Flume-自定义 Source
Source 是负责接收数据到 Flume Agent 的组件。
Source 组件可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。
官方提供的 source 类型已经很多,但是有时候并不能满足实际开发当中的需求,此时我们就需要根据实际需求自定义某些 source。
官方也提供了自定义 source 的接口:https://flume.apache.org/FlumeDeveloperGuide.html#source
根据官方说明自定义 Source 需要继承 AbstractSource 类并实现 Configurable 和 PollableSource 接口。
实现相应方法:
getBackOffSleepIncrement(); getMaxBackOffSleepInterval(); // 初始化 context(读取配置文件内容)
configure(Context context); // 获取数据封装成 event 并写入 channel,这个方法将被循环调用
process();
使用场景:读取 MySQL 数据或者其他文件系统。
这里使用 flume 接收数据,并给每条数据添加前缀,输出到控制台。前缀可从 flume 配置文件中配置。
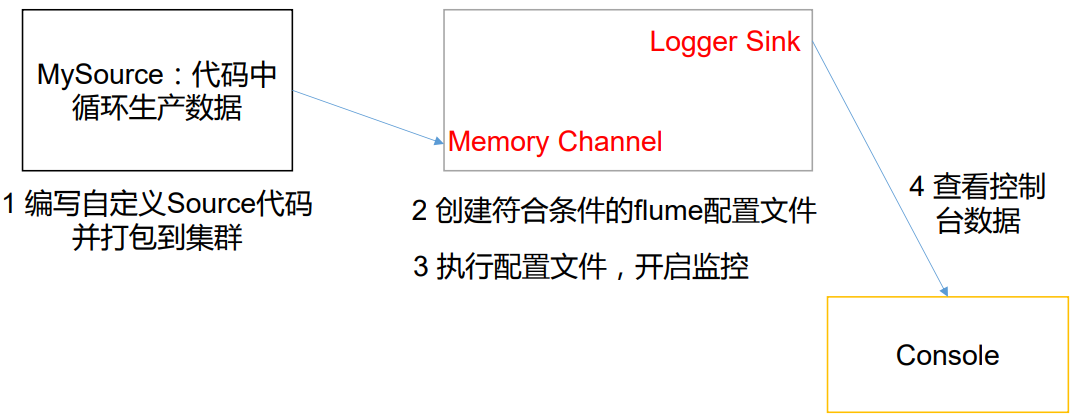
一、创建自定义 Source
1.添加 pom 依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com</groupId>
<artifactId>flume</artifactId>
<version>1.0-SNAPSHOT</version> <dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
</dependency>
</dependencies> <build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>
2.编写自定义的 Source 类
package source; import org.apache.flume.Context;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.PollableSource;
import org.apache.flume.conf.Configurable;
import org.apache.flume.event.SimpleEvent;
import org.apache.flume.source.AbstractSource; import java.util.HashMap; public class MySource extends AbstractSource implements Configurable, PollableSource { // 定义配置文件将来要读取的字段
private Long delay;
private String field; // 初始化配置信息
@Override
public void configure(Context context) {
delay = context.getLong("delay");
field = context.getString("field", "Hello!");
} @Override
public Status process() throws EventDeliveryException {
try {
// 创建事件头信息
HashMap<String, String> hearderMap = new HashMap<>();
// 创建事件
SimpleEvent event = new SimpleEvent();
// 循环封装事件
for (int i = 0; i < 5; i++) {
// 给事件设置头信息
event.setHeaders(hearderMap);
// 给事件设置内容
event.setBody((field + i).getBytes());
// 将事件写入 channel
getChannelProcessor().processEvent(event);
Thread.sleep(delay);
}
} catch (Exception e) {
e.printStackTrace();
return Status.BACKOFF;
}
return Status.READY;
} @Override
public long getBackOffSleepIncrement() {
return 0;
} @Override
public long getMaxBackOffSleepInterval() {
return 0;
}
}
二、打包测试
1.打包上传
参考:https://www.cnblogs.com/jhxxb/p/11582804.html
2.编写 flume 配置文件
mysource.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = source.MySource
# 代码中要获取的配置信息
a1.sources.r1.delay = 1000
# a1.sources.r1.field = jhxxb # Describe the sink
a1.sinks.k1.type = logger # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
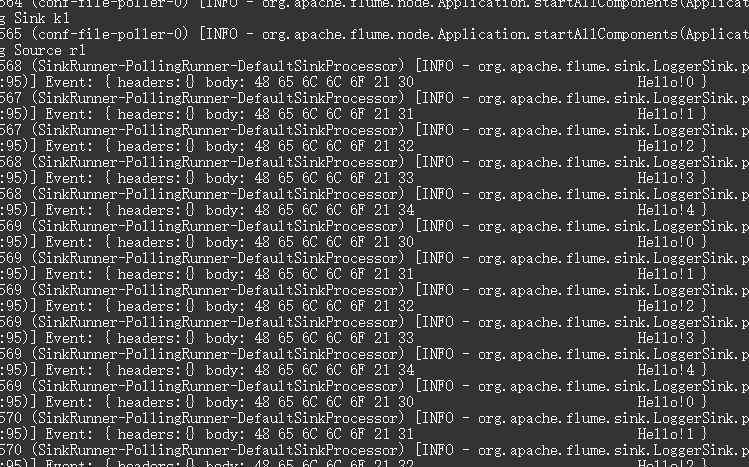
启动
cd /opt/apache-flume-1.9.-bin
bin/flume-ng agent --conf conf/ --name a1 --conf-file /tmp/flume-job/source/mysource.conf -Dflume.root.logger=INFO,console
Flume-自定义 Source的更多相关文章
- Flume自定义Source、Sink和Interceptor(简单功能实现)
1.Event event是flume传输的最小对象,从source获取数据后会先封装成event,然后将event发送到channel,sink从channel拿event消费. event由头he ...
