Hadoop完全分布式安装配置完整过程
一. 硬件、软件准备
1. 硬件设备
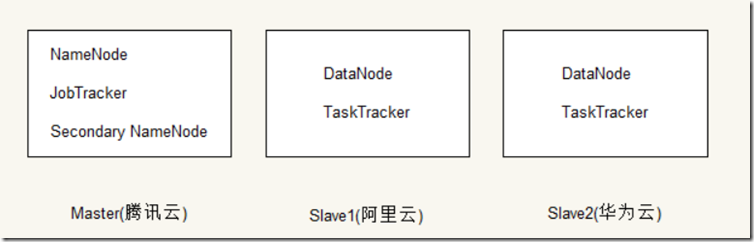
为了方便学习Hadoop,我采用了云服务器来配置Hadoop集群。集群使用三个节点,一个阿里云节点、一个腾讯云节点、一个华为云节点,其中阿里云和腾讯云都是通过使用学生优惠渠道购买了一年的云服务,华为云使用免费7天或15天的云服务器。我决定使用腾讯云节点作为Master节点,阿里云节点和华为云节点作为Slave节点。集群基本结构如下图:
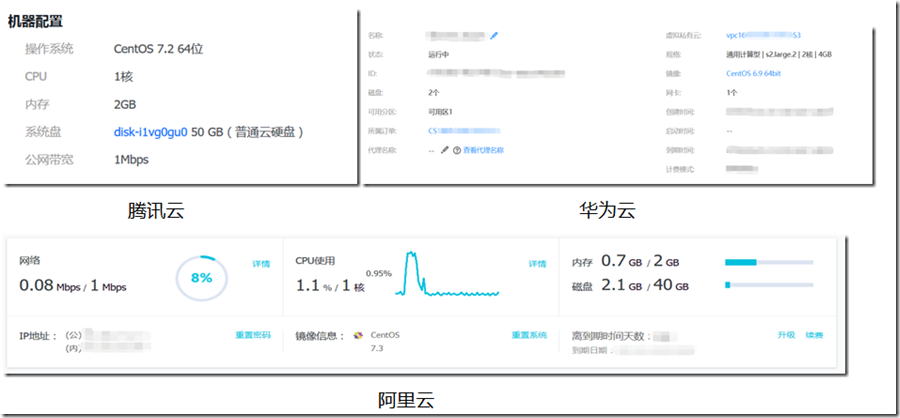
云服务器配置信息如下:
集群网络环境:

分别在每台机器上创建了用户hadoop,并且全部禁用了防火墙。
2. 软件
由于Hadoop需要JVM环境,所以需要下载JDK。需要的软件清单如下图所示。

二、环境搭建
1. JAVA安装
- 解压
我们下载软件jdk-8u61-linux-x64.tar.gz放在了 /home/install-package 下。先在 /home 下创建了java目录,并将jdk压缩文件解压到该目录下,命令如下。
- 建立软连接
和window上的快捷方式一样,我们为jdk安装的长路径建立一个短路径,方便我们后面设置环境变量。
- 配置环境变量
在 /etc/profile 中添加环境变量。
# vim /etc/profile
添加内容:
JAVA_HOME=/home/jdk
CLASSPATH=$JAVA_HOME/lib
PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
随后使用 source /etc/profile 命令使配置生效,最后通过执行 java –version 查看java是否安装配置成功。看到输出的结果是我们安装的内容,说明安装配置成功。
[root@libaoshen_tencent home]# java -version
java version "1.8.0_161"
Java(TM) SE Runtime Environment (build
1.8.0_161-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode)
2. SSH配置
Hadoop控制脚本依靠SSH来进行集群的管理,为了方便操作,设置SSH为免密访问。
- 进入创建的用户hadoop的工作目录下
- 执行ssh创建密钥命令
进入hadoop用户的工作目录,查看目录下的文件,发现出现了一个 .ssh 文件夹。打开 .ssh 文件夹,我们看到了生成的 公钥 id_rsa.pub 和私钥 id_rsa 两个文件。
al
total 28
drwx
------ 3 hadoop hadoop 4096 Mar 16 23:49 . drwxr-xr-x. 5 root root 4096 Mar 16 23:48 .. -rw------- 1 hadoop hadoop 63 Mar 16 23:49 .bash_history -rw-r--r-- 1 hadoop hadoop 18 Aug 3 2016 .bash_logout -rw-r--r-- 1 hadoop hadoop 193 Aug 3 2016 .bash_profile -rw-r--r-- 1 hadoop hadoop 231 Aug 3 2016 .bashrc drwx------ 2 hadoop hadoop 4096 Mar 16 23:49 .ssh [hadoop@libaoshen_tencent ~]$ cd .ssh/
[hadoop
@libaoshen_tencent .ssh]$
ls
id_rsa id_rsa.pub
- 将生成的公钥覆盖到authorized_keys
- 通过再这三台机器上分别执行上面的步骤,将三台机器上hadoop用户 ~/.ssh/authorized_keys 中的内容合成一个authorized_keys文件,并使用 scp 命令将该文件复刻到其余两台机器上对应的目录中。并且同时要设置 .ssh 目录的访问权限为700,设置 .ssh/authorized_keys 的权限为600。具体操作如下。
a.合成后的authorized_keys文件
hadoop@libaoshen.novalocal
b.为 .ssh 和 .ssh/authorized_keys 分别设置权限为 700 和 600(很关键)
[hadoop
@libaoshen_tencent ~]$ chmod 600 .ssh/authorized_keys
c.libaoshen_tencent 节点上测试是否能免密登录,通过输出结果看到,可以成功免密登录
libaohshen_tencent
Last login: Sat Mar 17 13:24:42 2018 from 127.0.0.1
d.随后分别使用 scp 命令将该authorized_keys 复制到其他两个节点上,同时设置文件权限以及分别测试是否能免密登录
[hadoop@libaoshen_tencent ~]$ scp ~
/.ssh/authorized_keys hadoop@114.*.*.*:~/.ssh/
e.最后,在libaoshen_tencent节点上,即Master节点上尝试免密连接其余的节点,测试ssh是否配置正确。看输出结果,我们已经可以免密连接Slave节点了,说明ssh配置成功
Last failed login: Sat Mar
17 13:31:38 CST 2018 from 193..*.*.* on ssh:notty There were 2 failed login attempts since the last successful login. Last login: Sat Mar 17 13:07:31 2018
Welcome to Alibaba Cloud Elastic Compute Service
!
[hadoop
@libaoshen_ali ~]$
3. Hadoop安装和配置
- Master节点安装Hadoop
a. 我们已经将下载好的hadoop-2.7.5.tat.gz放在了 /home/install-package 中。首先使用root身份登录,再将 hadoop-2.7.5.tar.gz压缩包解压到 /home/hadoop 中,然后要么设置link,要么修改hadoop-2.7.5 目录为hadoop,缩短hadoop安装目录名。操作命令如下。
b. 配置hadoop环境变量
添加如下内容
hadoop
PATH=
$PATH:$HADOOP_HOME/
bin
export PATH HADOOP_HOME
再执行source /etc/profile 让环境变量配置生效。同时在 /home/hadoop/hadoop/etc/hadoop/hadoop-env.sh 修改java路径。如下所示。
修改java路径为上面我们所配置的路径,再执行 source hadoop-env.sh 使其生效。

