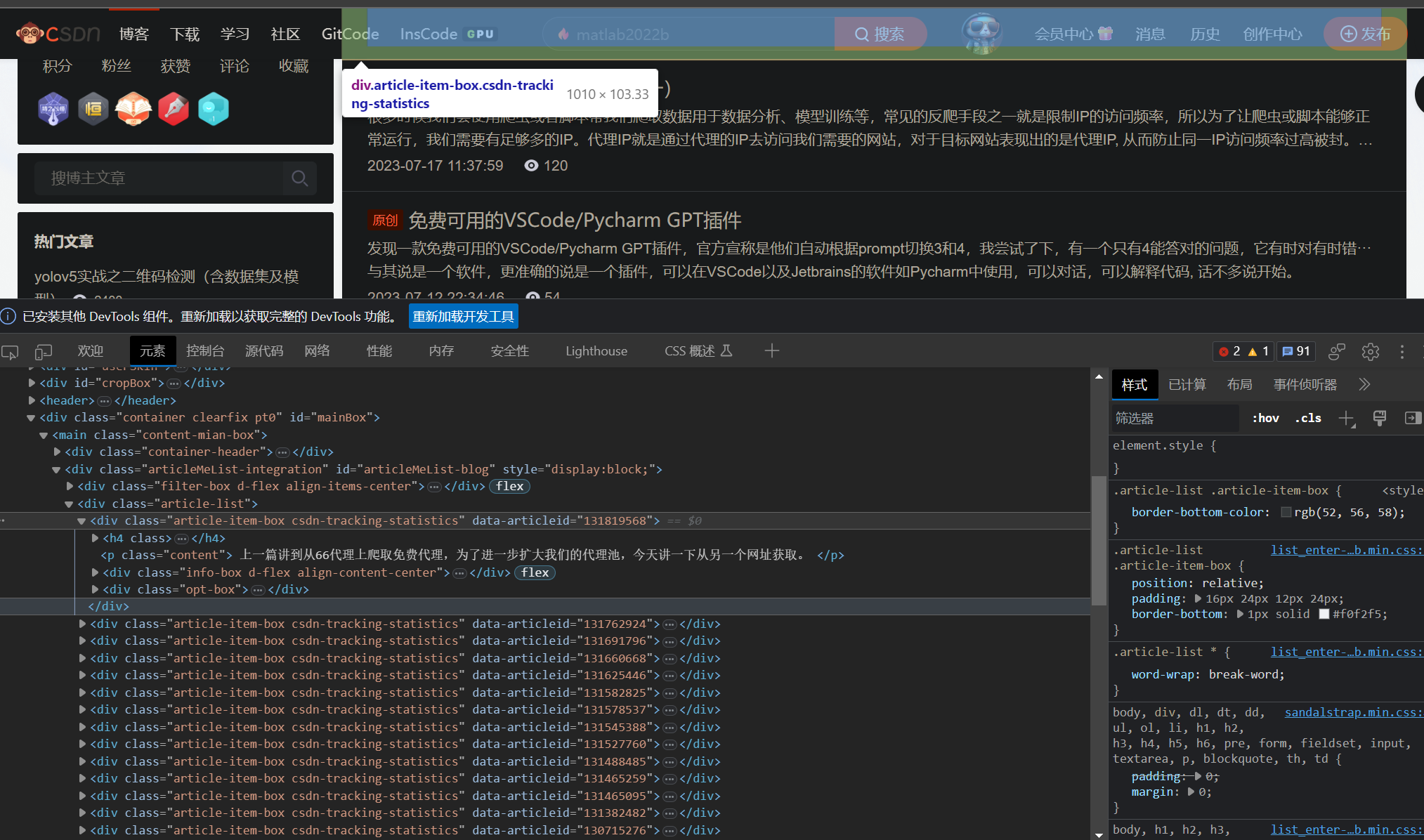
通过分析页面的html,我们可以知道文章都在html的“article-item-box”中,因此我们可以通过在返回的html中查找“article-item-box”来得到所有的文章链接。
html_text = requests.get(url=url, headers=type(self).headers).text
arts = []
soup = BeautifulSoup(html_text, 'html.parser')
articles = soup.findAll('div', {"class": "article-item-box"})
for art in articles:
tag_a = art.find_next('a') # 搜索a标签
url = tag_a.attrs['href'] # 文章链接
read_num = int((art.find_next('span', {'class': 'read-num'}).text)) # 文章阅读数量
title = tag_a.text.replace('\n', '') # 文章标题
arts.append({
'title': title,
'url': url,
'read_num': read_num
})
通过代理访问CSDN文章
proxy = self.local_proxy.get_one_proxy()
blog = self.csdn_blog.get_one_blog()
blog_url = blog['url']
headers = {
'User-Agent': self._refresh_headers()
}
proxies = {
k:v for k, v in proxy.items() if k !="unusable_cnt"
}
r = requests.get(blog_url, headers=headers, proxies=proxies, timeout=5)
if r.status_code != 200:
raise Exception('status_code is not 200')
通过设置requests接口的proxies参数,即可以代理的方式访问CSDN的博客。为了更像一个真正的浏览器,我们还要经常切换User-Agent,也就是浏览器的头。
进阶
User-Agent
The Latest and Most Common User Agents List (Updated Weekly)
我们可以从这个网站下载User-Agent列表,每次访问时从中随机一个。
代理池管理
前面只是从代理网站爬取了代理,为了有效管理,我们可以在这些代理基础上,进一步开发代理池的持久化功能,比如当有代理增加或者删除时,立即保存到本地;也可以将代理保存到redis, 实时更新,要获取代理时,也从redis中获取。简单起见,这里以保存到本地json为例:
class ProxyPool:
lock = Lock()
def __init__(self):
self.proxy_file = "proxy.json"
self.proxies = {}
self.load_proxies()
def _dump_proxies(self):
with self.lock:
with open(self.proxy_file, "w") as f:
json.dump(self.proxies, f)
def load_proxies(self):
if not os.path.exists(self.proxy_file):
return
with open(self.proxy_file, "r") as f:
