Python爬虫之简单爬虫框架实现
简单爬虫框架实现
目录
框架流程
调度器
url管理器
网页下载器
网页解析器
数据处理器
具体演示效果
框架流程

调度器
#导入模块
import Url_Manager
import parser_html
import html_output
import download class SpiderMain(object):
def __init__(self):
#实例化:url管理器,网页下载器,网页解析器,数据输出
self.urls=Url_Manager.UrlManager()
self.parser=parser_html.Htmlparser()
self.download = download.download()
self.outputer=html_output.HtmlOutputer() def craw(self,root_url):
count=1
#向列表里面添加新的单个url
self.urls.add_new_url(root_url)
#判断待爬取的url列表里面有没有新的url
while self.urls.has_new_url():
try:
#如果待爬取的url列表不为空,则取一个url出来
new_url=self.urls.get_new_url()
print('craw %d:%s' % (count,new_url))
#下载网页 html_cont=self.download.download(new_url)
#解析网页
#解析获得两个数据:新的url,以及我们要获取的数据
new_urls,new_data=self.parser.parse(new_url,html_cont)
#获取的url添加到待爬取的url列表 self.urls.add_new_urls(new_urls)
#保存数据
self.outputer.collect_data(new_data)
#如果下载的url页面达到50个,结束当前循环
if count ==50:
break
count=count+1
except:
print('craw failed')
#输出数据
self.outputer.output_html() if __name__ == '__main__':
#开始爬取的url
url = "http://www.dili360.com/gallery/"
root_url=url
#实例化
obj_spider=SpiderMain()
obj_spider.craw(root_url)
url管理器
#url管理器需要四个方法:
#add_new_url:向管理器添加单个url
#add_new_url:向管理器添加批量的url
#has_new_url:判断管理器里面是否有新的在爬取的url
#get_new_url:在管理器中获取一个正在爬取的url
#url管理器需要维护两个列表:待爬取的url,已经爬取的url class UrlManager(object):
def __init__(self):
#待爬取的url列表
self.new_urls=set()
#已经爬取的url列表
self.old_urls=set() #向管理器添加单个url
def add_new_url(self,url):
#首先判断url是否为空
if url is None:
return
#如果这个url既不在待爬取的url里面也没有在已经爬取的url里面,则说明这是一个新url
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
# 向管理器添加批量的url
def add_new_urls(self,urls):
if urls is None or len(urls) ==0:
return
for url in urls:
self.add_new_url(url)
#判断管理器里面是否有新的在爬取的url
def has_new_url(self):
return len(self.new_urls) != 0 # 获取一个正在爬取的url
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
网页下载器
import requests
class download(object):
def download(self,url):
if url is None:
return None
else: response = requests.get(url)
if response.status_code !=200: return None
return response.text
网页解析器
from urllib.parse import urljoin
from bs4 import BeautifulSoup class Htmlparser(object): def _get_new_urls(self,page_url,soup): new_urls = set()
#这里可以加上正则表达式,对url进行过滤
links=soup.find_all('a')
for link in links:
#补全url,添加到列表里面
new_url=link['href']
new_full_url=urljoin(page_url,new_url)
new_urls.add(new_full_url) return new_urls def _get_new_data(self,page_url,soup): #解析数据,由用户来编写
new_datas=set()
imgs=soup.find_all('img')
for img in imgs:
new_data=img['src']
new_full_data=new_data
new_datas.add(new_full_data)
return new_datas #需要解析出新的url和数据
def parse(self,page_url,html_cont):
if page_url is None or html_cont is None:
return
soup=BeautifulSoup(html_cont,'html.parser')
#调用两个本地方法:解析新的url以及解析数据
new_urls=self._get_new_urls(page_url,soup)
new_data = self._get_new_data(page_url,soup) return new_urls,new_data # 报错:
# UserWarning: You provided Unicode markup but also provided a value for from_encoding. Your from_encoding will be ignored.