修改后,执行hadoop version, 我们可以看到hadoop的版本号和其他信息。

c. 配置hadoop中的配置文件

i.core-site.xml: hadoop 的核心配置文件,添加设置为namenode节点的地址,端口号一般为9000

ii.hdfs-site.xml:设置备份数量,由于我们有两个datanode,所以设置为2

iii.mapred-site.xml:设置jobtracker对应的节点地址,端口号一般为9001

iv.masters和slaves:masters修改为设置为master的那个节点的ip,slaves修改为设置为slave的节点的ip

v.在master上配置完成后,再使用scp命令将java、hadoop及其配置复制到其他的两个节点上
复制hadoop
复制配置,由于我们的配置是在root用户下的,所以需要su root后输入密码才能scp
三. 启动
- 格式化
运行 hadoop namenode –format,会初始化namenode,记录集群元数据,即datanode的信息等。
- 启动
在目录 /usr/hadoop/hadoop/sbin 目录中执行 ./start-all.sh 即可以启动,执行 ./stop-all.sh 即可停止
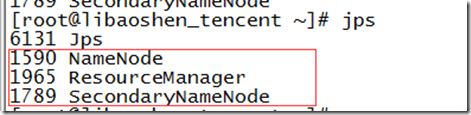
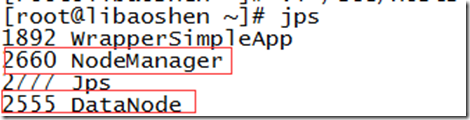
启动后可以使用 jps 命令查看hadoop后台进程是否已经启动
Master节点
Slave节点
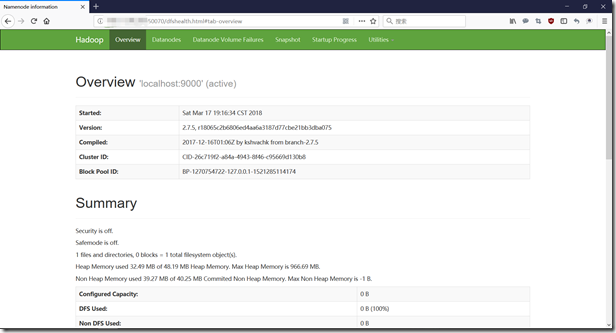
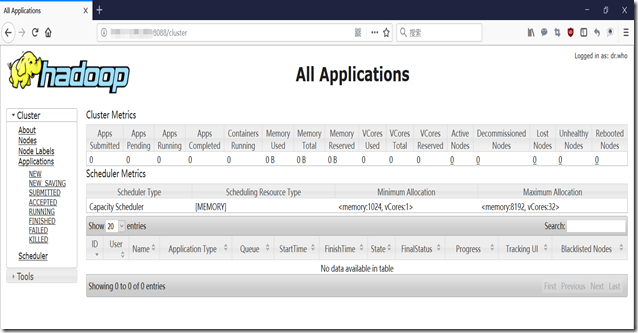
可以在浏览器中输入 namenode 的ip + 8088/50070 查看集群状态
安装过程中遇到的问题:
1. 配置不正确,导致分发给其他节点的配置也有问题,最后发现更正的成本比较高。所以一定要仔细检查,确认配置无误后,在复制到每个其他的节点;
2. hostname配置不正确,一定要确保 ip 和 hostname 对应,否则就可能出现 hostname unknown等报错;
3. 在启动过程中,hadoop会打印日志,当出现问题时,可以查看日志信息,准确定位错误位置。
Hadoop完全分布式安装配置完整过程的更多相关文章
- mysql-8.0解压缩版安装配置完整过程
https://www.cnblogs.com/xiongzaiqiren/p/8970203.html
- Hadoop 伪分布式安装配置
- hadoop伪分布式安装之Linux环境准备
Hadoop伪分布式安装之Linux环境准备 一.软件版本 VMare Workstation Pro 14 CentOS 7 32/64位 二.实现Linux服务器联网功能 网络适配器双击选择VMn ...
- 【Hadoop学习之三】Hadoop全分布式安装
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop3.1.1 全分布式就是集群,注意配置主机名. ...
- [大数据] hadoop全分布式安装
一.准备工作 在伪分布式的搭建基础上修改配置,搭建全分布式hadoop环境,伪分布式安装参照 hadoop伪分布式安装. 首先准备4台虚拟机,信息如下: 192.168.1.11 namenode1 ...
- < python音频库:Windows下pydub安装配置、过程出现的问题及常用API >
< python音频库:Windows下pydub安装配置.过程出现的问题及常用API > 背景 刚从B站上看过倒放挑战之后也想体验下,心血来潮一个晚上完成了基本的实现.其中倒放与播放部分 ...