self.proxies = json.load(f)
def set_proxies(self, proxies):
self.proxies.update(proxies)
self._dump_proxies()
def get_one_proxy(self):
if len(self.proxies) == 0:
return None
proxy = random.choice(list(self.proxies.keys()))
return json.loads(proxy)
def get_unusable_cnt(self, proxy):
proxy = json.dumps(proxy)
if proxy not in self.proxies:
return 0
return self.proxies[proxy]
def remove_proxy(self, proxy):
proxy = json.dumps(proxy)
if proxy not in self.proxies:
return
self.proxies.pop(proxy)
self._dump_proxies()
def update_proxy_unusable_cnt(self, proxy, cnt=0):
proxy = json.dumps(proxy)
if proxy not in self.proxies:
return
self.proxies[proxy] = cnt
self._dump_proxies()
定时爬取最新的代理和文章列表
可以借助apscheduler建立2个定时任务,免去自己手动实现定时任务:
from apscheduler.schedulers.blocking import BlockingScheduler
self.scheduler = BlockingScheduler()
self.scheduler.add_job(self._refresh_proxy_and_blog, 'interval', hours=24, next_run_time=datetime.now())
self.scheduler.add_job(self.read_jobs, 'interval', hours=24,next_run_time=datetime.now())
完整代码:
面包多:https://mbd.pub/o/bread/ZJuam5lx
Python爬虫实战之提高CSDN访问量的更多相关文章
- Python爬虫实战——反爬策略之模拟登录【CSDN】
在<Python爬虫实战-- Request对象之header伪装策略>中,我们就已经讲到:=="在header当中,我们经常会添加两个参数--cookie 和 User-Age ...
- 路飞学城—Python爬虫实战密训班 第三章
路飞学城—Python爬虫实战密训班 第三章 一.scrapy-redis插件实现简单分布式爬虫 scrapy-redis插件用于将scrapy和redis结合实现简单分布式爬虫: - 定义调度器 - ...
- 路飞学城—Python爬虫实战密训班 第二章
路飞学城—Python爬虫实战密训班 第二章 一.Selenium基础 Selenium是一个第三方模块,可以完全模拟用户在浏览器上操作(相当于在浏览器上点点点). 1.安装 - pip instal ...
- 【图文详解】python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识,(没看的先去看!!)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap sho ...
