Tensorflow 从文件中载入训练数据
本节包含:
- 用纯文本文件准备训练数据
- 加载文件中的训练数据
一、用纯文本文件准备训练数据
1.数据的数字化
比如,“是” —— “1”,“否” —— “0”
“优”,“中”,“差” —— 1 2 3 或者 3 2 1
2.训练数据的格式
在文本文件中,一般每行存放一条数据,一条数据中可以有多个数据项(有时称为“字段”),数据项中间一般使用英文逗号”,“ 进行分割
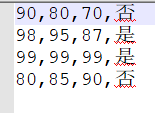
90,80,70,0
98,95,87,1
99,99,99,1
80,85,90,0
这就是三好学生评选结果问题的一组数据,每行代表一位学生的成绩和最后的评选结果
注意: 文本文件一定要以UTF-8 的编码形式来保存,逗号一定是英文的逗号,尽量不要有空格等空白字符
3.使用CSV格式文件辅助处理数据
CSV是逗号分隔值的简称,这种格式的文件中每行都是一个个用逗号分隔开的内容项
CSV格式的文件 是纯文本文件中的一种,也是 Excel 支持的文件格式,所以可以用 Excel 来处理数据
我使用的是 Notepad++ ,一款代码编辑软件

将刚才的数据保存为 .CSV 文件后,可以用Excel 打开,编辑修改
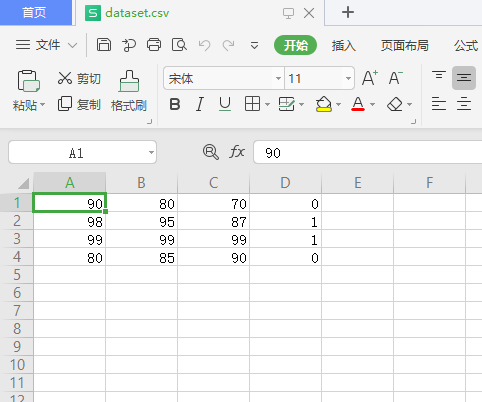
二、加载文件中的训练数据
1.加载函数
numpy包 中的 loadtxt 函数,其中第一个参数是 要读取的文件名和文件所在的目录,第二个参数 delimiter 表示数据项之间用什么字符分隔,第三个参数表示读取的数据类型
import numpy as np
wholeData = np.loadtxt(r"C:\Users\DELL\Desktop\abc.txt",delimiter=",",dtype=np.float32)
print(wholeData)
[[90. 80. 70. 0.]
[98. 95. 87. 1.]
[99. 99. 99. 1.]
[80. 85. 90. 0.]]
原因分析:在windows系统当中读取文件路径可以使用\,但是在python字符串中\有转义的含义,如\t可代表TAB,\n代表换行,所以我们需要采取一些方式使得\不被解读为转义字符。
2、替换为双反斜杠
3、替换为正斜杠
2.读取时舍弃非数字列
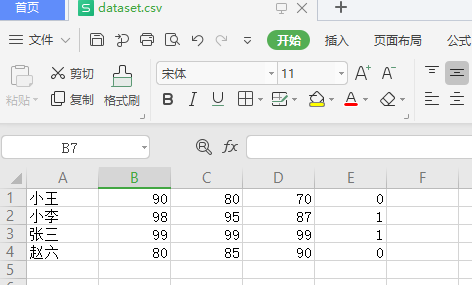
import pandas as pd
import numpy as np
fileData = pd.read_csv(r'C:\Users\DELL\Desktop\dataset.csv',dtype=np.float32,header=None,usecols=(1,2,3,4))
wholeData = fileData.as_matrix() print(wholeData)
[[90. 80. 70. 0.]
[98. 95. 87. 1.]
[99. 99. 99. 1.]
[80. 85. 90. 0.]]
可见,在读取时已经舍弃了非数字列

3.非数字列与数字列的转换
import pandas as pd
import numpy as np
fileData = pd.read_csv(r'C:\Users\DELL\Desktop\dataset.csv',dtype=np.float32,header=None,converters={(3):lambda s:1.0 if s == "是" else 0.0})
wholeData = fileData.as_matrix() print(wholeData)
[[90. 80. 70. 0.]
[98. 95. 87. 1.]
[99. 99. 99. 1.]
[80. 85. 90. 0.]]

