3 基于梯度的攻击——MIM
MIM攻击原论文地址——https://arxiv.org/pdf/1710.06081.pdf
1.MIM攻击的原理
MIM攻击全称是 Momentum Iterative Method,其实这也是一种类似于PGD的基于梯度的迭代攻击算法。它的本质就是,在进行迭代的时候,每一轮的扰动不仅与当前的梯度方向有关,还与之前算出来的梯度方向相关。其中的衰减因子就是用来调节相关度的,decay_factor在(0,1)之间,decay_factor越小,迭代轮数靠前算出来的梯度对当前的梯度方向影响越小。由于之前的梯度对后面的迭代也有影响,迭代的方向不会跑偏,总体的大方向是对的。
为了加速梯度下降,通过累积损失函数的梯度方向上的矢量,从而(1)稳定更新(2)有助于通过 narrow valleys, small humps and poor local minima or maxima.(大致意思就是,可以有效避免局部最优)

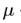 是decay_factor, 另外,在原论文中,每一次迭代对x的导数是直接算的1-范数,然后求平均,但在各个算法库以及论文实现的补充中,并没有求平均,估计这个对结果影响不太大。
是decay_factor, 另外,在原论文中,每一次迭代对x的导数是直接算的1-范数,然后求平均,但在各个算法库以及论文实现的补充中,并没有求平均,估计这个对结果影响不太大。
2.代码实现
class MomentumIterativeAttack(Attack, LabelMixin):
"""
The L-inf projected gradient descent attack (Dong et al. 2017).
The attack performs nb_iter steps of size eps_iter, while always staying
within eps from the initial point. The optimization is performed with
momentum.
Paper: https://arxiv.org/pdf/1710.06081.pdf
""" def __init__(
self, predict, loss_fn=None, eps=0.3, nb_iter=40, decay_factor=1.,
eps_iter=0.01, clip_min=0., clip_max=1., targeted=False):
"""
Create an instance of the MomentumIterativeAttack. :param predict: forward pass function.
:param loss_fn: loss function.
:param eps: maximum distortion.
:param nb_iter: number of iterations
:param decay_factor: momentum decay factor.
:param eps_iter: attack step size.
:param clip_min: mininum value per input dimension.
:param clip_max: maximum value per input dimension.
:param targeted: if the attack is targeted.
"""
super(MomentumIterativeAttack, self).__init__(
predict, loss_fn, clip_min, clip_max)
self.eps = eps
self.nb_iter = nb_iter
self.decay_factor = decay_factor
self.eps_iter = eps_iter
self.targeted = targeted
if self.loss_fn is None:
self.loss_fn = nn.CrossEntropyLoss(reduction="sum") def perturb(self, x, y=None):
"""
Given examples (x, y), returns their adversarial counterparts with
an attack length of eps. :param x: input tensor.
:param y: label tensor.
- if None and self.targeted=False, compute y as predicted
labels.
- if self.targeted=True, then y must be the targeted labels.
:return: tensor containing perturbed inputs.
"""
x, y = self._verify_and_process_inputs(x, y) delta = torch.zeros_like(x)
g = torch.zeros_like(x) delta = nn.Parameter(delta) for i in range(self.nb_iter): if delta.grad is not None:
delta.grad.detach_()
delta.grad.zero_() imgadv = x + delta
outputs = self.predict(imgadv)
loss = self.loss_fn(outputs, y)
if self.targeted:
loss = -loss
loss.backward() g = self.decay_factor * g + normalize_by_pnorm(
delta.grad.data, p=1)
# according to the paper it should be .sum(), but in their
# implementations (both cleverhans and the link from the paper)
# it is .mean(), but actually it shouldn't matter delta.data += self.eps_iter * torch.sign(g)
# delta.data += self.eps / self.nb_iter * torch.sign(g) delta.data = clamp(
delta.data, min=-self.eps, max=self.eps)
delta.data = clamp(
x + delta.data, min=self.clip_min, max=self.clip_max) - x rval = x + delta.data
return rval
有人认为,advertorch中在迭代过程中,应该是对imgadv求导,而不是对delta求导,foolbox和cleverhans的实现都是对每一轮的对抗样本求导。
3 基于梯度的攻击——MIM的更多相关文章
- 4.基于梯度的攻击——MIM
MIM攻击原论文地址——https://arxiv.org/pdf/1710.06081.pdf 1.MIM攻击的原理 MIM攻击全称是 Momentum Iterative Method,其实这也是 ...
