Spark学习一:Spark概述
1.1 什么是Spark
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。
一站式管理大数据的所有场景(批处理,流处理,sql)
spark不涉及到数据的存储,只做数据的计算
Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行计算框架,Spark拥有Hadoop MapReduce所具有的优点;
但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
注意:spark框架不能替代Hadoop,只能替代MR,spark的存在完善了Hadoop的生态系统.
Spark是Scala编写,方便快速编程。
学习spark的三个网站
1) http://spark.apache.org/
2) https://databricks.com/spark/about
3) https://github.com/apache/spark
- Apache Spark™ is a fast and general engine for large-scale data processing.
- Apache Spark is an open source cluster computing system that aims to make data analytics fast
- both fast to run and fast to write
目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLib、SparkR等子项目,Spark是基于内存计算的大数据并行计算框架。除了扩展了广泛使用的
MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。Spark 适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理。通过在一个统一的框架下支持这些不同的计算,Spark 使我们可以简单而低耗地把各种处理流程整合在一起。而这样的组合,在实际的数据分析 过程中是很有意义的。不仅如此,Spark 的这种特性还大大减轻了原先需要对各种平台分别管理的负担。
大一统的软件栈,各个组件关系密切并且可以相互调用,这种设计有几个好处:1、软件栈中所有的程序库和高级组件 都可以从下层的改进中获益。2、运行整个软件栈的代价变小了。不需要运 行 5 到 10 套独立的软件系统了,一个机构只需要运行一套软件系统即可。系统的部署、维护、测试、支持等大大缩减。3、能够构建出无缝整合不同处理模型的应用。
Spark的内置项目如下:
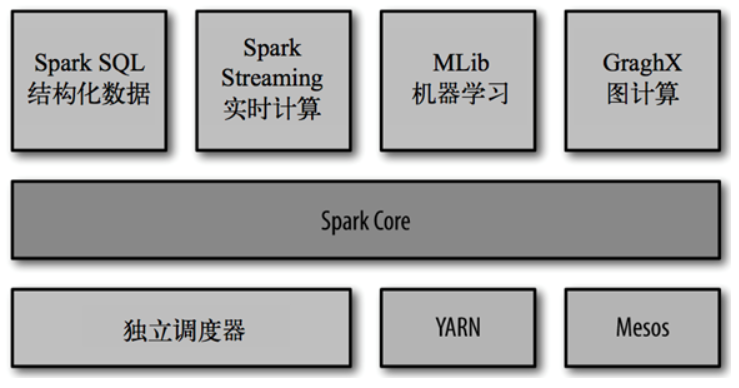
- Spark Core:实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core 中还包含了对弹性分布式数据集(resilient distributed dataset,简称RDD)的 API 定义。