4.行数据的拆分 及 喂给训练过程
由于从文件中读取的数据是一个第二维有4项的二维数组,而我们原来的数据有两个,一个是分数,每行3项,另一个是评选结果,只有一个数,所以,需要将新的数据格式 拆分后再 喂给神经网络
import tensorflow as tf
import numpy as np
import pandas as pd fileData = pd.read_csv(r'C:\Users\DELL\Desktop\abc.txt', dtype=np.float32, header=None)
wholeData = fileData.as_matrix() #将文件中的数据转换成二维数组 wholeData
rowCount = int(wholeData.size / wholeData[0].size) #获取一共多少条数据
# wholeData.size 获得的是 数据的所有项的个数,本题是 4 * 4 = 16
# wholeData[0].size 获得的是第一行的项数,本题是 4
# 所以 行数 = 16 / 4 = 4 goodCount = 0
# 用一个循环统计 符合三号学生条件的数据条数,并放入 goodCount 中
for i in range(rowCount):
if wholeData[i][0] * 0.6 + wholeData[i][1] * 0.3 + wholeData[i][2] * 0.1 >= 95:
goodCount = goodCount + 1 print("wholeData = %s" % wholeData)
print("行数rowCount = %d" % rowCount)
print("三好数goodCount = %d" % goodCount) # 定义模型
x = tf.placeholder(dtype=tf.float32)
yTrain = tf.placeholder(dtype=tf.float32) w = tf.Variable(tf.zeros([3]), dtype=tf.float32)
b = tf.Variable(80, dtype=tf.float32) wn = tf.nn.softmax(w) n1 = wn * x n2 = tf.reduce_sum(n1) - b y = tf.nn.sigmoid(n2) loss = tf.abs(yTrain - y) optimizer = tf.train.RMSPropOptimizer(0.1) train = optimizer.minimize(loss) sess = tf.Session()
sess.run(tf.global_variables_initializer()) for i in range(2):
for j in range(rowCount):
result = sess.run([train, x, yTrain, wn, b, n2, y, loss], feed_dict={x: wholeData[j][0:3], yTrain: wholeData[j][3]})
print(result)

wholeData = [[90. 80. 70. 0.]
[98. 95. 87. 1.]
[99. 99. 99. 1.]
[80. 85. 90. 0.]]
行数rowCount = 4
三好数goodCount = 2
[None, array([90., 80., 70.], dtype=float32), array(0., dtype=float32), array([0.33333334, 0.33333334, 0.33333334], dtype=float32), 80.02626, 0.0, 0.5, 0.5]
[None, array([98., 95., 87.], dtype=float32), array(1., dtype=float32), array([0.30555207, 0.33253884, 0.3619091 ], dtype=float32), 80.02626, 12.995125, 0.99999774, 2.2649765e-06]
[None, array([99., 99., 99.], dtype=float32), array(1., dtype=float32), array([0.3055522 , 0.33253887, 0.3619089 ], dtype=float32), 80.02626, 18.97374, 1.0, 0.0]
[None, array([80., 85., 90.], dtype=float32), array(0., dtype=float32), array([0.3055522 , 0.33253887, 0.3619089 ], dtype=float32), 80.02689, 5.2555237, 0.9948085, 0.9948085]
[None, array([90., 80., 70.], dtype=float32), array(0., dtype=float32), array([0.30587256, 0.33257753, 0.36154988], dtype=float32), 80.05657, -0.58367157, 0.3580882, 0.3580882]
[None, array([98., 95., 87.], dtype=float32), array(1., dtype=float32), array([0.27762243, 0.32822776, 0.39414987], dtype=float32), 80.05657, 12.6231, 0.99999666, 3.33786e-06]
[None, array([99., 99., 99.], dtype=float32), array(1., dtype=float32), array([0.27762258, 0.32822785, 0.39414948], dtype=float32), 80.05657, 18.94342, 1.0, 0.0]
[None, array([80., 85., 90.], dtype=float32), array(0., dtype=float32), array([0.27762258, 0.32822785, 0.39414948], dtype=float32), 80.05717, 5.5260544, 0.9960341, 0.9960341]
Tensorflow 从文件中载入训练数据的更多相关文章
- 从视频文件中读入数据-->将数据转换为灰度图-->对图像做canny边缘检测-->将这三个结构显示在一个图像中
//从视频文件中读入数据-->将数据转换为灰度图-->对图像做canny边缘检测-->将这三个结构显示在一个图像中 //作者:sandy //时间:2015-10-10 #inclu ...