- Python爬虫实战(4):豆瓣小组话题数据采集—动态网页
1, 引言 注释:上一篇<Python爬虫实战(3):安居客房产经纪人信息采集>,访问的网页是静态网页,有朋友模仿那个实战来采集动态加载豆瓣小组的网页,结果不成功.本篇是针对动态网页的数据 ...
- Python爬虫实战(2):爬取京东商品列表
1,引言 在上一篇<Python爬虫实战:爬取Drupal论坛帖子列表>,爬取了一个用Drupal做的论坛,是静态页面,抓取比较容易,即使直接解析html源文件都可以抓取到需要的内容.相反 ...
- Python爬虫实战四之抓取淘宝MM照片
原文:Python爬虫实战四之抓取淘宝MM照片其实还有好多,大家可以看 Python爬虫学习系列教程 福利啊福利,本次为大家带来的项目是抓取淘宝MM照片并保存起来,大家有没有很激动呢? 本篇目标 1. ...
- Python爬虫实战---抓取图书馆借阅信息
Python爬虫实战---抓取图书馆借阅信息 原创作品,引用请表明出处:Python爬虫实战---抓取图书馆借阅信息 前段时间在图书馆借了很多书,借得多了就容易忘记每本书的应还日期,老是担心自己会违约 ...
- Python爬虫实战七之计算大学本学期绩点
大家好,本次为大家带来的项目是计算大学本学期绩点.首先说明的是,博主来自山东大学,有属于个人的学生成绩管理系统,需要学号密码才可以登录,不过可能广大读者没有这个学号密码,不能实际进行操作,所以最主要的 ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
随机推荐
- ES6教程笔记
ES介绍 什么是ES ES全称 EcmaScript 是一种脚本语言的规范 Javascript为ES的实现 Ecma 是一个组织 Ecma组织 为什么要学习ES6? ES6的版本变动内容最多,具有里 ...
- 即时通讯系统为什么选择GaussDB(for Redis)?
摘要:如果你需要一款稳定可靠的高性能企业级KV数据库,不妨试试GaussDB(for Redis). 每当网络上爆出热点新闻,混迹于各个社交媒体的小伙伴们全都开启了讨论模式.一条消息的产生是如何在群聊 ...
- CISP_PTE学习
一.http协议的基础知识(请求方法.状态码.响应头信息.协议的URL) 1.请求方法: (1) http1.0请求包含 head.get.post (2)http1.1请求包含head.get.po ...
- Marior去除边距和迭代内容矫正用于自然文档矫正
一.简要介绍 本文简要介绍了论文" Marior: Margin Removal and Iterative Content Rectification for Document Dewar ...
- 深度学习04-(Tensorflow简介、图与会话、张量基本操作、Tensorboard可视化、综合案例:线性回归)
深度学习04-Tensorflow 深度学习04-(Tensorflow) Tensorflow概述 Tensorflow简介 什么是Tensorflow Tensorflow的特点 Tensorfl ...
- Python 使用类和实例
使用类和实例 直接修改实例的属性 编写方法以特定的方式进行修改 # 案例: class Car(): '''一次模拟汽车的简单尝试''' def __init__(self,make,model,ye ...
- Java的构造方法和标准JavaBean
构造方法 一.构造方法概述: 构造方法也叫做构造器,构造函数,平时叫做构造方法 二.构造方法的作用: 创建对象的时候,由虚拟机自动调用,给成员变量进行初始化(赋值) 三.构造方法的格式: public ...
- 2022-01-22:力扣411,最短独占单词缩写。 给一个字符串数组strs和一个目标字符串target。target的简写不能跟strs打架。 strs是[“abcdefg“,“ccc“],tar
2022-01-22:力扣411,最短独占单词缩写. 给一个字符串数组strs和一个目标字符串target.target的简写不能跟strs打架. strs是["abcdefg", ...
- 2021-09-10:给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那两个整数,并返回它们的数组下标。你可以假设每种输入只会对应一个答案
2021-09-10:给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那两个整数,并返回它们的数组下标.你可以假设每种输入只会对应一个答案, ...
- 虚拟机linux系统密码忘记了该怎么办?
当你的linux系统的密码忘记了该怎么办? 首先不要慌,重启电脑,开机的时候 出现这个页面的时候点击e然后出现这个页面 把里面的ro修改为 rw 修改为rw之后在这一行语句的最后面输入enforcin ...