XML基础介绍【二】
XML基础介绍【二】
1、schema约束
dtd语法: <!ELEMENT 元素名称 约束>
schema符合xml的语法,xml语句。一个xml中可以有多个schema,多个schema使用名称空间区分(类似于java包名)
dtd里面有PCDATA类型,但是在schema里面可以支持更多的数据类型
比如 年龄 只能是整数,在schema可以直接定义一个整数类型
schema语法更加复杂,schema目前不能替代dtd
2、schema的快速入门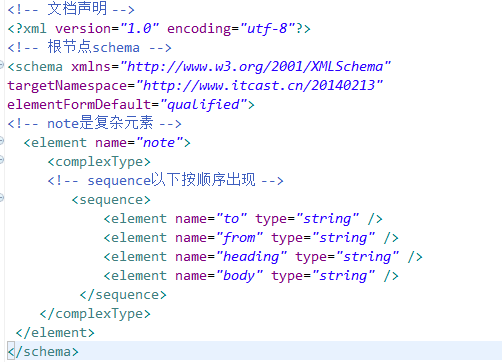
创建一个schema文件 后缀名是 .xsd
根节点 <schema>
在schema文件里面
属性 xmlns="http://www.w3.org/2001/XMLSchema"
- 表示当前xml文件是一个约束文件
targetNamespace="http://www.boom.cn/2015112401"
- 使用schema约束文件,直接通过这个地址引入约束文件
elementFormDefault="qualified"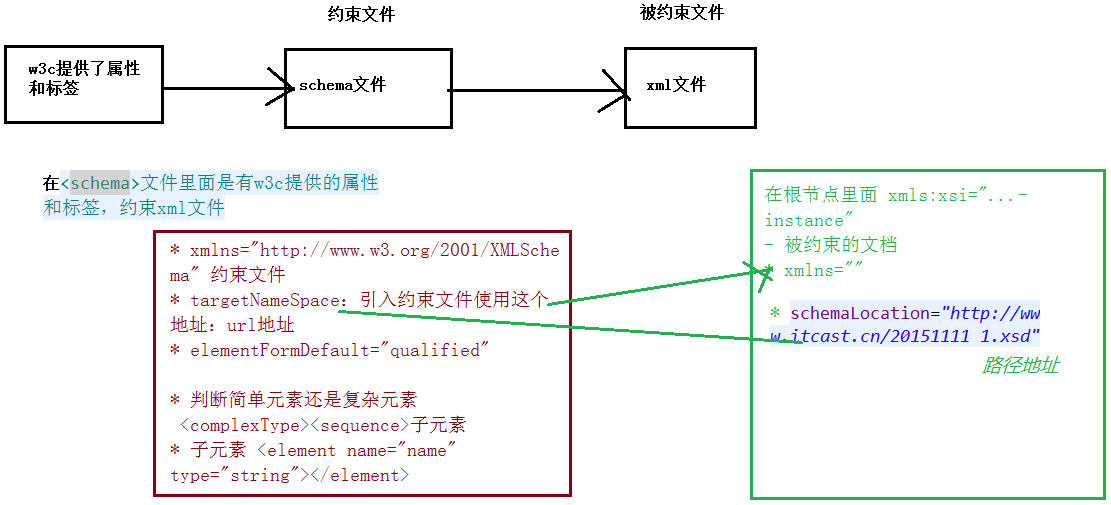
步骤:
(1)看xml中有多少个元素
<element>
(2)看简单元素和复杂元素
如果复杂元素
<complexType>
<sequence>
子元素
</sequence>
</complexType>
(3)简单元素,写在复杂元素的
<element name="person">
<complexType>
<sequence>
<element name="name" type="string"></element>
<element name="age" type="int"></element>
</sequence>
</complexType>
</element>
(4)在被约束文件里面引入约束文件
<person xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.boom.cn/2015112401"
xsi:schemaLocation="http://www.boom.cn/2015112401 1.xsd">
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
-- 表示xml是一个被约束文件
xmlns="http://www.boom.cn/2015112401"
-- 是约束文档里面 targetNamespace
xsi:schemaLocation="http://www.boom.cn/2015112401 1.xsd">
-- targetNamespace 空格 约束文档的地址路径
<sequence>:表示元素的出现的顺序
<all>: 元素只能出现一次
<choice>:元素只能出现其中的一个
maxOccurs="unbounded": 表示元素的出现的次数 unbounded:无限次数
<any></any>:表示任意元素
可以约束属性
写在复杂元素里面
写在 </complexType>之前
----------------------------
<attribute name="id1" type="int" use="required"></attribute>
- name: 属性名称
- type:属性类型 int stirng
- use:属性是否必须出现 required
复杂的schema约束
<company xmlns = "http://www.example.org/company"
