python中的set集合
当使用爬虫URL保存时,一般会选择set来保存urls,set是集合,集合中的元素不能重复,其次还有交集,并集等集合的功能,
爬虫每次获取的网页中提取网页中的urls,并保存,这就需要利用urls = set()
- 下面展示一下HTML解析器代码
#coding:utf-8
import re
import urlparse
from bs4 import BeautifulSoup
class HtmlParser(object):
def parser(self,page_url,html_cont):
'''
用于解析网页内容抽取URL和数据
:param page_url: 下载页面的URL
:param html_cont: 下载的网页内容
:return:返回URL和数据
'''
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont,'html.parser',from_encoding='utf-8')
new_urls = self._get_new_urls(page_url,soup)
new_data = self._get_new_data(page_url,soup)
return new_urls,new_data
def _get_new_urls(self,page_url,soup):
'''
抽取新的URL集合
:param page_url: 下载页面的URL
:param soup:soup
:return: 返回新的URL集合
'''
new_urls = set()
#抽取符合要求的a标签
#原书代码
# links = soup.find_all('a',href=re.compile(r'/view/\d+\.htm'))
#2017-07-03 更新,原因百度词条的链接形式发生改变
links = soup.find_all('a', href=re.compile(r'/item/.*'))
for link in links:
#提取href属性
new_url = link['href']
#拼接成完整网址
new_full_url = urlparse.urljoin(page_url,new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self,page_url,soup):
'''
抽取有效数据
:param page_url:下载页面的URL
:param soup:
:return:返回有效数据
'''
data={}
data['url']=page_url
title = soup.find('dd',class_='lemmaWgt-lemmaTitle-title').find('h1')
data['title']=title.get_text()
summary = soup.find('div',class_='lemma-summary')
#获取到tag中包含的所有文版内容包括子孙tag中的内容,并将结果作为Unicode字符串返回
data['summary']=summary.get_text()
return data
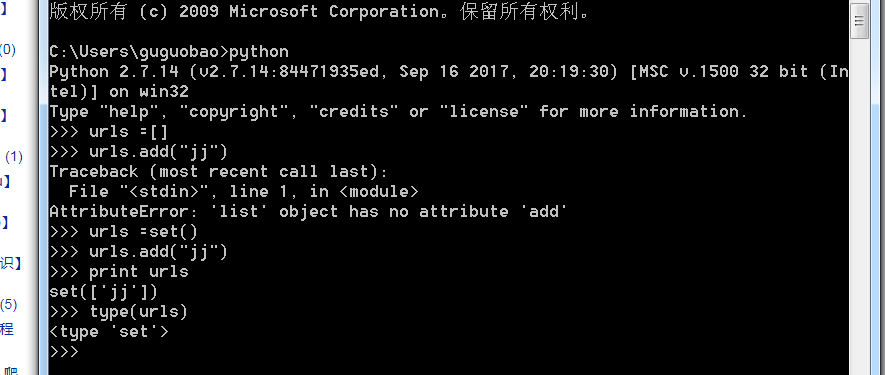
- 其次需要注意的是set可以add,而list不可以
python中的set集合的更多相关文章
- Python中字典和集合
Python中字典和集合 映射类型: 表示一个任意对象的集合,且可以通过另一个几乎是任意键值的集合进行索引 与序列不同,映射是无序的,通过键进行索引 任何不可变对象都可用作字典的键,如字符串.数字.元 ...
- 认识python中的set集合及其用法
python中,集合(set)是一个无序排列,可哈希, 支持集合关系测试,不支持索引和切片操作,没有特定语法格式, 只能通过工厂函数创建.集合里不会出现两个相同的元素, 所以集合常用来对字符串或元组或 ...
- Python中字典和集合的用法
本人开始学习python 希望能够慢慢的记录下去 写下来只是为了害怕自己忘记. python中的字典和其他语言一样 也是key-value的形式 利用空间换时间 可以进行快速的查找 key 是唯一的 ...