- 【Oracle RAC】Linux系统Oracle11gR2 RAC安装配置详细过程V3.1(图文并茂)
[Oracle RAC]Linux系统Oracle11gR2 RAC安装配置详细过程V3.1(图文并茂) 2 Oracle11gR2 RAC数据库安装准备工作2.1 安装环境介绍2.2 数据库安装软件 ...
- Hadoop(MapR)分布式安装及自动化脚本配置
MapR的分布式集群安装过程还是很艰难的,远远没有计划中的简单.本人总结安装配置,由于集群有很多机器,手动每台配置是很累的,编写了一个自动化配置脚本,下面以脚本为主线叙述(脚本并不完善,后续继续完善中 ...
- apache hadoop 伪分布式安装
1. 准备工作 1.1. 软件准备 1.安装VMWare 2.在VMWare上安装CentOS6.5 3.安装XShell5,用来远程登录系统 4.通过rpm -qa | grep ssh 检查cen ...
随机推荐
- String类型为什么不可变
在学习Java的过程中,我们会被告知 String 被设计成不可变的类型.为什么 String 会被 Java 开发者有如此特殊的对待?他们的设计意图和设计理念到底是什么?因此,我带着以下三个问题,对 ...
- Android异常与性能优化相关面试问题-其他优化面试问题详解
Android不用静态变量存储数据: 静态变量等数据由于进程已经被杀死而被初始化.在Android中应用进程不是安全的,因为它会有系统给kill掉,但是在实际中可能会有这样的一个假象:当app被杀掉之 ...
- 精选30道Java多线程面试题
1.线程和进程的区别 进程是应用程序的执行实例.比如说,当你双击的Microsoft Word的图标,你就开始运行的Word的进程.线程是执行进程中的路径.另外,一个过程可以包含多个线程.启动Word ...
- 关于Spring MVC写的不错的几篇博客
关于Spring MVC写的不错的几篇博客 https://my.oschina.net/kolbe/blog/509810 https://www.cnblogs.com/sunniest/p/45 ...
- 基于Hexo的个人博客搭建(上)
没有废话,直接开始. 1. 环境配置 —1.1 node.js安装 https://nodejs.org/en/download/ 下载最新版本即可,然后无脑安装(除了选安装目录的时候),为了保证安装 ...
- vue插件——滚动监听 vue-scrollwatch
造轮子的目的: 做项目的时候需要一个滚动监听的功能,html结构已经都写好了,不想使用vue组件的方式来写,因为不想改造html结构,于是花了几个小时做了一个简单的,使用vue指令方式来做的,项目上够 ...
- PHP Swoole websocket协议实现
- .net大文件上传断点续传源码
IE的自带下载功能中没有断点续传功能,要实现断点续传功能,需要用到HTTP协议中鲜为人知的几个响应头和请求头. 一. 两个必要响应头Accept-Ranges.ETag 客户端每次提交下载请求时,服务 ...
- java+大文件上传解决方案
众所皆知,web上传大文件,一直是一个痛.上传文件大小限制,页面响应时间超时.这些都是web开发所必须直面的. 本文给出的解决方案是:前端实现数据流分片长传,后面接收完毕后合并文件的思路. 实现文件夹 ...
- 判断一个ip地址合法性(基础c,不用库函数)
#include <stdio.h> int judge(char *strIp); int main() { ]; ) { scanf("%s", a); == ju ...