xmlns:dept="http://www.example.org/department"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.example.org/company company.xsd http://www.example.org/department department.xsd" >
<employee age="30">
<!-- 部门名称 -->
<dept:name>100</dept:name>
想要引入部门的约束文件里面的name,使用部门的别名 detp:元素名称
<!-- 员工名称 -->
<name>王晓晓</name>
</employee>
e-code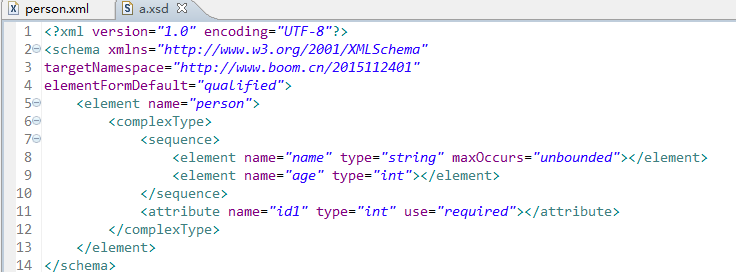

3、sax解析的原理(********)
解析xml有两种技术 dom 和sax
根据xml的层级结构在内存中分配一个树形结构,把xml中标签,属性,文本封装成对象
sax方式:事件驱动,边读边解析。在javax.xml.parsers包里面
SAXParser
此类的实例可以从 SAXParserFactory.newSAXParser() 方法获得
- parse(File f, DefaultHandler dh)
两个参数
a. 第一个参数:xml的路径
b. 事件处理器
SAXParserFactory
实例 newInstance() 方法得到
画图分析一下sax执行过程
* 当解析到开始标签时候,自动执行startElement方法
* 当解析到文本时候,自动执行characters方法
* 当解析到结束标签时候,自动执行endElement方法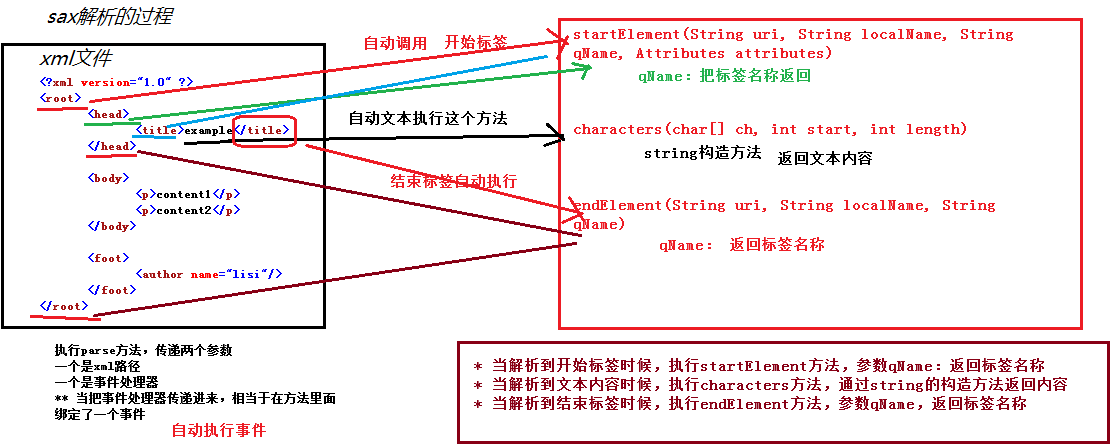
4、使用jaxp的sax方式解析xml(**会写***)
sax方式不能实现增删改操作,只能做查询操作
1、打印出整个文档
步骤:
1、创建解析器工厂
2、创建解析器
3、执行Parser()方法,第一个参数xml路径,第二个参数是 事件处理器
a. 创建一个类,继承事件处理器的类,
b. 重写里面的三个方法
4、创建一个类,继承事件处理器的类
5、重写里面的三个方法
2、获取到所有的name元素的值
定义一个成员变量 flag= false
判断开始方法是否是name元素,如果是name元素,把flag值设置成true
如果flag值是true,在characters方法里面打印内容
当执行到结束方法时候,把flag值设置成false
3、获取第一个name元素的值
定义一个成员变量 idx=1
在结束方法时候,idx+1 idx++
想要打印出第一个name元素的值,
- 在characters方法里面判断,
- 判断flag=true 并且 idx==1,在打印内容
e-code
package boom.jaxpsax; import javax.swing.text.DefaultCaret;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory; import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler; public class TestSax { /**
* 打印不同元素的a.xml文档
* @param args
* @throws SAXException
* @throws ParserConfigurationException
*/
public static void main(String[] args) throws Exception {
// 1、创建解析器工厂
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
// 2、创建解析器
SAXParser saxParser = saxParserFactory.newSAXParser();
// 3、执行Parser()方法