- Spark SQL:是 Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,比如 Hive 表、Parquet 以及 JSON 等。
- Spark Streaming:是 Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。
- Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
- 集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计 算。为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(cluster manager)上运行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自带的一个简易调度器,叫作独立调度器。
1.2 Spark特点
快
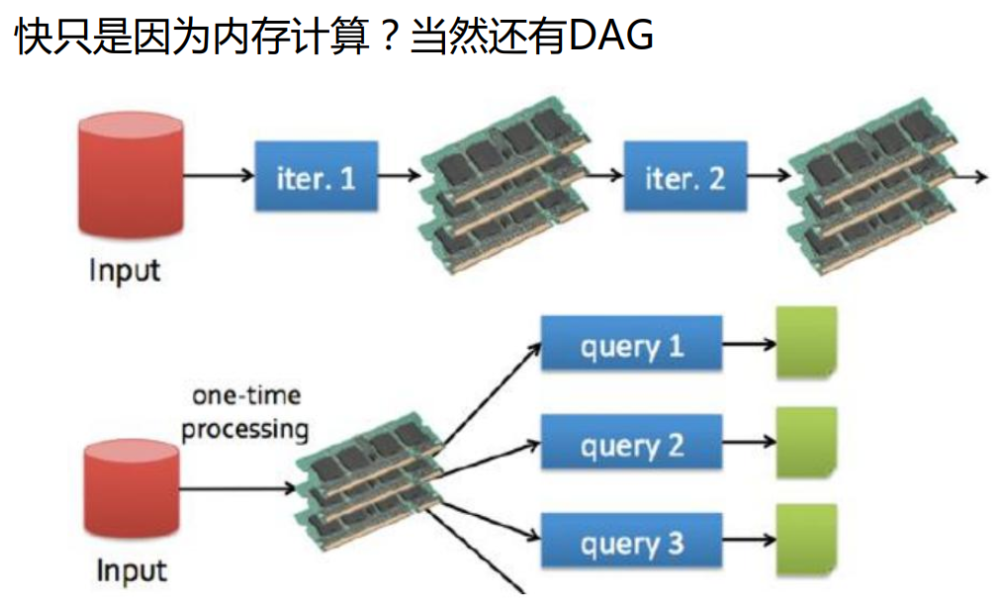
与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。计算的中间结果是存在于内存中的。

易用
Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。

通用
Spark提供了统一的解决方案。Spark可以用于批处理(Spark Core)、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。

兼容性
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。

1.3 Spark的用户和用途
我们大致把Spark的用例分为两类:数据科学应用和数据处理应用。也就对应的有两种人群:数据科学家和工程师。
数据科学任务
主要是数据分析领域,数据科学家要负责分析数据并建模,具备 SQL、统计、预测建模(机器学习)等方面的经验,以及一定的使用 Python、 Matlab 或 R 语言进行编程的能力。
数据处理应用
工程师定义为使用 Spark 开发 生产环境中的数据处理应用的软件开发者,通过对接Spark的API实现对处理的处理和转换等任务。
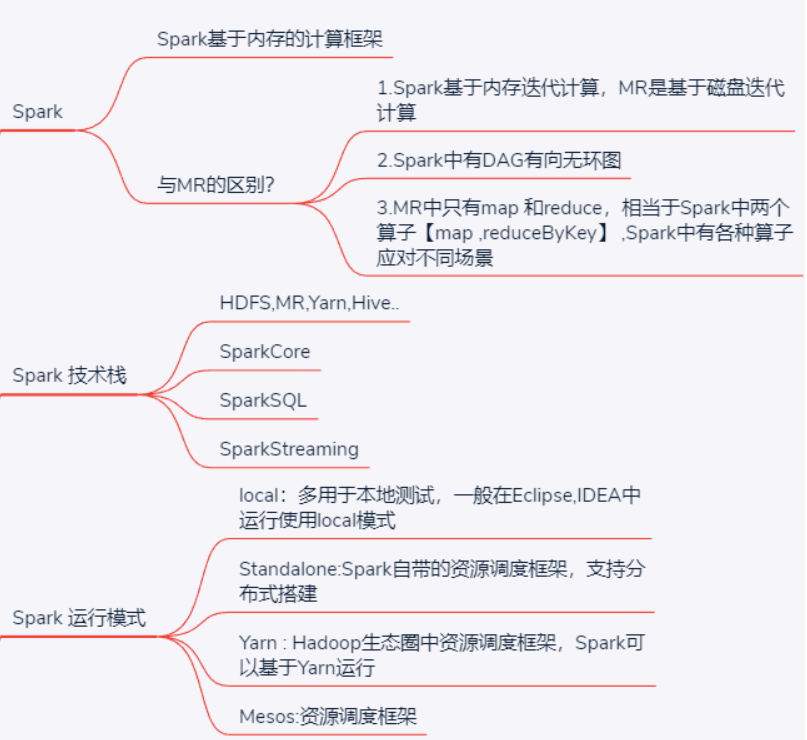
1.4 Spark技术栈
Spark技术栈:HDFS,Hadoop,Hive,MR,Storm,SparkCore,SparkSQL,SparkStreaming
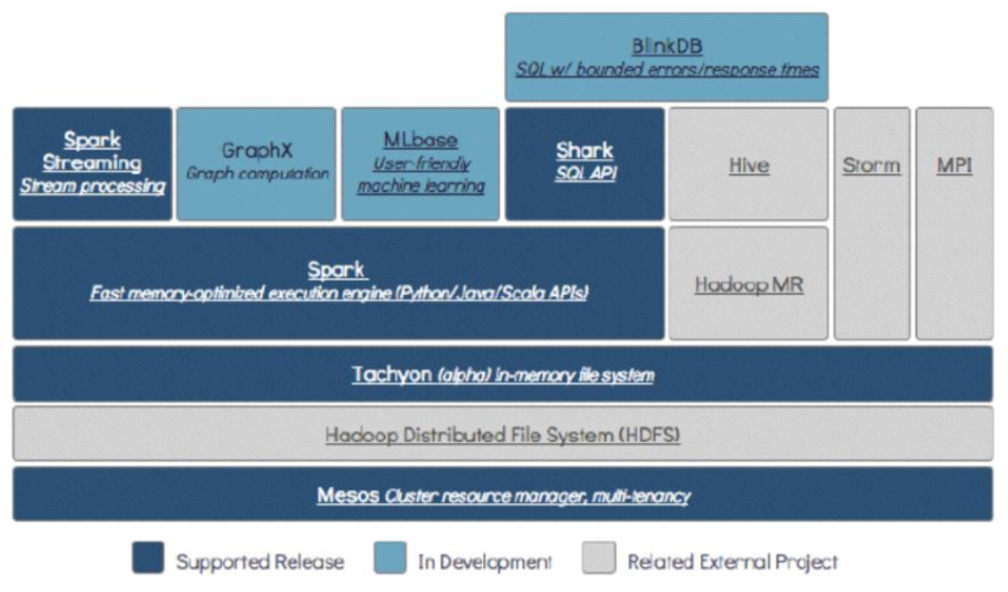
mesos相当于yarn 资源调度框架
tachyon基于内存:内存文件系统
HDFS存储层(基于磁盘存储 block存储策略)
mesos资源调度/任务调度层
Spark SQL : 延迟应该在毫秒级别
Spark core:批处理 延迟度非常高
Spark streaming :流式处理 延迟5s左右
BlinkDB:支持精确度查询的数据库
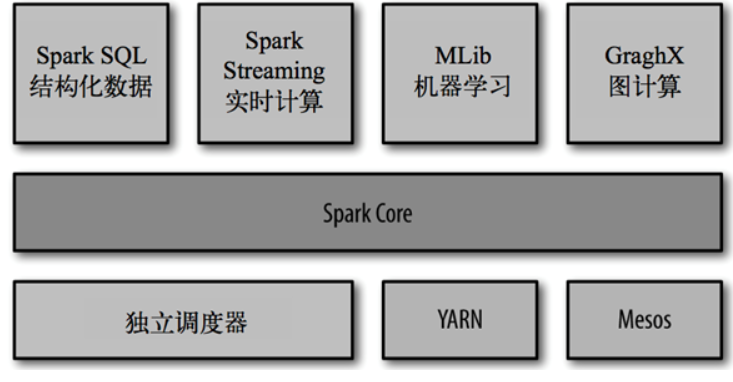