- flume自定义Source(taildirSource),自定义Sink(数据库),开发完整步骤
一.flume简单了解推荐网站(简介包括简单案例部署): http://www.aboutyun.com/thread-8917-1-1.html 二.我的需求是实现从ftp目录下采集数据,目录下文件 ...
- flume http source示例讲解
一.介绍 flume自带的Http Source可以通过Http Post接收事件. 场景:对于有些应用程序环境,它可能不能部署Flume SDK及其依赖项,或客户端代码倾向于通过HTTP而不是Flu ...
- Flume自定义拦截器(Interceptors)或自带拦截器时的一些经验技巧总结(图文详解)
不多说,直接上干货! 一.自定义拦截器类型必须是:类全名$内部类名,其实就是内部类名称 如:zhouls.bigdata.MySearchAndReplaceInterceptor$Builder 二 ...
- FLUME KAFKA SOURCE 和 SINK 使用同一个 TOPIC
FLUME KAFKA SOURCE 和 SINK 使用同一个 TOPIC 最近做了一个事情,过滤下kakfa中的数据后,做这个就用到了flume,直接使用flume source 和 flume s ...
- 一次flume exec source采集日志到kafka因为单条日志数据非常大同步失败的踩坑带来的思考
本次遇到的问题描述,日志采集同步时,当单条日志(日志文件中一行日志)超过2M大小,数据无法采集同步到kafka,分析后,共踩到如下几个坑.1.flume采集时,通过shell+EXEC(tail -F ...
- 把Flume的Source设置为 Spooling directory source
把Flume的Source设置为 Spooling directory source,在设定的目录下放置需要读取的文件,一些文件在读取过程中会报错. 文件格式和报错如下: 实验一 读取汉子和“:&qu ...
- Flume:source和sink
Flume – 初识flume.source和sink 目录基本概念常用源 Source常用sink 基本概念 什么叫flume? 分布式,可靠的大量日志收集.聚合和移动工具. events ...
- Flink 自定义source和sink,获取kafka的key,输出指定key
--------20190905更新------- 沙雕了,可以用 JSONKeyValueDeserializationSchema,接收ObjectNode的数据,如果有key,会放在Objec ...
- Flume 自定义拦截器 多行读取日志+截断
前言: Flume百度定义如下: Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,F ...
随机推荐
- 关于cubic-bezier 贝塞尔曲线的简单了解
在animation和transition两个属性中,cubic-bezier是控制变化的速度曲线,主要是生成速度曲线的函数 规定用法是: cubic-bezier(<x1>,<y1 ...
- vscode 使用ESLint 自动检查,保存时自动格式化
1:全局安装eslint `npm install -g eslint`2: 打开vscode 点击 “文件”----->“首选项”---->“设置”,在右侧“用户设置/settings. ...
- Forms Process (FRMWEB) Consumes 100% of CPU in Oracle Applications R12 (文档 ID 745711.1)
https://support.oracle.com/epmos/faces/DocumentDisplay?_afrLoop=283767243216583&id=745711.1& ...
- CentOS 安装hping3工具及安装遇到的错误及解决方法
hping是用于生成和解析TCPIP协议数据包的开源工具.创作者是Salvatore Sanfilippo.目前最新版是hping3,支持使用tcl脚本自动化地调用其API.hping是安全审计.防火 ...
- pythoth 中常用的魔法方法
Python魔法方法(magic method),顾名思义,魔法总是带有一些神奇色彩,就跟魔术似的.它也是有自己的规律,在这里或者说规则更合适一些. 魔法方法有一个非常鲜明的特征,就是总是被双下划线所 ...
- webSocket的场景应用
应用场景 服务器更新 前端页面也进行局部刷新,更新服务器端返回的信息 什么是webSocket? 它的最大特点就是,服务器可以主动向客户端推送信息,客户端也可以主动向服务器发送信息,是真正的双向平等对 ...
- java 常用算法和一些题目
选择排序,复杂度O(n²) package com.example.demo; import org.junit.Test; /** * 选择排序 * @author zhzh.yin * */ pu ...
- 如何比较js 浮点数
浮点数的定义,非整数的Number类型无法用 ==(===也不行) 来比较,这就是为什么在JavaScript中,0.1+0.2不能=0.3: console.log( 0.1 + 0.2 == 0. ...
- redis 订阅&发布(转载)
https://segmentfault.com/a/1190000016898228?utm_source=coffeephp.com 方法一: redis_helper.py: 封装发布订阅方法 ...
- express框架初步
express框架初步使用 var exp = require('express'); var ejs = require('ejs'); var app = new exp(); app.set(& ...