saxParser.parse("src/a.xml", new MyDefault3());
// 4、创建一个类,继承事件处理器的类
// 5、重写里面的三个方法 } }
//创建一个类,继承事件处理器的类
//1、打印整个a.xml文档
class MyDefault1 extends DefaultHandler{
// 重写startElement、characters、endElement的三个方法
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
System.out.print("<"+qName+">");
} @Override
public void characters(char[] ch, int start, int length)
throws SAXException {
System.out.print(new String(ch,start,length));
} @Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
System.out.print("</"+qName+">");
} } //2、获取所有的name元素值
class MyDefault2 extends DefaultHandler{
// 定义一个成员变量
boolean flag = false;
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
// 进行判断qName是否为name
if ("name".equals(qName)){
flag = true;
}
} @Override
public void characters(char[] ch, int start, int length)
throws SAXException {
// 当flag值为true时,表示解析到name值
if (flag == true){
System.out.println(new String(ch,start,length));
}
} @Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
// flag设置成false,表示name元素结束
if ("name".equals(qName)){
flag = false;
}
} } //3、获取第一个的name元素值
class MyDefault3 extends DefaultHandler{
// 定义一个成员变量
boolean flag = false;
int idx =1;
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
// 进行判断qName是否为name
if ("name".equals(qName)){
flag = true;
}
} @Override
public void characters(char[] ch, int start, int length)
throws SAXException {
// 当flag值为true时,表示解析到name值
// 索引是1
if (flag == true && idx == 1){
System.out.println(new String(ch,start,length));
}
} @Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
// flag设置成false,表示name元素结束
if ("name".equals(qName)){
flag = false;
idx++;
}
} }
5、使用dom4j解析xml
dom4j,是一个组织,针对xml解析,提供解析器 dom4j
dom4j不是javase的一部分,想要使用第一步需要怎么做?