SparkCore处理批数据
SparkSql使用SQL处理分布式数据
SparkStreaming处理流式数据
一站式管理大数据的所有场景(批处理,流处理,sql)
- Spark Core:实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core 中还包含了对弹性分布式数据集(resilient distributed dataset,简称RDD)的 API 定义。
- Spark SQL:是 Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,比 如 Hive 表、Parquet 以及 JSON 等。
- Spark Streaming:是 Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。
- Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
- 集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计 算。为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(cluster manager)上运行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自带的一个简易调度器,叫作独立调度器。
1.5 Spark演变历史
Spark 相比 hadoop历史
- 发展尤为迅速
- Hadoop历史2006~2017 11年时间
- Spark2012~2017 5年时间
Spark是美国加州大学伯克利分校的AMP实验室(主要创始人lester和Matei)开发的通用的大
数据处理框架
• 2009伯克利大学开始编写最初的源代码
• 2010年才开放的源码
• 2012年2月发布了0.6.0版本
• 2013年6月进入了Apache孵化器项目
• 2013年年中Spark的主要成员成立的DataBricks公司
• 2014年2月成为了Apache的顶级项目( 8个月的时间)
• 2014年5月底Spark1.0.0发布
• 2014年9月Spark1.1.0发布
• 2014年12月spark1.2.0发布
• 2015年3月Spark1.3.0发布
• 2015年6月Spark1.4.0发布
• 2015年9月Spark1.5.0发布
• 2016年1月Spark1.6.0发布
• 2016年5月Spark2.0.0预览版发布
• 2016年7月Spark2.0.0正式版发布
• 2016年12月Spark2.1.0正式版发布
• 2017年7月Spark2.2发布
1.6 Spark与MapReduce的区别
都是分布式计算框架,Spark基于内存,MR基于HDFS。Spark处理数据的能力一般是MR的十倍以上,Spark中除了基于内存计算外,还有DAG有向无环图来切分任务的执行先后顺序。
spark不涉及到数据的存储,只做数据的计算
spark与Hadoop MR不同的是,任务的中间结果可以保存到内存中,大大地提高了计算性能.