- 代码实现将键盘录入的数据拷贝到当前项目下的text.txt文件中,键盘录入数据当遇到quit时就退出
package com.looaderman.test; import java.io.FileNotFoundException; import java.io.FileOutputStream; ...
- java读取url中json文件中的json数据
有时候需要远程从其他接口中获取json数据,如果遇到返回的json数据是一个文件而不直接是数据,那么可以通过以下方法进行读取: /** * 从数据接口获取到数据 * @return * @throws ...
- Jmeter实现从csv文件中随机读取数据
一.需求 参数放在csv文件中,文件格式如下,需求每次从文件中随机读取一行数据. 二.步骤 1.在csv文件中新增加一列,pl 2.新增一个配置原件-随机数,设置如下: 50是文件数据的行数 3.新增 ...
- python数据可视化-matplotlib入门(6)-从文件中加载数据
前几篇都是手动录入或随机函数产生的数据.实际有许多类型的文件,以及许多方法,用它们从文件中提取数据来图形化. 比如之前python基础(12)介绍打开文件的方式,可直接读取文件中的数据,扩大了我们的数 ...
- vue-cli项目 build后请求本地static文件中的 json数据,路径不对,报错404处理方法
vue-cli 项目 build 出错点: 1,build生成dist 放在tomcat上 报错,不显示内容 解决办法: config>index.js===>assetsPublic ...
- python解析pcap文件中的http数据包
使用scapy.scapy_http就可以方便的对pcap包中的http数据包进行解析 scapy_http可以在https://github.com/invernizzi/scapy-http下载, ...
- easyui datagrid 加载静态文件中的json数据
本文主要介绍easyui datagrid 怎么加载静态文件里的json数据,开发环境vs2012, 一.json文件所处的位置 二.json文件内容 {"total":28,&q ...
- 从文件中读取数组数据————Java
自己总结一下Java文件的读取类似数组数据的方法,自己可以快速查看. 一.规整化数据: 对于数组数据是一一对应的情况 ArrayList<String> arrayList = new A ...
随机推荐
- 《Python基础教程》第二章:列表和元组(1)
列表可以修改,元组则不能 字符串就是一个由字符组成的序列 使用分片操作来访问一定范围内的元素,分片操作的实现需要提供两个索引作为边界,第一个索引的元素是包含在分片内的,而第二个不包含在分片内. 如果分 ...
- JavaScript16进制颜色值和rgb的转换
//十六进制颜色值域RGB格式颜色值之间的相互转换//十六进制颜色值的正则表达式 var reg = /^#([0-9a-fA-f]{3}|[0-9a-fA-f]{6})$/; /*RGB颜色转换为1 ...
- mybatis 注解@Results、@Result、@ResultMap、@One的使用
- TensorFlow使用记录 (五): 激活函数和初始化方式
In general ELU > leaky ReLU(and its variants) > ReLU > tanh > logistic. If you care a lo ...
- Binary Protocol
A. Binary Protocol 这道题要唯一注意的一点就是数字0的表示--0个"1"来表达,所以字符串"100"所表示的数字就是100 附代码: // C ...
- 自定义MessageConverter--消息转换器
我们在进行发送消息的时候,正常情况下消息体为二进制的数据方式进行传输,如果希望内部帮我们进行转换,或者指定自定义的转换器,就需要用到MessageConverter 自定义常用转换器:MessageC ...
- 第一章 大体知道java语法1----------能写java小算法
很多人开始学习java时,都是抱着诸如<Thinking in java>.<疯狂java>等书籍,从前到后慢慢翻看,不管其内容重要与否,也不关心自己以后能否使用到.我的建议是 ...
- Vue_(基础)Vue中的事件
Vue.js中文文档 传送门 Vue@事件绑定 v-show:通过切换元素的display CSS属性实现显示隐藏: v-if:根据表达式的真假实现显示隐藏,如果隐藏,它绑定的元素都会销毁,显示的时候 ...
- Jmeter设置成中文
首次启动Jmeter为中文 选择后即变为中文
- 转:VMware 15 安装 MAC OS 10.13 原版(详细图文教程)
-----------------转载------------------------ 原文:https://blog.csdn.net/qq_40147863/article/details/847 ...