# 解决方法:
# soup = BeautifulSoup(html_doc,"html.parser")
# 这一句中删除【from_encoding="utf-8"】
# 原因:
# python3 缺省的编码是unicode, 再在from_encoding设置为utf8, 会被忽视掉,去掉【from_encoding="utf-8"】这一个好了
数据处理器
使用文档保存文本信息
使用文件保存图片,视频文件等,可进行扩展
class HtmlOutputer(object):
def __init__(self):
self.datas=[]
def collect_data(self,data):
if data is None:
return
self.datas.append(data)
def output_html(self):
fout=open('output','a+')
for data in self.datas:
for da in data:
fout.write(str(da)+'\n')
fout.close()
具体演示效果
演示url:http://www.dili360.com/gallery/
演示过程:
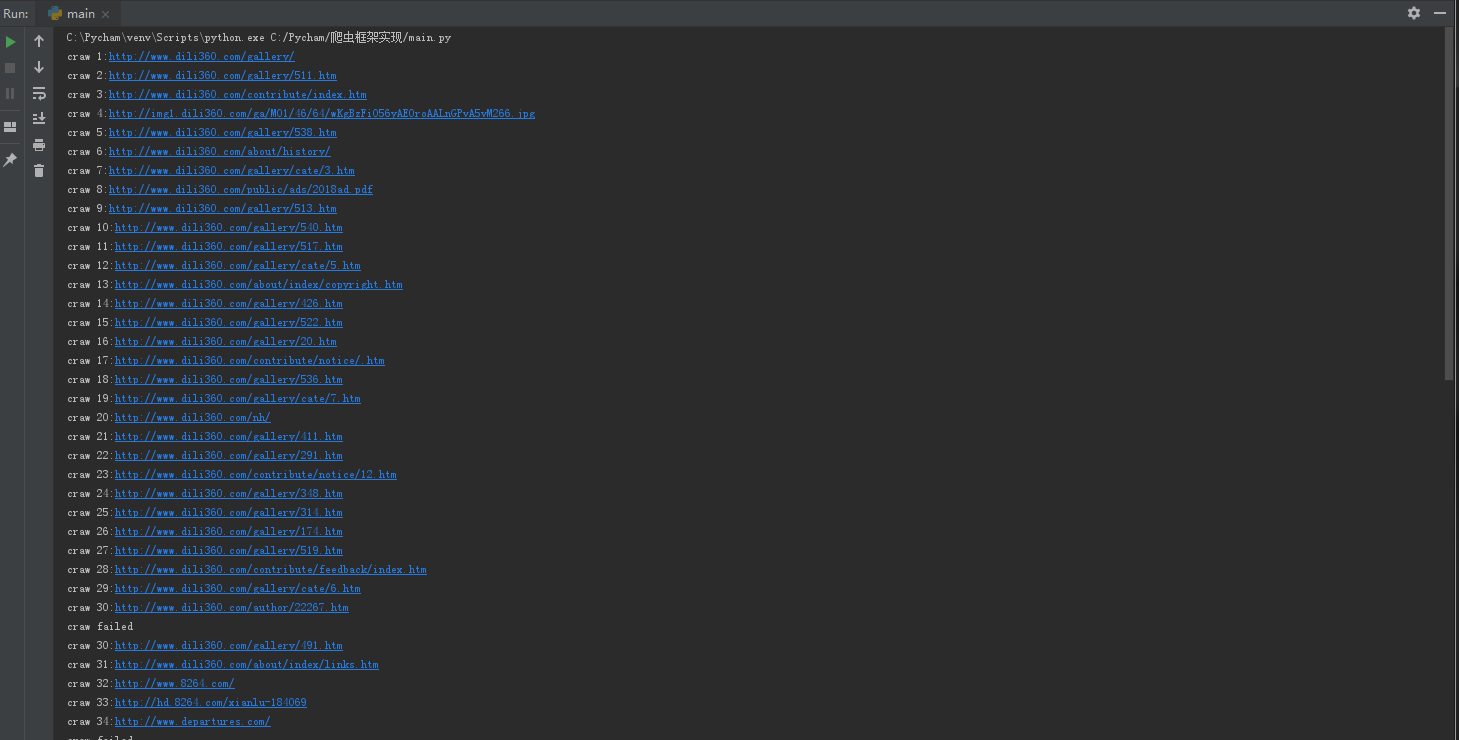
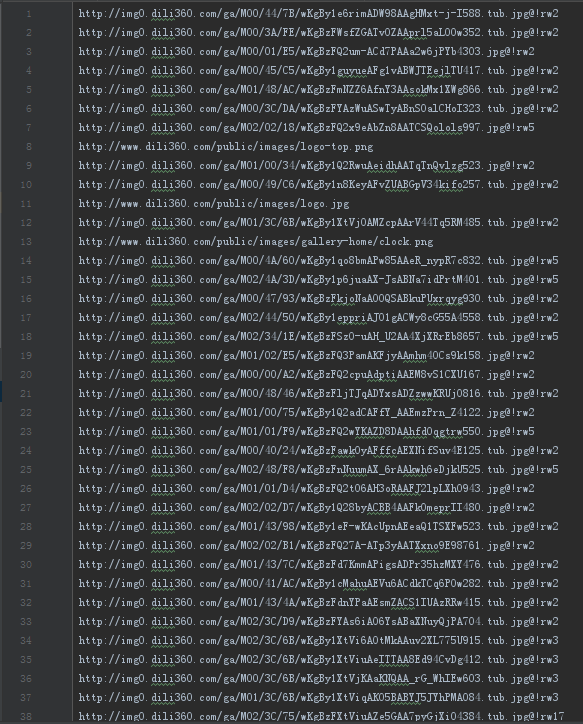
数据处理:
Python爬虫之简单爬虫框架实现的更多相关文章
- 【Python项目】简单爬虫批量获取资源网站的下载链接
简单爬虫批量获取资源网站的下载链接 项目链接:https://github.com/RealIvyWong/GotDownloadURL 1 由来 自己在收集剧集资源的时候,这些网站的下载链接还要手动 ...