导入dom4j提供jar包
-- 创建一个文件夹 lib
-- 复制jar包到lib下面,
-- 右键点击jar包,build path -- add to build path
-- 看到jar包,变成奶瓶样子,表示导入成功
得到document
SAXReader reader = new SAXReader();
Document document = reader.read(url);
document的父接口是Node
如果在document里面找不到想要的方法,到Node里面去找
document里面的方法 getRootElement() :获取根节点 返回的是Element
Element也是一个接口,父接口是Node
- Element和Node里面方法
getParent():获取父节点
addElement:添加标签
element(qname)
表示获取标签下面的第一个子标签
qname:标签的名称
elements(qname)
获取标签下面是这个名称的所有子标签(一层)
qname:标签名称
elements()
获取标签下面的所有一层子标签
6、使用dom4j查询xml
* 解析是从上到下解析
* 查询所有name元素里面的值
1、创建解析器
2、得到document
3、得到根节点 getRootElement() 返回Element
4、得到所有的p1标签
* elements("p1") 返回list集合
* 遍历list得到每一个p1
5、得到name
* 在p1下面执行 element("name")方法 返回Element
6、得到name里面的值
* getText方法得到值
*查询第一个name元素的值
1、创建解析器
2、得到document
3、得到根节点
4、得到第一个p1元素
* element("p1")方法 返回Element
5、得到p1下面的name元素
* element("name")方法 返回Element
6、得到name元素里面的值
* getText方法
* 获取第二个name元素的值
1、创建解析器
2、得到document
3、得到根节点
4、得到所有的p1
* 返回 list集合
5、遍历得到第二个p1
* 使用list下标得到 get方法,集合的下标从 0 开始,想要得到第二个值,下标写 1
6、得到第二个p1下面的name
* element("name")方法 返回Element
7、得到name的值
* getText方法
7、使用dom4j实现添加操作
* 在第一个p1标签末尾添加一个元素 <sex>nv</sex>
步骤:
1、创建解析器
2、得到document
3、得到根节点
4、获取到第一个p1
* 使用element方法
5、在p1下面添加元素
* 在p1上面直接使用 addElement("标签名称")方法 返回一个Element
6、在添加完成之后的元素下面添加文本
* 在sex上直接使用 setText("文本内容")方法
7、回写xml
* 格式化 OutputFormat,使用 createPrettyPrint方法,表示一个漂亮的格式
* 使用类XMLWriter 直接new 这个类 ,传递两个参数
*** 第一个参数是xml文件路径 new FileOutputStream("路径")
*** 第二个参数是格式化类的值
8、使用dom4j实现在特定位置添加元素
* 在第一个p1下面的age标签之前添加 <school>ahszu.edu.cn</schlool>
步骤:
1、创建解析器
2、得到document
3、得到根节点
4、获取到第一个p1
5、获取p1下面的所有的元素
** elements()方法 返回 list集合
** 使用list里面的方法,在特定位置添加元素
** 首先创建元素 在元素下面创建文本
- 使用DocumentHelper类方法createElement创建标签
- 把文本添加到标签下面 使用 setText("文本内容")方法
** list集合里面的 add(int index, E element)
* - 第一个参数是 位置 下标,从0开始
* - 第二个参数是 要添加的元素
6、回写xml
封装的总结:
** 可以对得到document的操作和 回写xml的操作,封装成方法
** 也可以把传递的文件路径,封装成一个常量
*** 好处:可以提高开发速度,可以提交代码可维护性
- 比如想要修改文件路径(名称),这个时候只需要修改常量的值就可以了,其他代码不需要做任何改变
9、使用dom4j实现修改节点的操作
* 修改第一个p1下面的age元素的值 <age>30</age>
步骤:
1、得到document
2、得到根节点,然后再得到第一个p1元素
3、得到第一个p1下面的age
element("")方法
4、修改值是 300
* * 使用setText("文本内容")方法
5、回写xml
10、使用dom4j实现删除节点的操作
* 删除第一个p1下面的<school></school>元素
步骤:
1、得到document
2、得到根节点
3、得到第一个p标签
4、得到第一个p下面的school元素
5、删除(使用p1删除school)
* 得到school的父节点
- 第一种直接得到p
- 使用方法 getParent方法得到
* 删除操作
- 在p上面执行remove方法删除节点
6、回写xml
11、使用dom4j获取属性的操作
* 获取第一个name里面的属性id1的值
步骤:
1、得到document
2、得到根节点
3、得到第一个p元素
5、得到p标签下层级的name
6、得到name里面的属性值
- name.attributeValue("id1");
- 在name上面执行这个方法,里面的参数是属性名称
e-code【a.xml】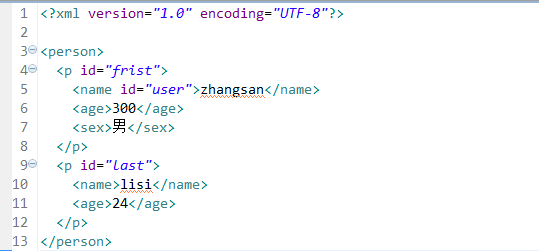
e-code【封装工具类:Dom4jUtils】
package boom.utils; import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter; import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter; public class Dom4jUtils {
public static final String PATH="src/a.xml";
// 返回document
public static Document getDocument(String path){
try {
// 创建解析器
SAXReader reader = new SAXReader();
// 得到document
Document document = reader.read(path);
return document;