基于内存存储
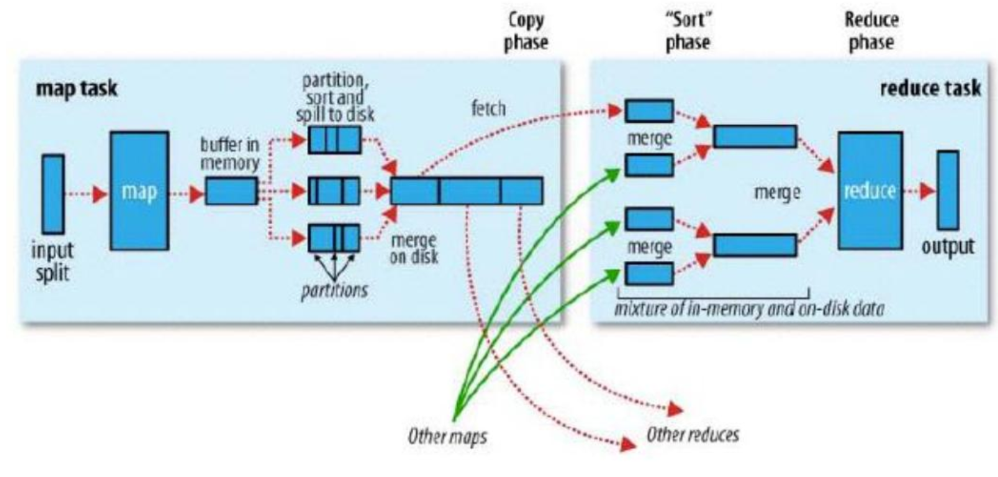
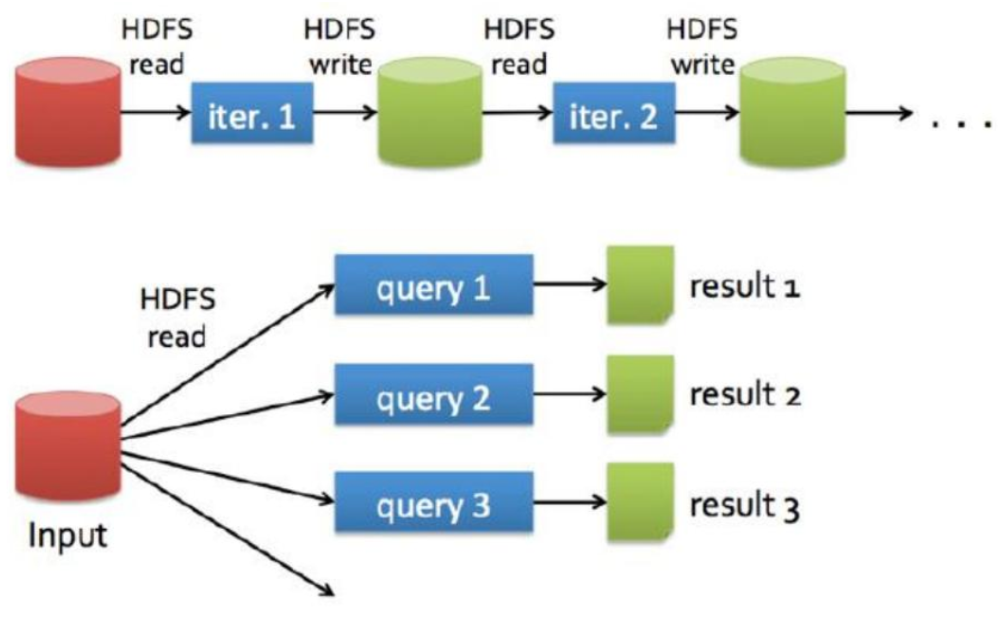
MR作业之间如果有依赖关系的话,每个作业都是从磁盘获取数据,处理完成之后数据落盘。
如:磁盘-MR作业-磁盘-MR作业-磁盘
Spark作业之间如果有依赖关系的话,spark程序处理完成之后可以将数据先存于内存中,不落盘,下一个spark程序就可以直接从内存中获取数据然后进行处理
如:磁盘-spark作业-内存-spark作业-内存-spark作业-磁盘
具体不同点
- Spark相比于MR处理数据是可以基于内存来处理数据的
- spark与Hadoop MR不同的是,任务的中间结果可以保存到内存中,大大地提高了计算性能.