- Python中的SET集合操作
python的set和其他语言类似, 是一个无序不重复元素集, 基本功能包括关系测试和消除重复元素. 集合对象还支持union(联合), intersection(交), difference(差)和 ...
- Python中的数据结构 --- 集合(set)
1.集合(set)里面的元素是不可以重复的 s={1,2,3,3,4,3,4} ## 输出之后,没有重复的 2.定义一个空集合 s = set([]) print s,type(s)3 ...
- python中的set集合和深浅拷贝
一.基础数据类型的补充 1.str中的join算法,将列表转换成字符串,并用'_'(或其他) li=['李嘉诚','马化腾','刘嘉玲','黄海峰',] s='_'.join(li) print(s) ...
- Python中字典,集合和元组函数总结
## 字典的所有方法- 内置方法 - 1 cmp(dict1, dict2) 比较两个字典元素. - 2 len(dict) 计算字典元素个数,即键的总数. - 3 str(dict) 输出字典可打印 ...
- 2018.8.3 python中的set集合及深浅拷贝
一.字符串和列表的相互转化 之前写到想把xx类型的数据转化成yy类型的数据,直接yy(xx)就可以了,但是字符串和列表的转化比较特殊,相互之间的转化要通过join()和split()来实现. 例如: ...
- day05 Python中的set集合
集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的.以下是集合最重要的两点: 1.去重,把一个列表变成集合,就自动去重了. 2.关 ...
随机推荐
- BZOJ2144 跳跳棋[建模+LCA]
思维题,思路比较神仙. 个人思路过程:个人只想到了只要中间棋子开始向外跳了,以后就不应该向内跳了,这样很蠢.所以应该要么先向内跳一会,要么直接开始中间的向外跳.不知道怎么处理,就卡住了. 20pts: ...
- MySQL BinLog Server 搭建实战
一.MySQL Binlog server 介绍 MySQL Binlog Server: 它使用 mysqlbinlog 命令以 daemon 进程的方式模拟一个 slave 的 IO 线程与主库连 ...
- 数据管理必看!Kendo UI for jQuery过滤器状态保持
Kendo UI for jQuery最新试用版下载 Kendo UI目前最新提供Kendo UI for jQuery.Kendo UI for Angular.Kendo UI Support f ...
- h5 rem计算
设置html默认font-size: 100px,此时默认的页面的width是750px,然后根据手机大小改变html节点的font-size,从而改变rem的大小,代码如下: <script& ...
- 关于怎么获取kafka指定位置offset消息(转)
1.在kafka中如果不设置消费的信息的话,一个消息只能被一个group.id消费一次,而新加如的group.id则会被“消费管理”记录,并指定从当前记录的消息位置开始向后消费.如果有段时间消费者关闭 ...
- 移动端rem使用及理解
先上代码 window.onload = function(){ getRem(720,100) }; window.onresize = function(){ getRem(720,100) }; ...
- 强制类型转换之String类型
㈠布尔(Boolean)类型 布尔值只有两个,主要用来做逻辑判断 true 表示真 : false 表示假 使用typeof检查一个布尔值时,会返回boolean ㈡Null和Unde ...
- Java线程之Timer
简述 java.util.Timer是一个定时器,用来调度线程在某个时间执行.在初始化Timer时,开启一个线程循环提取TaskQueue任务数组中的任务, 如果任务数组为空,线程等待直到添加任务: ...
- MySQL_(Java)使用JDBC创建用户名和密码校验查询方法
MySQL_(Java)使用JDBC向数据库发起查询请求 传送门 MySQL数据库中的数据,数据库名garysql,表名garytb,数据库中存在的用户表 通过JDBC对MySQL中的数据用户名和密码 ...
- linux shell 之流程控制 if if else while
(1)流程控制不可以为空: (2)if [ $(ps -ef | grep -c "ssh") -gt 1 ]; then echo "true"; fi 条件 ...