} catch (Exception e) {
e.printStackTrace();
}
return null;
} // 回写xml的方法
public static void xmlWriter(String path,Document document){
try {
OutputFormat format = OutputFormat.createPrettyPrint();
XMLWriter xmlWriter = new XMLWriter(new FileOutputStream(path), format);
xmlWriter.write(document);
xmlWriter.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
e-code【dom4j.java】
package boom.dom4j; import java.util.List; import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element; import boom.utils.Dom4jUtils; public class Dom4j { /**
* dom4j常规操作
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception{
/**
* 主函数调用方法
*/
// selectName();
// selectSingle();
// selectSecond();
// addSex();
// addAgeBefore();
// modifyAge();
// delSch();
getValue(); }
/**
*1、查询a.xml中所有name的值
* @throws Exception
*/
public static void selectName() throws Exception{
/*// 1. 创建解析器
SAXReader reader = new SAXReader();
// 2. 得到document
Document document = reader.read("src/a.xml");*/ Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH);
// 3. 得到根节点
Element root = document.getRootElement();
// 4. 得到所有的p1
List<Element> list = root.elements("p");
// 5. 遍历list[增强for循环]
for (Element element : list) {// element是每一个p元素
// 得到p1下面的name元素
Element name = element.element("name");
// 6. 得到name里面的值
String s = name.getText();
System.out.println(s);
} }
/**
*
*2、查询第一个name元素的值
* @throws Exception
*/
public static void selectSingle() throws Exception{
/*// 1. 创建解析器
SAXReader reader = new SAXReader();
// 2. 得到document
Document document = reader.read("src/a.xml");*/ Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH);
// 3. 得到根节点
Element root = document.getRootElement();
// 4. 得到第一个p标签
Element p = root.element("p");
// 5. 得到p1下面的name元素
Element name = p.element("name");
// 6. 得到name元素里面的值
String s= name.getText();
System.out.println(s);
}
/**
*获取第二个name元素的值
* @throws Exception
*/ public static void selectSecond() throws Exception{
/*// 1. 创建解析器
SAXReader reader = new SAXReader();
// 2. 得到document
Document document = reader.read("src/a.xml");*/ Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH);
// 3. 得到根节点
Element root = document.getRootElement();
// 4. 得到所有的p标签
List<Element> list = root.elements("p");
// 5. 得到第二个p标签 list集合下标从0开始
Element p = list.get(1);
// 6. 得到第二个p标签下的name
Element name = p.element("name");
// 7. 得到name元素里面的值
String s = name.getText();
System.out.println(s); }
/**
* 4、在第一个p标签末尾添加一个元素 <sex>nv</sex>
* @throws Exception
*/
public static void addSex() throws Exception{
/*// 1. 创建解析器
SAXReader reader = new SAXReader();
// 2. 得到document
Document document = reader.read("src/a.xml");*/ Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH);
// 3. 得到根节点
Element root = document.getRootElement();
// 4. 得到第一个p标签
Element p = root.element("p");
// 5. 在p标签下直接添加新的标签元素sex
Element sex = p.addElement("sex");
// 6. 直接在sex新创建的元素下添加元素值
sex.addText("男"); /*// 7. 回写xml
OutputFormat format = OutputFormat.createPrettyPrint(); //createPrettyPrint可以有缩进的效果