- Spark中有DAG有向无环图来切分任务的执行先后顺序
- Spark存储数据可以指定副本个数(持久化存储),MR默认3个。
- spark中做了很多已有的算子的封装,提供了各种场景的算子,而MR中只有map和reduce 相当于Spark中的map和reduceByKey两个算子
- Spark是粗粒度资源申请,Application执行快
- Spark中shuffle map端自动聚合功能,MR手动设置
- Spark中shuffle ByPass机制有自己灵活的实现
MR
Spark
1.7 Spark API
API就是用这些语言进行编码的时候使用的方法
应用可以通过使用Spark提供的库获得Spark集群的计算能力,这些库都是Scala编写的,但是Spark提供了面向各种语言的API,例如Scala、 Python Java等, 所以可以使用以上语言进行Spark应用开发。
Spark的API主要由两个抽象部件组成: SparkContext和RDD ,应用程序通过这两个部件和Spark进行交互,连接到
Spark-集群并使用相关资源。
SparkContext
是定义在Spark库中的一个类,作为Spark库的入口。 包含应用程序main ()方法的Driver program通过SparkContext对象访问Spark,因为SparkContext对象表示与Spark集群的一 个连接。每个Spark应用都有且只有一个激活的SparkContext类实例,如若需要新的实例,必须先让当前实例失活。(在shell中SparkContext已经自动创建好,就是sc)
RDD基础概念
- 弹性分布式数据集(Resilient Distributed Dataset)
- 并行分布在整个集群中
把指定路径下的文本文件加载到ines这个RDD中,这个lines就是一个RDD, 代表是就是整个文本文件 - RDD是Spark分发数据和计算的基础抽象类
例如: lines.count()
在.count(的函数操作是在RDD数据集上的,而不是对某一具体分片 - 一个RDD是一个不可改变的分布式集合对象
就lines来说,如果我们对其所代表的源文件进行了增删改操作,则相当于生成了一个新的RDD,来存放修改后的数据集 - Spark中所有的计算都是通过RDD的创建、转换,操作完成的
- 一个RDD内部由许多partitions (分片)组成
partitions:
每个分片包括一部分数据, 分片可在集群不同节点上计算
分片是Spark并行处理的单元,Spark顺序的,并行的处理分片
1.8 Spark运行模式(部署模式)
Local
在本地eclipse、IDEA中写spark代码运行程序,一般用于测试
Standalone
spark自带的资源调度框架(可以抛开hdfs,抛开yarn去运行),支持完全分布式集群搭建。Spark可以运行在standalone集群上
Yarn
Hadoop生态圈里面的一个资源调度框架,Spark也是可以基于Yarn来计算的。
要基于Yarn来进行资源调度,必须实现AppalicationMaster接口,Spark实现了这个接口,所以可以基于Yarn。
Mesos
运行在 mesos 资源管理器框架之上,由 mesos 负责资源管理,Spark 负责任务调度和计算,(很少用)
总结
Spark学习一:Spark概述的更多相关文章
- Spark学习之Spark Streaming(9)
Spark学习之Spark Streaming(9) 1. Spark Streaming允许用户使用一套和批处理非常接近的API来编写流式计算应用,这就可以大量重用批处理应用的技术甚至代码. 2. ...
- Spark学习之Spark SQL(8)
Spark学习之Spark SQL(8) 1. Spark用来操作结构化和半结构化数据的接口--Spark SQL. 2. Spark SQL的三大功能 2.1 Spark SQL可以从各种结构化数据 ...