- 2.基于梯度的攻击——FGSM
FGSM原论文地址:https://arxiv.org/abs/1412.6572 1.FGSM的原理 FGSM的全称是Fast Gradient Sign Method(快速梯度下降法),在白盒环境 ...
- 1 基于梯度的攻击——FGSM
FGSM原论文地址:https://arxiv.org/abs/1412.6572 1.FGSM的原理 FGSM的全称是Fast Gradient Sign Method(快速梯度下降法),在白盒环境 ...
- 3.基于梯度的攻击——PGD
PGD攻击原论文地址——https://arxiv.org/pdf/1706.06083.pdf 1.PGD攻击的原理 PGD(Project Gradient Descent)攻击是一种迭代攻击,可 ...
- 2 基于梯度的攻击——PGD
PGD攻击原论文地址——https://arxiv.org/pdf/1706.06083.pdf 1.PGD攻击的原理 PGD(Project Gradient Descent)攻击是一种迭代攻击,可 ...
- 5.基于优化的攻击——CW
CW攻击原论文地址——https://arxiv.org/pdf/1608.04644.pdf 1.CW攻击的原理 CW攻击是一种基于优化的攻击,攻击的名称是两个作者的首字母.首先还是贴出攻击算法的公 ...
- 基于梯度场和Hessian特征值分别获得图像的方向场
一.我们想要求的方向场的定义为: 对于任意一点(x,y),该点的方向可以定义为其所在脊线(或谷线)位置的切线方向与水平轴之间的夹角: 将一条直线顺时针或逆时针旋转 180°,直线的方向保持不变. 因 ...
- 4 基于优化的攻击——CW
CW攻击原论文地址——https://arxiv.org/pdf/1608.04644.pdf 1.CW攻击的原理 CW攻击是一种基于优化的攻击,攻击的名称是两个作者的首字母.首先还是贴出攻击算法的公 ...
- C / C ++ 基于梯度下降法的线性回归法(适用于机器学习)
写在前面的话: 在第一学期做项目的时候用到过相应的知识,觉得挺有趣的,就记录整理了下来,基于C/C++语言 原贴地址:https://helloacm.com/cc-linear-regression ...
随机推荐
- SpringBoot AOP介绍
说起spring,我们知道其最核心的两个功能就是AOP(面向切面)和IOC(控制反转),这边文章来总结一下SpringBoot如何整合使用AOP. 一.示例应用场景:对所有的web请求做切面来记录日志 ...
- [人物存档]【AI少女】【捏脸数据】活泼少女
AISChaF_20191028022750507.png
- vue的简单使用
1.使用vue 下载vue.js: 下载地址:https://vuejs.org/js/vue.min.js:打开链接后是一大堆js代码:ctrl+s保存即可: 新建一个htm ...
- Parallels Desktop 安装centos7
配置网卡: vi /etc/sysconfig/network-scripts/ifcfg-eth0 修改BOOTPROTO=dhcp,ONBOOT=yes. 保存后重启网卡 service netw ...
- MySQL基础入门之常用命令使用
如何启动MySql服务 /etc/init.d/mysqld start service mysqld start Centos .x 系统 sysctl start mysqld 检测端口是否运行 ...
- AtCoder AGC004E Salvage Robots (DP)
题目链接 https://atcoder.jp/contests/agc004/tasks/agc004_e 题解 本题的难度不在于想到大体思路,而在于如何把代码写对.. 首先我们可以不让机器人动,让 ...
- Vue_(组件通讯)父子组件简单关系
Vue组件 传送门 在Vue的组件内也可以定义组件,这种关系成为父子组件的关系 如果在一个Vue实例中定义了component-a,然后在component-a中定义了component-b,那他们的 ...
- LeetCode 6. Z字形变换(ZigZag Conversion)
题目描述 将字符串 "PAYPALISHIRING" 以Z字形排列成给定的行数: P A H N A P L S I I G Y I R 之后从左往右,逐行读取字符:"P ...
- better-scroll 的介绍
配置项中的 probeType 属性,是number,当值为 0 ,不会实时监听 scroll 事件,设置为 2 - 3 ,可以实时监听 scroll 事件 pullUpload 选项,设置为 fal ...
- Spring AOP增强(Advice)
Sring AOP通过PointCut来指定在那些类的那些方法上织入横切逻辑,通过Advice来指定在切点上具体做什么事情.如方法前做什么,方法后做什么,抛出异常做什么. Spring中有两种方式定义 ...