// OutputFormat format =OutputFormat.createCompactFormat();//createCompactFormat压缩格式[一行显示]
XMLWriter xmlWriter = new XMLWriter(new FileOutputStream("src/a.xml"),format);
xmlWriter.write(document);// 返回document
xmlWriter.close();// 关闭流*/ Dom4jUtils.xmlWriter(Dom4jUtils.PATH, document);
}
/**
* 5、使用dom4j实现在特定位置添加元素
* // 在第一个p下面的age标签之前添加 <school>ahszu.edu.cn</schlool>
* @throws Exception
*/
public static void addAgeBefore() throws Exception{
/*// 1. 创建解析器
SAXReader reader = new SAXReader();
// 2. 得到document
Document document = reader.read("src/a.xml");*/ Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH);
// 3. 得到根节点
Element root = document.getRootElement();
// 4. 得到第一个p标签
Element p = root.element("p");
// 5. 得到p标签下的所有元素
List<Element> list = p.elements();
// 6. 创建一个新标签
Element school = DocumentHelper.createElement("school");
// 7. 在school下面创建文本
school.setText("安徽宿州学院");
// 8. 在特定的位置添加
list.add(1, school); /*// 9. 回写xml
OutputFormat format =OutputFormat.createPrettyPrint(); // createPrettyPrint 可以有缩进的效果
// OutputFormat format =OutputFormat.createCompactFormat();// createCompactFormat压缩格式[一行显示]
XMLWriter xmlWriter = new XMLWriter(new FileOutputStream("src/a.xml"), format);
xmlWriter.write(document);// 返回document
xmlWriter.close();// 关闭流*/
Dom4jUtils.xmlWriter(Dom4jUtils.PATH, document);
}
/**
* 6、使用dom4j实现修改节点的操作
* 修改第一个p下面的age元素的值 <age>30</age>
* @throws Exception
*/
public static void modifyAge() throws Exception{
// 得到document
Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH);
// 得到根节点
Element root = document.getRootElement();
// 得到第一个p标签
Element p = root.element("p");
// 得到p标签下的age标签
Element age = p.element("age");
// 修改age值为30
age.setText("300");
// 回写xml文档
Dom4jUtils.xmlWriter(Dom4jUtils.PATH, document);
}
/**
* 7、使用dom4j实现删除节点的操作
* 删除第一个p1下面的<school></school>元素
* @throws Exception
*/
public static void delSch() throws Exception{
// 得到document
Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH);
// 得到根节点
Element root = document.getRootElement();
// 得到第一个p元素
Element p = root.element("p");
// 得到p标签的school元素
Element school = p.element("school");
// 删除school(通过父节点进行删除)[school.getParent(); // 获取school父节点]
p.remove(school); // 已得到元素,直接在p标签上执行remove方法
// 回写xml文件
Dom4jUtils.xmlWriter(Dom4jUtils.PATH, document);
}
/**
* 8、使用dom4j获取属性的操作
* 获取第一个name里面的属性id的值
* @throws Exception
*/
public static void getValue() throws Exception{
// 得到document
Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH);
// 得到根节点
Element root = document.getRootElement();
// 得到第一个p元素[如果获取p标签下面的name,继续层级获取元素。]
Element p = root.element("p");
// 得到p标签下层级的name
Element name = p.element("name");
// 得到name的属性值
String stringId = name.attributeValue("id");
System.out.println("stringId="+stringId);
} }
12、使用dom4j支持xpath的操作
* 可以直接获取到某个元素
* 第一种形式
/AAA/DDD/BBB: 表示一层一层的,AAA下面 DDD下面的BBB
* 第二种形式
//BBB: 表示和这个名称相同,表示只要名称是BBB,都得到
* 第三种形式
/*: 所有元素
* 第四种形式
** BBB[1]: 表示第一个BBB元素
** BBB[last()]:表示最后一个BBB元素
* 第五种形式
** //BBB[@id]: 表示只要BBB元素上面有id属性,都得到
* 第六种形式