- Spark学习之Spark调优与调试(7)
Spark学习之Spark调优与调试(7) 1. 对Spark进行调优与调试通常需要修改Spark应用运行时配置的选项. 当创建一个SparkContext时就会创建一个SparkConf实例. 2. ...
- Spark学习之Spark Streaming
一.简介 许多应用需要即时处理收到的数据,例如用来实时追踪页面访问统计的应用.训练机器学习模型的应用,还有自动检测异常的应用.Spark Streaming 是 Spark 为这些应用而设计的模型.它 ...
- Spark学习之Spark调优与调试(二)
下面来看看更复杂的情况,比如,当调度器进行流水线执行(pipelining),或把多个 RDD 合并到一个步骤中时.当RDD 不需要混洗数据就可以从父节点计算出来时,调度器就会自动进行流水线执行.上一 ...
- Spark学习之Spark调优与调试(一)
一.使用SparkConf配置Spark 对 Spark 进行性能调优,通常就是修改 Spark 应用的运行时配置选项.Spark 中最主要的配置机制是通过 SparkConf 类对 Spark 进行 ...
- Spark学习之Spark安装
Spark安装 spark运行环境 spark是Scala写的,运行在jvm上,运行环境为java7+ 如果使用Python的API ,需要使用Python2.6+或者Python3.4+ Spark ...
- Spark学习笔记——Spark Streaming
许多应用需要即时处理收到的数据,例如用来实时追踪页面访问统计的应用.训练机器学习模型的应用, 还有自动检测异常的应用.Spark Streaming 是 Spark 为这些应用而设计的模型.它允许用户 ...
- Spark学习笔记--Spark在Windows下的环境搭建
本文主要是讲解Spark在Windows环境是如何搭建的 一.JDK的安装 1.1 下载JDK 首先需要安装JDK,并且将环境变量配置好,如果已经安装了的老司机可以忽略.JDK(全称是JavaTM P ...
随机推荐
- [Luogu] 区间统计Tallest Cow
https://www.luogu.org/problemnew/show/P2879 差分 | 线段树 #include <iostream> #include <cstdio&g ...
- About Grisha N. ( URAL - 2012 )
Problem Grisha N. told his two teammates that he was going to solve all given problems at the subreg ...
- Mapreduce-实现webcount代码
参考博文:https://blog.csdn.net/qq_41035588/article/details/90514824 首先安装一个Hadoop-Eclipse-Plugin 方便来对于hdf ...
- C++常用字符串函数使用整理
strlen(字符数组) 功能:求字符串长度. 说明:该函数的实参可以是字符数组名,也可以是字符串. 使用样例: char s1[80] = "China"; cout<&l ...
- 域渗透-企业应用SAML签名攻击
在项目中遇到SAML企业应用 想留个后门时候一脸懵 随便的整理记录 记录项目中SAML渗透的知识点. 0x01 前置知识 SAML单点登陆 SAML(Security Assertion ...
- debian、ubuntu安装metasploit通用方法
网上有很多方法让去github上下载安装,这方法的确可以但是特别慢,更新也特别慢,这里写下比较快的方法 1.添加kali源 vim /etc/apt/sources.list 在原有源的基础上添加国内 ...
- 网络共享服务—SAMBA服务
SAMBA服务简介 SMB:Server Message Block服务器消息块,IBM发布,最早是DOS网络文件共享协议 Cifs:common internet file system,微软基于S ...
- DELPHI安卓动态权限申请
DELPHI安卓动态权限申请 安卓8.0以前的版本,只需要给静态权限就可以了,但安卓8.0及以后的版本,还需要运行期用代码动态申请权限. 下面以<蓝牙权限>为例,其他权限类似. Delph ...
- 源码编译vi过程中进行配置时报“checking if compile and link flags for Python are sane... no: PYTHON DISABLED”怎么办?
答: 需要安装python开发库(如果不安装这个库,那么在配置时执行./configure --enable-pythoninterp=yes将不会生效,以至于vi的python特性并没有被开启) 如 ...
- Objective-C如何自己实现一个基于数组下标的属性访问模式
在iOS6.0以及OS X10.8之后,Apple引入了一套非正式协议(informal protocol)与Objective-C语法直接绑定.当你实现了这其中的方法之后即可使用数组下标来访问属性元 ...