- [python]做一个简单爬虫
为什么选择python,它强大的库可以让你专注在爬虫这一件事上而不是更底层的更繁杂的事 爬虫说简单很简单,说麻烦也很麻烦,完全取决于你的需求是什么以及你爬的网站所决定的,遇到的第一个简单的例子是pas ...
- 【Python】:简单爬虫作业
使用Python编写的图片爬虫作业: #coding=utf-8 import urllib import re def getPage(url): #urllib.urlopen(url[, dat ...
- 【Python数据分析】简单爬虫 爬取知乎神回复
看知乎的时候发现了一个 “如何正确地吐槽” 收藏夹,里面的一些神回复实在很搞笑,但是一页一页地看又有点麻烦,而且每次都要打开网页,于是想如果全部爬下来到一个文件里面,是不是看起来很爽,并且随时可以看到 ...
- 第一次用python 写的简单爬虫 记录在自己的博客
#python.py from bs4 import BeautifulSoup import urllib.request from MySqlite import MySqlite global ...
- python bs4 + requests4 简单爬虫
参考链接: bs4和requests的使用:https://www.cnblogs.com/baojinjin/p/6819389.html 安装pip:https://blog.csdn.net/z ...
- 洗礼灵魂,修炼python(72)--爬虫篇—爬虫框架:Scrapy
题外话: 前面学了那么多,相信你已经对python很了解了,对爬虫也很有见解了,然后本来的计划是这样的:(请忽略编号和日期,这个是不定数,我在更博会随时改的) 上面截图的是我的草稿 然后当我开始写博文 ...
- Python开发简单爬虫
简单爬虫框架: 爬虫调度器 -> URL管理器 -> 网页下载器(urllib2) -> 网页解析器(BeautifulSoup) -> 价值数据 Demo1: # codin ...
- Python 爬虫(1)基础知识和简单爬虫
Python上手很容易,免费开源,跨平台不受限制,面向对象,框架和库很丰富. Python :Monty Python's Flying Circus (Python的名字来源,和蟒蛇其实无关). 通 ...
随机推荐
- 前端使用pdf.js预览pdf文件,超级简单
现在的浏览器基本都支持直接把pdf文件拖到浏览器就可以打开了,不用安装额外的插件.但是不同的浏览器显示的页面不一样.如果我们想在网页上统一预览pdf怎样实现呢? Mozilla开源了一个插件pdf.j ...
- 一个继承的 DataGridView
// 允许增加一个 checkbox 列 public class DgvBase : DataGridViewX { protected override void OnColumnAdded(Da ...
- is幻梦 Linux命令之文件和目录操作命令(二)——查看文件内容cat、more、less、tail、head
一.cat命令 用法:cat [选项][文件] 1.主要用来查看文件内容 2.-n 在文件内容的每一行上加上行号 3.再不加任何选项和文件名的时候,将标准输入的内容复制到标准输出 这个时候一般用于重定 ...
- AutoCompleteTextView实现搜索提示功能的实现
AutoCompleteTextView和EditText组件类似,都可以输入文本.但AutoCompleteTextView组件可以和一个字符串数组或List对象绑定,当用户输入两个及以上字符时,系 ...
- Void pointers in C
In this article we are learning about “void pointers” in C language. Before going further it will be ...
- python中接受上一条命令执行的结果----subprocess.check_output()
subprocess.call 是不能作为赋值的,需要用到 subprocess.check_output 函数,而且如果要引用赋值就必须使用subprocess.call(['echo',line] ...
- python-爬虫-selenium和phantomJs
1.selenum:三方库.可以实现让浏览器完成自动化的操作. 2.环境搭建 2.1 安装:pip install selenium 2.2 获取浏览器的驱动程序 下载地址: http://chrom ...
- 实现文件上传功能(FileUpload组件)
文件上传: 项目中经常用到文件上传. 自己实现文件上传,使用文件上传组件fileupload组件 1.指定表单类型为文件上传, enctype=”multipart/form-data” 2.提交方式 ...
- 【OpenJ_Bailian - 2790】迷宫(bfs)
-->迷宫 Descriptions: 一天Extense在森林里探险的时候不小心走入了一个迷宫,迷宫可以看成是由n * n的格点组成,每个格点只有2种状态,.和#,前者表示可以通行后者表示不 ...
- KVM虚拟迁移(5)
一.迁移简介 迁移: 系统的迁移是指把源主机上的操作系统和应用程序移动到目的主机,并且能够在目的主机上正常运行.在没有虚拟机的时代,物理机之间的迁移依靠的是系统备份和恢复技术.在源主机上实时 ...