** //BBB[@id='b1'] 表示元素名称是BBB,在BBB上面有id属性,并且id的属性值是b1
13、使用dom4j支持xpath具体操作
默认的情况下,dom4j不支持xpath,如果想要在dom4j里面使用xpath
* 第一步需要,引入支持xpath的jar包,使用 jaxen-1.1-beta-6.jar
** 需要把jar包导入到项目中
* 在dom4j里面提供了两个方法,用来支持xpath
** selectNodes("xpath表达式")
- 获取多个节点
** selectSingleNode("xpath表达式")
- 获取一个节点
使用xpath实现:查询xml中所有name元素的值
* 所有name元素的xpath表示: //name
* 使用selectNodes("//name");
* 代码和步骤:
1、得到document
2、直接使用selectNodes("//name")方法得到所有的name元素
//得到document
Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH);
//使用selectNodes("//name")方法得到所有的name元素
List<Node> list = document.selectNodes("//name");
//遍历list集合
for (Node node : list) {
//node是每一个name元素
//得到name元素里面的值
String s = node.getText();
System.out.println(s);
}
使用xpath实现:获取第一个p1下面的name的值
* //p1[@id1='aaaa']/name
* 使用到 selectSingleNode("//p1[@id1='aaaa']/name")
* 步骤和代码
1、得到document
2、直接使用selectSingleNode方法实现
- xpath : //p[@id1='aaaa']/name
//得到document
Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH);
//直接使用selectSingleNode方法实现
Node name1 = document.selectSingleNode("//p[@id='aaaa']/name"); //name的元素
//得到name里面的值
String s1 = name1.getText();
System.out.println(s1);
e-code【a.xml 和封装工具类:Dom4jUtils】上例子一样
e-code【dom4jXPath.java】
package boom.dom4j; import java.util.List; import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.Node; import boom.utils.Dom4jUtils; public class Dom4jXpath { /**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
test1();
// test2();
}
/**
* 2、查询xml中所有第一个name元素的值
* @throws Exception
*/
public static void test2() throws Exception{
// 得到document
Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH);
// 得到第一个name元素[selectSingleNode方法实现]
Node name = document.selectSingleNode("//p[@id='frist']/name");
String string =name.getText();
System.out.println(string);
}
/**
* 1、查询xml中所有name元素的值
* @throws Exception
*/
public static void test1() throws Exception{
// 得到document
Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH);
// 得到所有name元素[selectNodes("xpath表达式")]
List<Node> list = document.selectNodes("//name");
// 遍历集合 之前for循环实现
for (Node node : list) {
// node是每一个name元素
String getName =node.getText(); // 得到name元素值
System.out.println(getName);
}
} }
XML基础介绍【二】的更多相关文章
- XML基础介绍【一】
XML基础介绍[一] 1.XML简介(Extensible Markup Language)[可扩展标记语言] XML全称为Extensible Markup Language, 意思是可扩展的标记语 ...
- xml基础之二(XML结构【2】)DTD文档模版
xml基础之二(XML结构[2])DTD文档模版 xml 模板 文档结构 我们知道XML主要用于数据的存储和传输,所以无论是自定义还是外部引用DTD模板文档,都是为了突出数据的存储规范.DTD(文档 ...
- xml基础之二(XML结构【1】)
xml基础之二(XML结构[1]) 新建 模板 小书匠 XML结构 XML结构 1.1 元素:被开始标签和结束标签所包裹的内容,(红色部分),蓝色部分也是元素,由于其仅有词语和句子,可细分为文本元素 ...
- Neo4J图库的基础介绍(二)-图库开发应用
JAX-RS是一个用于构建REST资源的Java API,可以使用JAX-RS注解装饰每一个扩展类,从而让服务器处理对应的http请求,附加注解可以用来控制请求和响应的格式,http头和URI模板的格 ...
- python基础介绍二
一.python种类 1.1 Cpython python官方版本,使用c语言实现,运行机制:先编译,py(源码文件)->pyc(字节码文件),最终执行时先将字节码转换成机器码,然后交给cpu执 ...
- Slickflow.NET 开源工作流引擎基础介绍(二) -- 引擎组件和业务模块的交互
集成流程引擎的必要性 业务过程的变化是在BPM系统中常见的现象,企业管理层需要不断优化组织架构,改造业务流程,不可避免地带来了业务流程的变化,企业信息系统就会随之面临重构的可能性.一种直接的方式是改造 ...
- Slickflow.NET 开源工作流引擎基础介绍(二) -- 引擎组件和业务系统的集成
集成流程引擎的必要性 业务过程的变化是在BPM系统中常见的现象,企业管理层需要不断优化组织架构,改造业务流程,不可避免地带来了业务流程的变化,企业信息系统就会随之面临重构的可能性.一种直接的方式是改造 ...
- {Django基础十之Form和ModelForm组件}一 Form介绍 二 Form常用字段和插件 三 From所有内置字段 四 字段校验 五 Hook钩子方法 六 进阶补充 七 ModelForm
Django基础十之Form和ModelForm组件 本节目录 一 Form介绍 二 Form常用字段和插件 三 From所有内置字段 四 字段校验 五 Hook钩子方法 六 进阶补充 七 Model ...
- { MySQL基础数据类型}一 介绍 二 数值类型 三 日期类型 四 字符串类型 五 枚举类型与集合类型
MySQL基础数据类型 阅读目录 一 介绍 二 数值类型 三 日期类型 四 字符串类型 五 枚举类型与集合类型 一 介绍 存储引擎决定了表的类型,而表内存放的数据也要有不同的类型,每种数据类型都有自己 ...
随机推荐
- python连接mysql数据库实例demo(银行管理系统数据库版)
主函数: import adminView import os import pickle from bankFunction import BankFunction import time def ...
- mysql 松散索引与紧凑索引扫描(引入数据结构)
这一篇文章本来应该是放在 mysql 高性能日记中的,并且其优化程度并不高,但考虑到其特殊性和原理(索引结构也在这里稍微讲一下) 一,mysql 索引结构 (B.B+树) 要问到 mysql 的索引用 ...
- Spring IoC的形象化理解
1.IoC(控制反转) 首先想说说IoC(Inversion of Control,控制反转).这是spring的核心,贯穿始终.所谓IoC,对于spring框架来说,就是由spring来负责控制对象 ...
- Linux第三阶段题型测试
1.如何取得/etiantian文件的权限对应的数字内容,如-rw-r--r--为644,要求使用命令取得644或0644这样的数字. 解答: 1)最土的方法:ls -l /etiantian |cu ...
- iView中Tree组件children中动态checked选中后取消勾选再选中无效问题
如题,我有一个Tree组件,动态更新check选中子级列表的时候,取消勾选了再点击选中时复选框样式不是勾选状态,但是数据已经有了. 对此解决方案是:将初始化时Tree组件data数据深拷贝一遍再去判断 ...
- vue中关于checkbox数据绑定v-model指令说明
vue.js为开发者提供了很多便利的指令,其中v-model用于表单的数据绑定很常见, 下面是最常见的例子: <div id='myApp'> <input type="c ...
- # Python 3 & 爬虫一些记录
目录 Python 3 & 爬虫一些记录 交互模式和命令行模式 函数积累 语法积累 列表和元组 输入 交互模式下输入多行 爬虫 HTTP报文请求头User-Agent信息 解析库pyquery ...
- 洛谷P3353 【在你窗外闪耀的星星】
题目真的好甜呢QwQ 冲着这题面也要来做 满分解法:线段树 我们暴力地把所有点建成一颗线段数 接着在从1到maxx里每个长度为 w的区间中执行区间求和 其实单点修改都不需要,可以在输入的时候统计出每个 ...
- 虚拟机(Vmware)安装ubuntu18.04和配置调整(一)
一.虚拟机(Vmware)安装ubuntu18.04 1.下载ubuntu18.04桌面版镜像文件< ubuntu-18.04.3-desktop-amd64.iso> 2.使用VMwar ...
- kubernetes dashboard访问用户添加权限控制
前面我们在kubernetes dashboard 升级之路一文中成功的将Dashboard升级到最新版本了,增加了身份认证功能,之前为了方便增加了一个admin用户,然后授予了cluster-adm ...